Nesta página, explicamos como migrar sua configuração do GKE Inference Gateway da
API de prévia v1alpha2 para a API v1 disponível de maneira geral.
Este documento é destinado a administradores de plataforma e especialistas em rede
que usam a versão v1alpha2 do GKE Inference Gateway e querem
fazer upgrade para a versão v1 e usar os recursos mais recentes.
Antes de iniciar a migração, familiarize-se com os conceitos e a implantação do GKE Inference Gateway. Recomendamos que você leia Implantar o gateway de inferência do GKE.
Antes de começar
Antes de iniciar a migração, determine se você precisa seguir este guia.
Verificar se há APIs v1alpha2
Para verificar se você está usando a API v1alpha2 GKE Inference Gateway, execute os
seguintes comandos:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
A saída desses comandos determina se você precisa migrar:
- Se um dos comandos retornar um ou mais recursos
InferencePoolouInferenceModel, você estará usando a APIv1alpha2e precisará seguir este guia. - Se os dois comandos retornarem
No resources found, você não estará usando a APIv1alpha2. Você pode prosseguir com uma nova instalação dov1gateway de inferência do GKE.
Caminhos de migração
Há dois caminhos para migrar do v1alpha2 para o v1:
- Migração simples (com inatividade): esse caminho é mais rápido e simples, mas resulta em um breve período de inatividade. É o caminho recomendado se você não precisar de uma migração sem tempo de inatividade.
- Migração sem tempo de inatividade:este caminho é para usuários que não podem ter nenhuma interrupção no serviço. Isso envolve executar as stacks
v1alpha2ev1lado a lado e mudar o tráfego gradualmente.
Migração simples (com tempo de inatividade)
Esta seção descreve como realizar uma migração simples com tempo de inatividade.
Excluir recursos
v1alpha2atuais: para excluir os recursosv1alpha2, escolha uma das seguintes opções:Opção 1: desinstalar usando o Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOpção 2: excluir recursos manualmente
Se você não estiver usando o Helm, exclua manualmente todos os recursos associados à implantação do
v1alpha2:- Atualize ou exclua o
HTTPRoutepara remover obackendRefque aponta para ov1alpha2InferencePool. - Exclua o
v1alpha2InferencePool, todos os recursosInferenceModelque apontam para ele e a implantação e o serviço correspondentes do Endpoint Picker (EPP).
Depois que todos os recursos personalizados
v1alpha2forem excluídos, remova as definições de recursos personalizados (CRDs) do cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Atualize ou exclua o
Instale os recursos da v1: depois de limpar os recursos antigos, instale o gateway de inferência do GKE
v1. Esse processo envolve o seguinte:- Instale as novas
v1definições de recursos personalizados (CRDs). - Crie um novo
v1InferencePoole os recursosInferenceObjectivecorrespondentes. O recursoInferenceObjectiveainda está definido na APIv1alpha2. - Crie um novo
HTTPRouteque direcione o tráfego para seu novov1InferencePool.
- Instale as novas
Verifique a implantação: após alguns minutos, verifique se a nova pilha
v1está veiculando o tráfego corretamente.Confirme se o status do gateway é
PROGRAMMED:kubectl get gateway -o wideA saída será semelhante a esta:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifique o endpoint enviando uma solicitação:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Verifique se você recebeu uma resposta bem-sucedida com um código
200.
Migração sem inatividade
Esse caminho de migração é destinado a usuários que não podem ter interrupções no serviço. O diagrama a seguir ilustra como o GKE Inference Gateway facilita a veiculação de vários modelos de IA generativa, um aspecto fundamental de uma estratégia de migração sem tempo de inatividade.
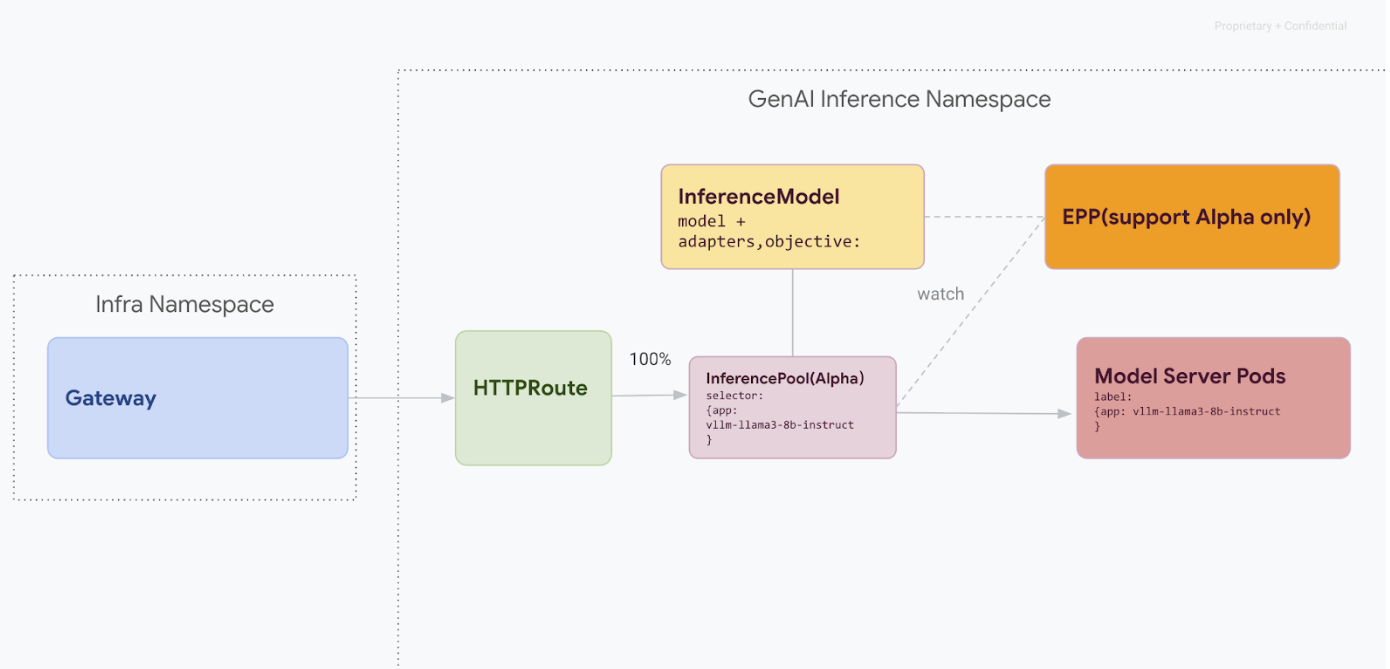
Como distinguir versões da API com o kubectl
Durante a migração sem tempo de inatividade, os CRDs v1alpha2 e v1 são instalados no cluster. Isso pode criar ambiguidade ao usar kubectl para consultar recursos
InferencePool. Para garantir que você esteja interagindo com a versão
correta, use o nome completo do recurso:
Para obter
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioPara obter
v1:kubectl get inferencepools.inference.networking.k8s.io
A API v1 também oferece um nome abreviado conveniente, infpool, que pode ser usado
para consultar recursos v1 especificamente:
kubectl get infpool
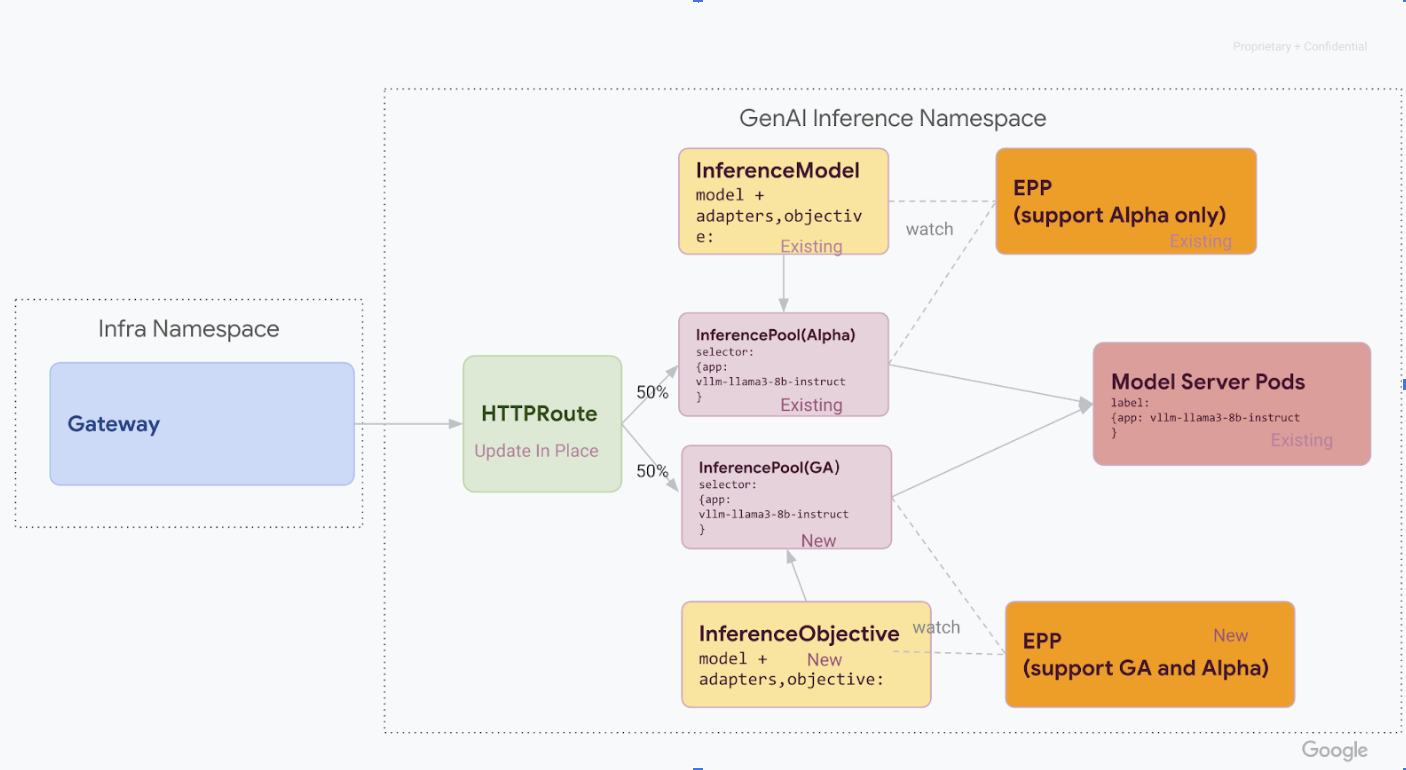
Etapa 1: implantação lado a lado da v1
Nesta etapa, você implanta a nova pilha v1 InferencePool ao lado da pilha v1alpha2 atual, o que permite uma migração gradual e segura.
Depois de concluir todas as etapas desta fase, você terá a seguinte infraestrutura no diagrama abaixo:
Instale as definições de recursos personalizados (CRDs) necessárias no cluster do GKE:
- Para versões do GKE anteriores a
1.34.0-gke.1626000, execute o comando a seguir para instalar os CRDs v1InferencePoole alfaInferenceObjective:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- Para versões do GKE
1.34.0-gke.1626000ou mais recentes, instale apenas a CRD alfaInferenceObjectiveexecutando o seguinte comando:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- Para versões do GKE anteriores a
Instale o
v1 InferencePool.Use o Helm para instalar um novo
v1 InferencePoolcom um nome de versão diferente, comovllm-llama3-8b-instruct-ga. OInferencePoolprecisa segmentar os mesmos pods do servidor de modelos que oInferencePoolAlfa usandoinferencePool.modelServers.matchLabels.app.Para instalar o
InferencePool, use o seguinte comando:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolCriar recursos
v1alpha2 InferenceObjective.Como parte da migração para a versão v1.0 da extensão de inferência da API Gateway, também precisamos migrar da API alfa
InferenceModelpara a nova APIInferenceObjective.Aplique o seguinte YAML para criar os recursos
InferenceObjective:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Etapa 2: mudança de tráfego
Com as duas pilhas em execução, você pode começar a transferir o tráfego de v1alpha2 para v1
atualizando o HTTPRoute para dividir o tráfego. Este exemplo mostra uma divisão de 50/50.
Atualize a HTTPRoute para divisão de tráfego.
Para atualizar o
HTTPRoutepara divisão de tráfego, execute o seguinte comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFVerifique e monitore.
Depois de aplicar as mudanças, monitore a performance e a estabilidade da nova pilha
v1. Verifique se o gatewayinference-gatewaytem um statusPROGRAMMEDdeTRUE.
Etapa 3: finalização e limpeza
Depois de verificar se o v1 InferencePool está estável, direcione todo o tráfego para ele e desative os recursos antigos do v1alpha2.
Mude 100% do tráfego para o
v1 InferencePool.Para transferir 100% do tráfego para
v1 InferencePool, execute o seguinte comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFFaça a verificação final.
Depois de direcionar todo o tráfego para a pilha
v1, verifique se ela está processando todo o tráfego conforme o esperado.Confirme se o status do gateway é
PROGRAMMED:kubectl get gateway -o wideA saída será semelhante a esta:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifique o endpoint enviando uma solicitação:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Verifique se você recebeu uma resposta bem-sucedida com um código
200.
Limpe os recursos v1alpha2.
Depois de confirmar que a pilha
v1está totalmente operacional, remova com segurança os recursosv1alpha2antigos.Verifique se há recursos
v1alpha2restantes.Agora que você migrou para a API
v1InferencePool, é seguro excluir os CRDs antigos. Verifique se há APIs v1alpha2 para garantir que você não tenha mais recursosv1alpha2em uso. Se ainda tiver alguns restantes, continue o processo de migração para eles.Exclua os CRDs
v1alpha2.Depois que todos os recursos personalizados
v1alpha2forem excluídos, remova as definições de recursos personalizados (CRDs) do cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlDepois de concluir todas as etapas, sua infraestrutura vai ficar parecida com este diagrama:
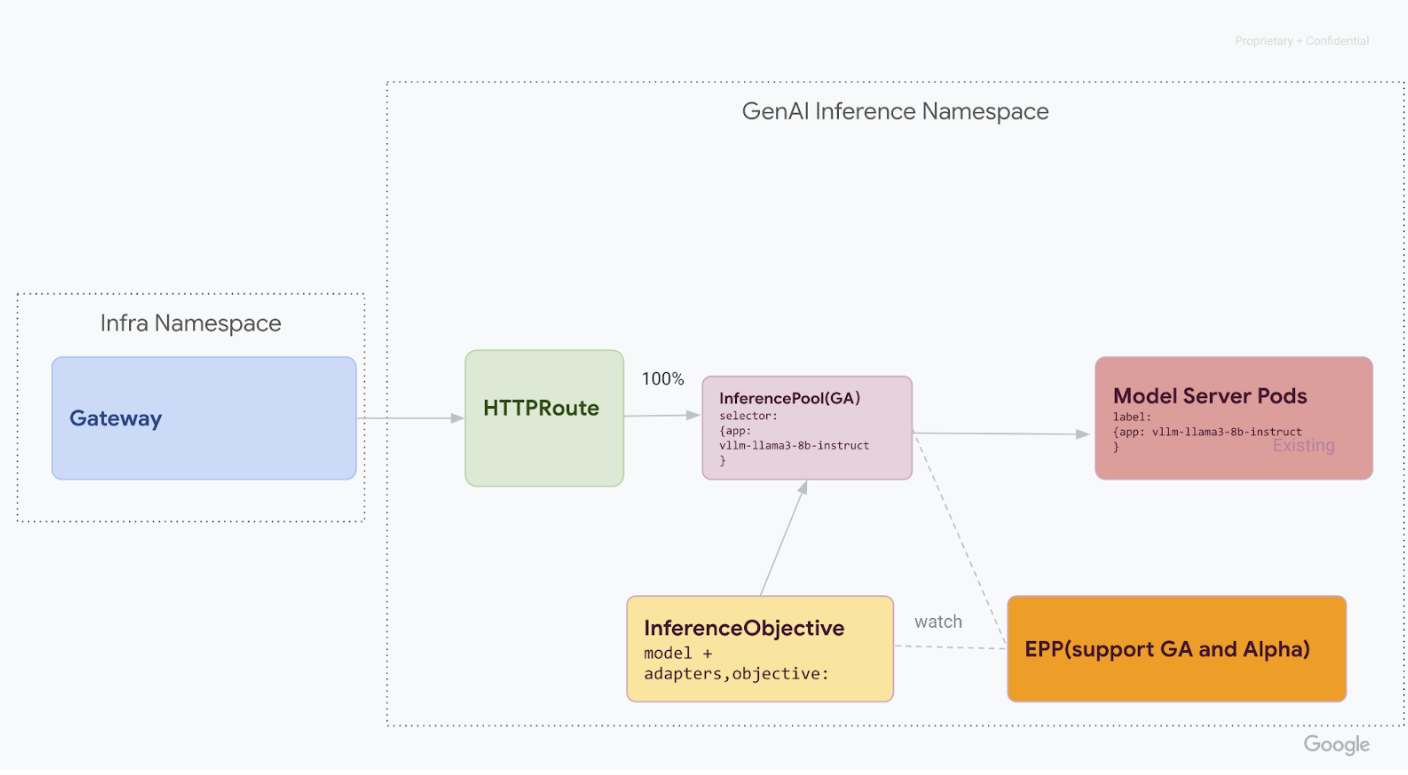
Figura: o gateway de inferência do GKE roteia solicitações para diferentes modelos de IA generativa com base no nome e na prioridade do modelo
A seguir
- Saiba mais sobre Implantar
o gateway de inferência do GKE.
- Conheça outros recursos de rede do GKE.