Questa pagina spiega come eseguire la migrazione della configurazione di GKE Inference Gateway dall'API v1alpha2 di anteprima all'API v1 disponibile a livello generale.
Questo documento è destinato agli amministratori della piattaforma e agli esperti di networking
che utilizzano la versione v1alpha2 di GKE Inference Gateway e vogliono
eseguire l'upgrade alla versione v1 per utilizzare le funzionalità più recenti.
Prima di iniziare la migrazione, assicurati di avere familiarità con i concetti e il deployment di GKE Inference Gateway. Ti consigliamo di consultare Deploy GKE Inference Gateway.
Prima di iniziare
Prima di iniziare la migrazione, determina se devi seguire questa guida.
Controlla le API v1alpha2 esistenti
Per verificare se stai utilizzando l'API GKE Inference Gateway v1alpha2, esegui
i seguenti comandi:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
L'output di questi comandi determina se devi eseguire la migrazione:
- Se uno dei due comandi restituisce una o più risorse
InferencePooloInferenceModel, stai utilizzando l'APIv1alpha2e devi seguire questa guida. - Se entrambi i comandi restituiscono
No resources found, non stai utilizzando l'APIv1alpha2. Puoi procedere con una nuova installazione div1GKE Inference Gateway.
Percorsi di migrazione
Esistono due percorsi per la migrazione da v1alpha2 a v1:
- Migrazione semplice (con tempi di inattività): questo percorso è più rapido e semplice, ma comporta un breve periodo di inattività. È il percorso consigliato se non è necessaria una migrazione senza tempi di inattività.
- Migrazione senza tempi di inattività: questo percorso è per gli utenti che non possono permettersi alcuna interruzione del servizio. Consiste nell'eseguire contemporaneamente gli stack
v1alpha2ev1e spostare gradualmente il traffico.
Migrazione semplice (con tempi di inattività)
Questa sezione descrive come eseguire una migrazione semplice con tempi di inattività.
Elimina risorse
v1alpha2esistenti: per eliminare le risorsev1alpha2, scegli una delle seguenti opzioni:Opzione 1: disinstallare utilizzando Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOpzione 2: elimina manualmente le risorse
Se non utilizzi Helm, elimina manualmente tutte le risorse associate al deployment di
v1alpha2:- Aggiorna o elimina
HTTPRouteper rimuoverebackendRefche punta av1alpha2InferencePool. - Elimina
v1alpha2InferencePool, tutte le risorseInferenceModelche lo puntano e il deployment e il servizio Endpoint Picker (EPP) corrispondenti.
Dopo aver eliminato tutte le risorse personalizzate
v1alpha2, rimuovi le definizioni di risorse personalizzate (CRD) dal cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Aggiorna o elimina
Installa risorse v1: dopo aver pulito le risorse precedenti, installa il gateway di inferenza GKE
v1. Questa procedura prevede quanto segue:- Installa le nuove
v1Custom Resource Definitions (CRD). - Crea un nuovo
v1InferencePoole le risorseInferenceObjectivecorrispondenti. La risorsaInferenceObjectiveè ancora definita nell'APIv1alpha2. - Crea un nuovo
HTTPRouteche indirizzi il traffico al nuovov1InferencePool.
- Installa le nuove
Verifica il deployment: dopo qualche minuto, verifica che il nuovo stack
v1gestisca correttamente il traffico.Verifica che lo stato del gateway sia
PROGRAMMED:kubectl get gateway -o wideL'output dovrebbe essere simile a questo:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifica l'endpoint inviando una richiesta:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Assicurati di ricevere una risposta positiva con un codice di risposta
200.
Migrazione senza tempi di inattività
Questo percorso di migrazione è progettato per gli utenti che non possono permettersi interruzioni del servizio. Il seguente diagramma illustra come GKE Inference Gateway facilita la pubblicazione di più modelli di AI generativa, un aspetto chiave di una strategia di migrazione senza tempi di inattività.
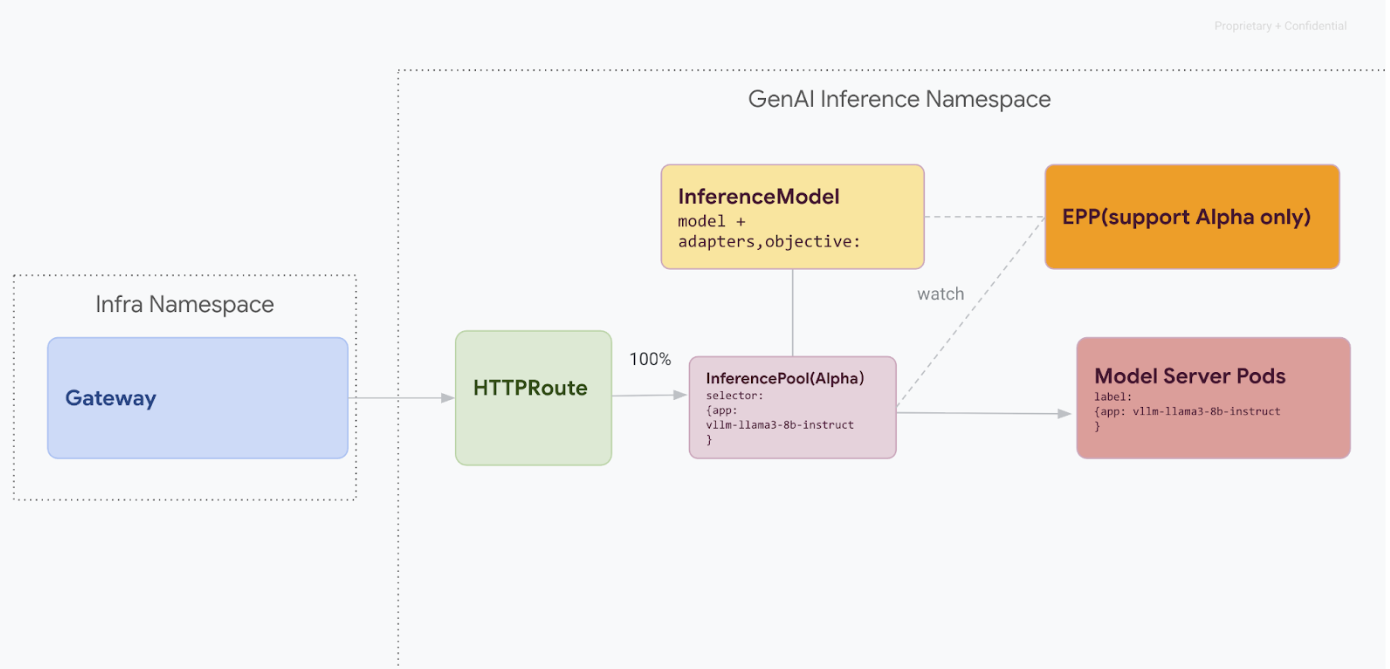
Distinguere le versioni API con kubectl
Durante la migrazione senza tempi di inattività, vengono installate le CRD v1alpha2 e v1
sul cluster. Ciò può creare ambiguità quando utilizzi kubectl per eseguire query per le risorse
InferencePool. Per assicurarti di interagire con la versione corretta, devi utilizzare il nome completo della risorsa:
Per
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioPer
v1:kubectl get inferencepools.inference.networking.k8s.io
L'API v1 fornisce anche un nome breve pratico, infpool, che puoi utilizzare
per eseguire query specifiche sulle risorse v1:
kubectl get infpool
Fase 1: deployment affiancato della versione 1
In questa fase, esegui il deployment del nuovo stack v1 InferencePool insieme allo stack v1alpha2 esistente, il che consente una migrazione sicura e graduale.
Dopo aver completato tutti i passaggi di questa fase, avrai l'infrastruttura mostrata nel seguente diagramma:
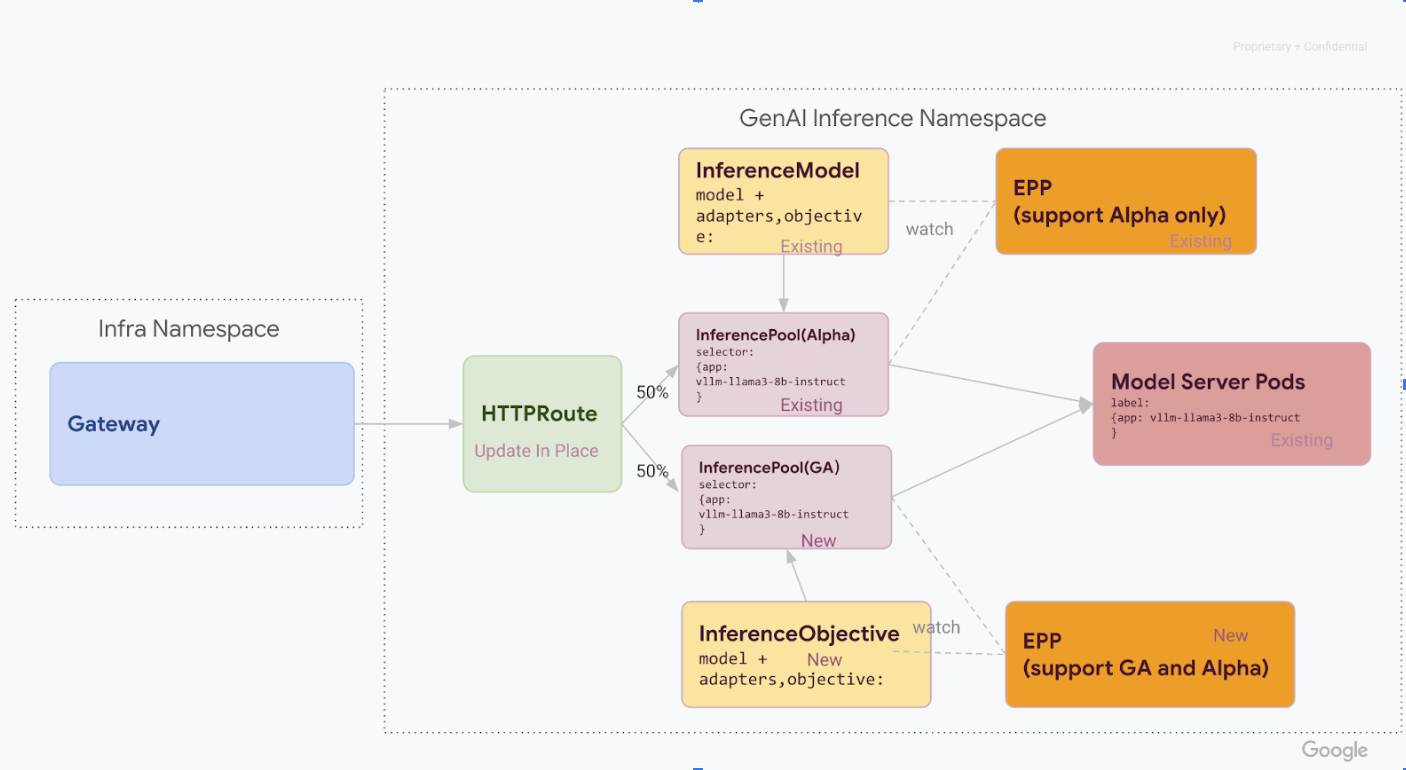
Installa la definizione di risorsa personalizzata (CRD) necessaria nel tuo cluster GKE:
- Per le versioni di GKE precedenti alla
1.34.0-gke.1626000, esegui il comando seguente per installare sia le CRD v1InferencePoolsia le CRD alphaInferenceObjective:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- Per le versioni di GKE
1.34.0-gke.1626000o successive, installa solo la CRD alphaInferenceObjectiveeseguendo il seguente comando:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- Per le versioni di GKE precedenti alla
Installa
v1 InferencePool.Utilizza Helm per installare un nuovo
v1 InferencePoolcon un nome di release distinto, ad esempiovllm-llama3-8b-instruct-ga.InferencePooldeve avere come target gli stessi pod Model Server diInferencePoolalpha utilizzandoinferencePool.modelServers.matchLabels.app.Per installare
InferencePool, utilizza il seguente comando:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolCrea risorse
v1alpha2 InferenceObjective.Nell'ambito della migrazione alla versione 1.0 dell'estensione di inferenza dell'API Gateway, dobbiamo anche eseguire la migrazione dall'API alpha
InferenceModelalla nuova APIInferenceObjective.Applica il seguente YAML per creare le risorse
InferenceObjective:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Fase 2: spostamento del traffico
Con entrambi gli stack in esecuzione, puoi iniziare a spostare il traffico da v1alpha2 a v1
aggiornando HTTPRoute per suddividere il traffico. Questo esempio mostra una divisione 50-50.
Aggiorna HTTPRoute per la suddivisione del traffico.
Per aggiornare
HTTPRouteper la suddivisione del traffico, esegui questo comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFVerifica e monitora.
Dopo aver applicato le modifiche, monitora il rendimento e la stabilità del nuovo stack
v1. Verifica che il gatewayinference-gatewayabbia uno statoPROGRAMMEDTRUE.
Fase 3: finalizzazione e pulizia
Una volta verificato che v1 InferencePool è stabile, puoi indirizzare tutto
il traffico e ritirare le vecchie risorse v1alpha2.
Sposta il 100% del traffico su
v1 InferencePool.Per spostare il 100% del traffico su
v1 InferencePool, esegui questo comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFEsegui la verifica finale.
Dopo aver indirizzato tutto il traffico allo stack
v1, verifica che gestisca tutto il traffico come previsto.Verifica che lo stato del gateway sia
PROGRAMMED:kubectl get gateway -o wideL'output dovrebbe essere simile a questo:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifica l'endpoint inviando una richiesta:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Assicurati di ricevere una risposta positiva con un codice di risposta
200.
Esegui la pulizia delle risorse v1alpha2.
Dopo aver confermato che lo stack
v1è completamente operativo, rimuovi in modo sicuro le vecchie risorsev1alpha2.Controlla le risorse
v1alpha2rimanenti.Ora che hai eseguito la migrazione all'API
v1InferencePool, puoi eliminare le vecchie CRD. Controlla le API v1alpha2 esistenti per assicurarti di non avere più risorsev1alpha2in uso. Se ne hai ancora a disposizione, puoi continuare la procedura di migrazione per questi.Elimina i CRD
v1alpha2.Dopo aver eliminato tutte le risorse personalizzate
v1alpha2, rimuovi le definizioni di risorse personalizzate (CRD) dal cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlDopo aver completato tutti i passaggi, la tua infrastruttura dovrebbe essere simile al seguente diagramma:
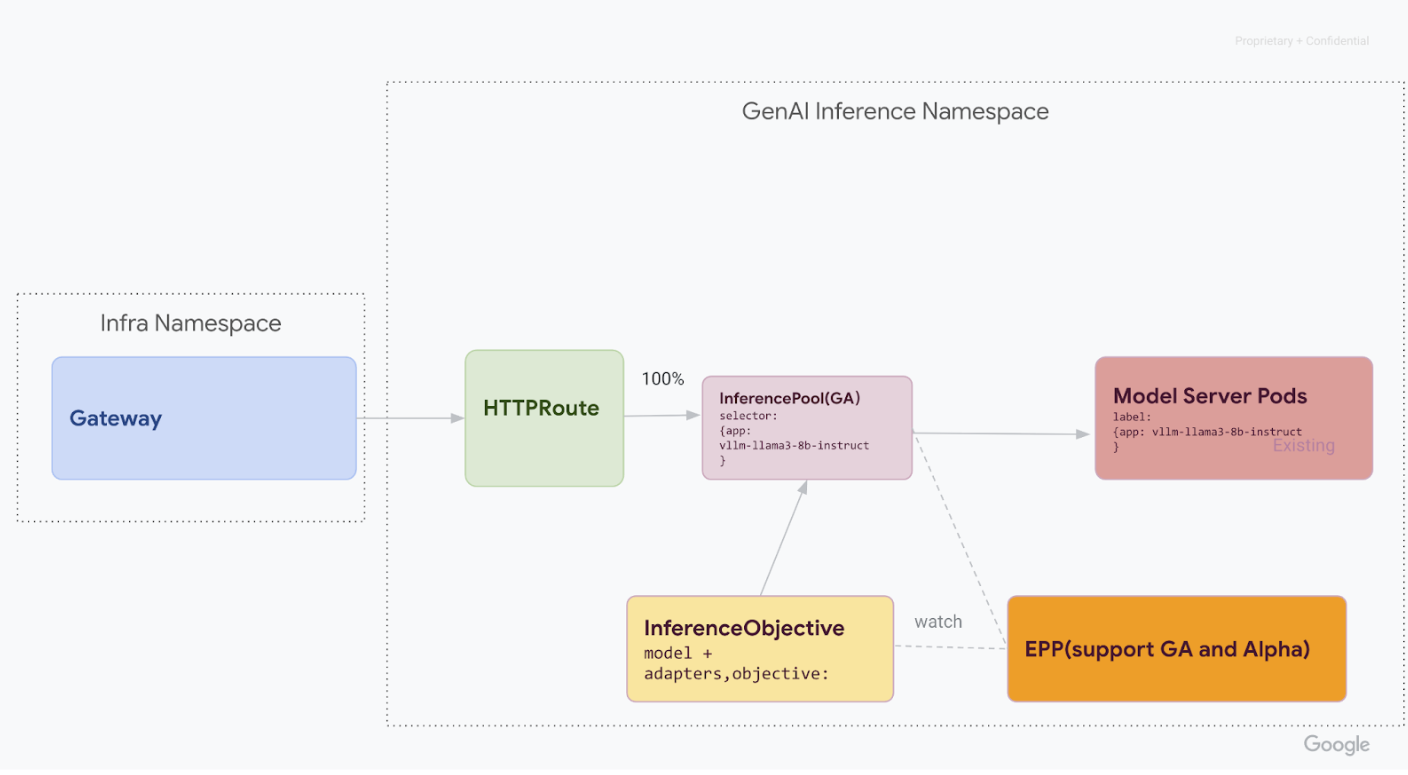
Figura: GKE Inference Gateway instrada le richieste a diversi modelli di AI generativa in base al nome e alla priorità del modello
Passaggi successivi
- Scopri di più su Deploy
GKE Inference Gateway.
- Esplora altre funzionalità di networking GKE.