このドキュメントでは、TensorFlow Extended(TFX)ライブラリを使用する機械学習(ML)システムの全体的なアーキテクチャについて説明します。また、Cloud Build と Vertex AI Pipelines を使用して ML システムの継続的インテグレーション(CI)、継続的デリバリー(CD)、継続的トレーニング(CT)を設定する方法についても説明します。
このドキュメントでは、ML システムと ML パイプラインという用語は、モデルのスコアリングや予測パイプラインではなく、ML モデルのトレーニング パイプラインを指します。
このドキュメントは、CI / CD の方法論を応用して ML ソリューションを Google Cloud の本番環境へ移行し、ML パイプラインの品質、保守性、適応性を確保する必要があるデータ サイエンティストと ML エンジニアを対象としています。
このドキュメントでは、次のトピックについて説明します。
- ML における CI / CD と自動化の理解
- TFX を使用した統合 ML パイプラインの設計
- Vertex AI Pipelines を使用した ML パイプラインのオーケストレーションと自動化
- Cloud Build を使用した ML パイプライン用の CI / CD システムの設定
MLOps
ML システムを本番環境に統合するには、ML パイプラインのステップをオーケストレートする必要があります。さらに、モデルの継続的なトレーニングのためにパイプラインの実行を自動化する必要があります。新しいアイデアや機能をテストするには、パイプラインの新しい実装で CI / CD の方法論を採用する必要があります。次のセクションでは、ML における CI / CD と CT の概要を説明します。
ML パイプラインの自動化
ユースケースによっては、ML モデルのトレーニング、検証、デプロイの手動プロセスで十分な場合もあります。この手動アプローチは、チームが、再トレーニングされていない、または頻繁に変更されていない ML モデルを少数しか管理していない場合に機能します。しかし実際のモデルは、環境のダイナミクスやダイナミクスを記述するデータの変更に適応しないため、現実世界にデプロイするとしばしばブレイクダウンします。
ML システムを変更に適応させるには、次の MLOps 手法を適用する必要があります。
- ML パイプラインの実行を自動化して、新しいデータで新しいモデルを再トレーニングし、新しいパターンをキャプチャします。CT については、このドキュメントの後半の Vertex AI Pipelines を使用した ML のセクションで説明します。
- ML パイプライン全体の新たな実装を繰り返しデプロイするには、継続的デリバリー システムを設定します。CI / CD については、後述の Google Cloud での ML の CI / CD 設定のセクションで説明します。
ML の本番環境のパイプラインを自動化して、新しいデータでモデルを再トレーニングできます。パイプラインがトリガーされる条件には、オンデマンド、スケジュール、新しいデータが利用可能になったこと、モデルのパフォーマンス低下、データの統計的特性の大幅な変化などがあります。
CI / CD パイプラインと CT パイプラインの比較
新しいデータが利用可能になることは、ML モデルが再トレーニングされる 1 つのトリガーです。ML パイプラインが再実行されるもう 1 つの重要なトリガーは、ML パイプラインの新しい実装(新しいモデル アーキテクチャ、特徴量エンジニアリング、ハイパーパラメータなど)が利用可能になることです。ML パイプラインのこの新しい実装は、モデル予測サービスの新しいバージョン(オンライン サービス用の REST API を備えたマイクロ サービスなど)として機能します。2 つのケースの違いは次のとおりです。
- 新しいデータを使用して新しい ML モデルをトレーニングするために、以前にデプロイされた CT パイプラインが実行されます。新しいパイプラインやコンポーネントはデプロイされません。新しい予測サービスや新しくトレーニングされたモデルのみがパイプラインの最後に提供されます。
- 新しい ML モデルを新しい実装でトレーニングするには、CI / CD パイプラインを介して新しいパイプラインをデプロイします。
新しい ML パイプラインを迅速にデプロイするには、CI / CD パイプラインを設定する必要があります。このパイプラインにより、さまざまな環境(開発、テスト、ステージング、本番環境移行前、本番環境など)で新しい実装が利用可能になると、新しい ML パイプラインとコンポーネントが自動的にデプロイされます。
次の図は、CI / CD パイプラインと ML CT パイプラインの関係を示しています。

図 1: CI / CD および ML CT パイプライン。
これらのパイプラインの出力は次のとおりです。
- 新しい実装の場合、CI / CD パイプラインが成功すると、新しい ML CT パイプラインがデプロイされます。
- 新しいデータの場合、CT パイプラインが成功すると、新しいモデルがトレーニングされ、予測サービスとしてデプロイされます。
TFX ベースの ML システムの設計
以降のセクションでは、TensorFlow Extended(TFX)を使用して ML システム用の CI / CD パイプラインを設定する統合 ML システムを設計する方法について説明します。ML モデルをビルドするためのフレームワークはいくつかありますが、TFX は、本番環境の ML システムを開発およびデプロイするための統合 ML プラットフォームです。TFX パイプラインは、ML システムを実装するコンポーネントのシーケンスです。この TFX パイプラインは、スケーラブルで高性能な ML タスク用に設計されています。これらのタスクには、モデリング、トレーニング、検証、推論の提供、デプロイの管理が含まれます。TFX の主なライブラリは次のとおりです。
- TensorFlow Data Validation(TFDV): データ内の異常を検出するために使用します。
- TensorFlow Transform(TFT): データの前処理と特徴量エンジニアリングに使用します。
- TensorFlow Estimator と Keras: ML モデルの構築とトレーニングに使用します。
- TensorFlow Model Analysis(TFMA): ML モデルの評価と解析に使用します。
- TensorFlow Serving(TFServing): ML モデルを REST および gRPC API として提供するために使用します。
TFX ML システムの概要
次の図は、さまざまな TFX ライブラリを統合して ML システムを構成する方法を示しています。

図 2. 典型的な TFX ベースの ML システム。
図 2 は、典型的な TFX ベースの ML システムを示しています。次のステップは、手動で、または自動パイプラインで実行できます。
- データ抽出: 最初のステップは、データソースから新しいトレーニング データを抽出することです。このステップの出力は、モデルのトレーニングと評価に使用されるデータファイルです。
- データの検証: TFDV では、予想される(未加工の)データスキーマに基づいてデータが検証されます。データスキーマは、システムのデプロイ前に開発フェーズで作成、修正されます。データの検証のステップでは、データの分散とスキーマのスキューの両方に関連する異常が検出されます。このステップの出力は、異常値(ある場合)、および下流のステップを実行するかどうかの決定です。
- データ変換: データは検証後に分割され、ML タスクに向けて準備されます。このために、TFT を使用してデータ変換と特徴量エンジニアリングのオペレーションが実行されます。このステップの出力は、モデルをトレーニングして評価するためのデータファイルで、通常は
TFRecords形式に変換されます。生成された変換アーティファクトは、モデル入力の構築に役立ち、またトレーニング後にエクスポートされた保存モデルに変換プロセスを埋め込みます。 - モデルのトレーニングとチューニング: ML モデルを実装してトレーニングするには、前のステップで生成された変換済みデータで、
tf.KerasAPI を使用します。最適なモデルにつながるパラメータ設定を選択するには、Keras 用のハイパーパラメータ チューニング ライブラリである Keras Tuner を使用します。あるいは、Katib、Vertex AI Vizier などのその他のサービスや、Vertex AI ハイパーパラメータ チューナーを使用することもできます。このステップの出力は、評価に使用される保存済みモデルと、予測用のモデルのオンライン サービスに使用される別の保存済みモデルです。 - モデルの評価と検証: トレーニング ステップの後にエクスポートされたモデルは、テスト データセットで評価され、TFMA を使用してモデルの品質が評価されます。TFMA ではモデル全体の品質が評価され、データモデルのどの部分が実行されていないかが特定されます。この評価により、モデルが品質基準を満たしている場合にのみサービングのためにプロモートされることが保証されます。品質基準には、さまざまなデータ サブセット(ユーザー属性やロケーションなど)での適正なパフォーマンスや、以前のモデルやベンチマーク モデルと比較して向上したパフォーマンスなどがあります。このステップの出力は、一連のパフォーマンス指標と、モデルを本番環境にプロモートするかどうかの決定です。
- 予測用モデルの提供: 新しくトレーニングされたモデルが検証されると、TensorFlow Serving を使用してオンライン予測に対応するマイクロサービスとしてデプロイされます。このステップの出力は、トレーニング済み ML モデルのデプロイされた予測サービスです。モデル レジストリにトレーニングしたモデルを保存することで、このステップを置き換えることができます。その後、別個のモデル サービング CI / CD プロセスが開始されます。
TFX ライブラリの使用例については、公式の TFX Keras コンポーネント チュートリアルをご覧ください。
Google Cloud 上の TFX ML システム
本番環境では、システムのコンポーネントは信頼性の高いプラットフォーム上で大規模に実行する必要があります。次の図は、TFX ML パイプラインの各ステップが Google Cloud のマネージド サービスを使用して実行される方法を示しています。これにより、大規模環境でのアジリティ、信頼性、パフォーマンスが確保されます。

図 3. Google Cloud 上の TFX ベースの ML システム
次の表に、図 3 に示す主要な Google Cloud サービスを示します。
| ステップ | TFX ライブラリ | Google Cloud サービス |
|---|---|---|
| データ抽出と検証 | TensorFlow のデータ検証 | Dataflow |
| データ変換 | TensorFlow Transform | Dataflow |
| モデルのトレーニングと調整 | TensorFlow | Vertex AI Training |
| モデルの評価と検証 | TensorFlow Model Analysis | Dataflow |
| 予測のためのモデル サービング | TensorFlow Serving | Vertex AI Prediction |
| モデルの保存 | なし | Vertex AI Model Registry |
- Dataflow は、Apache Beam パイプラインを Google Cloud 上で大規模に実行するための、フルマネージド、サーバーレスで信頼性の高いサービスです。Dataflow は、次のプロセスのスケーリングに使用されます。
- 統計を計算して、受信データを検証する。
- データの準備と変換を行う。
- 大規模なデータセットでモデルを評価する。
- 評価データセットのさまざまな側面で指標を計算する。
- Cloud Storage は、バイナリラージ オブジェクトを格納する可用性と耐久性に優れたストレージです。Cloud Storage は、ML パイプラインの実行中に生成された次のようなアーティファクトをホストします。
- データの異常(ある場合)
- 変換されたデータとアーティファクト
- エクスポート済み(トレーニング済み)のモデル
- モデル評価の指標
- Vertex AI Training は、ML モデルのトレーニングを大規模に行うためのマネージド サービスです。モデル トレーニング ジョブは、TensorFlow、Scikit Learn、XGBoost、PyTorch 用のビルド済みコンテナを使用して実行できます。また、独自のカスタム コンテナを使用して任意のフレームワークを実行することもできます。トレーニング インフラストラクチャでは、アクセラレータと複数のノードを分散トレーニングに使用できます。また、スケーラブルなベイズ最適化ベースのサービスを使用して、ハイパーパラメータ チューニングを行うこともできます。
- Vertex AI Prediction は、REST API でマイクロサービスとしてモデルをデプロイすることで、トレーニング済みモデルとオンライン予測を使用してバッチ予測を実行するマネージド サービスです。このサービスはまた、Vertex Explainable AI および Vertex AI Model Monitoring と統合され、モデルを理解し、特徴または特徴アトリビューションのスキューとドリフトがある場合にアラートを受け取ります。
- Vertex AI Model Registry を使用すると、ML モデルのライフサイクルを管理できます。インポートしたモデルをバージョニングし、パフォーマンス指標を表示できます。その後、モデルをバッチ予測に使用したり、Vertex AI Prediction を使用してオンライン サービング用のモデルをデプロイしたりできます。
Vertex AI Pipelines を使用した ML システムのオーケストレーション
このドキュメントでは、TFX ベースの ML システムの設計方法と、Google Cloud 上でシステムの各コンポーネントを大規模に実行する方法について説明します。ただし、システムのこれらの異なるコンポーネントを接続するにはオーケストレーターが必要です。オーケストレーターは、パイプラインを順に実行し、定義した条件に基づいてステップ間を自動的に移動します。たとえば、評価指標が事前定義したしきい値を満たしている場合、定義した条件により、モデル評価ステップの後にモデル提供ステップが実行されます。時間を節約するために、ステップを並行して実行することもできます(デプロイ インフラストラクチャの検証とモデルの評価など)。ML パイプラインのオーケストレーションは、開発フェーズと本番環境フェーズの両方で役に立ちます。
- 開発フェーズにおいて、データ サイエンティストは、各ステップを手動で実行する代わりに、オーケストレーションにより ML テストを実行できます。
- 本番環境フェーズでは、オーケストレーションにより、スケジュールや特定のトリガー条件に基づいた ML パイプラインの実行を自動化できます。
Vertex AI Pipelines での ML
Vertex AI Pipelines は、ML パイプラインをオーケストレートして自動化できるようにする Google Cloud マネージド サービスです。ML パイプラインの各コンポーネントは、Google Cloud またはその他のクラウド プラットフォームでコンテナ化して実行できます。生成されたパイプラインのパラメータとアーティファクトは、Vertex ML Metadata に自動的に保存されるため、リネージと実行の追跡が可能になります。Vertex AI Pipelines サービスは、次のもので構成されています。
- テスト、ジョブ、実行を管理およびトラックするためのユーザー インターフェース。
- マルチステップ ML ワークフローをスケジュールするためのエンジン。
- パイプラインとコンポーネントを定義して操作するための Python SDK。
- 実行、モデル、データセット、その他のアーティファクトに関する情報を保存する Vertex ML Metadata との統合。
Vertex AI Pipelines で実行されるパイプラインは、次のもので構成されています。
- 一連のコンテナ化された ML タスク、またはコンポーネント。パイプライン コンポーネントは、Docker イメージとしてパッケージ化された自己完結型のコードです。コンポーネントは、パイプラインで 1 つのステップを実行します。入力引数を取り、アーティファクトを生成します。
- Python ドメイン固有の言語(DSL)で定義された ML タスクのシーケンスの仕様。ワークフローのトポロジは、上流ステップの出力を下流ステップの入力に接続することによって暗黙的に定義されます。パイプライン定義のステップは、パイプライン内のコンポーネントを呼び出します。複雑なパイプラインのコンポーネントは、ループで複数回実行される場合や、条件付きで実行される場合があります。
- パイプライン入力パラメータのセット。値はパイプラインのコンポーネントに渡されます。データのフィルタリング条件や、パイプラインが生成するアーティファクトの保存場所が含まれます。
次の図は、Vertex AI Pipelines のサンプルグラフを示しています。
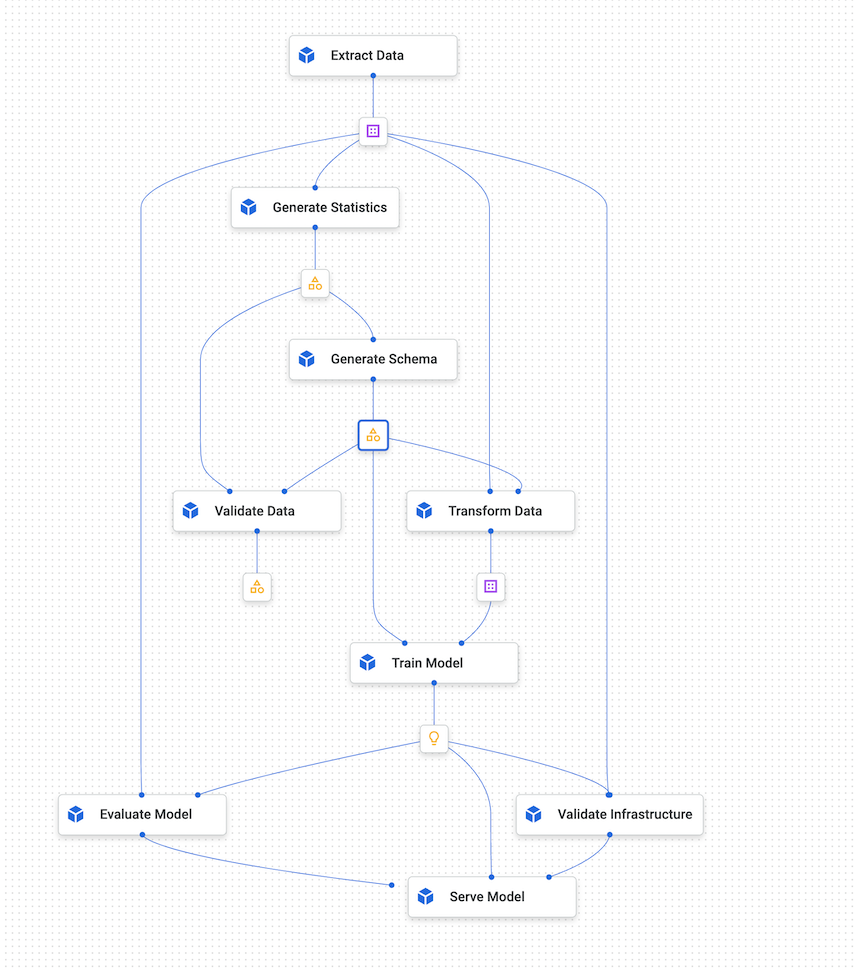
図 4. Vertex AI Pipelines のサンプルグラフ。
Kubeflow Pipelines SDK
Kubeflow Pipelines SDK を使用すると、コンポーネントを作成してオーケストレーションを定義し、コンポーネントを 1 つのパイプラインとして実行できます。Kubeflow Pipelines コンポーネントの詳細については、Kubeflow のドキュメントでコンポーネントを作成するをご覧ください。
TFX パイプライン DSL と TFX コンポーネントも使用できます。TFX コンポーネントは、メタデータ機能をカプセル化します。ドライバは、メタデータ ストアにクエリを実行してエグゼキュータにメタデータを提供します。パブリッシャーはエグゼキュータの結果を受け入れ、メタデータに保存します。メタデータと同じように統合されるカスタム コンポーネントを実装することもできます。tfx.orchestration.experimental.KubeflowV2DagRunner を使用して、TFX パイプラインを Vertex AI Pipelines 互換の YAML にコンパイルできます。その後、ファイルを Vertex AI Pipelines に送信して実行できます。
次の図は、Vertex AI Pipelines で、コンテナ化されたタスクが、BigQuery ジョブ、Vertex AI(分散)トレーニング ジョブ、Dataflow ジョブなどの他のサービスを呼び出す方法を示しています。

図 5. Google Cloud マネージド サービスを呼び出す Vertex AI Pipelines。
Vertex AI Pipelines では、必要な Google Cloud サービスを実行することで、本番環境の ML パイプラインをオーケストレートして自動化できます。図 5 では、Vertex ML Metadata が Vertex AI Pipelines の ML メタデータ ストアとして機能します。
パイプラインのコンポーネントは、Google Cloud での TFX 関連サービスの実行に限定されません。SparkML ジョブの Dataproc、AutoML、その他のコンピューティング ワークロードなど、データ関連サービスとコンピューティング関連サービスを実行できます。
Vertex AI Pipelines でタスクをコンテナ化するメリットは次のとおりです。
- 実行環境とコード ランタイムを分離します。
- テストの対象は本番環境でも同じであるため、開発環境と本番環境の間でコードの再現性があります。
- パイプライン内の各コンポーネントを分離します。それぞれに異なるバージョンのランタイム、異なる言語、異なるライブラリがあります。
- 複雑なパイプラインの構成に役立ちます。
- パイプラインの実行とアーティファクトのトレーサビリティと再現性のために Vertex ML Metadata と統合します。
Vertex AI Pipelines の概要については、利用可能なノートブックの例のリストをご覧ください。
Vertex AI Pipelines のトリガーとスケジュール設定
パイプラインを本番環境にデプロイするには、ML パイプラインの自動化セクションで説明したシナリオに応じて、実行を自動化する必要があります。
Vertex AI SDK を使用すると、パイプラインをプログラムで操作できます。google.cloud.aiplatform.PipelineJob クラスには、テストを作成し、パイプラインをデプロイして実行するための API が含まれています。このため、この SDK を使用すると、別のサービスから Vertex AI Pipelines を呼び出して、スケジューラまたはイベントに基づくトリガーを実現できます。

図 6. Pub/Sub と Cloud Run functions を使用した Vertex AI Pipelines の複数のトリガーを示すフロー図
図 6 は、Vertex AI Pipelines サービスをトリガーしてパイプラインを実行する方法の例を示しています。このパイプラインは、Cloud Run functions から Vertex AI SDK を使用してトリガーされます。Cloud Run functions 自体は Pub/Sub のサブスクライバーであり、新しいメッセージに基づいてトリガーされます。パイプラインの実行をトリガーするサービスはすべて、対応する Pub/Sub トピックでパブリッシュできます。上記の例には、次の 3 つのパブリッシュ サービスがあります。
- Cloud Scheduler は、スケジュールに従ってメッセージをパブリッシュします。これにより、パイプラインがトリガーされます。
- Cloud Composer は、大規模なワークフローの一部としてメッセージをパブリッシュします。このようなワークフローの例としては、BigQuery に新しいデータが取り込まれた後にトレーニング パイプラインをトリガーするデータ取り込みワークフローなどがあります。
- Cloud Logging は、いくつかのフィルタ基準を満たすログに基づいてメッセージをパブリッシュします。フィルタを設定すると、新しいデータの到着と、Vertex AI Model Monitoring サービスによって生成されたスキューとドリフトのアラートを検出できます。
Google Cloud での ML 用 CI / CD の設定
Vertex AI Pipelines を使用すると、データの前処理、モデルのトレーニングと評価、モデルのデプロイなどの複数のステップを含む ML システムをオーケストレートできます。データ サイエンスの探索フェーズでは、Vertex AI Pipelines はシステム全体の迅速なテストに役立ちます。本番環境フェーズでは、Vertex AI Pipelines を使用して、ML モデルをトレーニングまたは再トレーニングするための新しいデータに基づくパイプラインの実行を自動化できます。
CI / CD アーキテクチャ
次の図は、Vertex AI Pipelines を使用した ML の CI / CD の概要を示しています。
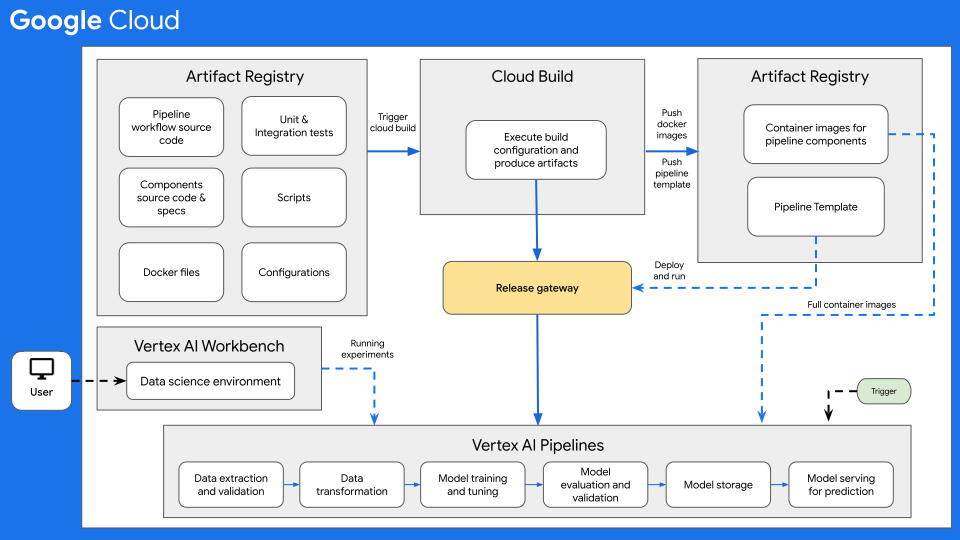
図 7: Vertex AI Pipelines を使用した CI / CD の概要。
このアーキテクチャの中核となるのは Cloud Build です。Cloud Build は、Artifact Registry、GitHub、Bitbucket からソースをインポートして、仕様に合わせてビルドを実行し、Docker コンテナや Python tar ファイルなどのアーティファクトを生成できます。
Cloud Build は、ビルド構成ファイル(cloudbuild.yaml)で定義された一連のビルドステップとしてビルドを実行します。各ビルドステップは Docker コンテナで実行されます。Cloud Build が提供するサポート対象のビルドステップを使用するか、独自のビルドステップを作成できます。
ML システムに必要な CI / CD を実行する Cloud Build プロセスは、手動で、または自動ビルドトリガーで実行できます。トリガーは、ビルドソースに変更が push されるたびに、構成されたビルドステップを実行します。ビルドトリガーを設定して、ソース リポジトリへの変更時にビルドルーチンを実行するか、変更が特定の条件に一致したときにのみビルドルーチンを実行できます。
さらに、さまざまなトリガーに応じて実行されるビルドルーチン(Cloud Build 構成ファイル)を使用できます。たとえば、開発ブランチまたはメインブランチに対して commit が行われたときにトリガーされるビルドルーチンを使用できます。
構成変数の置換を使用して、ビルド時に環境変数を定義できます。これらの置換は、トリガーされたビルドからキャプチャされます。これらの変数には、$COMMIT_SHA、$REPO_NAME、$BRANCH_NAME、$TAG_NAME、$REVISION_ID があります。他の非トリガーベースの変数は、$PROJECT_ID と $BUILD_ID です。置換はビルド時まで値が不明な変数を設定する場合や、既存のビルド リクエストを別の変数値で再利用する場合に役立ちます。
CI / CD ワークフローのユースケース
通常、ソースコード リポジトリには次の項目が含まれます。
- パイプライン ワークフローが定義されている Python パイプライン ワークフローのソースコード
- Python パイプライン コンポーネントのソースコードと、データ検証、データ変換、モデル トレーニング、モデル評価、モデル提供などの異なるパイプライン コンポーネント用の対応するコンポーネント仕様ファイル。
- Docker コンテナ イメージを作成するために必要な Dockerfile(パイプライン コンポーネントごとに 1 つ)。
- Python の単体テストと統合テストでは、コンポーネントとパイプライン全体で実装されたメソッドをテストします。
cloudbuild.yamlファイル、テストトリガー、パイプライン デプロイを含む、その他のスクリプト- パイプライン入力パラメータの構成を含む構成ファイル(
settings.yamlファイルなど)。 - 探索的データ分析、モデル分析、モデルのインタラクティブなテストに使用されるノートブック。
次の例では、デベロッパーがデータ サイエンス環境から開発ブランチにソースコードを push すると、ビルドルーチンがトリガーされます。
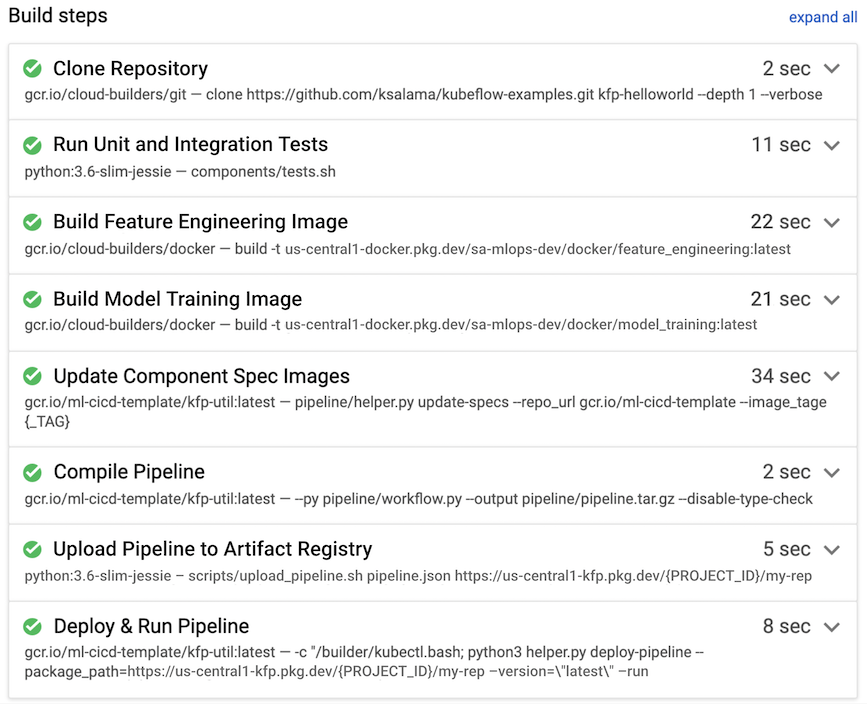
図 8. Cloud Build で実行されるビルドステップの例
通常、Cloud Build は次のビルドステップを実行します。これは図 7 にも示されています。
- ソースコード リポジトリが、Cloud Build ランタイム環境の
/workspaceディレクトリにコピーされます。 - 単体テストと統合テストを実行します。
- 省略可: Pylint などのアナライザを使用して静的コード分析を実行します。
- テストが正常に完了すると、パイプラインのコンポーネントごとに Docker コンテナ イメージが 1 つビルドされます。イメージには
$COMMIT_SHAパラメータがタグ付けされます。 - Docker コンテナ イメージは Artifact Registry にアップロードされます(図 7 を参照)。
- イメージの URL は、
component.yamlファイルで Docker コンテナ イメージが作成されタグ付けされるたびに更新されます。 - パイプライン ワークフローがコンパイルされ、
pipeline.jsonファイルが生成されます。 pipeline.jsonファイルが Artifact Registry にアップロードされます。- 省略可: 統合テストまたは本番環境での実行の一部としてパラメータ値を使用してパイプラインを実行します。実行されたパイプラインによって新しいモデルが生成されます。また Vertex AI Prediction の API としてモデルがデプロイされることもあります。
Cloud Build を使用した CI / CD を含む本番環境対応のエンドツーエンドの MLOps の例については、GitHub の Vertex Pipelines エンドツーエンド サンプルをご覧ください。
その他の考慮事項
Google Cloud で ML CI / CD アーキテクチャを設定する場合は、次の点を考慮してください。
- データ サイエンス環境では、ローカルマシンまたは Vertex AI Workbench を使用できます。
- 自動化された Cloud Build パイプラインは、ドキュメント ファイルのみが編集された場合やテストのノートブックが変更された場合などに、skip triggers に構成できます。
- 統合テストと回帰テスト用のパイプラインはビルドテストとして実行できます。パイプラインをターゲット環境にデプロイする前に、
wait()メソッドを使用して、送信されたパイプラインの実行が完了するまで待機できます。 - Cloud Build を使用する代わりに、Jenkins などの他のビルドシステムを使用することもできます。Jenkins のすぐに使えるデプロイは、Google Cloud Marketplace で使用可能です。
- さまざまなトリガーに基づいて、開発、テスト、ステージングなどのさまざまな環境に自動的にデプロイするようにパイプラインを構成できます。また、通常はリリース承認後に、本番環境移行前や本番環境など、特定の環境に手動でデプロイできます。異なるトリガーやターゲット環境ごとに、複数のビルドルーチンを作成できます。
- 汎用のワークフローとして、一般的なオーケストレーションとスケジューリングのフレームワークである Apache Airflow を使用できます。これは、フルマネージドの Cloud Composer サービスを使用して実行できます。Cloud Composer と Cloud Build でデータ パイプラインをオーケストレートする方法の詳細については、データ処理ワークフロー用の CI / CD パイプラインの設定をご覧ください。
- 新しいバージョンのモデルを本番環境にデプロイする場合は、カナリア リリースとしてデプロイして、パフォーマンス(CPU、メモリ、ディスク使用状況)を確認します。すべてのライブ トラフィックを処理する新しいモデルを構成する前に、A/B テストを実行することもできます。ライブ トラフィックの 10%~20% を提供する新しいモデルを構成します。新しいモデルのパフォーマンスが現在のモデルよりも優れている場合は、すべてのトラフィックを処理するように新しいモデルを構成できます。それ以外の場合、サービス システムは現在のモデルにロールバックします。
次のステップ
- Cloud Build を使用した GitOps スタイルの継続的デリバリーの詳細を見る。
- データ処理ワークフロー用の CI / CD パイプラインの設定の詳細を見る。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
著者:
- Ross Thomson | クラウド ソリューション アーキテクト
- Khalid Salama | スタッフ ソフトウェア エンジニア、ML
その他の寄稿者: Wyatt Gorman | HPC ソリューション マネージャー