Google Kubernetes Engine (GKE) 中的负载平衡问题可能会导致服务中断(例如出现 HTTP 502 错误),或导致无法访问应用。
本文档介绍了如何排查来自外部 Ingress 的 502 错误,以及如何使用负载平衡器日志和诊断工具(例如 check-gke-ingress)来发现问题。
对于在 GKE 中配置和维护负载均衡服务的平台管理员、运维人员和应用开发者来说,此信息非常重要。如需详细了解我们在 Google Cloud 内容中提及的常见角色和示例任务,请参阅常见的 GKE 用户角色和任务。
找不到 BackendConfig
如果在 Service 注解中指定了 Service 端口的 BackendConfig,但找不到实际 BackendConfig 资源,那么就会发生这种错误。
要评估 Kubernetes 事件,请运行以下命令:
kubectl get event
以下示例输出表明找不到 BackendConfig:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
如需解决此问题,请确保您没有在错误的命名空间中创建 BackendConfig 资源,或在 Service 注释中拼错了其引用名称。
找不到 Ingress 安全政策
Ingress 对象创建完毕后,如果安全政策未与 LoadBalancer Service 正确关联,请评估 Kubernetes 事件以了解是否存在配置错误。如果 BackendConfig 指定的安全政策不存在,则系统会定期发出警告事件。
要评估 Kubernetes 事件,请运行以下命令:
kubectl get event
以下示例输出表明找不到安全政策:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
如需解决此问题,请在 BackendConfig 中指定正确的安全政策名称。
解决在 GKE 中扩缩工作负载时出现的 NEG 500 系列错误
具体情况:
使用 GKE 预配的 NEG 进行负载均衡时,在工作负载缩容时,服务可能会遇到 502 或 503 错误。如果 Pod 在现有连接关闭之前终止,会发生 502 错误;如果流量被定向到已删除的 Pod,会发生 503 错误。
如果您使用的是使用 NEG 的 GKE 托管负载均衡产品(包括网关、Ingress 和独立 NEG),此问题可能会影响集群。如果您频繁扩缩工作负载,则集群受影响的风险很高。
诊断:
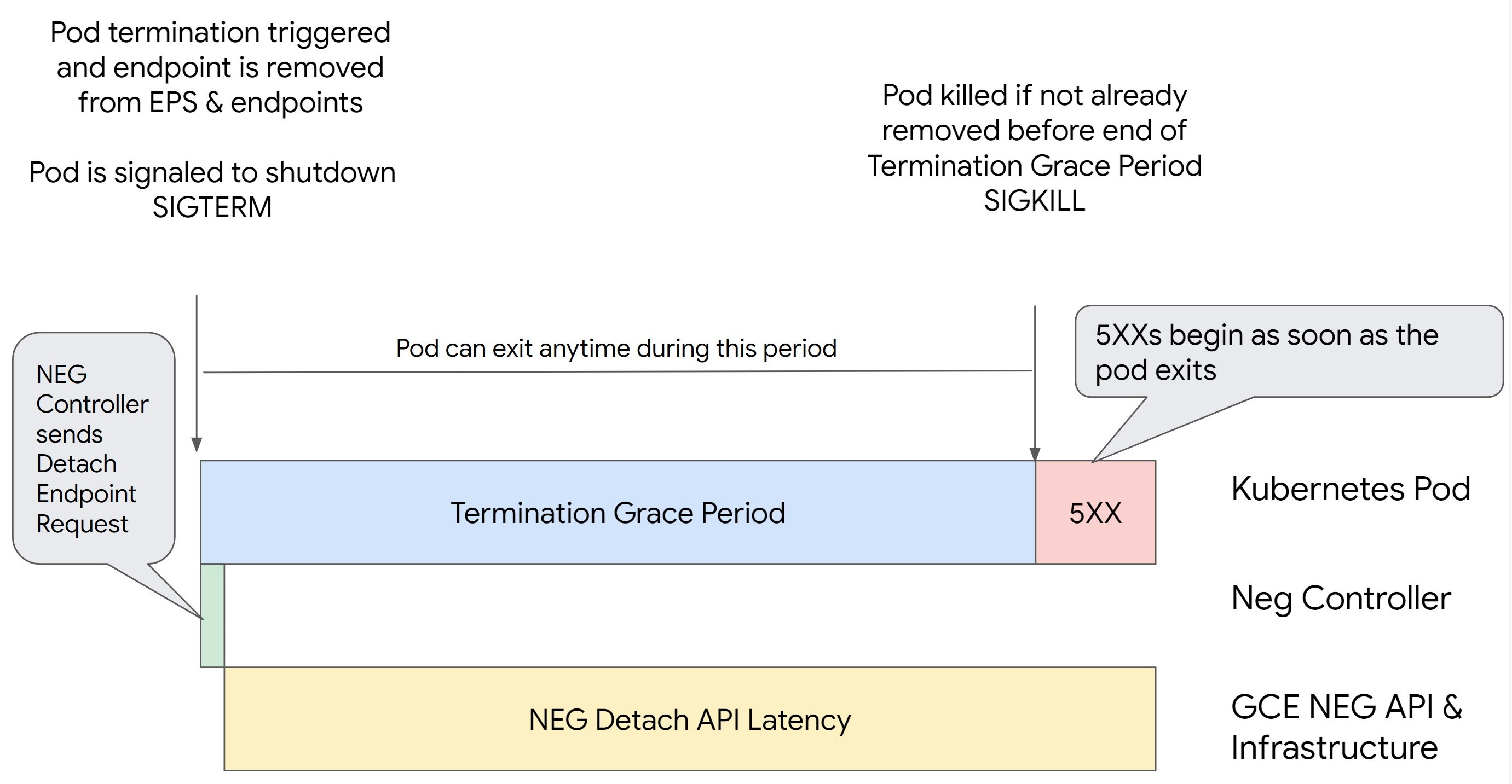
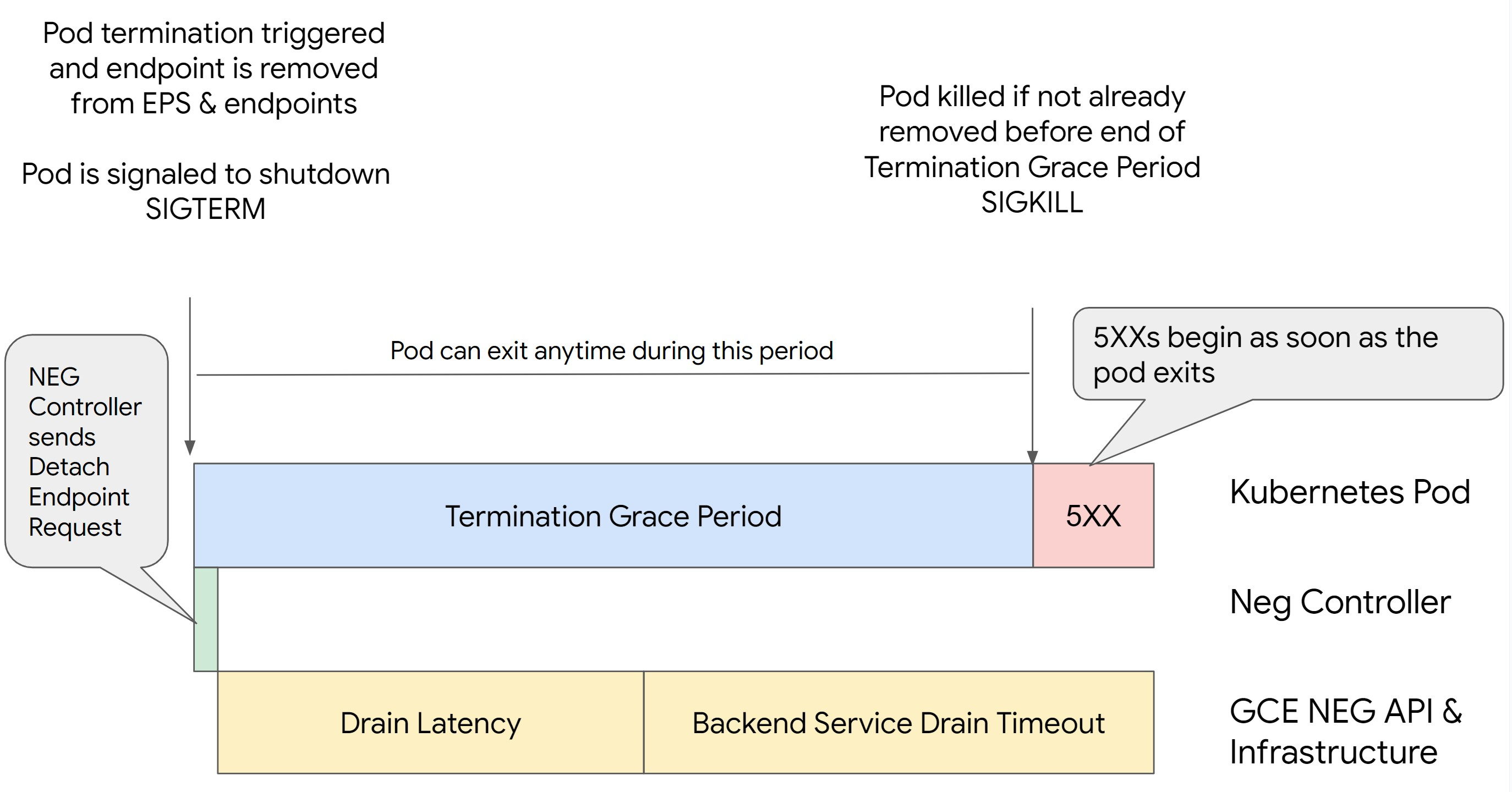
在 Kubernetes 中移除 Pod 而不排空其端点并先从 NEG 中移除 Pod 会导致 500 系列错误。为避免 Pod 终止期间出现问题,您必须考虑操作顺序。下图显示了未设置 BackendService Drain Timeout 且使用 BackendConfig 设置了 BackendService Drain Timeout 的场景。
场景 1:未设置 BackendService Drain Timeout。
下图显示了未设置 BackendService Drain Timeout 的场景。
场景 2:设置了 BackendService Drain Timeout。
下图显示设置了 BackendService Drain Timeout 的场景。
500 系列错误发生的确切时间取决于以下因素:
NEG API 分离延迟:NEG API 分离延迟表示分离操作在 Google Cloud中最终完成所花费的当前时间。此问题受 Kubernetes 之外的各种因素的影响,包括负载均衡器的类型和特定可用区。
排空延迟:排空延迟时间表示负载均衡器开始引导流量离开系统的特定部分所需的时间。排空启动后,负载均衡器会停止向端点发送新请求,但触发排空仍有延迟(排空延迟),如果 Pod 不再存在,这可能会导致暂时的 503 错误。
健康检查配置:更敏感的健康检查阈值可以缩短 503 错误的持续时间,因为它可以指示负载均衡器停止向端点发送请求,即使分离操作尚未完成也是如此。
终止宽限期:终止宽限期决定了 Pod 获得的最大退出时长。但是,Pod 可以在终止宽限期结束之前退出。如果 Pod 超过此期限,则会在此期限结束时被强制退出。这是 Pod 上的设置,需要在工作负载定义中进行配置。
可能的解决方法:
为防止出现这些 5XX 错误,请应用以下设置。超时值是建议的值,您可能需要针对特定应用进行调整。以下部分将引导您完成自定义过程。
下图展示了如何使用 preStop 钩子使 Pod 保持活跃状态:
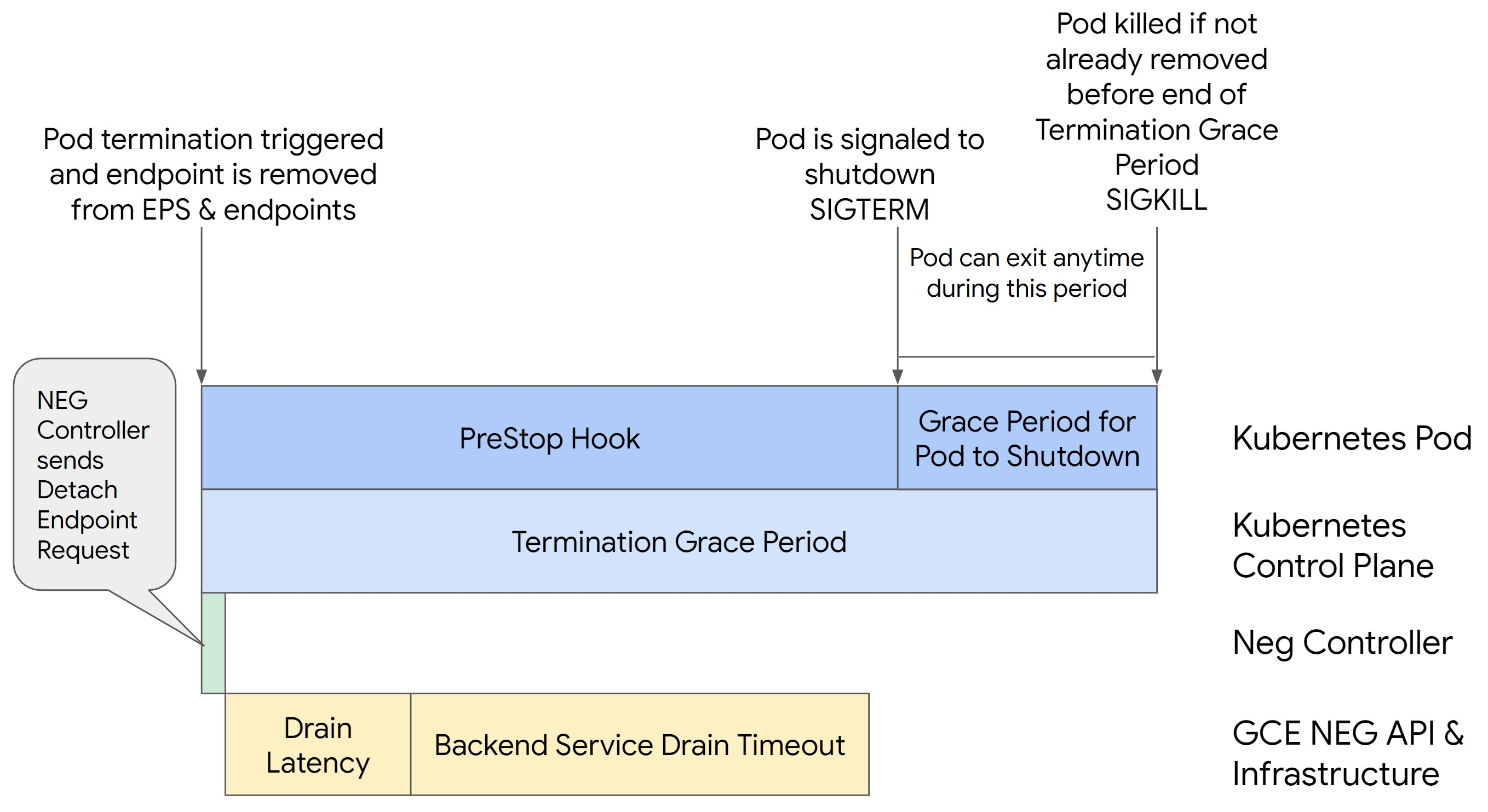
为避免 500 系列错误,请执行以下步骤:
将服务的
BackendService Drain Timeout设置为 1 分钟。对于 Ingress 用户,请参阅在 BackendConfig 上设置超时。
对于网关用户,请参阅在 GCPBackendPolicy 上配置超时。
对于使用独立 NEG 时直接管理其 BackendService 的用户,请参阅直接在后端服务上设置超时。
延长 Pod 上的
terminationGracePeriod。将 Pod 上的
terminationGracePeriodSeconds设置为 3.5 分钟。当此设置与推荐的设置结合使用时,在 Pod 的端点从 NEG 中移除后,Pod 可以获得 30 到 45 秒的安全关停窗口。如果您需要更多时间来进行安全关停,则可以延长宽限期,或者按照自定义超时部分中的说明操作。以下 Pod 清单指定 210 秒(3.5 分钟)的连接排空超时:
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...将
preStop钩子应用于所有容器。应用
preStop,确保当 Pod 的端点在负载均衡器中排空并且端点从 NEG 中移除时,Pod 的活跃时间延长 120 秒。spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
自定义超时
为了确保 Pod 连续性和防止 500 系列错误,Pod 必须在端点从 NEG 中移除之前保持活跃状态。特别是,为了防止 502 和 503 错误,请考虑同时实现超时和 preStop 钩子。
如需延长 Pod 在关停过程中的活跃时间,请向 Pod 添加 preStop 钩子。在 Pod 被指示退出之前运行 preStop 钩子,以使 preStop 钩子能被用于保持 Pod 活跃状态,直到其相应的端点从 NEG 中移除。
如需延长 Pod 在关停过程中的活跃时间,请按如下所示在 Pod 配置中插入 preStop 钩子:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
您可以配置超时和相关设置,以管理工作负载缩容期间 Pod 的安全关停。您可以根据具体用例调整超时。我们建议您先设置较长的超时,并根据需要缩短时长。您可以通过以下方式配置与超时相关的参数和 preStop 钩子,以自定义超时:
后端服务排空超时
默认情况下,Backend Service Drain Timeout 参数未设置,因此没有任何影响。如果您设置并激活了 Backend Service Drain Timeout 参数,则负载均衡器会停止将新请求路由到端点并等待超时,然后终止现有连接。
如需设置 Backend Service Drain Timeout 参数,您可以将 BackendConfig 与 Ingress 搭配使用,将 GCPBackendPolicy 与 Gateway 搭配使用,或者在独立 NEG 的 BackendService 上手动设置。超时应为处理请求所需时长的 1.5 到 2 倍。如果请求正好在排空开始之前传入,这样可确保请求将在超时完成之前完成。将 Backend Service Drain Timeout 参数设置为大于 0 的值有助于减少 503 错误,因为不会向计划移除的端点发送新请求。为使此超时生效,您必须将它与 preStop 钩子搭配使用,以确保 Pod 在排空期间保持活跃状态。如果不这样结合使用,未完成的现有请求将会收到 502 错误。
preStop 钩子时间
preStop 钩子必须充分延迟 Pod 关停,使排空延迟和后端服务排空超时完成,从而确保在 Pod 关停之前正确排空连接并从 NEG 中移除端点。
为获得最佳结果,请确保您的 preStop 钩子执行时间大于或等于 Backend Service Drain Timeout 和排空延迟的总和。
使用以下公式计算理想的 preStop 钩子执行时间:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
替换以下内容:
BACKEND_SERVICE_DRAIN_TIMEOUT:您为Backend Service Drain Timeout配置的时间。DRAIN_LATENCY:排空延迟的估算时间。我们建议您将一分钟作为估算值。
如果 500 错误仍然存在,请估算总持续时长,并在估算的排空延迟时间中加上该时间的两倍。这可确保 Pod 有足够的时间来安全排空,然后再从服务中移除。如果这个值对于您的特定应用场景而言太长,您可以进行调整。
或者,您也可以通过在 Cloud Audit Logs 中查看 Pod 的删除时间戳以及从 NEG 中移除端点的时间戳来估算时间。
“终止宽限期”参数
您配置的 terminationGracePeriod 参数值必须提供足够的时间使 preStop 钩子完成并且 Pod 安全关停。
如果未明确设置,terminationGracePeriod 默认为 30 秒。您可以使用以下公式计算最佳 terminationGracePeriod:
terminationGracePeriod >= preStop hook time + Pod shutdown time
按如下所示在 Pod 的配置中定义 terminationGracePeriod:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
创建内部 Ingress 资源时找不到 NEG
当您在 GKE 中创建内部 Ingress 时,可能会发生以下错误:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
发生此错误的原因是内部应用负载均衡器的 Ingress 需要网络端点组 (NEG) 作为后端。
在共享 VPC 环境或启用了网络政策的集群中,向 Service 清单添加注解 cloud.google.com/neg: '{"ingress": true}'。
504 网关超时:上游请求超时
从 GKE 中的内部 Ingress 访问 Service 时,可能会发生以下错误:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
发生此错误的原因是发送到内部应用负载均衡器的流量通过代理专用子网范围内的 envoy 代理来代理。
如需允许来自代理专用子网范围的流量,请在 Service 的 targetPort 上创建防火墙规则。
错误 400:字段“resource.target”的值无效
从 GKE 中的内部 Ingress 访问 Service 时,可能会发生以下错误:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
如需解决此问题,请创建代理专用子网。
同步时出错:运行负载均衡器同步例程时出错:负载均衡器不存在
在 GKE 控制平面升级或修改 Ingress 对象时,可能会发生以下错误之一:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
或:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
如需解决这些问题,请尝试以下步骤:
- 在 Ingress 清单的
tls部分中添加hosts字段,然后删除 Ingress。等待五分钟,让 GKE 删除未使用的 Ingress 资源。然后,重新创建 Ingress。如需了解详情,请参阅 Ingress 对象的主机字段。 - 还原您对 Ingress 所做的更改。然后,使用注解或 Kubernetes Secret 添加证书。
外部 Ingress 生成 HTTP 502 错误
请按照以下指导信息来排查外部 Ingress 资源的 HTTP 502 错误:
- 为 Ingress 所引用的每个 GKE Service 相关联的每个后端服务启用日志。
- 使用状态详细信息确定出现 HTTP 502 响应的原因。指示源自后端的 HTTP 502 响应的状态详细信息需要在服务 Pod(而非负载均衡器)中进行问题排查。
非代管实例组
如果外部 Ingress 使用非托管式实例组后端,您可能会遇到外部 Ingress 资源的 HTTP 502 错误。当满足以下所有条件时,就会出现此问题:
- 集群的所有节点池中的节点总数很多。
- Ingress 引用的一个或多个 Service 的服务 Pod 仅位于几个节点上。
- Ingress 引用的 Service 使用
externalTrafficPolicy: Local。
如需确定外部 Ingress 是否使用非代管实例组后端,请执行以下操作:
前往 Google Cloud 控制台中的 Ingress 页面。
点击外部 Ingress 的名称。
点击负载均衡器的名称。此时会显示 Load balancing details(负载均衡详情)页面。
查看后端服务部分中的表,以确定外部 Ingress 使用的是 NEG 还是实例组。
如需解决此问题,请使用以下解决方案之一:
- 使用 VPC 原生集群。
- 为外部 Ingress 引用的每个 Service 使用
externalTrafficPolicy: Cluster。此解决方案会导致您丢失数据包来源中的原始客户端 IP 地址。 - 使用
node.kubernetes.io/exclude-from-external-load-balancers=true注解。为未对集群中任何外部 Ingress 或LoadBalancerService 引用的任何 Service 运行任何服务 Pod 的节点或节点池添加注解。
使用负载均衡器日志进行问题排查
您可以使用内部直通网络负载均衡器日志和外部直通网络负载均衡器日志来排查负载均衡器的问题,并将从负载均衡器到 GKE 资源的流量关联起来。
日志会按连接汇总并近乎实时地导出。系统将为 LoadBalancer Service 的数据路径中涉及的每个 GKE 节点生成入站和出站流量日志。日志条目包含 GKE 资源的其他字段,例如:
- 集群名称
- 集群位置
- 服务名称
- 服务命名空间
- Pod 名称
- Pod 命名空间
价格
使用日志无需额外费用。根据您提取日志的方式,您需要按 Cloud Logging、BigQuery 或 Pub/Sub 的标准价格付费。启用日志不会影响负载均衡器的性能。
使用诊断工具排查问题
check-gke-ingress 诊断工具会检查 Ingress 资源是否存在常见配置错误。您可以通过以下方式使用 check-gke-ingress 工具:
- 在集群上运行
gcpdiag命令行工具。Ingress 结果显示在检查规则gke/ERR/2023_004部分中。 - 按照 check-gke-ingress 中的说明,单独使用
check-gke-ingress工具或是用作 kubectl 插件。
后续步骤
如果您在文档中找不到问题的解决方案,请参阅获取支持以获取进一步的帮助,包括以下主题的建议:
- 请与 Cloud Customer Care 联系,以提交支持请求。
- 通过在 StackOverflow 上提问并使用
google-kubernetes-engine标记搜索类似问题,从社区获得支持。您还可以加入#kubernetes-engineSlack 频道,以获得更多社区支持。 - 使用公开问题跟踪器提交 bug 或功能请求。