Ce document fournit les informations dont vous avez besoin pour vous aider à décider si vous souhaitez envoyer des journaux d'application à Cloud Logging de façon automatisée à l'aide de bibliothèques clientes ou d'un agent de journalisation. Les agents de journalisation envoient les données écrites dans un fichier, tel que stdout ou un fichier, sous forme de journaux à Cloud Logging. Des services tels que Google Kubernetes Engine, l'environnement flexible App Engine et les fonctions Cloud Run contiennent un agent de journalisation intégré. Pour Compute Engine, vous pouvez installer l'agent Ops ou l'ancien agent Cloud Logging.
Ces agents collectent les journaux à partir d'emplacements de fichiers ou de services de journalisation connus, tels que Windows Event Log, journald ou syslogd.
Lorsque vous ne pouvez pas utiliser de bibliothèque cliente ni d'agent Logging, ou lorsque vous souhaitez simplement effectuer des tests, vous pouvez écrire des journaux à l'aide de la commande gcloud logging write ou en envoyant des commandes HTTP au point de terminaison de l'API Cloud Logging entries.write.
L'API Cloud Logging est compatible avec les appels HTTP et gRPC. L'agent Ops et la plupart des bibliothèques clientes Logging appellent l'API gRPC Logging. Pour certains langages, l'ancien agent Logging et les bibliothèques clientes appellent l'API REST Logging.
Choisir un agent ou des bibliothèques clientes
Lorsque vous décidez entre un agent et les bibliothèques clientes, posez-vous les questions suivantes :
- Votre application s'exécute-t-elle en dehors de Google Cloud ?
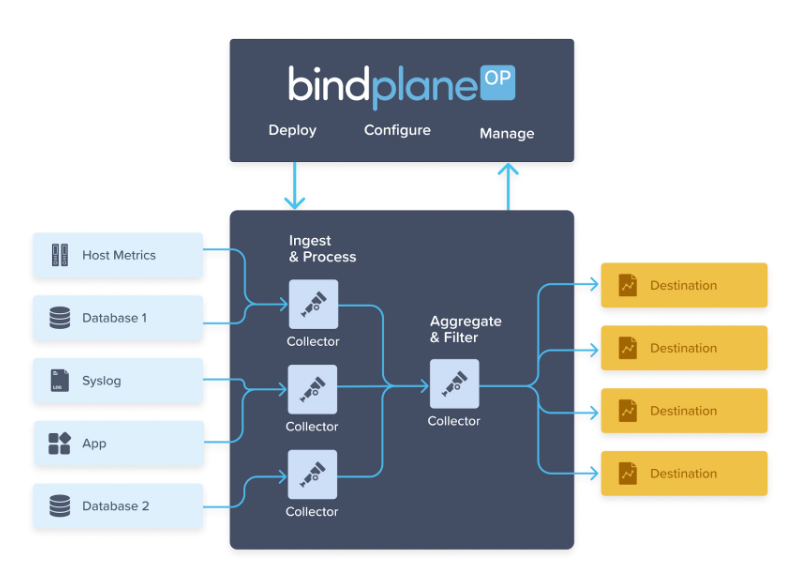
Si votre application ne s'exécute pas sur Google Cloud, vous devez pouvoir envoyer des journaux à l'API Logging. Pour acheminer les journaux des systèmes sur site vers Logging, nous vous recommandons d'utiliser Bindplane, qui déploie et gère des collecteurs OpenTelemetry pour envoyer des données de télémétrie à Google Cloud. Pour en savoir plus, consultez la section À propos de Bindplane.
Vous pouvez également acheminer les journaux vers Logging directement à partir de l'application à l'aide de bibliothèques clientes. Pour les environnements éphémères, tels que l'informatique sans serveur, vous devez utiliser des bibliothèques clientes pour appeler directement l'API Logging.
- Le service Google Cloud qui exécute votre application est-il compatible avec
- écrire du contenu
stdoutetstderrdans votre projet ? Certains Google Cloud services sont entièrement gérés. Vous n'avez donc pas besoin d'utiliser d'agents pour envoyer des journaux à votre Google Cloud projet. Vous pouvez utiliser n'importe quel framework de journalisation établi dans le langage de votre choix, tel que Go, Node.js et Python, pour envoyer des journaux à Logging dans des produits où
stdoutetstderrsont disponibles par défaut. L'ingestion de journaux viastdoutetstderrau lieu d'utiliser des bibliothèques clientes présente l'avantage de ne pas interrompre l'envoi de journaux à votre projet. Pour en savoir plus sur l'envoi de journaux structurés viastdoutetstderr, consultez la section Votre application peut-elle modifier le format des journaux ?.Vous pouvez utiliser les bibliothèques clientes Logging, mais gardez à l'esprit qu'elles peuvent introduire une dépendance à Logging pour les tests locaux lorsque vous n'en avez pas nécessairement besoin. L'utilisation des bibliothèques clientes peut également nécessiter un codage plus complexe pour gérer explicitement la mise en mémoire tampon et les nouvelles tentatives. En outre, chaque utilisation des bibliothèques clientes de Logging crée un flux de connexion à l'API. Ces nouvelles connexions accroissent la complexité, utilisent des ports supplémentaires et n'envoient des requêtes distinctes qu'avec les journaux de l'application, ce qui peut être inutile s'il y a peu de journaux.
- Les journaux d'application doivent-ils être accessibles dans votre environnement local ?
Si vous devez accéder aux journaux d'application dans votre environnement local à des fins de débogage et autres, vous pouvez utiliser les modules de journalisation dans certains langages pour générer les données
stdoutetstderr. Les bibliothèques clientes de Logging pour certains langages sont compatibles avec le routage des journaux versstdoutetstderr.Lorsque vous exécutez votre application dans des services Google Cloud qui ne permettent pas d'envoyer automatiquement les journaux écrits dans
stdoutetstderrà votre projetGoogle Cloud , vous pouvez collecter les journauxstdoutetstderrsur le disque et configurer l'agent pour les scraper et les envoyer à Logging. Pour en savoir plus, consultez le guide de configuration de l'agent Ops ou de l'ancien agent Logging.- Le processus d'installation de l'agent est-il manuel ou automatique ?
Certains services installent les agents automatiquement ou vous permettent d'installer les agents vous-même. Si le service que vous utilisez ne vous permet pas d'installer des agents, vous devez utiliser les bibliothèques clientes pour utiliser Logging.
- Exécutez-vous déjà Fluentd dans votre système ?
L'ancien agent Logging est basé sur Fluentd.
Si Fluentd est déjà en cours d'exécution sur votre système et que vous souhaitez utiliser ce daemon pour envoyer vos journaux à Logging, utilisez le plug-inGoogle Cloud Logging pour fluentd.
- Collectez-vous également des métriques d'application pour Cloud Monitoring ?
Dans les VM Compute Engine, l'agent Ops peut collecter les journaux et la plupart des métriques. Pour en savoir plus, consultez la section Fonctionnalités de l'agent Ops.
Si l'Agent Ops ne répond pas à vos cas d'utilisation, vous pouvez utiliser l'ancien agent Monitoring ou les bibliothèques clientes Monitoring pour collecter vos métriques.
- Votre application peut-elle modifier le format des journaux ?
Cette question vous aide à déterminer si votre application peut générer des journaux structurés. Logging reconnaît les journaux structurés si vous les envoyez à l'API Logging au format de journalisation structurée. Les bibliothèques clientes fournissent les méthodes permettant de gérer ce format.
Il existe deux façons d'écrire des journaux structurés : la première consiste à définir des champs spécifiques dans l'enveloppe
LogEntryet l'autre à définir le champjsonPayloaddans l'enveloppeLogEntry. Le premier schéma est déterminé par Cloud Logging, tandis que le second est déterminé par l'utilisateur.Vous devez configurer l'agent pour qu'il reconnaisse les journaux structurés. Par défaut, les agents sont configurés pour détecter les journaux au format JSON et les gérer en tant que journaux structurés. Si votre application possède son propre format de journal que vous ne pouvez pas modifier, mais que vous souhaitez que les journaux soient reconnus comme des journaux structurés, vous devez écrire les journaux au format de journalisation structurée, généralement au format JSON., vers
stdoutetstderr, afin que les agents puissent les reconnaître en tant que journaux structurés. Sinon, vous devez configurer votre agent pour qu'il comprenne votre propre format.
Récapitulatif de chaque option
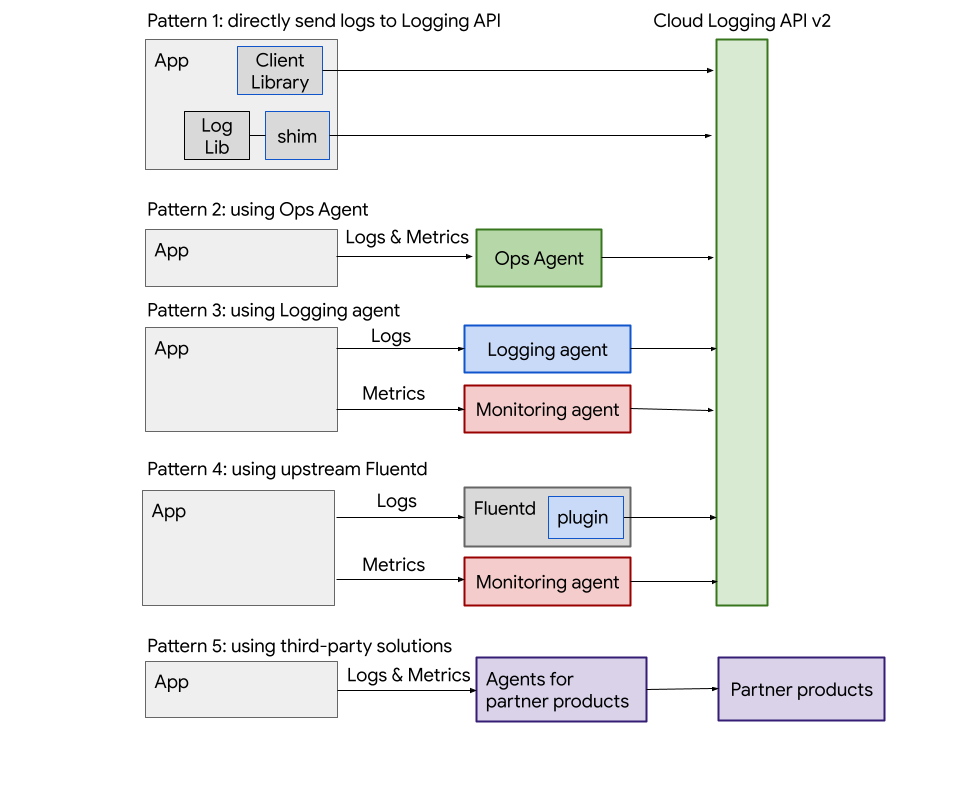
Bibliothèques clientes Cloud Logging
Avantages
- Vous pouvez acheminer les journaux directement vers l'API Cloud Logging.
- Certains langages peuvent générer des journaux vers
stdoutetstderrà l'aide de la bibliothèque.
Inconvénients
- Les plantages de l'application interrompent l'envoi des journaux à votre Google Cloud projet.
Agent Ops
Avantages
- L'agent Ops peut envoyer des journaux et des métriques à l'aide de technologies Open Source stables: Fluent Bit pour la collecte de journaux et OpenTelementry Collector pour la collecte de métriques.
- Vous pouvez collecter à la fois des journaux et des métriques à partir de nombreuses applications courantes. Pour en savoir plus, consultez Surveiller et collecter les journaux d'applications tierces.
- Vous pouvez conserver les journaux dans votre environnement local.
- Vous devriez pouvoir récupérer les journaux des plantages de l'application.
- L'Agent Ops est en cours de développement.
Inconvénients
- Fluent Bit n'est compatible qu'avec l'encodage UTF-8. Il n'est pas compatible avec la conversion d'encodage.
Ancien agent Logging
- Avantages
- L'agent utilise Fluentd pour collecter les journaux, ce qui permet la conversion d'encodage.
- Vous pouvez conserver les journaux dans votre environnement local.
- Vous devriez pouvoir récupérer les journaux des plantages de l'application.
- Inconvénients
- L'agent est actuellement compatible, mais n'est pas en cours de développement actif.
- Avantages
Les journaux
stdoutetstderrsont automatiquement envoyés à votre Google Cloud projet.- Avantages
- Ce processus est un moyen courant d'émettre des journaux vers des environnements locaux.
- Vous pouvez utiliser des bibliothèques de journalisation arbitraires.
- Vous devriez pouvoir récupérer les journaux des plantages de l'application.
- Inconvénients
- Certains environnements n'acheminent pas les journaux vers Logging automatiquement.
- Avantages