이 페이지에서는 GKE 추론 게이트웨이 설정을 미리보기 v1alpha2 API에서 정식 버전 v1 API로 이전하는 방법을 설명합니다.
이 문서는 GKE 추론 게이트웨이의 v1alpha2 버전을 사용하고 최신 기능을 사용하기 위해 v1 버전으로 업그레이드하려는 플랫폼 관리자 및 네트워킹 전문가를 대상으로 합니다.
마이그레이션을 시작하기 전에 GKE 추론 게이트웨이의 개념과 배포를 숙지해야 합니다. GKE 추론 게이트웨이 배포를 검토하는 것이 좋습니다.
시작하기 전에
마이그레이션을 시작하기 전에 이 가이드를 따라야 하는지 확인하세요.
기존 v1alpha2 API 확인
v1alpha2 GKE 추론 게이트웨이 API를 사용 중인지 확인하려면 다음 명령어를 실행합니다.
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
이 명령어의 출력에 따라 마이그레이션해야 하는지 여부가 결정됩니다.
- 두 명령어 중 하나에서 하나 이상의
InferencePool또는InferenceModel리소스가 반환되면v1alpha2API를 사용하고 있는 것이므로 이 가이드를 따라야 합니다. - 두 명령어 모두
No resources found를 반환하면v1alpha2API를 사용하지 않는 것입니다.v1GKE 추론 게이트웨이를 새로 설치하면 됩니다.
마이그레이션 경로
v1alpha2에서 v1로 마이그레이션하는 방법에는 두 가지가 있습니다.
- 간단한 마이그레이션 (다운타임 포함): 이 방법은 더 빠르고 간단하지만 짧은 기간의 다운타임이 발생합니다. 다운타임이 없는 마이그레이션이 필요하지 않은 경우 권장되는 경로입니다.
- 다운타임 없는 마이그레이션: 이 경로는 서비스 중단을 허용할 수 없는 사용자를 위한 것입니다. 여기에는
v1alpha2및v1스택을 나란히 실행하고 트래픽을 점진적으로 이동하는 작업이 포함됩니다.
간단한 마이그레이션 (다운타임 포함)
이 섹션에서는 다운타임이 있는 간단한 마이그레이션을 실행하는 방법을 설명합니다.
기존
v1alpha2리소스 삭제:v1alpha2리소스를 삭제하려면 다음 옵션 중 하나를 선택합니다.옵션 1: Helm을 사용하여 제거하기
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAME옵션 2: 리소스 수동 삭제
Helm을 사용하지 않는 경우
v1alpha2배포와 연결된 모든 리소스를 수동으로 삭제합니다.v1alpha2InferencePool를 가리키는backendRef를 삭제하도록HTTPRoute를 업데이트하거나 삭제합니다.v1alpha2InferencePool, 이를 가리키는InferenceModel리소스, 해당 엔드포인트 선택기 (EPP) 배포 및 서비스를 삭제합니다.
모든
v1alpha2커스텀 리소스가 삭제되면 클러스터에서 커스텀 리소스 정의 (CRD)를 삭제합니다.kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlv1 리소스 설치: 이전 리소스를 정리한 후
v1GKE 추론 게이트웨이를 설치합니다. 이 프로세스에는 다음이 포함됩니다.- 새
v1커스텀 리소스 정의 (CRD)를 설치합니다. - 새
v1InferencePool및 해당InferenceObjective리소스를 만듭니다.InferenceObjective리소스는 여전히v1alpha2API에 정의되어 있습니다. - 트래픽을 새
v1InferencePool로 안내하는 새HTTPRoute를 만듭니다.
- 새
배포 확인: 몇 분 후 새
v1스택이 트래픽을 올바르게 제공하는지 확인합니다.게이트웨이 상태가
PROGRAMMED인지 확인합니다.kubectl get gateway -o wide다음과 같이 출력되어야 합니다.
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m요청을 전송하여 엔드포인트를 확인합니다.
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'200응답 코드가 포함된 성공적인 응답을 수신해야 합니다.
제로 다운타임 마이그레이션
이 마이그레이션 경로는 서비스 중단을 감당할 수 없는 사용자를 위해 설계되었습니다. 다음 다이어그램은 GKE 추론 게이트웨이가 무중단 이전 전략의 핵심 측면인 여러 생성형 AI 모델의 서빙을 지원하는 방법을 보여줍니다.
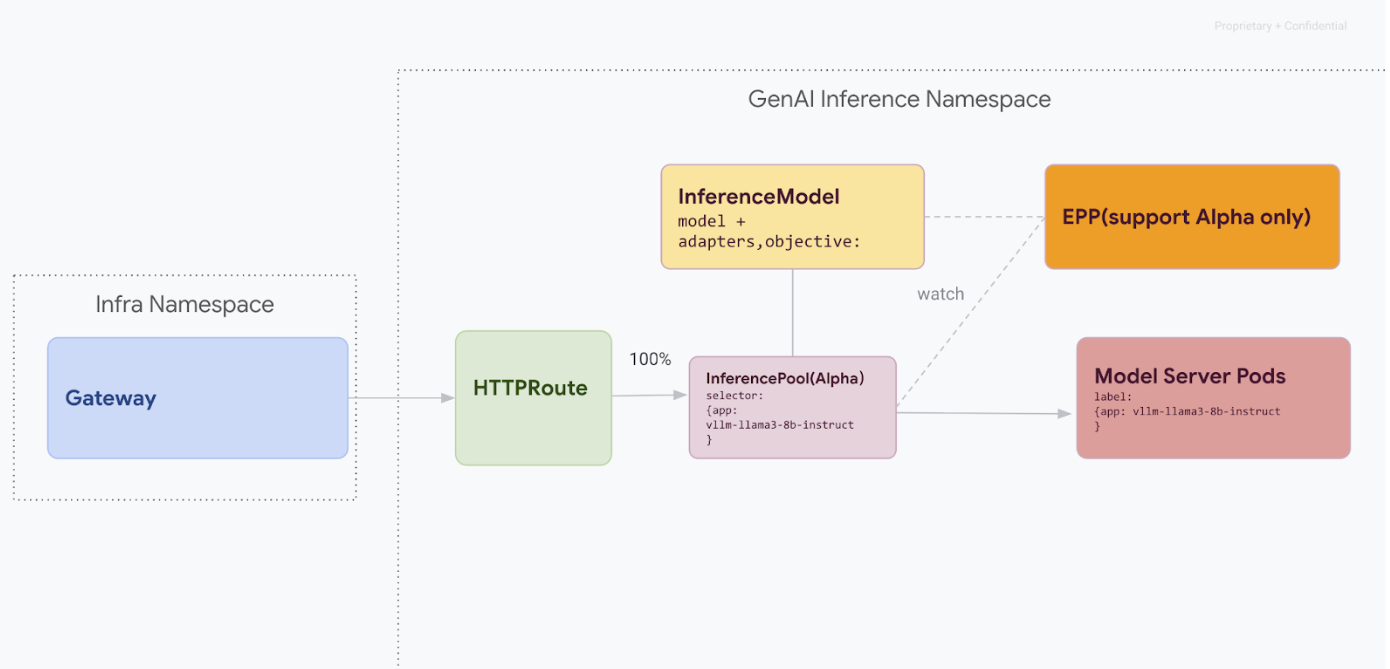
kubectl로 API 버전 구분
무중단 마이그레이션 중에 v1alpha2 및 v1 CRD가 모두 클러스터에 설치됩니다. kubectl를 사용하여 InferencePool 리소스를 쿼리할 때 모호성이 발생할 수 있습니다. 올바른 버전과 상호작용하려면 전체 리소스 이름을 사용해야 합니다.
v1alpha2의 경우:kubectl get inferencepools.inference.networking.x-k8s.iov1의 경우:kubectl get inferencepools.inference.networking.k8s.io
v1 API는 v1 리소스를 구체적으로 쿼리하는 데 사용할 수 있는 편리한 약식 이름 infpool도 제공합니다.
kubectl get infpool
1단계: v1 동시 배포
이 단계에서는 기존 v1alpha2 스택과 함께 새 v1 InferencePool 스택을 배포하여 안전하고 점진적인 마이그레이션을 지원합니다.
이 단계의 모든 단계를 완료하면 다음 다이어그램과 같은 인프라가 있습니다.
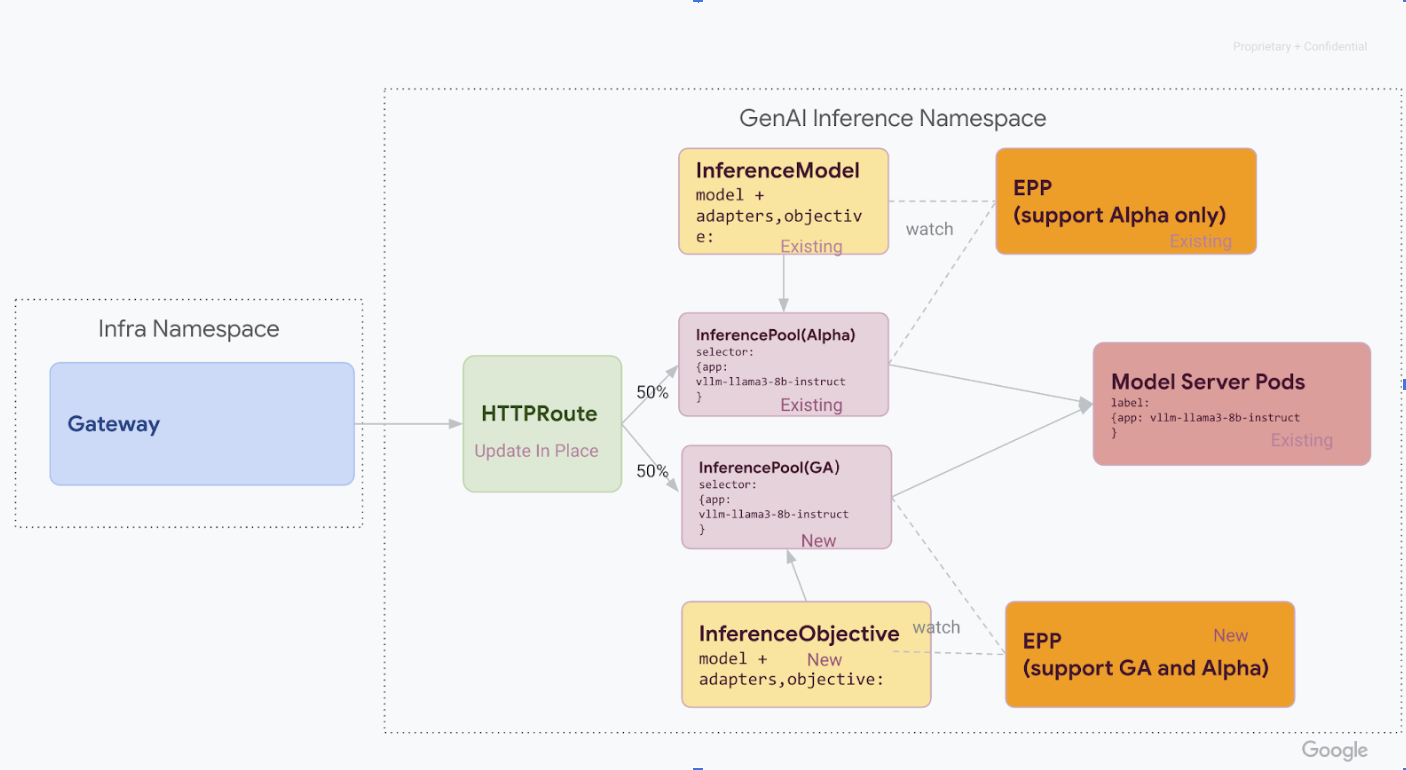
GKE 클러스터에 필요한 커스텀 리소스 정의 (CRD)를 설치합니다.
1.34.0-gke.1626000이전 GKE 버전의 경우 다음 명령어를 실행하여 v1InferencePool및 알파InferenceObjectiveCRD를 모두 설치합니다.
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- GKE 버전
1.34.0-gke.1626000이상의 경우 다음 명령어를 실행하여 알파InferenceObjectiveCRD만 설치합니다.
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yamlv1 InferencePool를 설치합니다.Helm을 사용하여
vllm-llama3-8b-instruct-ga과 같은 고유한 출시 이름으로 새v1 InferencePool를 설치합니다.InferencePool은inferencePool.modelServers.matchLabels.app을 사용하여 알파InferencePool과 동일한 모델 서버 포드를 타겟팅해야 합니다.InferencePool를 설치하려면 다음 명령어를 사용하세요.helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolv1alpha2 InferenceObjective리소스를 만듭니다.게이트웨이 API 추론 확장 프로그램의 v1.0 출시로 이전하는 과정에서 알파
InferenceModelAPI에서 새로운InferenceObjectiveAPI로도 이전해야 합니다.다음 YAML을 적용하여
InferenceObjective리소스를 만듭니다.kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
2단계: 트래픽 전환
두 스택이 모두 실행되면 HTTPRoute를 업데이트하여 트래픽을 분할함으로써 v1alpha2에서 v1로 트래픽을 이동할 수 있습니다. 이 예시에서는 50대 50 분할을 보여줍니다.
트래픽 분할을 위해 HTTPRoute를 업데이트합니다.
트래픽 분할을 위해
HTTPRoute를 업데이트하려면 다음 명령어를 실행합니다.kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOF확인 및 모니터링
변경사항을 적용한 후 새
v1스택의 성능과 안정성을 모니터링합니다.inference-gateway게이트웨이의PROGRAMMED상태가TRUE인지 확인합니다.
3단계: 마무리 및 정리
v1 InferencePool가 안정적인지 확인한 후 모든 트래픽을 v1 InferencePool로 전달하고 이전 v1alpha2 리소스를 사용 중단할 수 있습니다.
v1 InferencePool로 트래픽을 100% 이동합니다.트래픽을 100%
v1 InferencePool로 전환하려면 다음 명령어를 실행합니다.kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOF최종 확인을 실행합니다.
모든 트래픽을
v1스택으로 전달한 후 예상대로 모든 트래픽을 처리하는지 확인합니다.게이트웨이 상태가
PROGRAMMED인지 확인합니다.kubectl get gateway -o wide다음과 같이 출력되어야 합니다.
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m요청을 전송하여 엔드포인트를 확인합니다.
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'200응답 코드가 포함된 성공적인 응답을 수신해야 합니다.
v1alpha2 리소스를 정리합니다.
v1스택이 완전히 작동하는지 확인한 후 이전v1alpha2리소스를 안전하게 삭제합니다.남은
v1alpha2리소스가 있는지 확인합니다.이제
v1InferencePoolAPI로 이전했으므로 이전 CRD를 삭제해도 됩니다. 기존 v1alpha2 API 확인을 통해 사용 중인v1alpha2리소스가 더 이상 없는지 확인합니다. 아직 남아 있는 항목이 있다면 해당 항목에 대한 이전 프로세스를 계속 진행할 수 있습니다.v1alpha2CRD를 삭제합니다.모든
v1alpha2커스텀 리소스가 삭제되면 클러스터에서 커스텀 리소스 정의 (CRD)를 삭제합니다.kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml모든 단계를 완료하면 인프라가 다음 다이어그램과 유사해야 합니다.
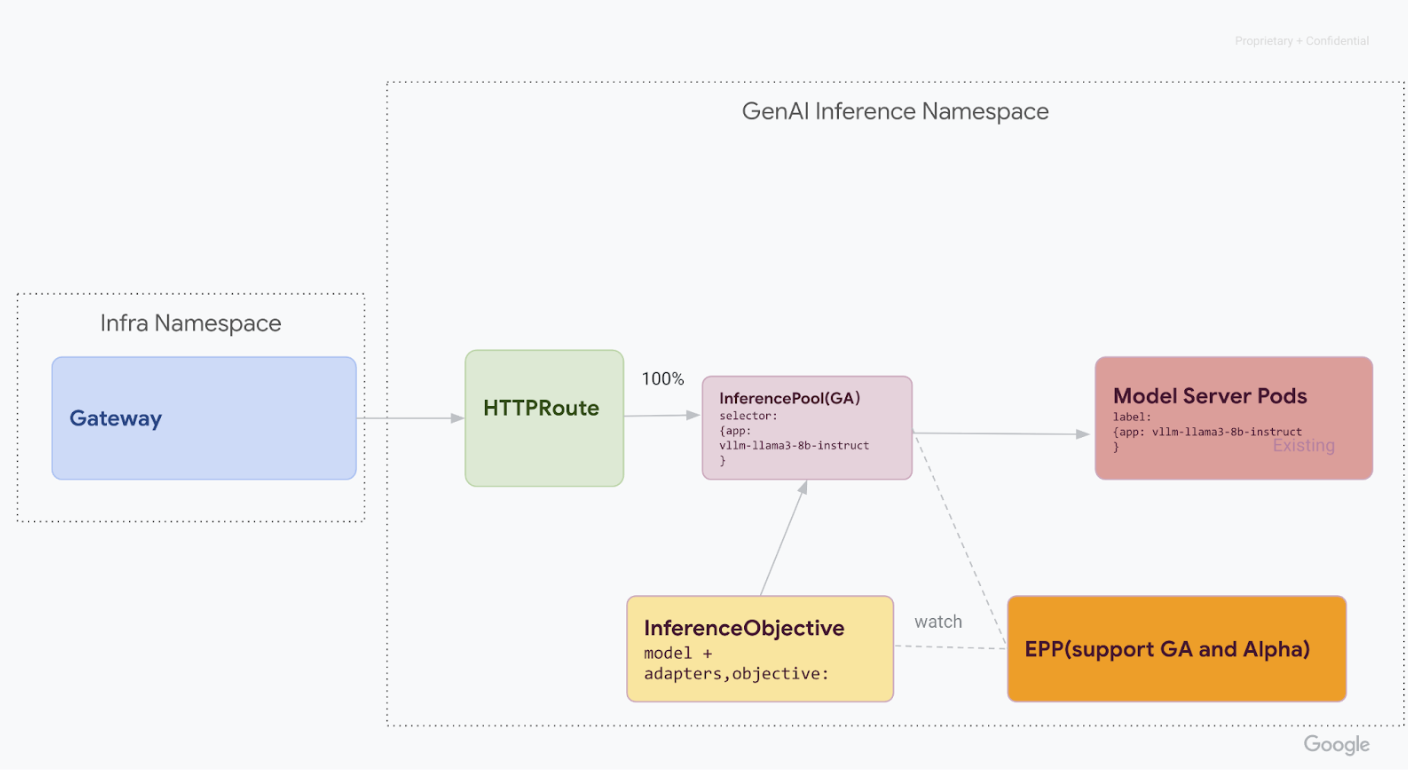
그림: 모델 이름과 우선순위에 따라 다양한 생성형 AI 모델로 요청을 라우팅하는 GKE Inference Gateway
다음 단계
- GKE 추론 게이트웨이 배포에 대해 자세히 알아보세요.
- 다른 GKE 네트워킹 기능 살펴보기