En esta página se explica cómo migrar la configuración de GKE Inference Gateway de la API v1alpha2 de vista previa a la API v1, que ya está disponible para el público general.
Este documento está dirigido a administradores de plataformas y especialistas en redes que usan la versión v1alpha2 de GKE Inference Gateway y quieren actualizar a la versión 1 para usar las funciones más recientes.
Antes de iniciar la migración, familiarízate con los conceptos y la implementación de GKE Inference Gateway. Te recomendamos que consultes el artículo Implementar GKE Inference Gateway.
Antes de empezar
Antes de iniciar la migración, determina si debes seguir esta guía.
Comprobar si hay APIs v1alpha2
Para comprobar si estás usando la API v1alpha2 GKE Inference Gateway, ejecuta los siguientes comandos:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
La salida de estos comandos determina si debes migrar:
- Si alguno de los comandos devuelve uno o varios recursos
InferencePooloInferenceModel, significa que estás usando la APIv1alpha2y debes seguir esta guía. - Si ambos comandos devuelven
No resources found, significa que no estás usando la APIv1alpha2. Puedes continuar con una instalación nueva dev1GKE Inference Gateway.
Rutas de migración
Hay dos formas de migrar de v1alpha2 a v1:
- Migración sencilla (con tiempo de inactividad): esta opción es más rápida y sencilla, pero conlleva un breve periodo de inactividad. Es la opción recomendada si no necesitas una migración sin tiempo de inactividad.
- Migración sin tiempo de inactividad: esta opción es para los usuarios que no pueden permitirse ninguna interrupción del servicio. Implica ejecutar las pilas
v1alpha2yv1en paralelo y cambiar el tráfico de forma gradual.
Migración sencilla (con tiempo de inactividad)
En esta sección se describe cómo realizar una migración sencilla con tiempo de inactividad.
Eliminar recursos de
v1alpha2: para eliminar los recursos dev1alpha2, elige una de las siguientes opciones:Opción 1: Desinstalar con Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOpción 2: Eliminar recursos manualmente
Si no usas Helm, elimina manualmente todos los recursos asociados a tu despliegue de
v1alpha2:- Actualiza o elimina el
HTTPRoutepara quitar elbackendRefque apunta alv1alpha2InferencePool. - Elimina el
v1alpha2InferencePool, los recursosInferenceModelque apunten a él y la implementación y el servicio de Endpoint Picker (EPP) correspondientes.
Una vez que se hayan eliminado todos los recursos personalizados de
v1alpha2, quita las definiciones de recursos personalizados (CRDs) de tu clúster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Actualiza o elimina el
Instala los recursos de la versión 1: después de limpiar los recursos antiguos, instala la
v1GKE Inference Gateway. Este proceso implica lo siguiente:- Instala las nuevas
v1Custom Resource Definitions (CRDs). - Crea un
v1InferencePooly losInferenceObjectiverecursos correspondientes. El recursoInferenceObjectivesigue definido en la APIv1alpha2. - Crea un nuevo
HTTPRouteque dirija el tráfico a tu nuevov1InferencePool.
- Instala las nuevas
Verifica la implementación: después de unos minutos, comprueba que tu nueva
v1pila esté sirviendo tráfico correctamente.Comprueba que el estado de la pasarela sea
PROGRAMMED:kubectl get gateway -o wideLa salida debería ser similar a esta:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifica el endpoint enviando una solicitud:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Asegúrate de recibir una respuesta correcta con el código de respuesta
200.
Migración sin tiempo de inactividad
Esta ruta de migración se ha diseñado para los usuarios que no pueden permitirse ninguna interrupción del servicio. En el siguiente diagrama se muestra cómo facilita GKE Inference Gateway el servicio de varios modelos de IA generativa, un aspecto clave de una estrategia de migración sin tiempo de inactividad.
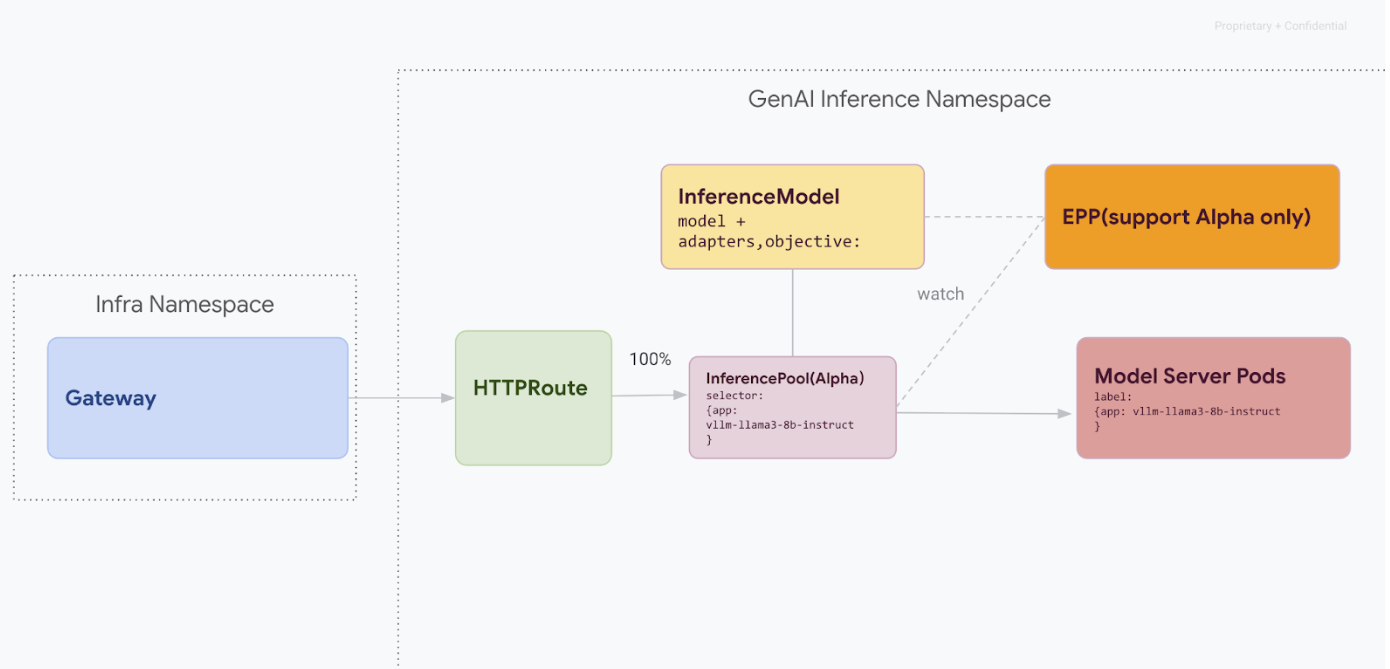
Distinguir versiones de API con kubectl
Durante la migración sin tiempo de inactividad, se instalan CRDs v1alpha2 y v1 en tu clúster. Esto puede generar ambigüedad al usar kubectl para consultar recursos InferencePool. Para asegurarte de que interactúas con la versión correcta, debes usar el nombre de recurso completo:
Para
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioPara
v1:kubectl get inferencepools.inference.networking.k8s.io
La API v1 también proporciona un nombre corto práctico, infpool, que puedes usar para consultar recursos de v1 específicos:
kubectl get infpool
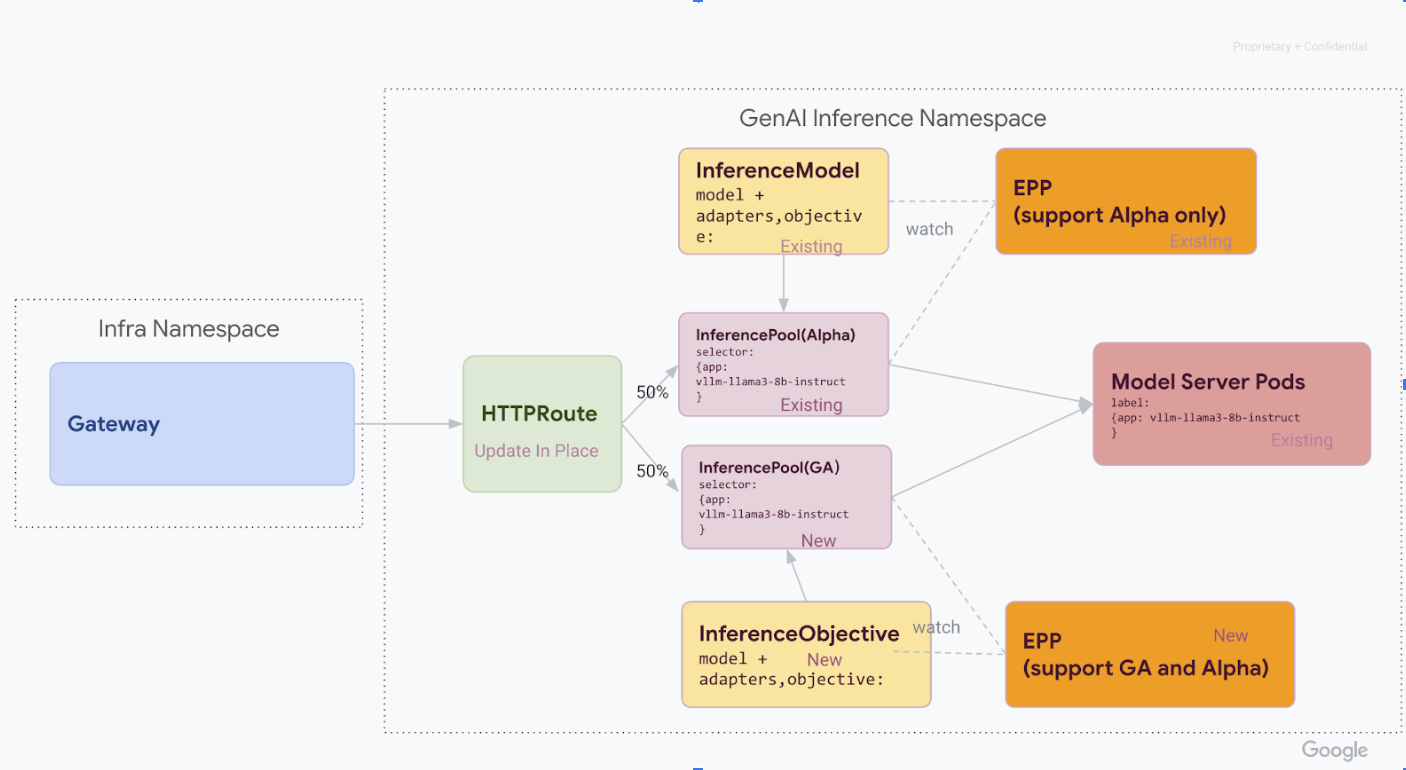
Fase 1: Implementación de la versión 1 en paralelo
En esta fase, implementas la nueva pila InferencePool v1 junto con la pila v1alpha2, lo que permite una migración segura y gradual.
Una vez que hayas completado todos los pasos de esta fase, tendrás la siguiente infraestructura, que se muestra en el diagrama:
Instala las definiciones de recursos personalizados (CRDs) necesarias en tu clúster de GKE:
- En las versiones de GKE anteriores a
1.34.0-gke.1626000, ejecuta el siguiente comando para instalar los CRDs v1InferencePooly alfaInferenceObjective:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- En las versiones de GKE
1.34.0-gke.1626000o posteriores, instala solo el CRD alfaInferenceObjectiveejecutando el siguiente comando:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- En las versiones de GKE anteriores a
Instala
v1 InferencePool.Usa Helm para instalar un nuevo
v1 InferencePoolcon un nombre de lanzamiento distinto, comovllm-llama3-8b-instruct-ga. ElInferencePooldebe orientarse a los mismos pods de Model Server que elInferencePoolalfa medianteinferencePool.modelServers.matchLabels.app.Para instalar
InferencePool, usa el siguiente comando:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolCrea recursos
v1alpha2 InferenceObjective.Como parte de la migración a la versión 1.0 de la extensión de inferencia de la API Gateway, también debemos migrar de la API alfa
InferenceModela la nueva APIInferenceObjective.Aplica el siguiente archivo YAML para crear los recursos
InferenceObjective:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Fase 2: Cambio de tráfico
Con ambas pilas en funcionamiento, puedes empezar a transferir tráfico de v1alpha2 a v1
actualizando HTTPRoute para dividir el tráfico. En este ejemplo se muestra una división al 50 %.
Actualiza HTTPRoute para dividir el tráfico.
Para actualizar el
HTTPRoutepara la división del tráfico, ejecuta el siguiente comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFVerificar y monitorizar.
Después de aplicar los cambios, monitoriza el rendimiento y la estabilidad de la nueva pila
v1. Verifica que la pasarelainference-gatewaytenga el estadoPROGRAMMEDTRUE.
Fase 3: Finalización y limpieza
Una vez que hayas verificado que el v1 InferencePool es estable, puedes dirigir todo el tráfico a él y retirar los recursos del v1alpha2 antiguo.
Dirige el 100% del tráfico a
v1 InferencePool.Para dirigir el 100 % del tráfico a
v1 InferencePool, ejecuta el siguiente comando:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFRealiza la verificación final.
Después de dirigir todo el tráfico a la pila
v1, comprueba que gestione todo el tráfico según lo previsto.Comprueba que el estado de la pasarela sea
PROGRAMMED:kubectl get gateway -o wideLa salida debería ser similar a esta:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifica el endpoint enviando una solicitud:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Asegúrate de recibir una respuesta correcta con el código de respuesta
200.
Elimina los recursos de la versión v1alpha2.
Después de confirmar que la pila
v1funciona correctamente, elimina de forma segura los recursos antiguosv1alpha2.Comprueba si quedan recursos de
v1alpha2.Ahora que has migrado a la API
v1InferencePool, puedes eliminar los CRDs antiguos. Comprueba si hay APIs v1alpha2 para asegurarte de que ya no usas ningún recursov1alpha2. Si aún te quedan algunas, puedes continuar con el proceso de migración.Elimina los CRDs
v1alpha2.Una vez que se hayan eliminado todos los recursos personalizados de
v1alpha2, elimina las definiciones de recursos personalizados (CRD) de tu clúster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlUna vez que hayas completado todos los pasos, tu infraestructura debería ser similar al siguiente diagrama:
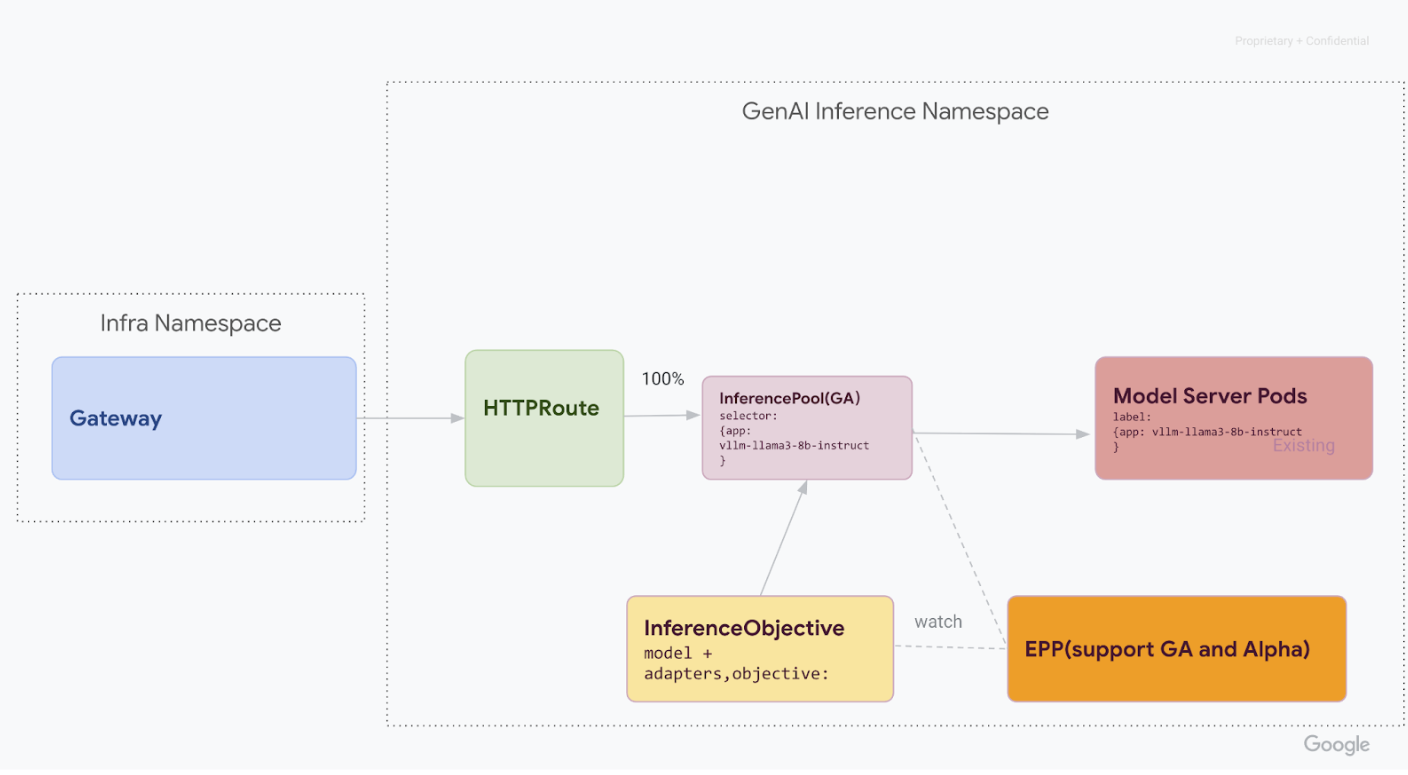
Ilustración: GKE Inference Gateway enruta las solicitudes a diferentes modelos de IA generativa en función del nombre y la prioridad del modelo
Siguientes pasos
- Más información sobre cómo desplegar GKE Inference Gateway
- Consulta otras funciones de redes de GKE.