本页面介绍了如何在 Cloud Run 中将 NFS 文件共享作为卷装载。您可以使用任何 NFS 服务器,包括在本地或 Compute Engine 虚拟机上托管的您自己的 NFS 服务器。如果您还没有 NFS 服务器,我们建议您使用 Filestore,这是 Google Cloud提供的全托管式 NFS 产品。
在 Cloud Run 中将 NFS 文件共享作为卷进行装载会将文件共享以文件的形式呈现在容器文件系统中。将文件共享作为卷装载后,您可以使用编程语言的文件系统操作和库来访问该文件共享,就像访问本地文件系统上的目录一样。
不允许的路径
Cloud Run 不允许您将卷装载到 /dev、/proc 或 /sys,以及它们的子目录。
限制
如需将数据写入 NFS 卷,容器必须以根用户身份运行。如果容器仅从文件系统中读取数据,则可以以任何用户身份运行。
Cloud Run 不支持 NFS 锁定。NFS 卷会自动以无锁定模式装载。
准备工作
如需在 Cloud Run 中将 NFS 服务器作为卷装载,请确保您满足以下条件:
- 运行 NFS 服务器或 Filestore 实例的 VPC 网络。
- 在 VPC 网络中运行的 NFS 服务器,以及与该 VPC 网络连接的 Cloud Run 服务。如果您还没有 NFS 服务器,请通过创建 Filestore 实例来创建一个。
- Cloud Run 服务已连接到运行 NFS 服务器的 VPC 网络。如需获得最佳性能,请使用直接 VPC,而不是 VPC 连接器。
- 如果您使用的是现有项目,请确保 VPC 防火墙配置允许 Cloud Run 访问 NFS 服务器。(如果您从新项目开始,则默认为如此。)如果您使用 Filestore 作为 NFS 服务器,请按照 Filestore 文档创建防火墙出站流量规则,以便 Cloud Run 可以访问 Filestore。
所需的角色
如需获得配置和部署 Cloud Run 服务所需的权限,请让您的管理员为您授予服务的以下 IAM 角色:
-
Cloud Run Developer (
roles/run.developer) - Cloud Run 服务 -
Service Account User (
roles/iam.serviceAccountUser) - 服务身份
如果您要从源代码部署服务或函数,则还必须向您授予项目和 Cloud Build 服务账号的其他角色。
如需查看与 Cloud Run 关联的 IAM 角色和权限的列表,请参阅 Cloud Run IAM 角色和 Cloud Run IAM 权限。如果您的 Cloud Run 服务与Google Cloud API(例如 Cloud 客户端库)进行交互,请参阅服务身份配置指南。如需详细了解如何授予角色,请参阅部署权限和管理访问权限。
装载 NFS 卷
您可以在不同的装载路径中装载多个 NFS 服务器、Filestore 实例或其他卷类型。
如果您使用多个容器,请先指定卷,然后为每个容器指定卷装载。
控制台
在 Google Cloud 控制台中,前往 Cloud Run:
从菜单中选择服务,然后点击部署容器以配置新服务。如果您要配置现有服务,请点击该服务,然后点击修改和部署新的修订版本。
如果您要配置新服务,请填写初始服务设置页面,然后点击容器、卷、网络、安全性以展开服务配置页面。
点击卷标签页。
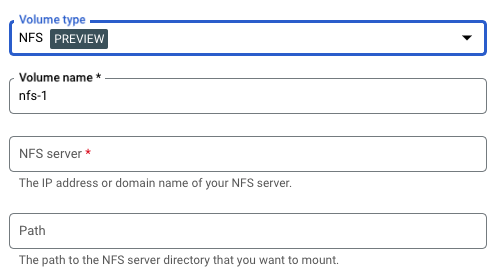
- 在卷下:
- 点击添加卷。
- 在卷类型下拉列表中,选择 NFS 作为卷类型。
- 在卷名称字段中,输入要用于卷的名称。
- 在 NFS 服务器字段中,输入 NFS 文件共享的域名或位置(采用
IP_ADDRESS格式)。 - 在路径字段中,输入您要装载的 NFS 服务器目录的路径。
- 点击完成。
- 点击“容器”标签页,然后展开要将卷装载到的容器,以修改该容器。
- 点击卷装载标签页。
- 点击装载卷。
- 从菜单中选择 NFS 卷。
- 指定您要用于装载卷的路径。
- 点击装载卷
- 在卷下:
点击创建或部署。
gcloud
如需添加卷并装载,请运行以下命令:
gcloud run services update SERVICE \ --add-volume=name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --add-volume-mount=volume=VOLUME_NAME,mount-path=MOUNT_PATH
您需要进行如下替换:
- 将 SERVICE 替换为您的服务名称。
- 将 VOLUME_NAME 替换为您要为卷指定的名称。
- 将 IP_ADDRESS 替换为 NFS 文件共享的位置。
- 将 NFS_PATH 替换为 NFS 文件共享的路径,以正斜杠开头,例如
/example-directory。 - 将 MOUNT_PATH 替换为您用于装载卷的相对路径,例如
/mnt/my-volume。 - 将 VOLUME_NAME 替换为您要用于卷的任何名称。VOLUME_NAME 值用于将卷映射到卷装载。
如需将卷装载为只读卷,请运行以下命令:
--add-volume=name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH,readonly=true
如果您使用多个容器,请先指定卷,然后为每个容器指定卷装载:
gcloud run services update SERVICE \ --add-volume=name VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --container CONTAINER_1 \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH \ --container CONTAINER_2 \ --add-volume-mount volume= VOLUME_NAME,mount-path=MOUNT_PATH2
YAML
如果您要创建新的服务,请跳过此步骤。如果您要更新现有服务,请下载其 YAML 配置:
gcloud run services describe SERVICE --format export > service.yaml
根据需要更新 MOUNT_PATH、VOLUME_NAME、IP_ADDRESS 和 NFS_PATH。如果您有多个卷装载,则会拥有多个此类属性。
apiVersion: run.googleapis.com/v1 kind: Service metadata: name: SERVICE spec: template: metadata: annotations: run.googleapis.com/execution-environment: gen2 spec: containers: - image: IMAGE_URL volumeMounts: - name: VOLUME_NAME mountPath: MOUNT_PATH volumes: - name: VOLUME_NAME nfs: server: IP_ADDRESS path: NFS_PATH readOnly: IS_READ_ONLY
您需要进行如下替换
- 将 SERVICE 替换为您的 Cloud Run 服务的名称
- 将 MOUNT_PATH 替换为您用于装载卷的相对路径,例如
/mnt/my-volume。 - 将 VOLUME_NAME 替换为您要用于卷的任何名称。VOLUME_NAME 值用于将卷映射到卷装载。
- 将 IP_ADDRESS 替换为 NFS 文件共享的地址。
- 将 NFS_PATH 替换为 NFS 文件共享的路径,以正斜杠开头,例如
/example-directory。 - 将 IS_READ_ONLY 替换为
True以将卷设为只读,或替换为False以允许写入。
使用以下命令创建或更新服务:
gcloud run services replace service.yaml
Terraform
如需了解如何应用或移除 Terraform 配置,请参阅基本 Terraform 命令。
将以下内容添加到 Terraform 配置中的google_cloud_run_v2_service 资源:resource "google_cloud_run_v2_service" "default" {
name = "SERVICE"
location = "REGION"
template {
execution_environment = "EXECUTION_ENVIRONMENT_GEN2"
containers {
image = "us-docker.pkg.dev/cloudrun/container/hello"
volume_mounts {
name = "VOLUME_NAME"
mount_path = "MOUNT_PATH"
}
}
vpc_access {
network_interfaces {
network = "default"
subnetwork = "default"
}
}
volumes {
name = "VOLUME_NAME"
nfs {
server = google_filestore_instance.default.networks[0].ip_addresses[0]
path = "NFS_PATH"
read_only = IS_READ_ONLY
}
}
}
}
resource "google_filestore_instance" "default" {
name = "cloudrun-service-ro"
location = "REGION"
tier = "BASIC_HDD"
file_shares {
capacity_gb = 1024
name = "share1"
}
networks {
network = "default"
modes = ["MODE_IPV4"]
}
}
您需要进行如下替换:
- 将 SERVICE 替换为您的 Cloud Run 服务的名称。
- 将 REGION 替换为 Google Cloud 区域。 例如
europe-west1。 - 将 MOUNT_PATH 替换为您用于装载卷的相对路径,例如
/mnt/nfs/filestore。 - 将 VOLUME_NAME 替换为您要用于卷的任何名称。VOLUME_NAME 值用于将卷映射到卷装载。
- 将 NFS_PATH 替换为 NFS 文件共享的路径,以正斜杠开头,例如
/share1。 - 将 IS_READ_ONLY 替换为
True以将卷设为只读,或替换为False以允许写入。
读取和写入卷
如果您使用 Cloud Run 卷装载功能,则可以使用编程语言中用于在本地文件系统上读写文件的相同库来访问已装载的卷。
如果您使用的是期望数据存储在本地文件系统中并使用常规文件系统操作来访问数据的现有容器,此方法会特别有用。
以下代码段假定一个 mountPath 设置为 /mnt/my-volume 的卷装载。
Nodejs
使用文件系统模块创建新文件或附加到卷 /mnt/my-volume 中的现有文件:
var fs = require('fs');
fs.appendFileSync('/mnt/my-volume/sample-logfile.txt', 'Hello logs!', { flag: 'a+' });Python
写入保存在卷 /mnt/my-volume 中的文件:
f = open("/mnt/my-volume/sample-logfile.txt", "a")Go
使用 os 软件包创建一个保存在卷 /mnt/my-volume 中的新文件:
f, err := os.Create("/mnt/my-volume/sample-logfile.txt")Java
使用 Java.io.File 类在卷 /mnt/my-volume 中创建日志文件:
import java.io.File;
File f = new File("/mnt/my-volume/sample-logfile.txt");排查 NFS 问题
如果您遇到问题,请检查以下各项:
- 您的 Cloud Run 服务已连接到 NFS 服务器所在的 VPC 网络。
- 没有防火墙规则阻止 Cloud Run 访问 NFS 服务器。
- 如果您的容器将数据写入 NFS 服务器,请确保它以根用户身份运行。
容器启动时间和 NFS 卷装载
使用 NFS 卷装载可能会略微增加 Cloud Run 容器的冷启动时间,因为卷装载是在启动容器之前启动的。只有在 NFS 成功装载后,容器才会启动。
请注意,只有在与服务器建立连接并提取文件句柄后,NFS 才会成功装载卷。如果 Cloud Run 无法与服务器建立连接,则 Cloud Run 服务将无法启动。
此外,由于 Cloud Run 执行所有装载操作的总超时时间为 30 秒,任何网络延迟都可能影响容器的启动时间。如果 NFS 的装载时间超过 30 秒,Cloud Run 服务将无法启动。
NFS 性能特性
如果您创建多个 NFS 卷,则所有卷都会并行装载。
由于 NFS 是网络文件系统,因此受带宽限制,并且对文件系统的访问可能会受到带宽限制的影响。
写入 NFS 卷时,写入内容将存储在 Cloud Run 内存中,直到数据被清空。在以下情况下会清空数据:
- 您的应用使用 sync(2)、msync(2) 或 fsync(3) 显式清空文件数据。
- 您的应用使用 close(2) 关闭文件。
- 内存压力会强制回收系统内存资源。
如需了解详情,请参阅 Linux 上的 NFS 文档。
清除并移除卷和卷装载
您可以清除所有卷和卷装载,也可以移除个别卷和卷装载。
清除所有卷和卷装载
如需从单容器服务中清除所有卷和卷装载,请运行以下命令:
gcloud run services update SERVICE \ --clear-volumes --clear-volume-mounts
如果您有多个容器,请遵循边车 CLI 惯例来清除卷和卷装载:
gcloud run services update SERVICE \ --container=container1 \ --clear-volumes -–clear-volume-mounts \ --container=container2 \ --clear-volumes \ -–clear-volume-mounts
移除个别卷和卷装载
如需移除某个卷,您还必须移除使用该卷的所有卷装载。
如需移除个别卷或卷装载,请使用 remove-volume 和 remove-volume-mount 标志:
gcloud run services update SERVICE \ --remove-volume VOLUME_NAME \ --container=container1 \ --remove-volume-mount MOUNT_PATH \ --container=container2 \ --remove-volume-mount MOUNT_PATH