Einführung
Stellen Sie sich vor, Ihr Unternehmen hat ein Kontaktformular auf seiner Website. Jeden Tag erhalten Sie viele Nachrichten über das Formular, von denen viele leicht umsetzbar sind. Sie kommen aber alle auf einmal und man gerät leicht ins Hintertreffen, da die verschiedenen Nachrichtentypen von verschiedenen Mitarbeitern abgearbeitet werden. Wäre es nicht toll, wenn ein automatisiertes System sie kategorisieren könnte, damit die richtige Person die richtigen Kommentare sieht?
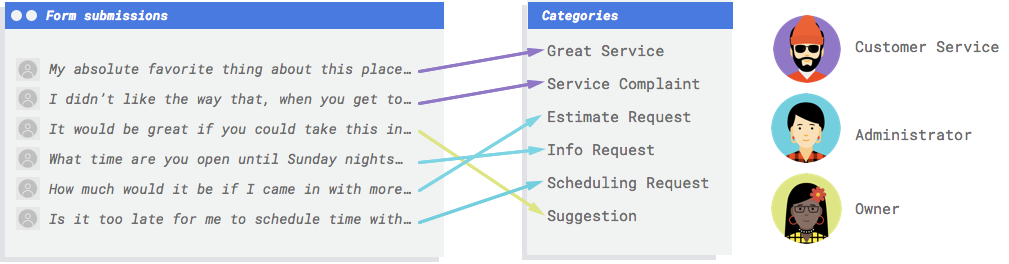
Sie brauchen ein System, das die Kommentare lesen und entscheiden kann, ob es Beschwerden sind, Lob für vergangene Dienste oder ein Versuch, mehr über Ihr Unternehmen zu erfahren, einen Termin zu vereinbaren oder eine Beziehung aufzubauen.
Warum ist maschinelles Lernen (ML) das richtige Werkzeug für dieses Problem?
 Bei der klassischen Programmierung muss der Programmierer dem Computer jeden Arbeitsschritt explizit vorgeben. Dieser Ansatz ist jedoch schnell unmöglich. Kundenkommentare verwenden ein breites und vielfältiges Vokabular und eine Struktur – zu vielfältig, um von einem einfachen Regelsatz erfasst zu werden. Wenn Sie versucht haben, manuelle Filter zu erstellen, werden Sie schnell feststellen, dass Sie den Großteil Ihrer Kundenkommentare nicht kategorisieren konnten. Du brauchst ein System, das eine Vielzahl von Kommentaren verallgemeinern kann.
In einem Szenario, in dem eine Folge bestimmter Regeln exponentiell erweitert werden muss, benötigen Sie ein System, das aus Beispielen lernen kann. Zum Glück sind Systeme für maschinelles Lernen gut aufgestellt, um dieses Problem zu lösen.
Bei der klassischen Programmierung muss der Programmierer dem Computer jeden Arbeitsschritt explizit vorgeben. Dieser Ansatz ist jedoch schnell unmöglich. Kundenkommentare verwenden ein breites und vielfältiges Vokabular und eine Struktur – zu vielfältig, um von einem einfachen Regelsatz erfasst zu werden. Wenn Sie versucht haben, manuelle Filter zu erstellen, werden Sie schnell feststellen, dass Sie den Großteil Ihrer Kundenkommentare nicht kategorisieren konnten. Du brauchst ein System, das eine Vielzahl von Kommentaren verallgemeinern kann.
In einem Szenario, in dem eine Folge bestimmter Regeln exponentiell erweitert werden muss, benötigen Sie ein System, das aus Beispielen lernen kann. Zum Glück sind Systeme für maschinelles Lernen gut aufgestellt, um dieses Problem zu lösen.
Ist die Natural Language API oder AutoML Natural Language das richtige Tool für mich?
Die Natural Language API erkennt Syntax, Entitäten und Sentiment in Texten und klassifiziert die Texte in eine vordefinierte Gruppe von Kategorien. Wenn Ihr Text aus Nachrichtenartikeln oder anderen Inhalten besteht, die kategorisiert werden sollen, oder wenn Sie Ihre Beispiele einer Sentimentanalyse unterziehen möchten, ist die Natural Language API einen Versuch wert. Wenn Ihre Textbeispiele jedoch nicht genau in das in der Natural Language API verfügbare Klassifizierungs- oder Gewichtungsschema der Kategorie übereinstimmen und Sie stattdessen Ihre eigenen Labels verwenden möchten, lohnt es sich, mit einem benutzerdefinierten Klassifikator zu experimentieren, um zu sehen, ob er Ihren Anforderungen entspricht.
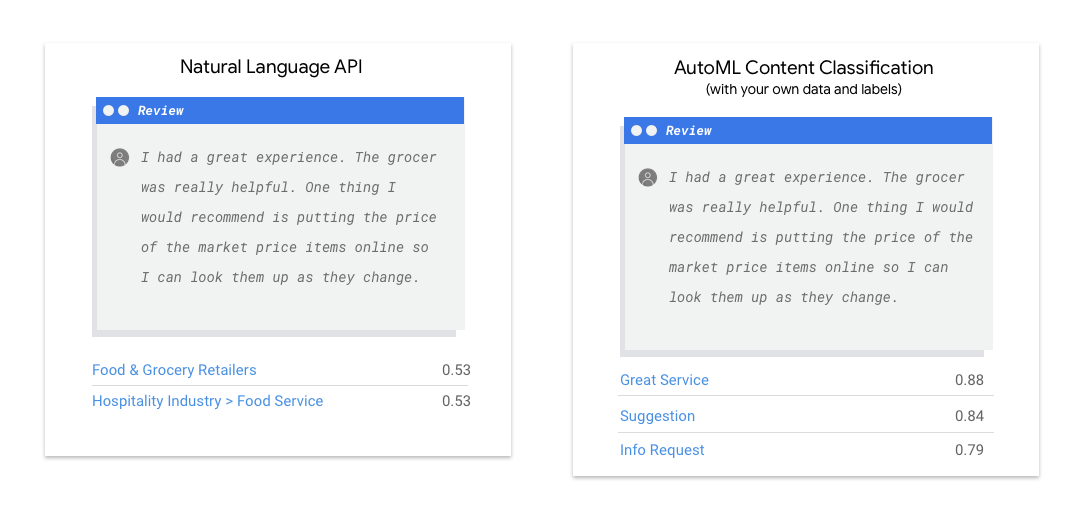
| Natural Language API testen | Erste Schritte mit AutoML |
Was bedeutet maschinelles Lernen in AutoML Natural Language?
 Beim maschinellen Lernen werden mithilfe von Daten Algorithmen trainiert, um ein gewünschtes Ergebnis zu erzielen. Die Eigenschaften des Algorithmus und der Trainingsmethoden ändern sich je nach Anwendungsfall. Beim maschinellen Lernen gibt es viele verschiedene Unterkategorien. Jede für sich kann unterschiedliche Probleme lösen und für jede gelten unterschiedliche Beschränkungen. Mit AutoML Natural Language können Sie im Rahmen einer überwachten Lernphase einen Computer so trainieren, dass er Muster in Daten erkennen kann, die mit einem Label versehen wurden. Mithilfe von überwachtem Lernen können Sie ein benutzerdefiniertes Modell trainieren, um Inhalte zu erkennen, die Ihnen wichtig sind.
Beim maschinellen Lernen werden mithilfe von Daten Algorithmen trainiert, um ein gewünschtes Ergebnis zu erzielen. Die Eigenschaften des Algorithmus und der Trainingsmethoden ändern sich je nach Anwendungsfall. Beim maschinellen Lernen gibt es viele verschiedene Unterkategorien. Jede für sich kann unterschiedliche Probleme lösen und für jede gelten unterschiedliche Beschränkungen. Mit AutoML Natural Language können Sie im Rahmen einer überwachten Lernphase einen Computer so trainieren, dass er Muster in Daten erkennen kann, die mit einem Label versehen wurden. Mithilfe von überwachtem Lernen können Sie ein benutzerdefiniertes Modell trainieren, um Inhalte zu erkennen, die Ihnen wichtig sind.
Datenvorbereitung
Zum Trainieren eines benutzerdefinierten Modells mit AutoML Natural Language stellen Sie Beispiele für die Arten von Textelementen (Eingaben) bereit, die Sie klassifizieren möchten, und die Kategorien oder Labels (die Antwort), die die ML-Systeme vorhersagen sollen.
Anwendungsfall bewerten

Gehen Sie beim Erstellen des Datasets immer vom konkreten Anwendungsfall aus. Folgende Fragestellungen können Ihnen am Anfang helfen:
- Welches Ergebnis möchten Sie erzielen?
- Welche Kategorien müssen erkannt werden, damit dieses Ergebnis erzielt werden kann?
- Könnte ein Mensch diese Kategorien erkennen? AutoML Natural Language kann zwar mehr Kategorien verarbeiten, als sich ein Mensch gleichzeitig merken und zuweisen kann, aber wenn ein Mensch eine bestimmte Kategorie nicht erkennen kann, hat es AutoML Natural Language auch schwer.
- Welche Beispiele geben am besten die Art und Bandbreite der Daten wieder, die das System klassifizieren soll?
Das Kernprinzip der ML-Produkte von Google ist ein auf den Menschen ausgerichtetes maschinelles Lernen. Bei diesem Ansatz stehen verantwortungsbewusste Vorgehensweisen in Bezug auf künstliche Intelligenz einschließlich Fairness im Vordergrund. Bei Fariness innerhalb von ML geht es darum, eine ungerechte oder von Vorurteilen beeinflusste Behandlung von Menschen aufgrund ihrer Herkunft, ihres Einkommens, ihrer sexuellen Orientierung, ihrer Religion, ihres Geschlechts und anderer Merkmale, die historisch mit Diskriminierung und Ausgrenzung verbunden waren, dort zu erkennen und zu verhindern, wo sie in Algorithmen oder bei der Entscheidungsfindung durch algorithmische Systeme sichtbar werden. Weitere Informationen finden Sie im Leitfaden Inklusives ML und den "Fair-aware"-Hinweisen ✽ in den Richtlinien weiter unten. Wir empfehlen Ihnen, sich mit dem Thema Fairness beim maschinellen Lernen vertraut zu machen, während Sie die Richtlinien für die Erstellung Ihres Datasets lesen, sofern dies für Ihren Anwendungsfall relevant ist.
Daten erheben
 Nachdem Sie nun wissen, welche Art von Daten Sie benötigen, sollten Sie sich überlegen, woher diese Daten kommen könnten. Zuerst einmal kommen alle Daten infrage, die Ihr Unternehmen ohnehin erfasst.
Möglicherweise werden die Daten, die Sie zum Trainieren eines Modells benötigen, bereits erhoben.
Wenn die erforderlichen Daten nicht verfügbar sind, können Sie sie manuell erfassen oder von einem Drittanbieter beziehen.
Nachdem Sie nun wissen, welche Art von Daten Sie benötigen, sollten Sie sich überlegen, woher diese Daten kommen könnten. Zuerst einmal kommen alle Daten infrage, die Ihr Unternehmen ohnehin erfasst.
Möglicherweise werden die Daten, die Sie zum Trainieren eines Modells benötigen, bereits erhoben.
Wenn die erforderlichen Daten nicht verfügbar sind, können Sie sie manuell erfassen oder von einem Drittanbieter beziehen.
In jede Kategorie genug Beispiele mit Labels aufnehmen
 Damit ein Training mit AutoML Natural Language gestartet werden kann, sind mindestens 10 Textbeispiele pro Kategorie/Label erforderlich.
Je mehr hochwertige Beispiele zur Verfügung gestellt werden, desto wahrscheinlicher ist es, dass ein Label erfolgreich erkannt wird. Im Allgemeinen gilt: Je mehr mit Labels versehene Daten Sie in den Trainingsprozess einbringen, desto besser wird Ihr Modell. Die Anzahl der benötigten Beispiele variiert auch mit dem Grad der Konsistenz der Daten, die Sie vorhersagen wollen, und mit dem angestrebten Genauigkeitsgrad. Sie können weniger Beispiele für konsistente Datensätze verwenden oder eine Genauigkeit von 80 % anstelle einer Genauigkeit von 97 % erzielen.
Trainieren Sie ein Modell anhand von 50 Beispielen pro Label und bewerten Sie die Ergebnisse. Fügen Sie weitere Beispiele hinzu und trainieren Sie noch einmal, bis Sie den angestrebten Genauigkeitsgrad erreicht haben. Hierfür sind möglicherweise Hunderte oder sogar Tausende Beispiele pro Etikett erforderlich.
Damit ein Training mit AutoML Natural Language gestartet werden kann, sind mindestens 10 Textbeispiele pro Kategorie/Label erforderlich.
Je mehr hochwertige Beispiele zur Verfügung gestellt werden, desto wahrscheinlicher ist es, dass ein Label erfolgreich erkannt wird. Im Allgemeinen gilt: Je mehr mit Labels versehene Daten Sie in den Trainingsprozess einbringen, desto besser wird Ihr Modell. Die Anzahl der benötigten Beispiele variiert auch mit dem Grad der Konsistenz der Daten, die Sie vorhersagen wollen, und mit dem angestrebten Genauigkeitsgrad. Sie können weniger Beispiele für konsistente Datensätze verwenden oder eine Genauigkeit von 80 % anstelle einer Genauigkeit von 97 % erzielen.
Trainieren Sie ein Modell anhand von 50 Beispielen pro Label und bewerten Sie die Ergebnisse. Fügen Sie weitere Beispiele hinzu und trainieren Sie noch einmal, bis Sie den angestrebten Genauigkeitsgrad erreicht haben. Hierfür sind möglicherweise Hunderte oder sogar Tausende Beispiele pro Etikett erforderlich.
Beispiele gleichmäßig auf Kategorien verteilen
Es ist wichtig, für jede Kategorie ungefähr gleich viele Trainingsbeispiele zu erfassen. Selbst wenn für ein Label wesentlich mehr Daten vorliegen als für andere, ist eine gleichmäßige Verteilung für alle Labels am besten. Wenn Sie sich fragen, warum, dann stellen Sie sich vor, 80 % der Kundenkommentare für das Training Ihres Modells wären Anfragen für Kostenvoranschläge. Wenn Sie die Labels derart ungleichmäßig verteilen, wird Ihr Modell höchstwahrscheinlich lernen, dass es am sichersten ist, einen Kundenkommentar einer Anfrage für einen Kostenvoranschlag zuzuordnen, anstatt die Vorhersage eines selteneren Labels zu reduzieren. Es ist wie bei einem Multiple-Choice-Test, bei dem fast alle richtigen Antworten "C" lauten. Ein versierter Testteilnehmer wird nach kurzer Zeit feststellen, dass man jedes Mal "C" ankreuzen kann, ohne sich die Frage vorher durchzulesen.

Es ist nicht immer möglich, für jedes Label etwa gleich viele Beispiele zu finden. Bei manchen Kategorien kann es schwieriger sein, hochwertige, unverzerrte Beispiele zu finden. In diesen Fällen sollte das Label mit der geringsten Anzahl von Beispielen mindestens 10 % der Beispiele als Label mit den meisten Beispielen enthalten. Wenn also das größte Label 10.000 Beispiele hat, sollte das kleinste Label mindestens 1.000 Beispiele haben.
Variation im Problembereich abdecken
Prüfen Sie analog dazu, ob Ihre Daten die Vielfalt und Vielseitigkeit Ihres Problembereichs abdecken. Wenn Sie eine breitere Reihe von Beispielen bereitstellen, kann das Modell neue Daten besser verallgemeinern. Angenommen, Sie versuchen, Artikel über Unterhaltungselektronik nach Thema zu sortieren. Je mehr Markennamen und technische Spezifikationen Sie angeben, desto einfacher wird es für das Modell sein, das Thema eines Artikels herauszufinden – auch wenn es in einem Artikel um eine Marke geht, die überhaupt nicht in den Trainingsbeispielen vorkommt. Sie können auch Dokumente mit dem Label "none_of_the_above" zur Verfügung stellen, die keinem Ihrer definierten Labels entsprechen, um die Modellleistung weiter zu verbessern.
Daten an die beabsichtigte Ausgabe des Modells anpassen

Suchen Sie nach Textbeispielen, die denen ähneln, für die Sie Vorhersagen treffen möchten. Wenn Sie versuchen, Beiträge in sozialen Medien über das Glasblasen zu klassifizieren, werden Sie wahrscheinlich keine besonders gute Leistung von einem Modell erhalten, das auf Glasbläser-Informationsseiten geschult wurde, da das Vokabular und der Stil sehr unterschiedlich sein können. Im Idealfall handelt es sich bei Ihren Trainingsbeispielen um reale Daten, die aus dem Dataset stammen, für das Sie auch das Modell zur Klassifizierung verwenden möchten.
Berücksichtigen, wie AutoML Natural Language das Dataset beim Erstellen eines benutzerdefinierten Modells verwendet
Zu Ihrem Dataset gehören Trainings-, Validierungs- und Test-Datasets. Wenn Sie die Aufteilungen nicht wie unter Daten vorbereiten beschrieben angeben, verwendet AutoML Natural Language automatisch 80 % des Inhalts der Dokumente für das Training, 10 % für die Validierung und 10% für Tests.
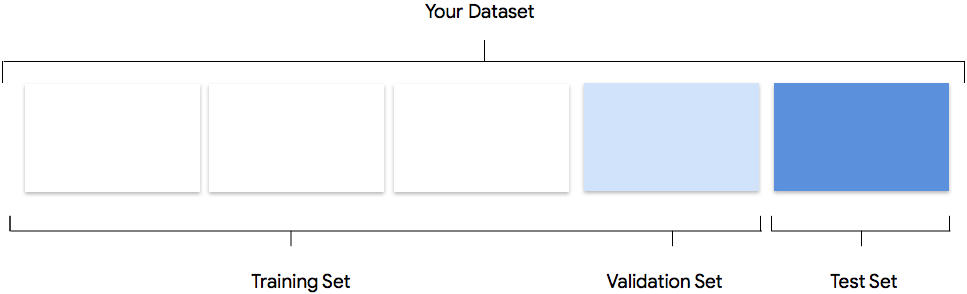
Trainings-Dataset
 Die meisten Daten sollten im Trainings-Dataset enthalten sein. Dies sind die Daten, die das Modell während des Trainings "sieht". Damit werden die Parameter des Modells erlernt, vor allem die Gewichtung der Verbindungen zwischen den Knoten des neuronalen Netzes.
Die meisten Daten sollten im Trainings-Dataset enthalten sein. Dies sind die Daten, die das Modell während des Trainings "sieht". Damit werden die Parameter des Modells erlernt, vor allem die Gewichtung der Verbindungen zwischen den Knoten des neuronalen Netzes.
Validierungs-Dataset
 Während des Trainingsvorgangs wird auch das Validierungs-Dataset, oft als "dev"-Dataset bezeichnet, verwendet. Das Modell-Lern-Framework bindet Trainingsdaten während jeder Iteration des Trainingsvorgangs ein. Anschließend verwendet es im Validierungs-Dataset die Leistung des Modells, um die Hyperparameter des Modells zu optimieren. Hyperparameter sind Variablen, die die Struktur des Modells festlegen. Falls Sie versuchen, die Hyperparameter mit dem Trainings-Dataset zu optimieren, ist es wahrscheinlich, dass sich das Modell zu stark an den Trainingsdaten orientieren würde und die Verallgemeinerung der Beispiele, die nicht genau mit diesen Daten übereinstimmen, schwieriger wird. Wenn Sie aber beim Validierungsschritt für die Feinabstimmung der Modellstruktur relativ neuartige Daten verwenden, ermöglicht dies dem Modell potenziell bessere Verallgemeinerungen.
Während des Trainingsvorgangs wird auch das Validierungs-Dataset, oft als "dev"-Dataset bezeichnet, verwendet. Das Modell-Lern-Framework bindet Trainingsdaten während jeder Iteration des Trainingsvorgangs ein. Anschließend verwendet es im Validierungs-Dataset die Leistung des Modells, um die Hyperparameter des Modells zu optimieren. Hyperparameter sind Variablen, die die Struktur des Modells festlegen. Falls Sie versuchen, die Hyperparameter mit dem Trainings-Dataset zu optimieren, ist es wahrscheinlich, dass sich das Modell zu stark an den Trainingsdaten orientieren würde und die Verallgemeinerung der Beispiele, die nicht genau mit diesen Daten übereinstimmen, schwieriger wird. Wenn Sie aber beim Validierungsschritt für die Feinabstimmung der Modellstruktur relativ neuartige Daten verwenden, ermöglicht dies dem Modell potenziell bessere Verallgemeinerungen.
Test-Dataset
 Das Test-Dataset wird unabhängig vom Trainingsvorgang eingesetzt. Nachdem das Training des Modells abgeschlossen ist, nutzt AutoML Natural Language das Test-Dataset als Herausforderung für Ihr Modell. Anhand der Leistung des Modells beim Test-Dataset lässt sich absehen, wie gut es später mit Realdaten funktionieren wird.
Das Test-Dataset wird unabhängig vom Trainingsvorgang eingesetzt. Nachdem das Training des Modells abgeschlossen ist, nutzt AutoML Natural Language das Test-Dataset als Herausforderung für Ihr Modell. Anhand der Leistung des Modells beim Test-Dataset lässt sich absehen, wie gut es später mit Realdaten funktionieren wird.
Manuelle Aufteilung
 Sie können Ihr Dataset selbst aufteilen. Die manuelle Aufteilung Ihrer Daten ist dann sinnvoll, wenn Sie den Vorgang genauer steuern möchten oder bestimmte Beispiele unbedingt in einem bestimmten Bereich des Modelltrainings verwenden möchten.
Sie können Ihr Dataset selbst aufteilen. Die manuelle Aufteilung Ihrer Daten ist dann sinnvoll, wenn Sie den Vorgang genauer steuern möchten oder bestimmte Beispiele unbedingt in einem bestimmten Bereich des Modelltrainings verwenden möchten.
Daten für den Import vorbereiten

Sobald Sie entschieden haben, ob eine manuelle oder automatische Aufteilung Ihrer Daten für Sie infrage kommt, haben Sie drei Möglichkeiten, Daten in AutoML Natural Language hinzuzufügen:
- Sie können die Daten mit Ihren Textbeispielen in Ordnern sortieren, die Ihren Labels entsprechen, und sie dann importieren.
- Sie können die Daten im CSV-Format mit den Labels inline speichern und dann entweder von Ihrem Computer oder aus Cloud Storage importieren. Informationen dazu finden Sie in dem Abschnitt Trainingsdaten vorbereiten. Wenn Sie Ihr Dataset manuell aufteilen möchten, müssen Sie diese Option auswählen und Ihre CSV-Datei entsprechend formatieren.
- Wenn Ihre Daten nicht mit Labels versehen wurden, können Sie Beispiele ohne Text hochladen und diese mithilfe der AutoML Natural Language UI mit Labels versehen.
Bewerten
Nachdem das Modell trainiert wurde, erhalten Sie eine Zusammenfassung der Modellleistung. Wenn Sie eine detaillierte Analyse ansehen möchten, klicken Sie auf evaluate oder evaluate.
Was sollte ich beachten, bevor ich mein Modell bewerte?
 Bei der Fehlerbehebung eines Modells geht es in erster Linie darum, Fehler in den Daten und nicht im Modell selbst zu beheben. Wenn sich Ihr Modell unerwartet verhält, während Sie seine Leistung vor und nach der Übernahme in die Produktion bewerten, sollten Sie zurückkehren und Ihre Daten überprüfen, um zu sehen, wo es verbessert werden könnte.
Bei der Fehlerbehebung eines Modells geht es in erster Linie darum, Fehler in den Daten und nicht im Modell selbst zu beheben. Wenn sich Ihr Modell unerwartet verhält, während Sie seine Leistung vor und nach der Übernahme in die Produktion bewerten, sollten Sie zurückkehren und Ihre Daten überprüfen, um zu sehen, wo es verbessert werden könnte.
Welche Analysen kann ich in AutoML Natural Language ausführen?
In AutoML Natural Language können Sie im Abschnitt "Bewerten" die Leistung Ihres benutzerdefinierten Modells bewerten. Die Bewertung beruht auf der Ausgabe des Modells für Testbeispiele und allgemeinen Messwerten für das maschinelle Lernen. In diesem Abschnitt werden die folgenden Konzepte erläutert:
- Modellausgabe
- Score-Schwellenwert
- Richtig positive, richtig negative, falsch positive und falsch negative Ergebnisse
- Precision und recall
- Genauigkeits-/Trefferquotenkurve
- Durchschnittliche Genauigkeit
Wie interpretiere ich die Modellausgabe?
AutoML Natural Language extrahiert Beispiele aus Ihren Testdaten, um sie dem Modell als neue Aufgaben zu präsentieren. Für jedes Beispiel gibt das Modell eine Reihe von Zahlen aus, die angeben, wie eng das jeweilige Beispiel mit den einzelnen Labels verknüpft ist. Wenn die Zahl hoch ist, ist das Modell sehr sicher, dass das Label auf dieses Dokument angewendet werden sollte.
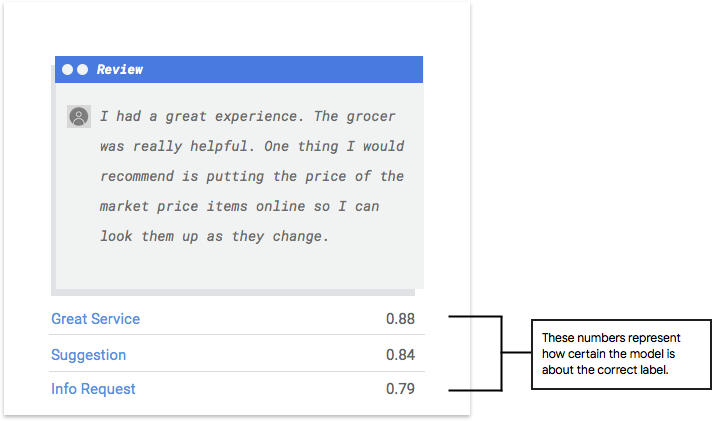
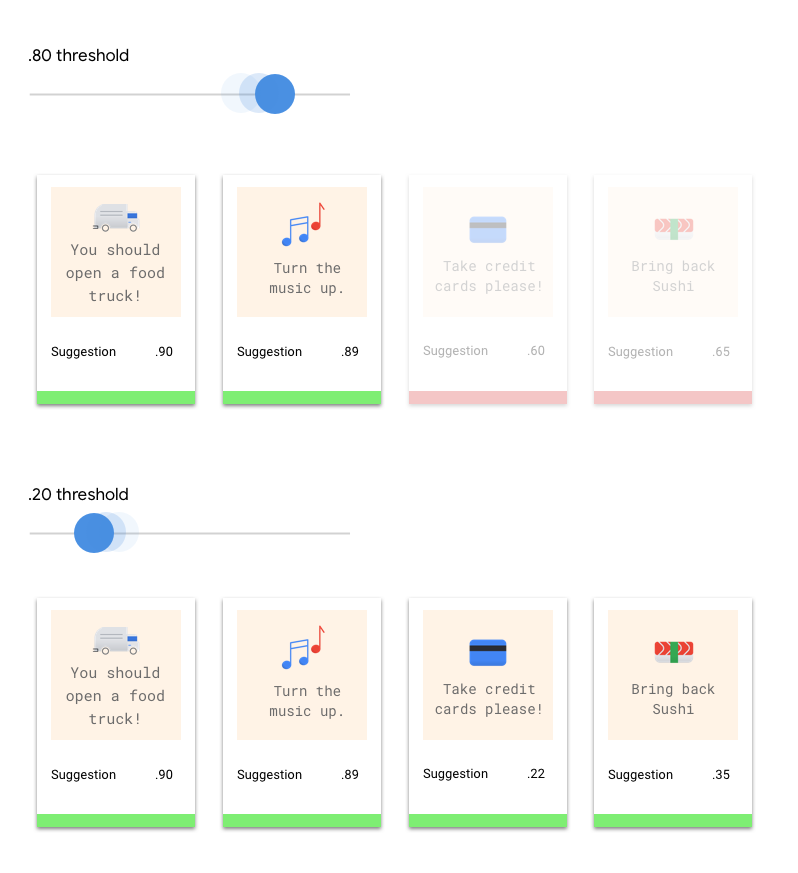
Was ist der Scorel-Schwellenwert?
Mithilfe des Score-Schwellenwerts kann AutoML Natural Language Wahrscheinlichkeiten in binäre Ein-/Aus-Werte umwandeln. Der Score-Schwellenwert bezieht sich darauf, wie zuverlässig das Modell einem Testelement eine Kategorie zuordnen kann. Der Schieberegler für den Score-Schwellenwert in der Benutzeroberfläche ist ein visuelles Hilfsmittel, mit dem Sie die Auswirkungen verschiedener Schwellenwerte in Ihrem Dataset testen können. Wenn im obigen Beispiel der Score-Schwellenwert für alle Kategorien auf 0,8 festgelegt wird, werden "Great Service" und "Suggestion" zugewiesen, nicht jedoch "Info Request". Wenn Ihr Score-Schwellenwert niedrig ist, klassifiziert Ihr Modell zwar mehr Textelemente, es besteht jedoch auch das Risiko, dass mehr Textelemente falsch klassifiziert werden. Ist der Score-Schwellenwert hoch, kann das Modell zwar weniger Textelemente klassifizieren, dafür ist aber das Risiko einer falschen Klassifizierung geringer. Sie können die Schwellenwerte für die einzelnen Kategorien in der Benutzeroberfläche ändern, wenn Sie experimentieren möchten. Wenn Sie aber Ihr Modell in der Produktion verwenden, müssen Sie die von Ihnen als optimal ermittelten Schwellenwerte selbst durchsetzen.
Was sind richtig positive, richtig negative, falsch positive und falsch negative Ergebnisse?
Nach dem Anwenden des Score-Schwellenwerts fallen die Vorhersagen Ihres Modells in eine der folgenden vier Kategorien.
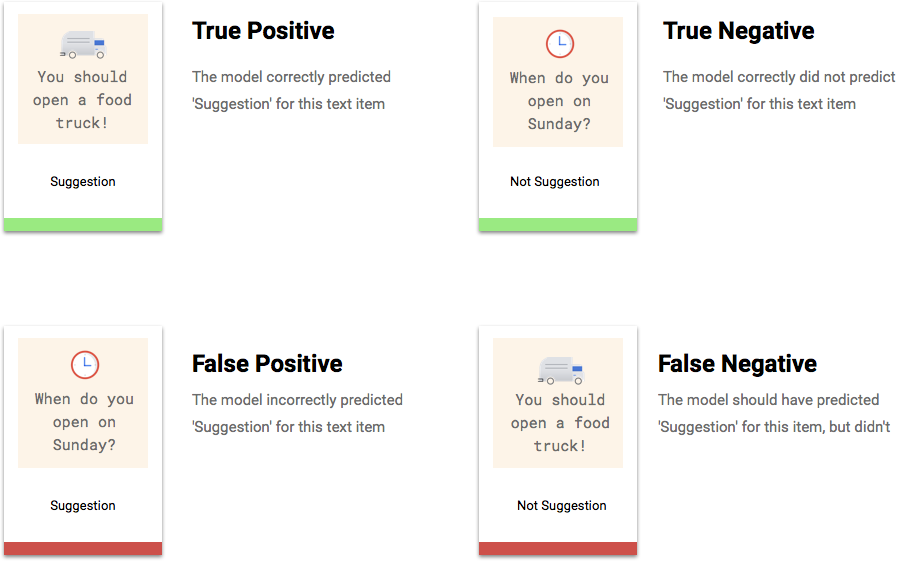
Mit diesen Kategorien können Sie die Genauigkeit und die Trefferquote berechnen, d. h. die Messwerte für die Beurteilung der Effektivität Ihres Modells.
Was sind Genauigkeit und Trefferquote?
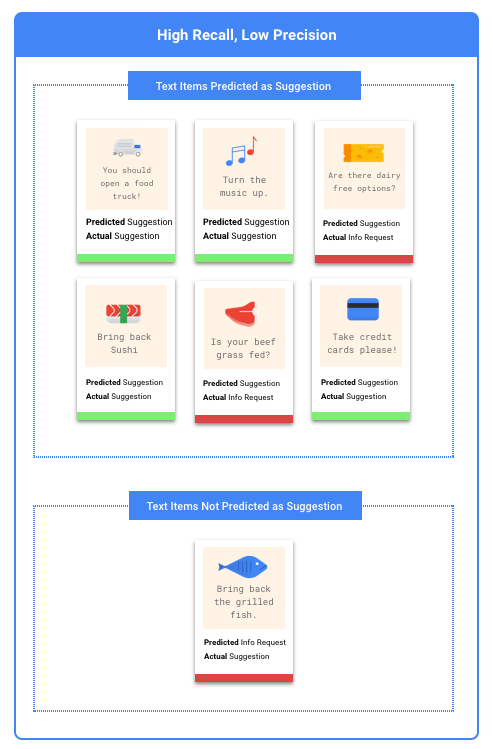
Anhand der Genauigkeit ("Precision") und Trefferquote ("Recall") können Sie analysieren, wie gut das Modell Informationen erhebt und wie viele Informationen es auslässt. Die Genauigkeit zeigt, wie viele Testbeispiele, die mit einem Label versehen wurden, auch mit diesem Label kategorisiert werden sollten. Die Trefferquote zeigt, wie viele Testbeispiele, die mit diesem Label versehen werden sollten, tatsächlich mit diesem Label versehen wurden.

Empfiehlt sich die Optimierung der Genauigkeit oder der Trefferquote?
Ob Sie die Genauigkeit oder die Trefferquote optimieren sollten, hängt vom jeweiligen Anwendungsfall ab. Lassen Sie uns anhand der folgenden zwei Anwendungsfälle untersuchen, wie Sie diese Entscheidung angehen könnten.
Anwendungsfall: Dringende Dokumente
Angenommen, Sie möchten ein System erstellen, das dringende Dokumente priorisieren kann.

Ein falsch positives Ergebnis wäre in diesem Fall ein Dokument, das nicht dringend ist, aber als solches markiert wird. Der Nutzer kann es als nicht dringend abweisen und weitermachen.

Ein falsch negatives Ergebnis wäre in diesem Fall ein Dokument, das dringend ist, aber nicht als solches markiert wird. Das könnte Probleme verursachen.
In diesem Fall wäre es besser, die Trefferquote zu optimieren. Die Trefferquote misst bei allen getroffenen Vorhersagen, wie viel ausgelassen wurde. Bei Modellen mit hoher Trefferquote ist die Wahrscheinlichkeit hoch, dass sie auch wenig relevante Beispiele mit einem Label versehen. Das kann nützlich sein, wenn Ihre Kategorie zu wenig Trainingsdaten hat.
Anwendungsfall: Spam-Filter
Angenommen, Sie möchten ein System erstellen, das automatisch Spam-E-Mails von nützlichen Nachrichten unterscheidet und sie ausfiltert.

Ein falsch negatives Ergebnis wäre in diesem Fall eine Spam-E-Mail, die nicht abgefangen wird und die Sie in Ihrem Posteingang sehen. Das ist in der Regel ein bisschen nervig.

Ein falsch positives Ergebnis wäre in diesem Fall eine E-Mail, die fälschlicherweise als Spam gekennzeichnet und aus dem Posteingang entfernt wird. Wenn die E-Mail wichtig war, kann dies für den Nutzer nachteilig sein.
In diesem Fall wäre es besser, die Genauigkeit zu optimieren. Die Genauigkeit misst bei allen getroffenen Vorhersagen, wie genau sie sind. Bei Modellen mit hoher Genauigkeit ist die Wahrscheinlichkeit hoch, dass sie nur sehr relevante Beispiele mit einem Label versehen. Das kann nützlich sein, wenn Ihre Kategorie in den Trainingsdaten häufig vorkommt.
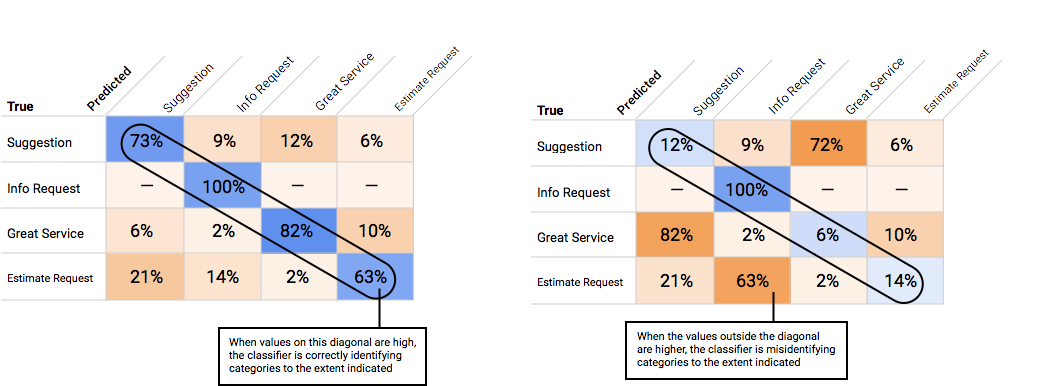
Wie verwende ich die Wahrheitsmatrix?
Mit der Wahrheitsmatrix lässt sich die Leistung eines Modells für jedes Label vergleichen. In einem idealen Modell sind die Werte auf der Diagonalen hoch und alle anderen Werte niedrig. Daran ist zu erkennen, dass die gewünschten Kategorien richtig identifiziert werden. Sind die anderen Werte hoch, ist das ein Hinweis darauf, dass das Modell Testelemente falsch klassifiziert.
Wie interpretiere ich die Genauigkeits-/Trefferquotenkurve?
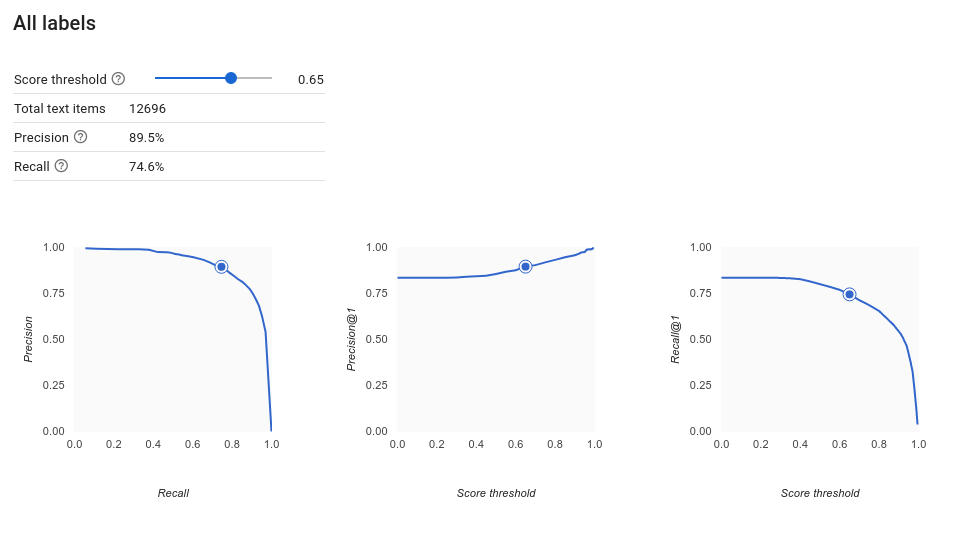
Mit dem Score-Schwellenwert-Tool können Sie herausfinden, wie sich der gewählte Score-Schwellenwert auf Genauigkeit und Trefferquote auswirkt. Bewegen Sie den Schieberegler für den Score-Schwellenwert, um zu sehen, wo Sie sich auf der Genauigkeits-/Trefferquotenkurve befinden und wie sich dieser Schwellenwert jeweils auf Genauigkeit und Trefferquote auswirkt. Bei Modellen mit mehreren Klassen wird für die Berechnung der Genauigkeit und der Trefferquote nur das am besten bewertete Label verwendet. Dies kann Ihnen helfen, ein Gleichgewicht zwischen falsch positiven und falsch negativen Ergebnissen zu schaffen.
Wenn Sie einen Schwellenwert gewählt haben, der für Ihr Modell insgesamt akzeptabel erscheint, können Sie auf einzelne Labels klicken und sehen, in welchen Bereich dieser Schwellenwert auf der Genauigkeits-/Trefferquotenkurve eines bestimmten Labels fällt. Dabei kann es sein, dass Sie für einige Labels eine Menge falscher Vorhersagen erhalten. In diesem Fall ist es eine Überlegung wert, für jede Klasse einen eigenen Schwellenwert zu wählen, der genau auf diese Labels zugeschnitten ist. Nehmen wir beispielsweise an, Sie sehen sich das Dataset Ihrer Kundenkommentare an und stellen fest, dass ein Schwellenwert von 0,5 für jeden Kommentartyp mit Ausnahme von "Suggestion" zu einer angemessenen Genauigkeit und einer angemessenen Trefferquote führt. Das könnte daran liegen, dass es sich um eine sehr allgemeine Kategorie handelt. Für diese Kategorie erhalten Sie eine Menge falsch positiver Ergebnisse. In diesem Fall könnten Sie einen Schwellenwert von 0,8 nur für "Suggestion" in Erwägung ziehen, wenn Sie den Klassifikator für Vorhersagen verwenden.
Was ist die durchschnittliche Genauigkeit?
Ein nützlicher Messwert für die Modellgenauigkeit ist die Fläche unter der Genauigkeits-/Trefferquotenkurve. Er misst, wie gut Ihr Modell über alle Score-Schwellenwerte hinweg funktioniert. In AutoML Natural Language wird dieser Messwert als durchschnittliche Genauigkeit bezeichnet. Je näher dieser Wert bei 1,0 liegt, desto besser schneidet Ihr Modell im Test-Dataset ab. Ein Modell, das Labels nach dem Zufallsprinzip errät, hätte eine durchschnittliche Genauigkeit von etwa 0,5.
Modell testen
 Zum Testen des Modells verwendet AutoML Natural Language automatisch 10% Ihrer Daten (oder, wenn Sie die Datenaufteilung selbst ausgewählt haben, den Prozentsatz, den Sie verwendet haben). Auf der Seite „Bewerten“ können Sie sehen, wie das Modell mit diesen Testdaten abgeschnitten hat. Für den Fall, dass Sie Ihr Modell jedoch einer Plausibilitätsprüfung unterziehen möchten, gibt es dafür mehrere Möglichkeiten. Am einfachsten ist es, Textbeispiele in das Textfeld auf der Seite „Vorhersagen“ einzugeben und sich die Labels anzusehen, die das Modell für Ihre Beispiele auswählt. Hoffentlich erfüllt dies
Ihren Erwartungen. Probieren Sie einfach ein paar Beispiele für jeden erwarteten Kommentartyp aus.
Zum Testen des Modells verwendet AutoML Natural Language automatisch 10% Ihrer Daten (oder, wenn Sie die Datenaufteilung selbst ausgewählt haben, den Prozentsatz, den Sie verwendet haben). Auf der Seite „Bewerten“ können Sie sehen, wie das Modell mit diesen Testdaten abgeschnitten hat. Für den Fall, dass Sie Ihr Modell jedoch einer Plausibilitätsprüfung unterziehen möchten, gibt es dafür mehrere Möglichkeiten. Am einfachsten ist es, Textbeispiele in das Textfeld auf der Seite „Vorhersagen“ einzugeben und sich die Labels anzusehen, die das Modell für Ihre Beispiele auswählt. Hoffentlich erfüllt dies
Ihren Erwartungen. Probieren Sie einfach ein paar Beispiele für jeden erwarteten Kommentartyp aus.
Wenn Sie Ihr Modell in Ihren eigenen automatisierten Tests verwenden möchten, erfahren Sie auf der Seite "Vorhersagen", wie Sie das Modell programmgesteuert aufrufen können.