Nach dem Training eines Modells verwendet AutoML Natural Language Dokumente aus dem TEST-Set für die Bewertung der Qualität und Genauigkeit des neuen Modells.
AutoML Natural Language bietet eine ganze Reihe von Bewertungsmesswerten. Sie geben an, wie gut das Modell insgesamt funktioniert. Auch für jedes Kategorie-Label gibt es Bewertungsmesswerte. Sie geben an, wie gut das Modell für das jeweilige Label funktioniert.
Mit Genauigkeit und Trefferquote wird gemessen, wie gut das Modell Informationen erfasst und wie viele es auslässt. Die Genauigkeit gibt an, wie viele der Dokumente, die als eine bestimmte Entität oder ein bestimmtes Label identifiziert wurden, auch tatsächlich dieser Entität oder diesem Label zugeordnet werden sollten. Die Trefferquote gibt an, wie viele der Dokumente, die als eine bestimmte Entität oder ein bestimmtes Label identifiziert werden sollten, auch tatsächlich dieser Entität oder diesem Label zugeordnet wurden.
Die Wahrheitsmatrix (nur für Modelle mit einem Label pro Dokument vorhanden) stellt in Prozent dar, wie oft jedes Label während der Bewertung im Trainings-Dataset vorhergesagt wurde. Idealerweise würde das Label one nur Dokumenten zugewiesen werden, die als Label one usw. klassifiziert wurden, sodass eine perfekte Matrix so aussähe:
100 0 0 0
0 100 0 0
0 0 100 0
0 0 0 100
Wenn im obigen Beispiel ein Dokument als one klassifiziert wurde, das Modell jedoch two vorhergesagt hat, würde die erste Zeile stattdessen so aussehen:
99 1 0 0
AutoML Natural Language erstellt die Wahrheitsmatrix für bis zu zehn Labels. Wenn Sie mehr als zehn Labels haben, enthält die Matrix die zehn Labels mit der höchsten Konfusion (falsche Vorhersagen).
Für Sentimentmodelle:
Der mittlere absolute Fehler (mean absolute error, MAE) und der mittlere quadratische Fehler (mean squared error, MSE) messen die Abweichung zwischen dem vorhergesagten Sentimentwert und dem tatsächlichen Sentimentwert. Niedrigere Werte deuten auf genauere Modelle hin.
Der linear gewichtete Kappa-Wert und quadratisch gewichtete Kappa-Wert messen, wie genau die vom Modell zugewiesenen Sentimentwerte mit den von menschlichen Beurteilern zugewiesenen Werten übereinstimmen. Höhere Werte deuten auf genauere Modelle hin.
Verwenden Sie diese Messwerte, um die Bereitschaft Ihres Modells zu bewerten. Geringe Genauigkeits- oder Trefferquotenwerte können darauf hinweisen, dass das Modell zusätzliche Trainingsdaten benötigt oder inkonsistente Annotationen enthält. Eine perfekte Genauigkeit und Trefferquote können darauf hindeuten, dass die Daten zu einfach sind und sich unter Umständen nicht gut verallgemeinern lassen. Im Leitfaden für Anfänger finden Sie weitere Tipps zur Bewertung von Modellen.
Wenn Sie mit dem Qualitätsniveau nicht zufrieden sind, können Sie zu den vorherigen Schritten zurückkehren, um die Qualität zu verbessern:
- Erwägen Sie, allen Labels mit geringer Qualität weitere Dokumente hinzuzufügen.
- Möglicherweise müssen Sie verschiedene Arten von Dokumenten hinzufügen, beispielsweise längere oder kürzere Dokumente bzw. Dokumente von verschiedenen Autoren, die unterschiedliche Formulierungen oder Stile verwenden.
- Sie können Labels bereinigen.
- Entfernen Sie Labels unter Umständen vollständig, wenn Sie nicht genügend Trainingsdokumente haben.
Nachdem Sie Änderungen vorgenommen haben, trainieren und bewerten Sie ein neues Modell, bis Sie ein ausreichend hohes Qualitätsniveau erreicht haben.
Web-UI
So prüfen Sie die Bewertungsmesswerte für Ihr Modell:
Klicken Sie auf das Glühbirnensymbol in der linken Navigationsleiste, um die verfügbaren Modelle aufzurufen.
Wählen Sie zum Anzeigen der Modelle für ein anderes Projekt das Projekt in der Dropdown-Liste oben rechts in der Titelleiste aus.
Klicken Sie auf die Zeile für das Modell, das Sie bewerten möchten.
Klicken Sie ggf. unterhalb der Titelleiste auf den Tab Bewerten.
Wenn das Training für das Modell abgeschlossen wurde, werden die Bewertungskriterien von AutoML Natural Language angezeigt.
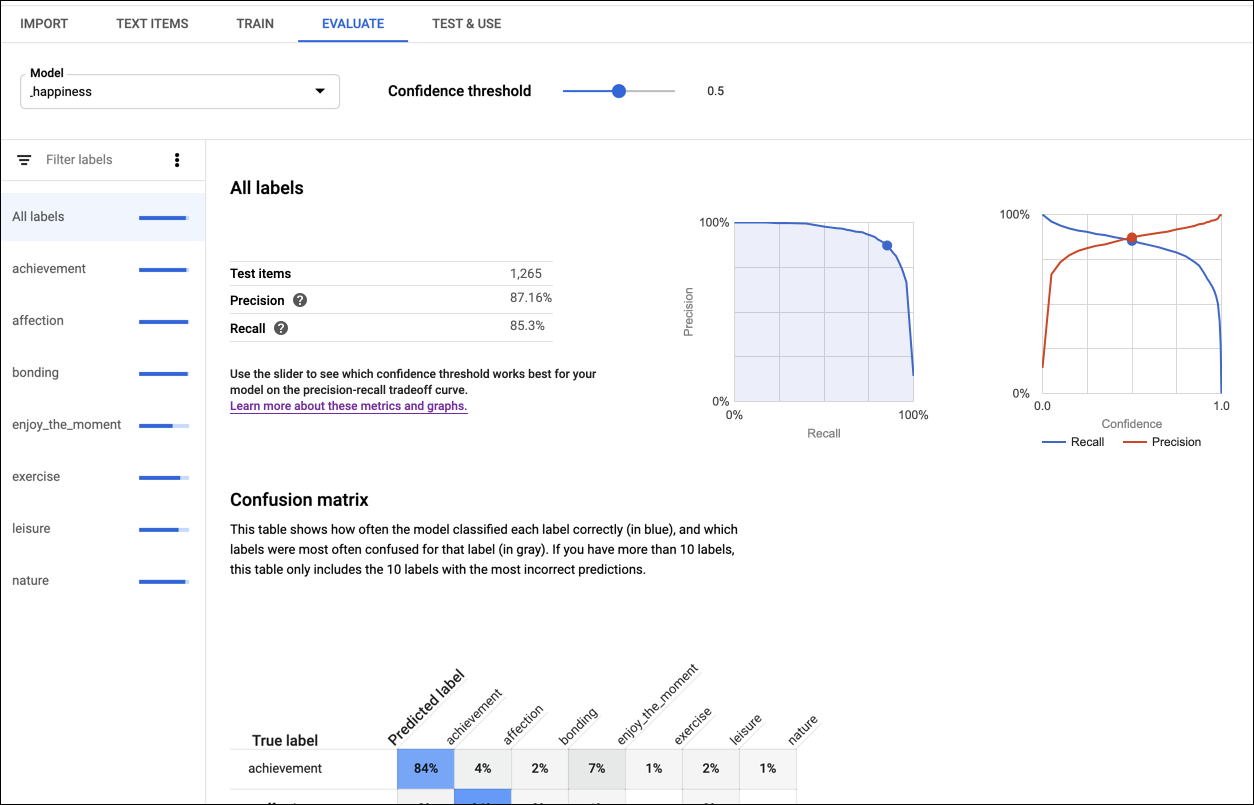
Wählen Sie unten auf der Seite in der Liste der Labels den Label-Namen aus, um Messwerte für ein bestimmtes Label anzeigen zu lassen.
Codebeispiele
Mit den Beispielen wird das Modell als Ganzes bewertet. Sie können auch mithilfe einer Bewertungs-ID die Messwerte für ein bestimmtes Label abrufen (displayName).
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: Ihre Projekt-ID
- location-id: Der Standort für die Ressource,
us-central1für den globalen Standort odereufür die EU - model-id: Ihre Modell-ID
HTTP-Methode und URL:
GET https://automl.googleapis.com/v1/projects/project-id/locations/location-id/models/model-id/modelEvaluations
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{
"modelEvaluation": [
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603448",
"annotationSpecId": "17040929661974749",
"classificationMetrics": {
"auPrc": 0.99772006,
"baseAuPrc": 0.21706384,
"evaluatedExamplesCount": 377,
"confidenceMetricsEntry": [
{
"recall": 1,
"precision": -1.3877788e-17,
"f1Score": -2.7755576e-17,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.05,
"recall": 0.997,
"precision": 0.867,
"f1Score": 0.92746675,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.1,
"recall": 0.995,
"precision": 0.905,
"f1Score": 0.9478684,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.15,
"recall": 0.992,
"precision": 0.932,
"f1Score": 0.96106446,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.2,
"recall": 0.989,
"precision": 0.951,
"f1Score": 0.96962786,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.25,
"recall": 0.987,
"precision": 0.957,
"f1Score": 0.9717685,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
...
],
},
"createTime": "2018-04-30T23:06:14.746840Z"
},
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603671",
"annotationSpecId": "1258823357545045636",
"classificationMetrics": {
"auPrc": 0.9972302,
"baseAuPrc": 0.1883289,
...
},
"createTime": "2018-04-30T23:06:14.649260Z"
}
]
}
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Python API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Java API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Node.js API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Go API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Bitte folgen Sie der Anleitung für die Einrichtung von C# auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für .NET
PHP: Bitte folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für PHP
Ruby: Bitte folgen Sie der Anleitung für die Einrichtung von Ruby auf der Seite „Clientbibliotheken“ und rufen Sie dann die AutoML Natural Language-Referenzdokumentation für Ruby