After you have secured and configured your database, you're ready to connect your database to Looker.
You create a database connection in Looker on the Connect your database to Looker page. There are two options for opening the Connect your database to Looker page:
- Select Connections from the Database section in the Admin panel. On the Connections page, click the Add Connection button.
- Click the Create button in the left navigation panel then select the Connection menu item.
For more information about applying user attributes to connection settings, see the Connections section of the User Attributes documentation page.
This page describes common fields that Looker displays on the Connect your database to Looker page. The exact fields that the page displays depend on your dialect setting.
Click here to see the links for the dialect-specific instructions in Looker documentation.
- Actian Avalanche
- AlloyDB for PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS for MySQL
- Amazon RDS for PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3+ and 3.1.2+
- Apache Spark 3+
- ClickHouse
- Cloudera Impala 3.1+
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- Firebolt
- Google BigQuery Legacy SQL
- Google BigQuery Standard SQL
- Google Cloud SQL for MySQL
- Google Cloud SQL for PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 on AS400
- IBM DB2 on LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL Database
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- MongoDB Connector for BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (formerly MemSQL)
- Snowflake
- Teradata
- Trino
- Vector
- Vertica
Once you have entered your database connection settings, you can select the Test button on the Connect your database to Looker page to test the connection and make sure that it's configured correctly. Click Test to verify that the connection is successful. See the Testing database connectivity documentation page for troubleshooting information. If Looker displays Can Connect, press Connect to create the connection. Your database connection is then added to the list on the Looker Connections admin page.
General settings
Name
The name of the connection as you want to refer to it. You need this database connection name to use in the connection parameter of your LookML model. The database connection name is also how the connection is identified on the Connections Admin page of Looker. Don't use the name of any folders for this setting. This value doesn't need to match anything in your database; Name is a label that identifies this connection within the Looker UI.
Connection scope
Select whether the connection should be able to be used with all projects or with only one project:
- All Projects: All LookML projects on the instance can have access to the connection, so the connection name can be specified in the
connectionparameter of model files in that project. - Selected Project: Only one LookML project on the instance can have access to the connection. When you select this option, the Connection screen displays a drop-down menu of the projects on the instance. Select the project that can have access to this connection.
Use this option alongside the following permissions to delegate connection management and model configuration:
Dialect
The SQL dialect that matches your connection. It's important to choose the correct value so that you are presented with the proper connection options, and so that Looker can properly translate your LookML into SQL.
Billing Project ID
For Google BigQuery connections only, the Billing Project ID is the Google Cloud project ID.
Host
Your database hostname that Looker should use to connect to your database host.
If you worked with a Looker analyst to configure an SSH tunnel to your database, in the Host field, enter "localhost".
Port
Your database port that Looker should use to connect to your database host.
If you worked with a Looker analyst to configure an SSH tunnel to your database, in the Port field, enter the port number that redirects to your database, which your Looker analyst should have provided.
Database
The name of the database on your host. For example, you might have a hostname of my-instance.us-east-1.redshift.amazonaws.com on which there is a database called sales_info. You would enter sales_info in this field. If you have multiple databases on the same host, you may need to create multiple connections to use them (with the exception of MySQL, in which the word database means something a little bit different than in most SQL dialects).
Schema
The default schema that Looker uses when a schema is not specified. This applies when you're using SQL Runner, during LookML project generation, and when you're querying tables.
Authentication
For Google BigQuery, Snowflake, Trino, and Databricks connections, select the type of authentication that you want Looker to use to access your database:
- For Google BigQuery connections, you have the option to configure OAuth or a service account for Looker to use to authenticate to your database.
- For Snowflake, Trino, and Databricks connections, you have the option to configure OAuth or a database account for Looker to use to authenticate to your database.
When you use OAuth, your users are required to sign in to your database to issue queries from Looker. For more information on configuring OAuth on a connection to Looker, see the Google BigQuery, Snowflake, Trino, or Databricks connection procedures.
Username
The username from a user account on your database that Looker can use to connect to your database.
Password
The password from a user account on your database that Looker can use to connect to your database.
Optional Settings
SSH Server
The SSH Server option is available only if the instance is deployed on Kubernetes infrastructure, and only if the ability to add SSH server configuration information to your Looker instance has been enabled. If this option is not enabled on your Looker instance and you want to enable it, contact a Google Cloud sales specialist or open a support request.
The SSH server automatically chooses the localhost port for you, and it is not possible to specify the localhost port. If you need to create an SSH connection that requires you to specify a localhost port, open a support request.
To connect to your database using an SSH tunnel, turn on the toggle and select an SSH server configuration from the drop-down list.
Local Port
By default, Looker automatically selects an available local port for the SSH Tunnel. To manually choose a local port, select Manual Entry and enter a port number into the Custom Local Port field. Make sure that the local port is available on your instance.
Persistent Derived Tables (PDTs)
Enable PDTs
Turn on the Enable PDTs toggle to enable persistent derived tables. When PDTs are enabled, the Connection window reveals additional PDT fields and the PDT Overrides section. Looker displays the Enable PDTs toggle only if the database dialect supports using PDTs.
Note the following about PDTs:
- PDTs are not supported for Snowflake connections that use OAuth.
- Disabling PDTs on a connection does not disable the datagroups that are associated with your PDTs. Even if you disable PDTs, existing datagroups will still run their
sql_triggerqueries against the database. If you want to stop a datagroup from running itssql_triggerquery against your database, you must delete or comment out thedatagroupparameter from your LookML project, or you can update the Datagroup and PDT Maintenance Schedule setting for the connection so that Looker checks PDTs and datagroups very infrequently or never. - For Snowflake connections, Looker sets the value for the
AUTOCOMMITparameter toTRUE(Snowflake's default value).AUTOCOMMITis required for SQL commands that Looker runs to maintain its PDT registration system.
Temp Database
Although this is labeled Temp Database, you'll enter either the database name or schema name — as appropriate for your SQL dialect — that Looker should use to create persistent derived tables. You should configure this database or schema ahead of time, with the appropriate write permissions. On the Database configuration instructions documentation page, select your database dialect to see the instructions for that dialect.
Each connection must have its own Temp Database or Schema; they cannot be shared across connections.
Max number of PDT builder connections
The Max number of PDT builder connections setting lets you specify how many concurrent table builds the Looker regenerator can initiate on your database connection. The Max number of PDT builder connections setting applies only to the types of tables for which the Looker regenerator initiates rebuilds:
- Trigger-persisted tables (persistent derived tables and aggregate tables that use the
datagroup_triggerorsql_trigger_valuepersistence strategy). - Persisted tables that use the
persist_forstrategy, but only when thepersist_fortable is part of a cascade of derived tables where it is depended on by a table that uses thedatagroup_triggerorsql_trigger_valuepersistence strategy. In this case, the Looker regenerator will rebuild apersist_fortable, since the table is needed to rebuild another table in the cascade. Otherwise, the regenerator does not initiate builds forpersist_fortables.
The Max number of PDT builder connections setting defaults to 1 but may be set as high as 10. However, the value cannot be higher than the value set in the Max connections per node field or in the per-user-query-limit set in Looker's startup options.
Set this value carefully. If the value is too high, you may overwhelm your database. If the value is low, then long-running PDTs or aggregate tables can delay the creation of other persistent tables or slow down other queries on the connection. Databases that support multi-tenancy — such as BigQuery, Snowflake, and Redshift — may be more performant in handling parallel query builds.
If you want to increase the Max number of PDT builder connections setting, a good rule of thumb is to increase it by an increment of 1. If any unexpected behavior occurs, set it back to the default of 1. Otherwise, if query performance isn't impacted, you can continue raising it incrementally by 1 and verifying the performance at each increment before further increasing the setting.
Note the following about the Max number of PDT builder connections setting:
- The Max number of PDT builder connections setting applies only to connections required for the rebuilding of tables, not to the connections needed for trigger checks. A trigger check is a query that checks whether the table's persistence strategy is triggered; because these trigger check queries are always run sequentially, the Max number of PDT builder connections setting does not apply.
- In a clustered Looker instance, the regenerator runs only on the main node. The Max number of PDT builder connections setting applies only to the main node, and therefore sets the limit for the entire cluster.
- The Max number of PDT builder connections setting does not apply to the following types of tables. These types of tables are built consecutively:
- Tables persisted through the
persist_forparameter (unless the table is depended on by tables using thedatagroup_triggerorsql_trigger_valuestrategies). - Tables in Development Mode.
- Tables rebuilt with the Rebuild Derived Tables & Run option.
- Tables where one depends on another in a dependency cascade. A table cannot build at the same time as a table it depends on. For example, if
table_Bdepends ontable_A, thentable_Amust finish rebuilding beforetable_Bcan start to rebuild.
- Tables persisted through the
Datagroup and PDT Maintenance Schedule
The Looker regenerator checks datagroups and persisted tables (both aggregate tables and persistent derived tables) that are based on sql_trigger_value. Based on these checks, the Looker regenerator rebuilds or drops persisted tables from the scratch schema of your database.
The Datagroup and PDT Maintenance Schedule value sets the cron interval for the Looker regenerator. The Looker regenerator initiates a regenerator cycle to check datagroups and persisted tables on the cron interval. If a Looker regenerator cycle is still in progress at the next cron interval, the Looker regenerator will complete the regenerator cycle that is in progress and then wait until the subsequent cron interval to begin the next regenerator cycle.
The Datagroup and PDT Maintenance Schedule setting accepts a cron expression. The default value is */5 * * * *, which means that the Looker regenerator cycle will initiate a cycle on the five-minute interval, if the previous regenerator cycle has completed. If the previous regenerator cycle has not completed, the Looker regenerator will initiate on the next five-minute interval after its cycle completes.
The default of five minutes is also the most frequent interval supported for Datagroup and PDT Maintenance Schedule. Looker does not enforce a maximum interval for Datagroup and PDT Maintenance Schedule, which means you can extend the interval between Looker regenerator cycles for as long as can be specified by a cron expression. Keep in mind that longer Looker regenerator cycles can adversely affect the freshness of the data in your cache and persisted tables.
After the Looker regenerator completes all the checks and PDT rebuilds in a cycle, it will wait for the next cron interval to initiate the next cycle. If you have long-running PDT builds, you may have long periods between Looker regenerator cycles. Other factors can affect the time that is required to rebuild your tables, as described in the Important considerations for implementing persisted tables section on the Derived tables in Looker page.
If your database isn't up 24/7, you may want to limit checks to times when the database is up. Here are some additional cron expressions:
cron expression |
Definition |
|---|---|
*/5 8-17 * * MON-FRI |
Check datagroups and PDTs every 5 minutes during business hours, Monday through Friday |
*/5 8-17 * * * |
Check datagroups and PDTs every 5 minutes during business hours, every day |
0 8-17 * * MON-FRI |
Check datagroups and PDTs every hour during business hours, Monday through Friday |
1 3 * * * |
Check datagroups and PDTs every day at 3:01am |
A few things to note when you create a cron expression:
- Looker uses parse-cron v0.1.3, which doesn't support
?incronexpressions. - The
cronexpression uses the Looker application timezone to determine when checks are made. - If PDTs aren't being built, reset the cron string back to the default of
*/5 * * * *.
The following are some resources to assist with creating cron strings:
- https://crontab.guru — Help editing and testing
cronstrings. - http://www.crontab-generator.org — Select time settings and the generator creates the corresponding
cronstring.
Retry failed PDT builds
The Retry failed PDT builds toggle configures how the Looker regenerator attempts to rebuild trigger-persisted tables that failed in the previous regenerator cycle. The Looker regenerator is the process that rebuilds trigger-persisted tables (PDTs and aggregate tables) according to the interval that is configured in the Datagroup and PDT Maintenance Schedule connection setting. When the Retry Failed PDT Builds toggle is enabled, the Looker regenerator will attempt to rebuild a PDT that failed in the previous regenerator cycle, even if the PDT's trigger condition is not met. When this setting is disabled, the Looker regenerator will attempt to rebuild a previously failed PDT only when the PDT's trigger condition is met. Retry Failed PDT Builds is disabled by default.
See the Derived tables in Looker documentation page for more information on the Looker regenerator.
PDT API Control
The PDT API Control toggle determines whether the start_pdt_build, check_pdt_build, and stop_pdt_build API calls can be used for this connection. When the PDT API Control toggle is disabled, these API calls will fail when they reference PDTs on this connection. The PDT API Control toggle is disabled by default.
PDT Overrides
If your database supports persistent derived tables, and you have turned on the Enable PDTs toggle in the connection settings, Looker displays the PDT Overrides section. In the PDT Overrides section, you can enter separate JDBC parameters (host, port, database, username, password, schema, additional parameters, and after connect statements) that are specific to PDT processes. This can be valuable for a number of reasons:
- By creating a separate database user for PDT processes, you can use PDTs in your Looker project even if you assign user attributes to your database login credentials or use OAuth for your database connection.
- PDT processes can authenticate through a separate database user who has a higher priority. This way the database can prioritize the PDT jobs over less-critical user queries.
- Write access can be revoked for the standard Looker database connection, and only granted to a special user that PDT processes will use for authentication. This is a better security strategy for most organizations.
- For databases such as Snowflake, PDT processes can be routed to more powerful hardware that is not shared with the rest of the Looker users. This way, PDTs can build quickly without incurring the cost of running expensive hardware full-time.
For example, the following configuration shows a connection where the username and password fields are set to user attributes. This way, each user can access the database using their individual credentials. The PDT Overrides section creates a separate user (pdt_user) with its own password. The pdt_user account will be used for all PDT processes, with access levels appropriate to PDT creation and update.
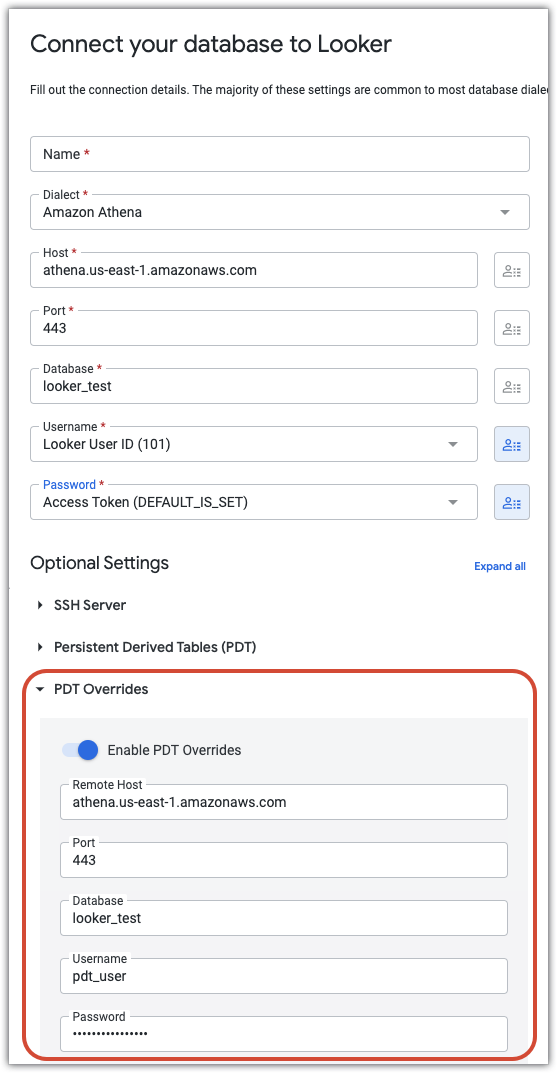
Time Zone
Database Time Zone
The time zone in which your database stores time-based information. Looker needs to know this so that it can convert time values for users, making it easier to understand and use time-based data. See the Using time zone settings documentation page for more information.
Query Time Zone
The Query Time Zone option is visible only if you have disabled User Specific Time Zones.
When User Specific Time Zones are disabled, the Query Time Zone is the time zone that displays to your users when they query time-based data, and the time zone into which Looker will convert time-based data from the Database Time Zone.
See the Using time zone settings documentation page for more information.
Additional Settings
Additional JDBC parameters
You can include additional Java Database Connectivity (JDBC) parameters for your queries here, if needed.
To reference a user attribute in a JDBC parameter, use the Liquid templating syntax: _user_attributes['name_of_attribute']. For example:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Max connections per node
Here you can set the maximum number of connections that Looker can establish with your database. For the most part, you are setting the number of simultaneous queries that Looker can run against your database. Looker also reserves up to three connections for query killing. If the connection pool is very small, then Looker will reserve fewer connections.
Set this value carefully. If the value is too high, then you may overwhelm your database. If the value is too low, then queries have to share a small number of connections. Thus many queries may seem slow to users as the queries have to wait for other, earlier queries to return.
The default value (which varies depending upon your SQL dialect) is typically a reasonable starting point. Most databases also have their own settings for the maximum number of connections they will accept. If your database configuration limits connections, ensure that your Max Connections per node value is equal to or lower than your database's limit.
Connection Pool Timeout
If your users do request more connections than the Max Connections per node setting, the requests will wait for others to finish before they are executed. The maximum amount of time that a request will wait is configured here. The default setting is 120 seconds.
You should set this value carefully. If it is too low, users may find their queries get cancelled because there isn't enough time for other users' queries to finish. If it is too high, large numbers of queries may build up, causing users to wait for a very long time. The default value is typically a reasonable starting point.
SSL
Choose whether or not you want to use SSL encryption to protect data as it passes between Looker and your database. SSL is only one option that can be used to protect your data; other secure options are described on the Enabling secure database access documentation page.
Verify SSL
Choose whether you want to require verification of the SSL certificate used by the connection. If verification is required, the SSL Certificate Authority (CA) that signed the SSL certificate must come from the client's list of trusted sources. If the CA is not a trusted source, the database connection is not established.
If this box is not selected, SSL encryption is still used on the connection, but verification of the SSL connection is not required, so a connection can be established when the CA is not on the client's list of trusted sources.
SQL Runner Precache
In SQL Runner, all table information is pre-loaded as soon as you select a connection and schema. This enables SQL Runner to quickly display table columns as soon as you click a table name. However, for connections and schema with many tables or with very large tables, you may not want SQL Runner to pre-load all the information.
If you prefer SQL Runner to load table information only when a table is selected, you can deselect the SQL Runner Precache option to disable SQL Runner pre-loading for the connection.
Fetch Information Schema For SQL Writing
For some SQL-writing features such as aggregate awareness, Looker uses your database's information schema to optimize SQL writing. If the information schema is not cached, Looker may have to occasionally block SQL writing to the database to be able to fetch the information schema. For dialects that use Hadoop Distributed File System (HDFS), fetching the information schema may take long enough to significantly affect the performance of your Looker queries. If you know that your information schema is slow, you can disable the Fetch Information Schema For SQL Writing option for your connection. Disabling this feature will prevent some of the Looker SQL optimization for certain features, so you should enable the Fetch Information Schema For SQL Writing option unless you know that your connection's information schema is particularly slow.
Cost Estimate
The Cost Estimate toggle applies to the following database connections only:
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL for PostgreSQL, and Microsoft Azure PostgreSQL
The Cost Estimate toggle enables the following features on the connection:
- Cost estimates for Explore queries
- Cost estimates for SQL Runner queries
- Computation savings estimates for aggregate awareness queries
See the Exploring data in Looker documentation page for more information.
Database Connection Pooling
For dialects that support database connection pooling, this feature allows Looker to use pools of connections through the JDBC driver. Database connection pooling enables faster query performance; a new query does not need to create a new database connection but can instead use an existing connection from the connection pool. The connection pooling capability ensures that a connection is cleaned up after a query execution and is available for reuse after the query execution ends. See the Database connection pooling documentation page for more information.
Testing your connection settings
You can test your connection settings from a couple places in the Looker UI:
- Select the Test button at the bottom of the Connections Settings page.
- Select the Test button by the connection's listing on the Connections admin page, as described on the Connections documentation page.
Once you've entered the connection settings, click Test to verify that the information is correct and the database is able to connect.
If your connection does not pass one or more tests, here are some troubleshooting options:
- Try some of the troubleshooting steps on the Testing database connectivity documentation page.
- If you are running Mongo version 3.6 or earlier on Atlas and you get a communications link failure, see the Mongo Connector documentation page.
- To receive successful connection messages regarding the temp schema and PDTs, you must allow that functionality when you set up your Looker database. Instructions for doing so can be found on the Database configuration instructions documentation page.
If you are still having trouble, contact Looker Support for assistance.
Test as user
If you have set one or more connection parameter values to a user attribute, then the Test as User option will appear. Select a user and then click Test to verify that the database can connect and run queries as this user.
Next steps
After you have connected your database to Looker, you're ready to configure sign-in options for your users.