Auf dieser Seite wird beschrieben, wie Sie Probleme im Zusammenhang mit dem Load-Balancing in Google Kubernetes Engine-Clustern (GKE) mithilfe von Dienst-, Ingress- oder Gateway-Ressourcen beheben.
BackendConfig wurde nicht gefunden
Dieser Fehler tritt auf, wenn in der Dienstannotation eine BackendConfig-Ressource für einen Dienstport angegeben wurde, die eigentliche BackendConfig-Ressource jedoch nicht gefunden werden konnte.
Führen Sie den folgenden Befehl aus, um ein Kubernetes-Ereignis auszuwerten:
kubectl get event
Die folgende Ausgabe zeigt an, dass Ihre BackendConfig nicht gefunden wurde:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Achten Sie zur Behebung dieses Problems darauf, dass Sie die BackendConfig-Ressource nicht im falschen Namespace erstellt oder ihren Verweis in der Dienstannotation falsch geschrieben haben.
Ingress-Sicherheitsrichtlinie nicht gefunden
Wenn die Sicherheitsrichtlinie nach der Erstellung des Ingress-Objekts nicht ordnungsgemäß dem Load-Balancer-Dienst zugeordnet wird, sollten Sie das Kubernetes-Ereignis auf Konfigurationsfehler prüfen. Wenn Ihre BackendConfig eine Sicherheitsrichtlinie angibt, die nicht vorhanden ist, wird regelmäßig ein Warnungsereignis ausgegeben.
Führen Sie den folgenden Befehl aus, um ein Kubernetes-Ereignis auszuwerten:
kubectl get event
Die folgende Ausgabe zeigt an, dass Ihre Sicherheitsrichtlinie nicht gefunden wurde:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Geben Sie zur Behebung dieses Problems den richtigen Namen der Sicherheitsrichtlinie in Ihrer BackendConfig an.
500er-Fehler bei NEGs während der Arbeitslastskalierung in GKE beheben
Symptom:
Wenn Sie von GKE bereitgestellte NEGs für den Lastenausgleich verwenden, können bei den Diensten während der Arbeitslastskalierung 502- oder 503-Fehler auftreten. 502-Fehler treten auf, wenn Pods beendet werden, bevor bestehende Verbindungen geschlossen werden, während 503-Fehler auftreten, wenn Traffic an gelöschte Pods weitergeleitet wird.
Dieses Problem kann Cluster betreffen, wenn Sie von GKE verwaltete Load-Balancing-Produkte verwenden, die NEGs nutzen, einschließlich Gateway, Ingress und eigenständige NEGs. Wenn Sie Ihre Arbeitslasten häufig skalieren, ist das Risiko, dass Ihr Cluster betroffen ist, höher.
Diagnose:
Das Entfernen eines Pods in Kubernetes, ohne seinen Endpunkt zu leeren und ihn aus der NEG zu entfernen, führt zu 500-Fehlern. Um Probleme beim Beenden von Pods zu vermeiden, müssen Sie die Reihenfolge der Vorgänge berücksichtigen. Die folgenden Bilder zeigen Szenarien, in denen BackendService Drain Timeout nicht festgelegt ist und in denen BackendService Drain Timeout mit BackendConfig festgelegt ist.
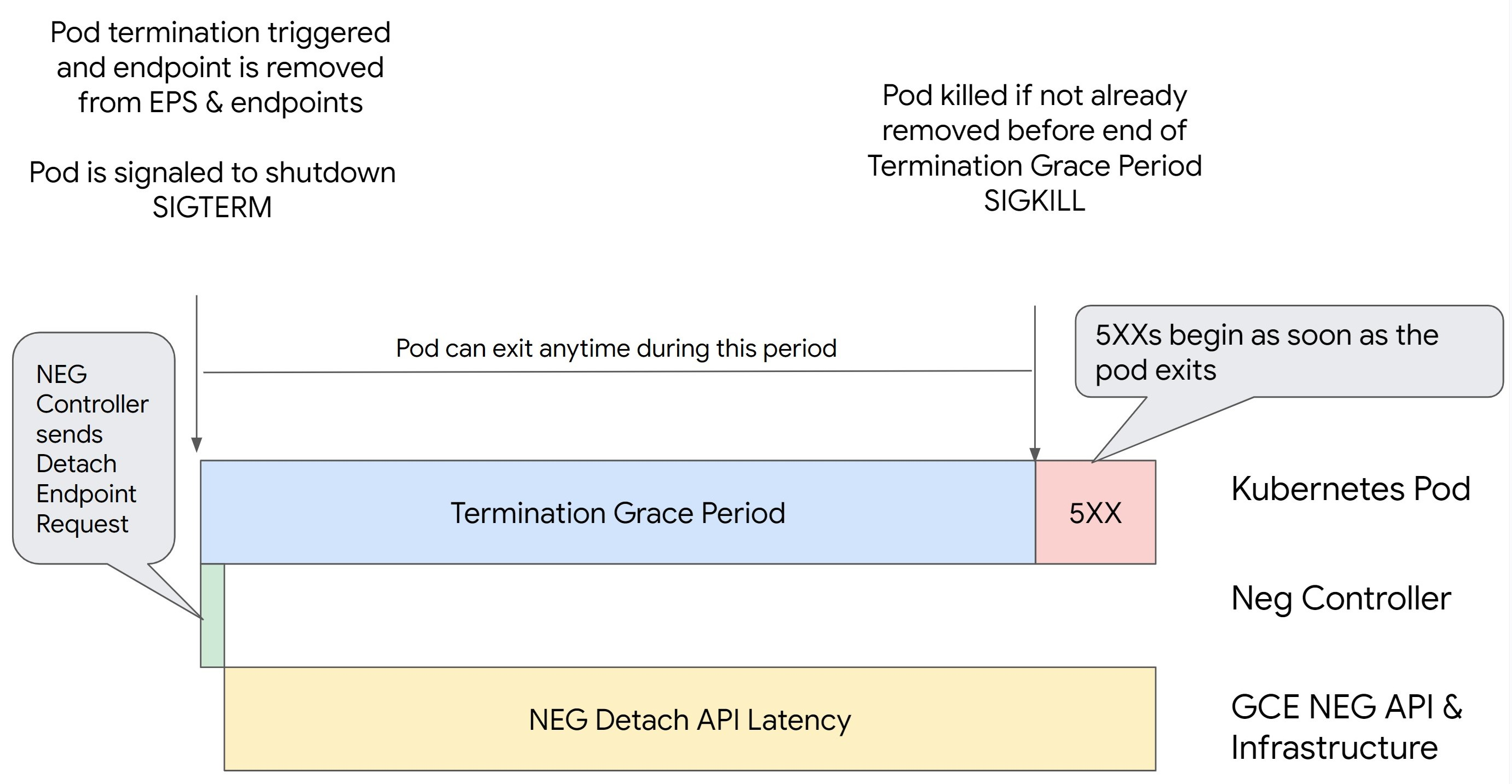
Szenario 1: BackendService Drain Timeout ist nicht festgelegt.
Die folgende Abbildung zeigt ein Szenario, in dem BackendService Drain Timeout nicht festgelegt ist.
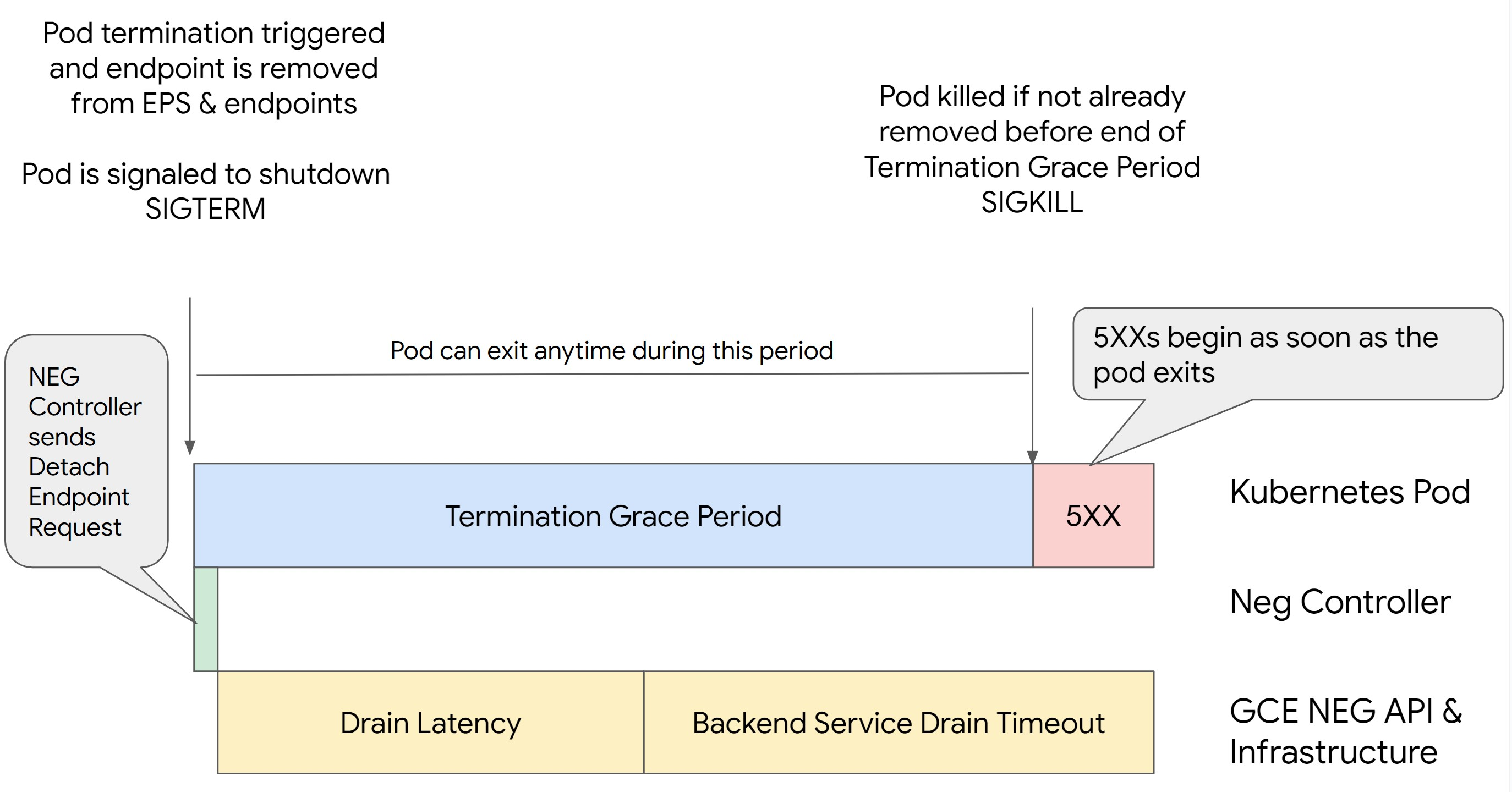
Szenario 2: BackendService Drain Timeout ist festgelegt.
Die folgende Abbildung zeigt ein Szenario, in dem BackendService Drain Timeout festgelegt ist.
Die genaue Zeit, zu der die 500er-Fehler auftreten, hängt von folgenden Faktoren ab:
NEG API-Trennlatenz: Die NEG API-Trennlatenz stellt die aktuelle Zeit dar, die für den Abschluss des Trennvorgangs in Google Cloudbenötigt wird. Dies wird von einer Reihe von Faktoren außerhalb von Kubernetes beeinflusst, darunter der Typ des Load-Balancers und die spezifische Zone.
Drain-Latenz: Die Drain-Latenz ist die Zeit, die der Load-Balancer benötigt, um Traffic von einem bestimmten Teil Ihres Systems wegzuleiten. Nach dem Start des Leerens sendet der Load-Balancer keine neuen Anfragen an den Endpunkt mehr. Es besteht jedoch weiterhin eine Latenz beim Auslösen des Leerens (Drain-Latenz), was zu temporären 503-Fehlern führen kann, wenn der Pod nicht mehr vorhanden ist.
Konfiguration der Systemdiagnose: Sensible Schwellenwerte für Systemdiagnosen verringern die Dauer von 503-Fehlern, da dies dem Load-Balancer signalisieren kann, dass er keine Anfragen mehr an Endpunkte senden soll, auch wenn der Trennvorgang nicht abgeschlossen ist.
Kulanzzeitraum für die Beendigung: Der Kulanzzeitraum für die Beendigung bestimmt die maximale Zeit, die einem Pod zum Beenden gewährt wird. Ein Pod kann jedoch beendet werden, bevor der Kulanzzeitraum für die Beendigung abgelaufen ist. Wenn ein Pod länger als dieser Zeitraum dauert, wird der Pod zum Beenden am Ende dieses Zeitraums gezwungen. Dies ist eine Einstellung für den Pod, die in der Arbeitslastdefinition konfiguriert werden muss.
Mögliche Lösung:
Wenden Sie die folgenden Einstellungen an, um diese 5XX-Fehler zu vermeiden. Die Zeitüberschreitungswerte sind Vorschläge und Sie müssen sie möglicherweise für Ihre spezifische Anwendung anpassen. Im folgenden Abschnitt wird die Anpassung beschrieben.
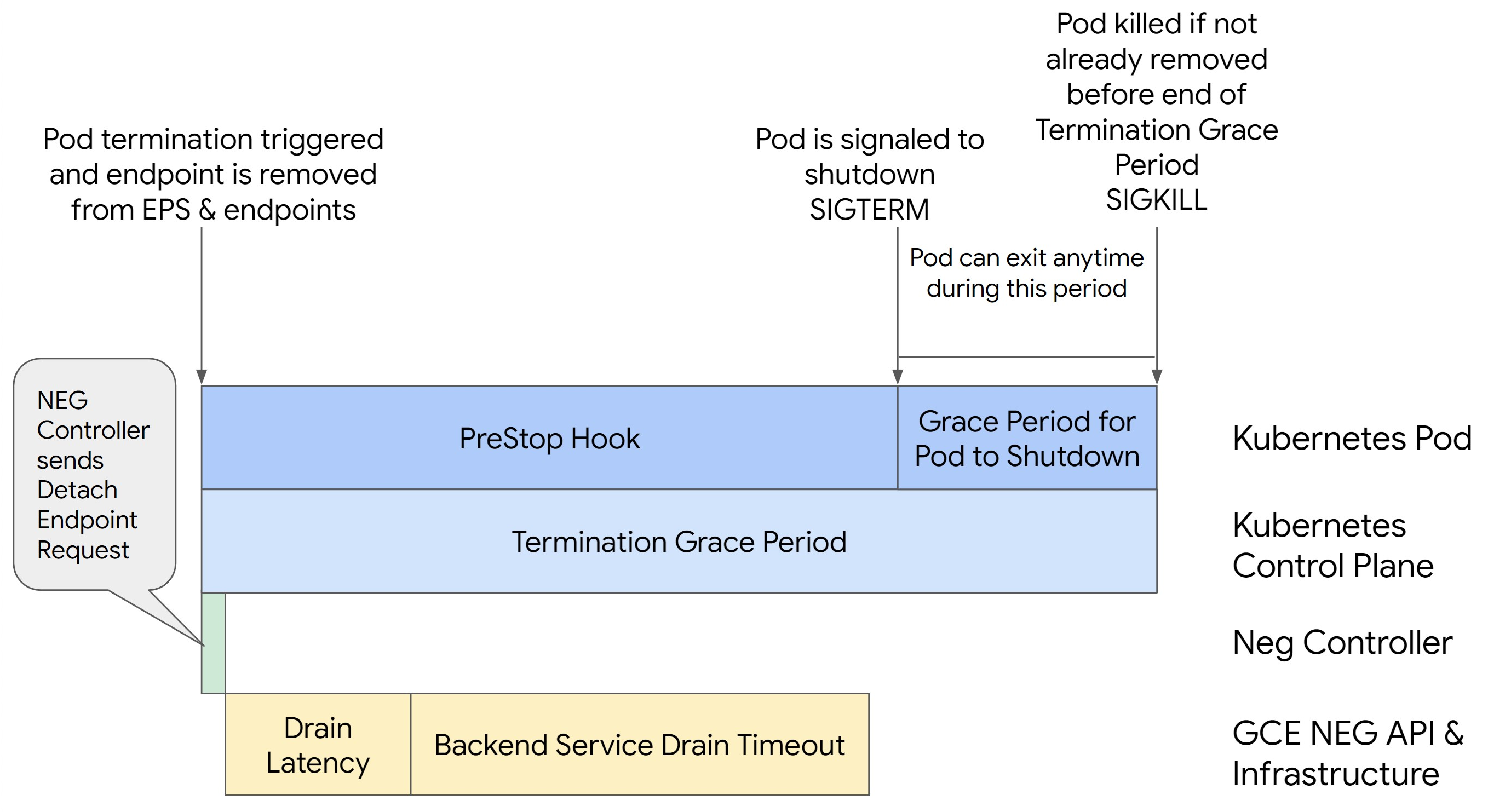
Das folgende Bild zeigt, wie der Pod mit einem preStop-Hook aktiv gehalten wird:
Führen Sie die folgenden Schritte aus, um Fehler der 500er-Serie zu vermeiden:
Legen Sie für
BackendService Drain Timeoutfür Ihren Dienst eine Minute fest.Informationen für Ingress-Nutzer finden Sie unter Zeitlimit für BackendConfig festlegen.
Informationen für Gateway-Nutzer finden Sie unter Zeitlimit in der GCPBackendPolicy konfigurieren.
Wenn Sie Ihre BackendServices bei Verwendung eigenständiger NEGs direkt verwalten, lesen Sie den Abschnitt Zeitlimit direkt für den Backend-Dienst festlegen.
Erweitern Sie
terminationGracePeriodauf dem Pod.Legen Sie die
terminationGracePeriodSecondsfür den Pod auf 3,5 Minuten fest. In Kombination mit den empfohlenen Einstellungen haben Ihre Pods dadurch ein Fenster von 30 bis 45 Sekunden für ein ordnungsgemäßes Herunterfahren, nachdem der Endpunkt des Pods aus der NEG entfernt wurde. Wenn Sie mehr Zeit für das ordnungsgemäße Herunterfahren benötigen, können Sie die Kulanzfrist verlängern oder der Anleitung im Abschnitt Zeitlimits anpassen folgen.Das folgende Pod-Manifest gibt ein Zeitlimit von 210 Sekunden (3,5 Minuten) für den Verbindungsausgleich an:
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Wenden Sie einen
preStop-Hook auf alle Container an.Wenden Sie einen
preStop-Hook an, der dafür sorgt, dass der Pod 120 Sekunden länger aktiv ist, während der Endpunkt des Pods im Load-Balancer per Drain beendet und der Endpunkt aus der NEG entfernt wird.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Zeitlimits anpassen
Zur Gewährleistung der Pod-Kontinuität und zur Vermeidung von 500-Fehlern muss der Pod aktiv sein, bis der Endpunkt aus der NEG entfernt wird. Um insbesondere 502- und 503-Fehler zu vermeiden, sollten Sie eine Kombination aus Zeitüberschreitungen und einem preStop-Hook implementieren.
Wenn Sie den Pod während des Herunterfahrens länger aktiv halten möchten, fügen Sie dem Pod einen preStop-Hook hinzu. Führen Sie den preStop-Hook aus, bevor einem Pod das Beenden signalisiert wird. Damit kann der preStop-Hook den Pod so lange aktiv halten, bis der entsprechende Endpunkt aus der NEG entfernt wird.
Wenn Sie die Dauer verlängern möchten, in der ein Pod während des Herunterfahrens aktiv bleibt, fügen Sie der Pod-Konfiguration einen preStop-Hook wie folgt hinzu:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Sie können Zeitüberschreitungen und zugehörige Einstellungen konfigurieren, um das ordnungsgemäße Herunterfahren von Pods während des Herunterskalierens von Arbeitslasten zu verwalten. Sie können Zeitüberschreitungen an bestimmte Anwendungsfälle anpassen. Wir empfehlen, mit längeren Zeitüberschreitungen zu beginnen und die Dauer nach Bedarf zu verkürzen. Sie können die Zeitüberschreitungen anpassen, indem Sie zeitüberschreitungsbezogene Parameter und den preStop-Hook auf folgende Weise konfigurieren:
Zeitlimit für Back-End-Drain
Der Parameter Backend Service Drain Timeout ist standardmäßig nicht festgelegt und hat keine Auswirkungen. Wenn Sie den Parameter Backend Service Drain Timeout festlegen und aktivieren, beendet der Load Balancer das Routing neuer Anfragen an den Endpunkt und wartet das Zeitlimit, bevor vorhandene Verbindungen beendet werden.
Sie können den Parameter Backend Service Drain Timeout mit BackendConfig mit Ingress, mit GCPBackendPolicy mit Gateway oder manuell auf dem BackendService mit eigenständigen NEGs festlegen. eine Das Zeitlimit sollte 1,5- bis 2-mal länger sein als die Zeit, die für die Verarbeitung einer Anfrage benötigt wird. Dadurch wird sichergestellt, dass eine Anfrage, die kurz vor dem Drain eingegangen ist, abgeschlossen wird, bevor die Zeitüberschreitung beendet ist. Wenn Sie den Parameter Backend Service Drain Timeout auf einen Wert größer als 0 setzen, können Sie 503-Fehler vermeiden, da keine neuen Anfragen an Endpunkte gesendet werden, die entfernt werden sollen. Damit dieses Zeitlimit wirksam ist, müssen Sie es mit dem preStop-Hook verwenden. So bleibt der Pod während des Drains aktiv. Ohne diese Kombination erhalten bestehende Anfragen, die nicht abgeschlossen wurden, den Fehler 502.
preStop Hook-Zeit
Der preStop-Hook muss das Herunterfahren des Pods so lange verzögern, bis sowohl die Drain-Latenz als auch die Zeitüberschreitung für den Drain des Back-End-Dienstes abgeschlossen sind, sodass ein ordnungsgemäßer Verbindungsausgleich und die Entfernung des Endpunkts vom NEG gewährleistet sind, bevor der Pod heruntergefahren wird.
Damit Sie optimale Ergebnisse erzielen, muss die Ausführungszeit des preStop-Hooks größer oder gleich der Summe der Backend Service Drain Timeout- und Drain-Latenz sein.
Berechnen Sie die ideale Ausführungszeit für den preStop-Hook mit der folgenden Formel:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Ersetzen Sie Folgendes:
BACKEND_SERVICE_DRAIN_TIMEOUT: Die Zeit, die Sie für dieBackend Service Drain Timeoutkonfiguriert haben.DRAIN_LATENCY: Eine geschätzte Zeit für die Latenz beim Leeren. Wir empfehlen, eine Minute als Schätzung zu verwenden.
Wenn 500-Fehler bestehen bleiben, schätzen Sie die Gesamtdauer des Vorkommens und fügen Sie der geschätzten Latenz für die Erschöpfung das Doppelte davon hinzu. Dadurch wird sichergestellt, dass der Pod ausreichend Zeit zum ordnungsgemäßen Drain hat, bevor er aus dem Dienst entfernt wird. Sie können diesen Wert anpassen, wenn er für Ihren speziellen Anwendungsfall zu lang ist.
Alternativ können Sie den Zeitpunkt schätzen, indem Sie den Löschzeitstempel des Pods und den Zeitstempel, an dem der Endpunkt aus der NEG entfernt wurde, in den Cloud-Audit-Logs prüfen.
Parameter für den Kulanzzeitraum bei Kündigung
Sie müssen den Parameter terminationGracePeriod so konfigurieren, dass der preStop-Hook genügend Zeit hat, um abgeschlossen zu werden, und der Pod ordnungsgemäß heruntergefahren werden kann.
Wenn nicht explizit festgelegt, beträgt die terminationGracePeriod standardmäßig 30 Sekunden.
Sie können den optimalen Wert für terminationGracePeriod mit der folgenden Formel berechnen:
terminationGracePeriod >= preStop hook time + Pod shutdown time
So definieren Sie terminationGracePeriod in der Konfiguration des Pods:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG beim Erstellen einer internen Ingress-Ressource nicht gefunden
Der folgende Fehler kann auftreten, wenn Sie ein internes Ingress in GKE erstellen:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Dieser Fehler tritt auf, weil Ingress für interne Anwendungs-Load-Balancer Netzwerk-Endpunktgruppen (NEGs) als Back-Ends erfordert.
In Umgebungen mit freigegebener VPC oder Clustern mit aktivierten Netzwerkrichtlinien müssen Sie die Annotation cloud.google.com/neg: '{"ingress": true}' dem Servicemanifest hinzufügen.
504 Gateway-Zeitüberschreitung: Upstream-Zeitüberschreitung bei Anfrage
Der folgende Fehler kann auftreten, wenn Sie über einen internen Ingress in GKE auf einen Dienst zugreifen:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Dieser Fehler tritt auf, weil Traffic, der an interne Anwendungs-Load-Balancer gesendet wird, von Envoy-Proxys im Nur-Proxy-Subnetzbereich weitergeleitet wird.
Um Traffic aus dem Nur-Proxy-Subnetzbereich zuzulassen, erstellen Sie eine Firewallregel für den targetPort des Dienstes.
Fehler 400: Ungültiger Wert für das Feld "resource.target"
Der folgende Fehler kann auftreten, wenn Sie über einen internen Ingress in GKE auf einen Dienst zugreifen:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Stellen Sie ein Nur-Proxy-Subnetz bereit, um dieses Problem zu beheben.
Fehler während der Synchronisierung: Fehler beim Ausführen der Synchronisierungsroutine des Load-Balancers: Load-Balancer existiert nicht
Einer der folgenden Fehler kann auftreten, wenn die GKE-Steuerungsebene aktualisiert wird oder Sie ein Ingress-Objekt ändern:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
oder:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Um diese Probleme zu beheben, führen Sie die folgenden Schritte aus:
- Fügen Sie das Feld
hostsim Abschnitttlsdes Ingress-Manifests hinzu und löschen Sie dann das Ingress-Objekt. Warten Sie fünf Minuten, bis GKE die nicht verwendeten Ingress-Ressourcen gelöscht hat. Erstellen Sie dann das Ingress neu. Weitere Informationen finden Sie unter Feld „Hosts“ eines Ingress-Objekts. - Setzen Sie die Änderungen zurück, die Sie am Ingress-Objekt vorgenommen haben. Fügen Sie dann ein Zertifikat mit einer Annotation oder einem Kubernetes-Secret hinzu.
Externer Ingress erzeugt HTTP-502-Fehler
Folgen Sie der nachstehenden Anleitung, um HTTP-502-Fehler mit externen Ingress-Ressourcen zu beheben:
- Aktivieren Sie Logs für jeden Backend-Dienst, der jedem GKE-Dienst zugeordnet ist, auf den der Ingress verweist.
- Verwenden Sie Statusdetails, um Ursachen für HTTP-502-Antworten zu identifizieren. Statusdetails, die angeben, dass die HTTP-502-Antwort vom Backend stammt, erfordern eine Fehlerbehebung innerhalb der Bereitstellungs-Pods, nicht im Load-Balancer.
Nicht verwaltete Instanzgruppen
Es können HTTP-502-Fehler mit externen Ingress-Ressourcen auftreten, wenn Ihr externes Ingress nicht verwaltete Instanzgruppen-Back-Ends verwendet. Dieses Problem tritt auf, wenn alle der folgenden Bedingungen erfüllt sind:
- Der Cluster hat eine große Gesamtzahl von Knoten unter allen Knotenpools.
- Die Bereitstellungs-Pods für einen oder mehrere Services, auf die vom Ingress verwiesen wird, befinden sich nur auf wenigen Knoten.
- Dienste, auf die vom Ingress verwiesen wird, verwenden
externalTrafficPolicy: Local.
So ermitteln Sie, ob Ihr externes Ingress nicht verwaltete Instanzgruppen-Back-Ends verwendet:
Rufen Sie in der Google Cloud Console die Seite Ingress auf.
Klicken Sie auf den Namen Ihres externen Ingress.
Klicken Sie auf den Namen des Load-Balancers. Die Seite Details zum Load-Balancing wird angezeigt.
Prüfen Sie in der Tabelle im Abschnitt Backend-Dienste, ob Ihr externes Ingress NEGs oder Instanzgruppen verwendet.
Verwenden Sie eine der folgenden Lösungen, um dieses Problem zu beheben.
- Verwenden Sie einen VPC-nativen Cluster.
- Verwenden Sie
externalTrafficPolicy: Clusterfür jeden Service, auf den der externe Ingress verweist. Bei dieser Lösung gehen die ursprüngliche Client-IP-Adresse in den Quellen des Pakets verloren. - Verwenden Sie die Annotation
node.kubernetes.io/exclude-from-external-load-balancers=true. Fügen Sie den Knoten oder Knotenpools, die keinen Bereitstellungs-Pod ausführen, die Annotation für einen Dienst hinzu, auf den von einem externen Ingress- oderLoadBalancer-Dienst in Ihrem Cluster verwiesen wird.
Load-Balancer-Logs zur Fehlerbehebung verwenden
Sie können Logs von internen Passthrough-Netzwerk-Load-Balancers und Logs von externen Passthrough-Netzwerk-Load-Balancer dazu verwenden, Probleme mit Load-Balancern zu beheben und Traffic von Load-Balancern mit GKE-Ressourcen zu korrelieren.
Logs werden pro Verbindung zusammengefasst und nahezu in Echtzeit exportiert. Logs werden sowohl für eingehenden als auch für ausgehenden Traffic für jeden GKE-Knoten generiert, der am Datenpfad eines LoadBalancer-Dienstes beteiligt ist. Logeinträge umfassen zusätzliche Felder für GKE-Ressourcen, z. B.:
- Clustername
- Clusterstandort
- Dienstname
- Dienst-Namespace
- Pod-Name
- Pod-Namespace
Preise
Für die Verwendung von Logs fallen keine zusätzlichen Gebühren an. Je nachdem, wie Sie Logs aufnehmen, gelten die Standardpreise für Cloud Logging, BigQuery oder Pub/Sub. Das Aktivieren von Logs hat keine Auswirkungen auf die Leistung des Load-Balancers.
Diagnosetools zur Fehlerbehebung verwenden
Das Diagnosetool check-gke-ingress untersucht Ingress-Ressourcen auf häufige Fehlkonfigurationen. Sie können das check-gke-ingress-Tool auf folgende Weise verwenden:
- Führen Sie das
gcpdiag-Befehlszeilentool in Ihrem Cluster aus. Die Ergebnisse des Ingress werden im Abschnittgke/ERR/2023_004der Prüfregel angezeigt. - Verwenden Sie das
check-gke-ingress-Tool allein oder als kubectl-Plug-in. Folgen Sie dazu der Anleitung unter check-gke-ingress.
Nächste Schritte
Wenn Sie in der Dokumentation keine Lösung für Ihr Problem finden, lesen Sie den Abschnitt Support erhalten. Dort finden Sie weitere Hilfe, z. B. zu den folgenden Themen:
- Sie können eine Supportanfrage erstellen, indem Sie sich an den Cloud Customer Care wenden.
- Support von der Community erhalten, indem Sie Fragen auf Stack Overflow stellen und mit dem Tag
google-kubernetes-enginenach ähnlichen Problemen suchen. Sie können auch dem#kubernetes-engine-Slack-Kanal beitreten, um weiteren Community-Support zu erhalten. - Sie können Fehler melden oder Funktionsanfragen stellen, indem Sie die öffentliche Problemverfolgung verwenden.