Ein Dataset enthält repräsentative Beispiele für den zu klassifizierenden Inhaltstyp und ist mit den Kategorielabels gekennzeichnet, die das benutzerdefinierte Modell verwenden soll. Das Dataset dient als Eingabe zum Trainieren eines Modells.
Die wesentlichen Schritte zum Erstellen eines Datasets sind:
- Dataset-Ressource erstellen
- Trainingsdaten in das Dataset importieren
- Dokumente mit Labels versehen oder Entitäten identifizieren
Bei der Klassifizierung und Sentimentanalyse werden die Schritte 2 und 3 häufig kombiniert: Sie können Dokumente importieren, für die Labels bereits zugewiesen sind.
Dataset erstellen
Der erste Schritt zum Erstellen eines benutzerdefinierten Modells besteht darin, ein leeres Dataset zu erstellen, das mit den Trainingsdaten für das Modell gefüllt wird. Das neu erstellte Dataset enthält keine Daten, solange noch keine Dokumente darin importiert wurden.
Web-UI
So erstellen Sie ein Dataset:
Öffnen Sie die AutoML Natural Language UI und wählen Sie Erste Schritte in dem Feld für den Modelltyp aus, den Sie trainieren möchten.
Auf der Seite Datasets wird der Status zuvor erstellter Datasets für das aktuelle Projekt angezeigt.
Wenn Sie ein Dataset für ein anderes Projekt hinzufügen möchten, wählen Sie das Projekt in der Drop-down-Liste oben rechts in der Titelleiste aus.
Klicken Sie in der Titelleiste auf die Schaltfläche Neues Dataset.
Geben Sie einen Namen für das Dataset ein und legen Sie fest, an welchem geografischen Standort das Dataset gespeichert werden soll.
Weitere Informationen finden Sie unter Standorte.
Wählen Sie Ihr Modellziel aus, das angibt, welche Art von Analyse Sie mit dem Modell durchführen möchten, das Sie mit diesem Dataset trainieren.
- Die Klassifizierung mit einem einzigen Label weist jedem klassifizierten Dokument ein einzelnes Label zu
- Durch die Klassifizierung mit mehreren Labels können einem Dokument mehrere Labels zugewiesen werden
- Die Entitätsextraktion erkennt Entitäten in Dokumenten
- Die Sentimentanalyse ermittelt subjektive Einstellungen in Dokumenten
Klicken Sie auf Dataset erstellen.
Die Seite Importieren wird für das neue Dataset angezeigt. Weitere Informationen finden Sie unter Daten in ein Dataset importieren.
Codebeispiele
Klassifizierung
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: Ihre Projekt-ID
- location-id: Der Standort für die Ressource,
us-central1für den globalen Standort odereufür die EU
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON-Text anfordern:
{
"displayName": "test_dataset",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{
"name": "projects/434039606874/locations/us-central1/datasets/356587829854924648",
"displayName": "test_dataset",
"createTime": "2018-04-26T18:02:59.825060Z",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Python API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Java API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Node.js API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Go API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Bitte folgen Sie der Anleitung für die Einrichtung von C# auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für .NET
PHP: Bitte folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für PHP
Ruby: Bitte folgen Sie der Anleitung für die Einrichtung von Ruby auf der Seite „Clientbibliotheken“ und rufen Sie dann die AutoML Natural Language-Referenzdokumentation für Ruby
Entitätsextraktion
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: Ihre Projekt-ID
- location-id: Der Standort für die Ressource,
us-central1für den globalen Standort odereufür die EU
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON-Text anfordern:
{
"displayName": "test_dataset",
"textExtractionDatasetMetadata": {
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{
name: "projects/000000000000/locations/us-central1/datasets/TEN5582774688079151104"
display_name: "test_dataset"
create_time {
seconds: 1539886451
nanos: 757650000
}
text_extraction_dataset_metadata {
}
}
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Python API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Java API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Node.js API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Go API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Bitte folgen Sie der Anleitung für die Einrichtung von C# auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für .NET
PHP: Bitte folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für PHP
Ruby: Bitte folgen Sie der Anleitung für die Einrichtung von Ruby auf der Seite „Clientbibliotheken“ und rufen Sie dann die AutoML Natural Language-Referenzdokumentation für Ruby
Sentimentanalyse
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: Ihre Projekt-ID
- location-id: Der Standort für die Ressource,
us-central1für den globalen Standort odereufür die EU
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON-Text anfordern:
{
"displayName": "test_dataset",
"textSentimentDatasetMetadata": {
"sentimentMax": 4
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{
name: "projects/000000000000/locations/us-central1/datasets/TST8962998974766436002"
display_name: "test_dataset_name"
create_time {
seconds: 1538855662
nanos: 51542000
}
text_sentiment_dataset_metadata {
sentiment_max: 7
}
}
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Python API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Java API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Node.js API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Go API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Bitte folgen Sie der Anleitung für die Einrichtung von C# auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für .NET
PHP: Bitte folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für PHP
Ruby: Bitte folgen Sie der Anleitung für die Einrichtung von Ruby auf der Seite „Clientbibliotheken“ und rufen Sie dann die AutoML Natural Language-Referenzdokumentation für Ruby
Trainingsdaten in ein Dataset importieren
Nachdem Sie ein Dataset erstellt haben, können Sie Dokument-URIs und Labels für Dokumente aus einer CSV-Datei importieren, die in einem Cloud Storage-Bucket gespeichert ist. Weitere Informationen zum Vorbereiten von Daten und Erstellen einer CSV-Datei zum Importieren finden Sie unter Trainingsdaten vorbereiten.
Sie können Dokumente in ein leeres Dataset importieren oder zusätzliche Dokumente in ein vorhandenes Dataset importieren.
Web-UI
So importieren Sie Dokumente in ein Dataset:
Wählen Sie auf der Seite Datasets das Dataset aus, in das Sie Dokumente importieren möchten.
Geben Sie auf dem Tab Import an, wo die Trainingsdokumente zu finden sind.
Sie haben folgende Möglichkeiten:
Laden Sie eine CSV-Datei mit den Trainingsdokumenten und den zugehörigen Kategorielabels von Ihrem lokalen Computer oder aus dem Cloud Storage hoch.
Sie können eine Sammlung von TXT-, PDF-, TIF- oder ZIP-Dateien mit den Trainingsdokumenten von Ihrem lokalen Computer hochladen.
Wählen Sie die zu importierenden Dateien und den Cloud Storage-Pfad für die importierten Dokumente aus.
Klicken Sie auf Importieren.
Codebeispiele
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: Ihre Projekt-ID
- location-id: Der Standort für die Ressource,
us-central1für den globalen Standort odereufür die EU - dataset-id: Ihre Dataset-ID
- bucket-name: Ihr Cloud Storage-Bucket
- csv-file-name: Ihre CSV-Trainingsdatendatei
HTTP-Methode und URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets/dataset-id:importData
JSON-Text anfordern:
{
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/csv-file-name.csv"]
}
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Die Ausgabe sieht in etwa so aus: Sie können den Status der Aufgabe anhand der Vorgangs-ID abrufen. Ein Beispiel finden Sie unter Status eines Vorgangs abrufen.
{
"name": "projects/434039606874/locations/us-central1/operations/1979469554520650937",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Python API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Java API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Node.js API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Natural Language finden Sie unter AutoML Natural Language-Clientbibliotheken Weitere Informationen finden Sie in der AutoML Natural Language Go API Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Natural Language zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Bitte folgen Sie der Anleitung für die Einrichtung von C# auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für .NET
PHP: Bitte folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite „Clientbibliotheken“ und rufen Sie dann die Referenzdokumentation zu AutoML Natural Language für PHP
Ruby: Bitte folgen Sie der Anleitung für die Einrichtung von Ruby auf der Seite „Clientbibliotheken“ und rufen Sie dann die AutoML Natural Language-Referenzdokumentation für Ruby
Trainingsdokumente mit Labels versehen
Damit die einzelnen Dokumente eines Datasets beim Training eines Modells von Nutzen sind, müssen diesen Dokumenten Labels so zugewiesen werden, wie auch AutoML Natural Language ähnliche Dokumente mit Labels versehen soll. Die Qualität der Trainingsdaten beeinflusst stark die Effizienz des von Ihnen erstellten Modells und folglich die Qualität der damit generierten Vorhersagen. AutoML Natural Language ignoriert während des Trainings Dokumente ohne Labels.
Sie können Labels für Ihre Trainingsdokumente auf drei verschiedene Arten angeben:
- Fügen Sie Labels in die CSV-Datei ein (nur bei der Klassifizierung und Sentimentanalyse).
- Weisen Sie Ihren Dokumenten Labels in der AutoML Natural Language UI zu
- Anfordern von Labeling durch Menschen über den AI Platform Data Labeling Service
Die AutoML API enthält keine Methoden für das Labeling.
Weitere Informationen zum Labeling von Dokumenten in einer CSV-Datei finden Sie unter Trainingsdaten vorbereiten.
Labeling bei Klassifizierung und Sentimentanalyse
Wählen Sie auf der Seite mit der Dataset-Liste das Dataset aus, um Dokumente in der AutoML Natural Language UI mit einem Label zu versehen und Details zum Dataset anzeigen zu lassen. Der Anzeigename des ausgewählten Datasets wird in der Titelleiste angezeigt. Die einzelnen Dokumente im Dataset werden zusammen mit ihren Labels aufgelistet. Die Navigationsleiste auf der linken Seite fasst die Anzahl der Dokumente mit und ohne Label zusammen und ermöglicht, die Liste der Dokumente nach Label oder Sentimentwert zu filtern.
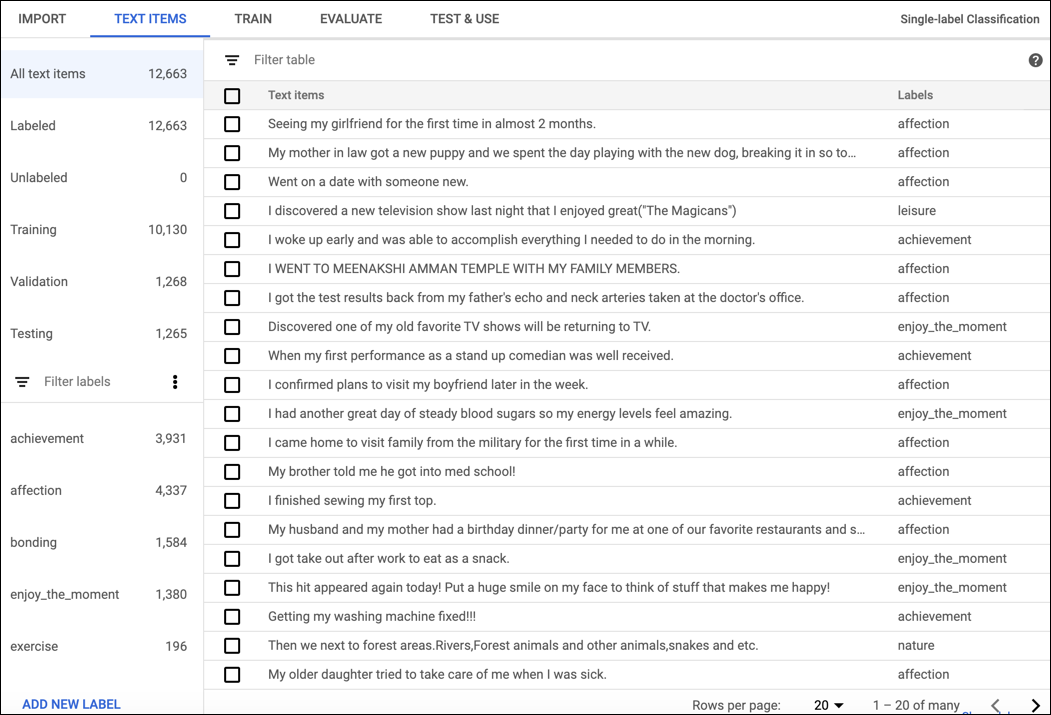
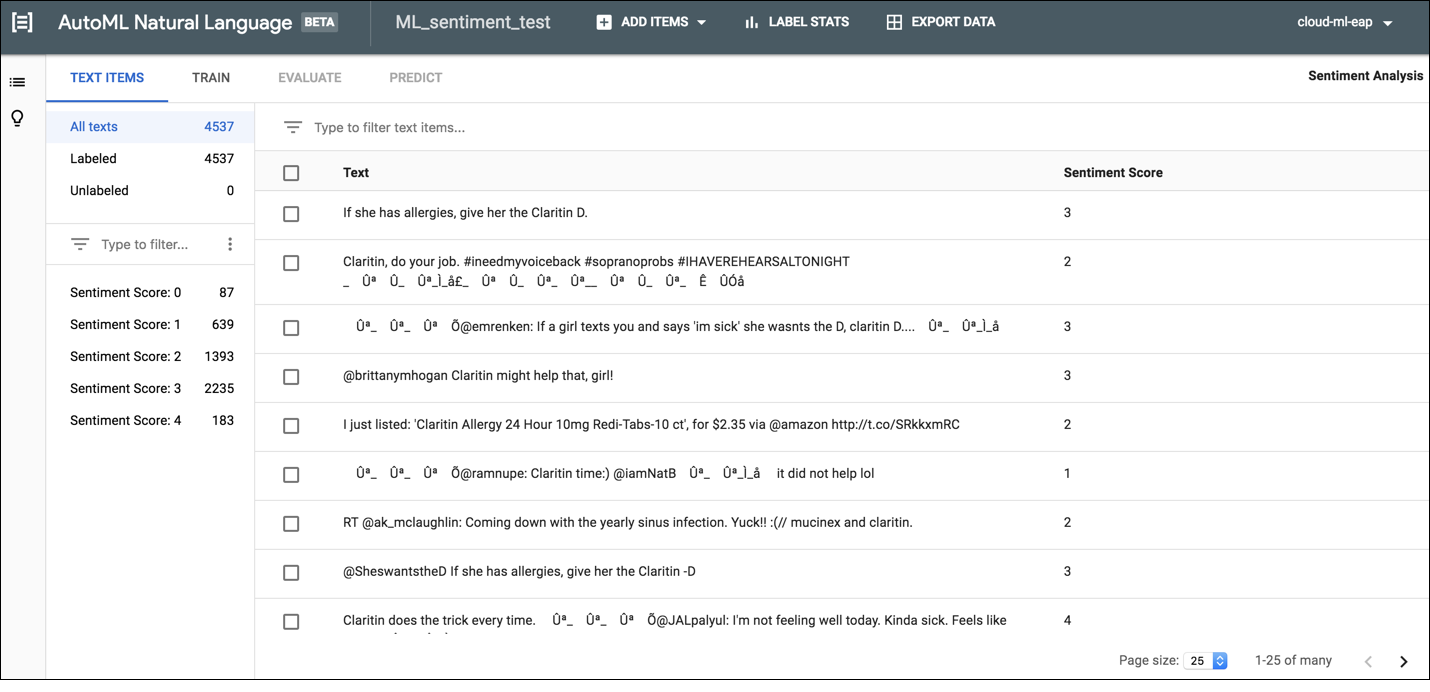
Wählen Sie die Dokumente aus, die Sie aktualisieren möchten, und die Labels oder Werte, die Sie ihnen zuweisen möchten, um Labels oder Sentimentwerte Elementen ohne Labels zuzuweisen oder Labels für Dokumente zu ändern. Es gibt zwei Möglichkeiten, das Label eines Dokuments zu aktualisieren:
Klicken Sie auf das Kästchen neben den Dokumenten, die Sie aktualisieren möchten, und wählen Sie die anzuwendenden Labels aus der Drop-down-Liste Label aus, die oben in der Liste der Dokumente angezeigt wird.
Klicken Sie auf die Zeile des Dokuments, das Sie aktualisieren möchten, und wählen Sie die anzuwendenden Labels oder Werte aus der Liste auf der Seite Textdetail aus.
Entitäten für die Entitätsextraktion identifizieren
Vor dem Training Ihres benutzerdefinierten Modells müssen Sie die Trainingsdokumente im Dataset annotieren. Sie können Trainingsdokumente annotieren, bevor Sie sie importieren, oder Sie können Annotationen in der AutoML Natural Language UI hinzufügen.
Wählen Sie auf der Seite mit der Dataset-Liste das Dataset aus, um in der AutoML Natural Language UI Annotationen hinzuzufügen und Details zum Dataset anzeigen zu lassen. Der Anzeigename des ausgewählten Datasets wird in der Titelleiste angezeigt. Die einzelnen Dokumente im Dataset werden zusammen mit ihren Annotationen aufgelistet. Die Navigationsleiste auf der linken Seite fasst die Labels und die Häufigkeit der einzelnen Labels zusammen. Sie können die Liste der Dokumente auch nach Label filtern.
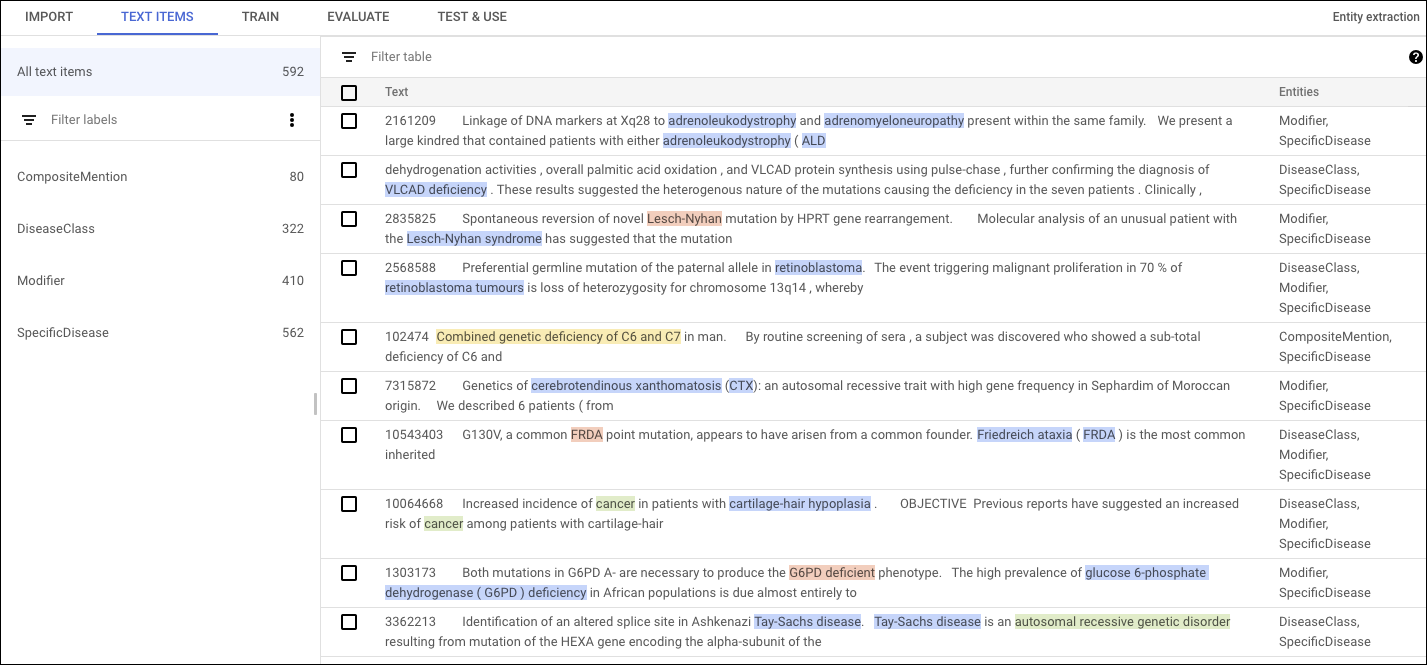
Wenn Sie Annotationen in einem Dokument hinzufügen oder löschen möchten, doppelklicken Sie auf das Dokument, das Sie aktualisieren möchten. Die Seite Bearbeiten zeigt den vollständigen Text des ausgewählten Dokuments an, wobei alle vorherigen Annotationen hervorgehoben sind.

Bei PDF-Trainingsdokumenten oder Dokumenten, die mit Layoutinformationen importiert wurden, hat die Seite Bearbeiten zwei Tabs: Nur Text und Strukturierter Text. Der Tab Nur Text zeigt den Rohinhalt des Trainingsdokuments ohne Formatierung an. Der Tab Strukturierter Text erstellt das grundlegende Layout des Trainingsdokuments neu. (Der Tab Nur Text enthält auch einen Link zur ursprünglichen PDF-Datei.)
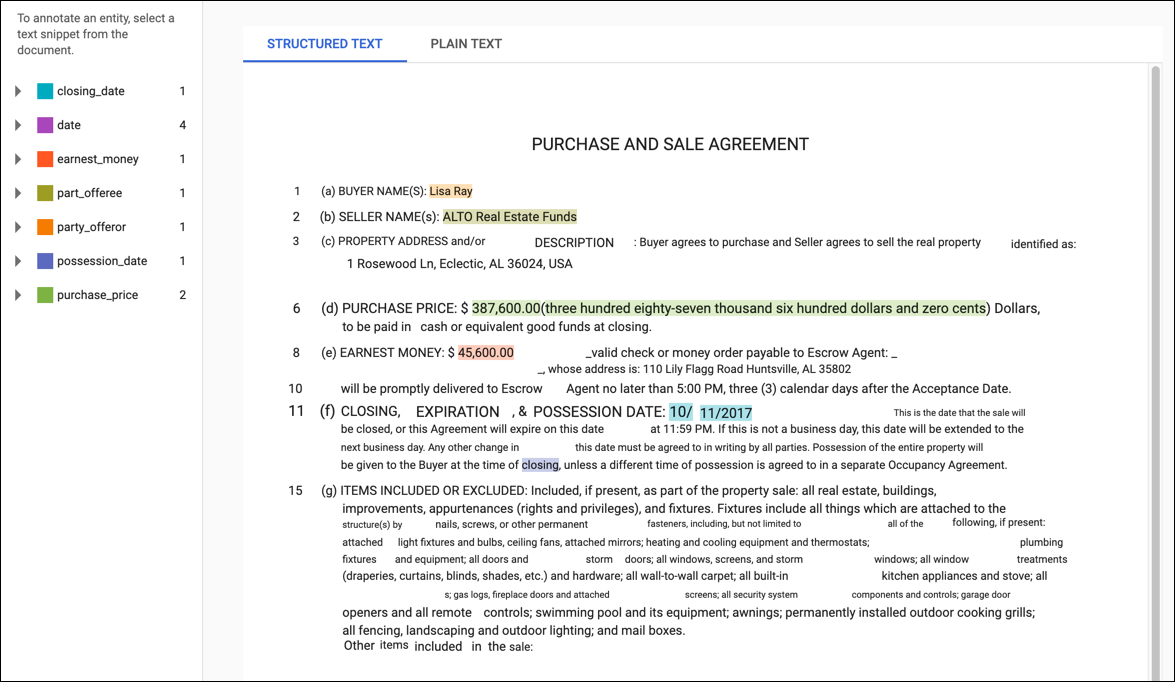
Um eine neue Anmerkung hinzuzufügen, markieren Sie den Text, der die Entität darstellt, wählen Sie das Label aus dem Dialogfeld Annotation und klicken Sie auf Speichern. Wenn Sie Anmerkungen auf dem Tab Strukturierter Text hinzufügen, erfasst AutoML Natural Language die Position der Anmerkung auf der Seite als einen Faktor, der während des Trainings berücksichtigt wird.
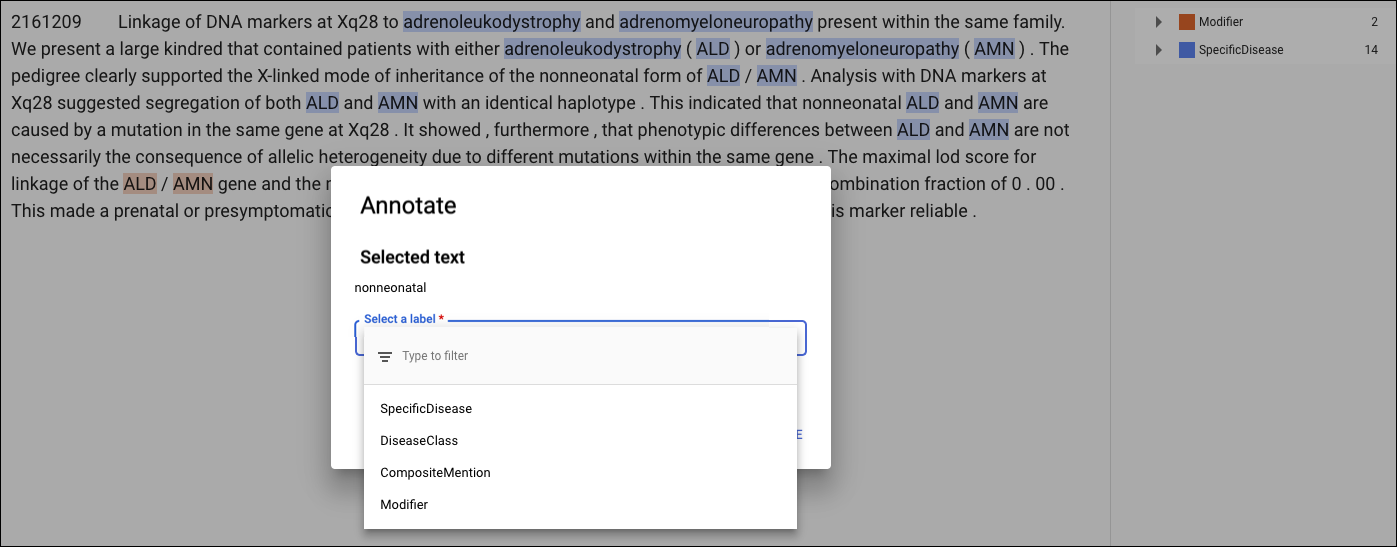
Um eine Anmerkung zu entfernen, suchen Sie den Text in der Liste der Labels auf der rechten Seite und klicken Sie daneben auf das Papierkorbsymbol.