Este documento es la segunda parte de una serie sobre la recuperación tras fallos en Google Cloud. En esta sección se describen los servicios y productos que se pueden usar para crear planes de recuperación tras fallos, tanto Google Cloud productos como productos que funcionan en distintas plataformas.
La serie consta de las siguientes partes:
- Guía de planificación para la recuperación tras fallos
- Componentes básicos de recuperación tras fallos (este artículo)
- Situaciones de recuperación tras fallos con los datos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
Google Cloud tiene una amplia gama de productos que puedes usar como parte de tu arquitectura de recuperación ante desastres. En esta sección se describen las funciones relacionadas con la recuperación tras fallos de los productos que se usan con más frecuencia como Google Cloud componentes básicos de la recuperación tras fallos.
Muchos de estos servicios tienen funciones de alta disponibilidad. La alta disponibilidad no se solapa por completo con la recuperación tras fallos, pero muchos de sus objetivos también se aplican al diseño de un plan de recuperación tras fallos. Por ejemplo, si aprovechas las funciones de alta disponibilidad, puedes diseñar arquitecturas que optimicen el tiempo de actividad y que puedan mitigar los efectos de fallos a pequeña escala, como el fallo de una sola máquina virtual. Para obtener más información sobre la relación entre la recuperación tras fallos y la alta disponibilidad, consulta la guía de planificación para la recuperación tras fallos.
En las siguientes secciones se describen estos Google Cloud componentes básicos de recuperación ante desastres y cómo te ayudan a alcanzar tus objetivos de recuperación ante desastres.
Computación y almacenamiento
En la siguiente tabla se resumen las funciones de los Google Cloud servicios de computación y almacenamiento que sirven como elementos de creación para la recuperación ante desastres:
| Producto | Función |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Para obtener más información sobre cómo pueden influir las funciones y el diseño de estos y otros productos en tu estrategia de recuperación tras desastres, consulta el artículo Diseño de la recuperación tras desastres para interrupciones de la infraestructura en la nube: referencia de productos.Google Cloud
Compute Engine
Compute Engine proporciona instancias de máquina virtual (VM) y es el motor de Google Cloud. Además de configurar, iniciar y monitorizar instancias de Compute Engine, normalmente se usan varias funciones relacionadas para implementar un plan de recuperación tras fallos.
En los casos de recuperación ante desastres, puedes evitar que se eliminen máquinas virtuales por error configurando la marca de protección contra la eliminación. Esto resulta especialmente útil cuando alojas servicios con reconocimiento del estado, como bases de datos.
Para obtener información sobre cómo cumplir los valores de RTO y RPO bajos, consulta el artículo Diseñar sistemas resilientes.
Plantillas de instancia
Puedes usar plantillas de instancia de Compute Engine para guardar los detalles de configuración de la VM y, a continuación, crear instancias de Compute Engine a partir de plantillas de instancia. Puedes usar la plantilla para lanzar tantas instancias como necesites, configuradas exactamente como quieras cuando tengas que configurar tu entorno de destino de recuperación ante desastres. Las plantillas de instancia se replican a nivel global, por lo que puedes volver a crear la instancia en cualquier lugar con la misma configuración. Google Cloud
Para obtener más información, consulta los siguientes recursos:
Para obtener más información sobre cómo usar imágenes de Compute Engine, consulta la sección Equilibrio de la configuración de imágenes y la velocidad de implementación más adelante en este documento.
Grupos de instancias administradas
Los grupos de instancias gestionadas funcionan con Cloud Load Balancing (que se explica más adelante en este documento) para distribuir el tráfico a grupos de instancias configuradas de forma idéntica que se copian en diferentes zonas. Los grupos de instancias gestionados permiten usar funciones como el autoescalado y la reparación automática, con las que el grupo de instancias gestionado puede eliminar y volver a crear instancias automáticamente.
Reservas
Compute Engine permite reservar instancias de VM en una zona específica, con tipos de máquinas personalizados o predefinidos, con o sin GPUs o SSD locales adicionales. Para asegurar la capacidad de tus cargas de trabajo críticas para la misión en caso de desastre, debes crear reservas en tus zonas de destino de recuperación ante desastres. Si no haces reservas, es posible que no obtengas la capacidad bajo demanda que necesitas para cumplir tu objetivo de tiempo de recuperación. Las reservas pueden ser útiles en escenarios de recuperación ante desastres con temperaturas frías, cálidas o altas. Te permiten mantener recursos de recuperación disponibles para la conmutación por error y, así, satisfacer las necesidades de RTO más bajas sin tener que configurarlos y desplegarlos por completo con antelación.
Discos persistentes y capturas
Los discos persistentes son dispositivos de almacenamiento en red duraderos a los que pueden acceder tus instancias. Son independientes de tus instancias, por lo que puedes desvincular y mover discos persistentes para conservar los datos aunque hayas eliminado las instancias.
Puedes crear copias de seguridad o capturas incrementales de máquinas virtuales de Compute Engine que puedes copiar entre regiones y usar para recrear discos persistentes en caso de desastre. Además, puedes crear capturas de discos persistentes para protegerte frente a la pérdida de datos por errores de los usuarios. Las capturas son incrementales y se crean en cuestión de minutos, aunque los discos de las capturas estén conectados a instancias en ejecución.
Los discos persistentes tienen redundancia integrada para proteger tus datos frente a fallos de los equipos y para asegurar la disponibilidad de los datos durante los eventos de mantenimiento de los centros de datos. Los discos persistentes pueden ser de zona o regionales. Los discos persistentes regionales replican las escrituras en dos zonas de una región. En caso de interrupción de una zona, una instancia de máquina virtual de copia de seguridad puede vincular de forma forzosa un disco persistente regional en la zona secundaria. Para obtener más información, consulta Opciones de alta disponibilidad con discos persistentes regionales.
Mantenimiento transparente
Google mantiene su infraestructura periódicamente aplicando parches a los sistemas con el software más reciente, realizando pruebas rutinarias y tareas de mantenimiento preventivo, y trabajando para que la infraestructura de Google sea lo más rápida y eficiente posible.
De forma predeterminada, todas las instancias de Compute Engine están configuradas para que estos eventos de mantenimiento sean transparentes para tus aplicaciones y cargas de trabajo. Para obtener más información, consulta Mantenimiento transparente.
Cuando se produce un evento de mantenimiento, Compute Engine usa la migración en tiempo real para migrar automáticamente las instancias en ejecución a otro host de la misma zona. La migración activa permite a Google llevar a cabo el mantenimiento necesario para mantener la infraestructura protegida y fiable sin interrumpir ninguna de tus máquinas virtuales.
Herramienta de importación de discos virtuales
La herramienta de importación de discos virtuales te permite importar formatos de archivo como VMDK, VHD y RAW para crear nuevas máquinas virtuales de Compute Engine. Con esta herramienta, puedes crear máquinas virtuales de Compute Engine que tengan la misma configuración que tus máquinas virtuales locales. Este es un buen enfoque cuando no puedes configurar imágenes de Compute Engine a partir de los archivos binarios de origen del software que ya está instalado en tus imágenes.
Copias de seguridad automáticas
Puedes automatizar las copias de seguridad de tus instancias de Compute Engine mediante etiquetas. Por ejemplo, puedes crear una plantilla de plan de copias de seguridad con el servicio Backup and DR y aplicarla automáticamente a tus instancias de Compute Engine.
Para obtener más información, consulta Automatizar la protección de nuevas instancias de Compute Engine.
Cloud Storage
Cloud Storage es un almacén de objetos ideal para almacenar archivos de copia de seguridad. Ofrece diferentes clases de almacenamiento que se adaptan a casos prácticos específicos, como se indica en el siguiente diagrama.

En los casos de recuperación ante desastres, las clases Nearline, Coldline y Archive Storage son especialmente interesantes. Estas clases de almacenamiento reducen el coste de almacenamiento en comparación con el almacenamiento estándar. Sin embargo, se aplican otros cargos si recuperas datos o metadatos almacenados en estas clases. También se aplica un cargo por tiempo mínimo de almacenamiento. Nearline se ha diseñado para situaciones de copia de seguridad en las que se accede a los datos como máximo una vez al mes, lo que resulta ideal para realizar pruebas de estrés de recuperación ante desastres periódicas y, al mismo tiempo, mantener los costes bajos.
Las clases Nearline, Coldline y Archive están optimizadas para el acceso poco frecuente, y el modelo de precios se ha diseñado teniendo esto en cuenta. Por lo tanto, se te cobra por los tiempos mínimos de almacenamiento y se aplican cargos adicionales por recuperar datos o metadatos de estas clases antes del tiempo mínimo de almacenamiento de la clase.
Para proteger los datos de un segmento de Cloud Storage frente a eliminaciones accidentales o maliciosas, puedes usar la función Eliminación no definitiva para conservar los objetos eliminados y sobrescritos durante un periodo específico, así como la función Retenciones de objetos para evitar que se eliminen o actualicen objetos.
Servicio de transferencia de Storage te permite importar datos de Amazon S3, Azure Blob Storage o fuentes de datos on-premise a Cloud Storage. En situaciones de recuperación ante desastres, puede usar el Servicio de transferencia de Storage para lo siguiente:
- Crea copias de seguridad de datos de otros proveedores de almacenamiento en un segmento de Cloud Storage.
- Mueve datos de un segmento de una región dual o multirregión a un segmento de una región para reducir los costes de almacenamiento de copias de seguridad.
Filestore
Las instancias de Filestore son servidores de archivos NFS totalmente gestionados que se usan con las aplicaciones que se ejecutan en instancias de Compute Engine o en clústeres de GKE.
Los niveles Basic y Zonal de Filestore son recursos zonales y no admiten la replicación entre zonas, mientras que las instancias del nivel Enterprise de Filestore son recursos regionales. Para ayudarte a aumentar la resiliencia de tu entorno de Filestore, te recomendamos que uses instancias de nivel Enterprise.
Google Kubernetes Engine
GKE es un entorno gestionado y listo para producción, diseñado para desplegar aplicaciones en contenedores. GKE te permite orquestar sistemas de alta disponibilidad e incluye las siguientes funciones:
- Reparación automática de nodos. Si un nodo no supera comprobaciones del estado consecutivas durante un periodo prolongado (aproximadamente 10 minutos), GKE inicia un proceso de reparación del nodo en cuestión.
- Comprobaciones de actividad y preparación. Puedes especificar una sonda de actividad, que indica periódicamente a GKE que el pod está en ejecución. Si el pod no supera la prueba, se puede reiniciar.
- Clústeres multizona y regionales. Puedes distribuir recursos de Kubernetes en varias zonas de una región.
- Multi-cluster Gateway te permite configurar recursos de balanceo de carga compartidos en varios clústeres de GKE de diferentes regiones.
- Copia de seguridad de GKE te permite crear copias de seguridad de las cargas de trabajo en clústeres de GKE y restaurarlas.
Redes y transferencia de datos
En la siguiente tabla se resumen las funciones de los servicios de redes y de transferencia de datos que sirven como componentes básicos para la recuperación ante desastres: Google Cloud
| Producto | Función |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing proporciona alta disponibilidad a los productos de computación Google Cloud distribuyendo el tráfico de usuarios entre varias instancias de tus aplicaciones. Puede configurar Cloud Load Balancing con comprobaciones de estado para determinar si las instancias están disponibles para realizar el trabajo, de modo que el tráfico no se dirija a las instancias que fallan.
Cloud Load Balancing proporciona una única dirección IP anycast para el frontend de tus aplicaciones. Tus aplicaciones pueden tener instancias que se ejecuten en diferentes regiones (por ejemplo, en Europa y en EE. UU.), y tus usuarios finales se dirigen al conjunto de instancias más cercano. Además de proporcionar balanceo de carga para los servicios expuestos a Internet, puedes configurar el balanceo de carga interno para tus servicios con una dirección IP de balanceo de carga privada. Solo pueden acceder a esta dirección IP las instancias de VM internas de tu nube privada virtual (VPC).
Para obtener más información, consulta la información general sobre Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh es una malla de servicios gestionada por Google que está disponible en Google Cloud. Cloud Service Mesh proporciona telemetría detallada para ayudarte a obtener información valiosa sobre tus aplicaciones. Admite servicios que se ejecutan en una amplia gama de infraestructuras informáticas.
Cloud Service Mesh también admite funciones avanzadas de gestión del tráfico y de enrutamiento, como la interrupción de circuitos y la inyección de errores. Con la interrupción de circuitos, puedes aplicar límites a las solicitudes de un servicio concreto. Cuando se alcanzan los límites de interrupción de circuitos, se impide que las solicitudes lleguen al servicio, lo que evita que este se deteriore aún más. Con la inyección de errores, Cloud Service Mesh puede introducir retrasos o abortar una fracción de las solicitudes a un servicio. La inyección de fallos te permite probar la capacidad de tu servicio para resistir retrasos o cancelaciones de solicitudes.
Para obtener más información, consulta la información general sobre Cloud Service Mesh.
Cloud DNS
Cloud DNS ofrece una forma programática de gestionar tus entradas DNS como parte de un proceso de recuperación automatizado. Cloud DNS utiliza la red mundial de servidores de nombres Anycast de Google para distribuir tus zonas DNS desde ubicaciones redundantes de todo el mundo, lo que te permite ofrecer alta disponibilidad y baja latencia a tus usuarios.
Si has elegido gestionar las entradas DNS de forma local, puedes habilitar las VMs en Google Cloud para que resuelvan estas direcciones mediante el reenvío de Cloud DNS.
Cloud DNS admite políticas para configurar cómo responde a las solicitudes de DNS. Por ejemplo, puedes configurar políticas de enrutamiento de DNS para dirigir el tráfico en función de criterios específicos, como habilitar la conmutación por error a una configuración de copia de seguridad para proporcionar alta disponibilidad o enrutar las solicitudes de DNS en función de su ubicación geográfica.
Cloud Interconnect
Cloud Interconnect ofrece formas de mover información de otras fuentes a Google Cloud. Hablaremos de este producto más adelante en la sección Transferir datos a y desde Google Cloud.
Gestión y monitorización
En la siguiente tabla se resumen las funciones de los servicios de gestión y monitorización que sirven como elementos de creación para la recuperación ante desastres: Google Cloud
| Producto | Función |
|---|---|
| Panel de Estado de Cloud |
|
| Google Cloud Observability |
|
| Servicio gestionado de Google Cloud para Prometheus |
|
Panel de Estado de Cloud
En el panel de estado de Cloud se muestra la disponibilidad actual de los servicios de Google Cloud . Puedes consultar el estado en la página y suscribirte a un feed RSS que se actualiza cada vez que hay novedades sobre un servicio.
Cloud Monitoring
Cloud Monitoring recoge métricas, eventos y metadatos de Google Cloud, AWS, comprobaciones de tiempo de funcionamiento alojadas, instrumentación de aplicaciones y otros componentes de aplicaciones. Puedes configurar las alertas para que envíen notificaciones a herramientas de terceros, como Slack o PagerDuty, y así proporcionar información actualizada a los administradores.
Cloud Monitoring te permite crear comprobaciones de disponibilidad del servicio para endpoints disponibles públicamente y para endpoints de tus VPCs. Por ejemplo, puedes monitorizar URLs, instancias de Compute Engine, revisiones de Cloud Run y recursos de terceros, como instancias de Amazon Elastic Compute Cloud (EC2).
Servicio gestionado de Google Cloud para Prometheus
Google Cloud Managed Service para Prometheus es una solución multicloud y entre proyectos gestionada por Google para métricas de Prometheus. Te permite monitorizar y recibir alertas a nivel global sobre tus cargas de trabajo con Prometheus, sin tener que gestionarlo ni usarlo manualmente a gran escala.
Para obtener más información, consulta Google Cloud Managed Service para Prometheus.
Componentes básicos de recuperación tras desastres multiplataforma
Cuando ejecutas cargas de trabajo en más de una plataforma, una forma de reducir la sobrecarga operativa es seleccionar herramientas que funcionen con todas las plataformas que utilices. En esta sección se describen algunas herramientas y servicios que son independientes de la plataforma y, por lo tanto, admiten escenarios de recuperación ante desastres multiplataforma.
Infraestructura como código
Si defines tu infraestructura mediante código en lugar de con interfaces gráficas o secuencias de comandos, puedes adoptar herramientas de plantillas declarativas y automatizar el aprovisionamiento y la configuración de la infraestructura en diferentes plataformas. Por ejemplo, puedes usar Terraform e Infrastructure Manager para activar tu configuración de infraestructura declarativa.
Herramientas de gestión de la configuración
En el caso de las infraestructuras de recuperación ante desastres grandes o complejas, recomendamos herramientas de gestión de software independientes de la plataforma, como Chef y Ansible. Estas herramientas aseguran que se puedan aplicar configuraciones reproducibles independientemente de dónde se encuentre tu carga de trabajo de computación.
Herramientas de orquestación
Los contenedores también se pueden considerar un componente básico de la recuperación ante desastres. Los contenedores son una forma de empaquetar servicios y ofrecer coherencia en todas las plataformas.
Si trabajas con contenedores, normalmente usas un orquestador. Kubernetes no solo gestiona los contenedores en Google Cloud (con GKE), sino que también ofrece una forma de orquestar cargas de trabajo basadas en contenedores en varias plataformas. Google Cloud, AWS y Microsoft Azure ofrecen versiones gestionadas de Kubernetes.
Para distribuir el tráfico a clústeres de Kubernetes que se ejecutan en diferentes plataformas en la nube, puedes usar un servicio DNS que admita registros ponderados e incorpore comprobaciones de estado.
También debes asegurarte de que puedes extraer la imagen al entorno de destino. Esto significa que debes poder acceder a tu registro de imágenes en caso de desastre. Una buena opción que también es independiente de la plataforma es Artifact Registry.
Transferencia de datos
La transferencia de datos es un componente fundamental de las situaciones de recuperación tras desastres entre plataformas. Asegúrate de diseñar, implementar y probar tus escenarios de recuperación ante desastres multiplataforma con simulaciones realistas de lo que requiere el escenario de transferencia de datos de recuperación ante desastres. En la siguiente sección se describen los escenarios de transferencia de datos.
Servicio de copia de seguridad y DR
El servicio de copia de seguridad y recuperación tras fallos es una solución de copia de seguridad y recuperación tras fallos para cargas de trabajo en la nube. Te ayuda a recuperar datos y reanudar operaciones empresariales críticas, y es compatible con variosGoogle Cloud productos, bases de datos de terceros y sistemas de almacenamiento de datos.
Para obtener más información, consulta la descripción general del servicio de copia de seguridad y recuperación ante desastres.
Patrones de recuperación ante desastres
En esta sección se describen algunos de los patrones más habituales de arquitecturas de recuperación ante desastres basados en los componentes que hemos analizado anteriormente.
Transferir datos a y desde Google Cloud
Un aspecto importante de tu plan de recuperación ante desastres es la rapidez con la que se pueden transferir datos a y desde Google Cloud. Esto es fundamental si tu plan de recuperación ante desastres se basa en mover datos de un entorno local a Google Cloud o de otro proveedor de servicios en la nube a Google Cloud. En esta sección se habla de las redes y losGoogle Cloud servicios que pueden asegurar un buen rendimiento.
Si utilizas Google Cloud como sitio de recuperación de cargas de trabajo que se encuentran en un entorno local o en otra nube, ten en cuenta los siguientes aspectos clave:
- ¿Cómo te conectas a Google Cloud?
- ¿Cuánto ancho de banda hay entre usted y el proveedor de interconexión?
- ¿Cuál es el ancho de banda que proporciona el proveedor directamente a Google Cloud?
- ¿Qué otros datos se transferirán mediante ese enlace?
Para obtener más información sobre cómo transferir datos a Google Cloud, consulta el artículo Migrar a Google Cloud: transferir conjuntos de datos grandes.
Equilibrar la configuración de imágenes y la velocidad de implementación
Cuando configures una imagen de máquina para desplegar nuevas instancias, ten en cuenta el efecto que tendrá tu configuración en la velocidad de despliegue. Hay un equilibrio entre la cantidad de preconfiguración de la imagen, los costes de mantenimiento de la imagen y la velocidad de implementación. Por ejemplo, si una imagen de máquina tiene una configuración mínima, las instancias que la usen tardarán más en iniciarse, ya que tendrán que descargar e instalar dependencias. Por otro lado, si tu imagen de máquina está muy configurada, las instancias que la usen se iniciarán más rápido, pero tendrás que actualizar la imagen con más frecuencia. El tiempo que se tarda en lanzar una instancia totalmente operativa está directamente relacionado con el RTO.
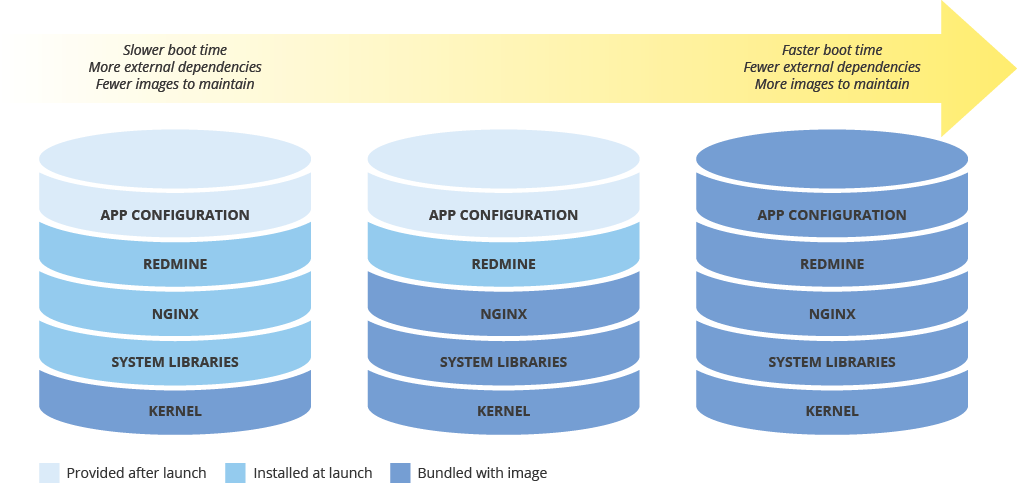
Mantener la coherencia de las imágenes de máquina en entornos híbridos
Si implementas una solución híbrida (on-premise a la nube o de nube a nube), debes encontrar una forma de mantener la coherencia de las imágenes en los entornos de producción.
Si necesitas una imagen totalmente configurada, puedes usar Packer, que puede crear imágenes de máquina idénticas para varias plataformas. Puedes usar los mismos scripts con archivos de configuración específicos de la plataforma. En el caso de Packer, puedes poner el archivo de configuración en el control de versiones para hacer un seguimiento de la versión que se ha desplegado en producción.
También puedes usar herramientas de gestión de la configuración, como Chef, Puppet, Ansible o Saltstack, para configurar instancias con mayor granularidad, crear imágenes base, imágenes mínimamente configuradas o imágenes totalmente configuradas según sea necesario.
También puedes convertir e importar manualmente imágenes, como imágenes AMI de Amazon, imágenes de VirtualBox e imágenes de disco RAW, a Compute Engine.
Implementar el almacenamiento por niveles
El patrón de almacenamiento por niveles se suele usar para las copias de seguridad, donde la copia de seguridad más reciente se encuentra en un almacenamiento más rápido y las copias de seguridad más antiguas se migran lentamente a un almacenamiento más lento, pero más económico. Al aplicar este patrón, migras copias de seguridad entre segmentos de diferentes clases de almacenamiento, normalmente de Estándar a clases de almacenamiento de menor coste, como Nearline y Coldline.
Para implementar este patrón, puedes usar la gestión del ciclo de vida de los objetos. Por ejemplo, puedes cambiar automáticamente la clase de almacenamiento de los objetos que tengan más de un tiempo determinado a Coldline.
Siguientes pasos
- Consulta información sobre Google Cloud geografía y regiones.
Lee otros artículos de esta serie sobre la recuperación ante desastres:
- Guía de planificación para la recuperación tras fallos
- Situaciones de recuperación tras fallos con los datos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
Colaboradores
Autores:
- Grace Mollison | Responsable de soluciones
- Marco Ferrari | Arquitecto de soluciones en la nube