Cette page explique comment effectuer des opérations de déploiement progressif, qui déploient progressivement de nouvelles versions de votre infrastructure d'inférence, pour la passerelle d'inférence GKE. Cette passerelle vous permet d'effectuer des mises à jour sûres et contrôlées de votre infrastructure d'inférence. Vous pouvez mettre à jour les nœuds, les modèles de base et les adaptateurs LoRA avec une perturbation minimale du service. Cette page fournit également des conseils sur la répartition du trafic et les rollbacks pour garantir des déploiements fiables.
Cette page s'adresse aux administrateurs de comptes et d'identité GKE, ainsi qu'aux développeurs qui souhaitent effectuer des opérations de déploiement pour GKE Inference Gateway.
Les cas d'utilisation suivants sont acceptés :
- Déploiement de la mise à jour des nœuds (calcul, accélérateur)
- Déploiement de la mise à jour du modèle de base
Mettre à jour un déploiement de nœud
Les mises à jour de nœuds migrent en toute sécurité les charges de travail d'inférence vers de nouvelles configurations matérielles ou d'accélérateur de nœuds. Ce processus se déroule de manière contrôlée sans interrompre le service de modèle. Utilisez les mises à jour de nœuds pour minimiser les interruptions de service lors des mises à niveau matérielles, des mises à jour de pilotes ou de la résolution de problèmes de sécurité.
Créer un
InferencePool: déployez unInferencePoolconfiguré avec les spécifications de nœud ou de matériel mises à jour.Répartissez le trafic à l'aide d'un
HTTPRoute: configurez unHTTPRoutepour répartir le trafic entre les ressourcesInferencePoolexistantes et les nouvelles. Utilisez le champweightdansbackendRefspour gérer le pourcentage de trafic dirigé vers les nouveaux nœuds.Conserver un
InferenceObjectivecohérent : conservez la configurationInferenceObjectiveexistante pour garantir un comportement uniforme du modèle dans les deux configurations de nœuds.Conserver les ressources d'origine : conservez les
InferencePoolet les nœuds d'origine actifs pendant le déploiement pour permettre les annulations si nécessaire.
Par exemple, vous pouvez créer un InferencePool nommé llm-new. Configurez ce pool avec la même configuration de modèle que votre llm
InferencePool existant. Déployez le pool sur un nouvel ensemble de nœuds de votre cluster. Utilisez un objet HTTPRoute pour répartir le trafic entre le llm d'origine et le nouveau InferencePool llm-new. Cette technique vous permet de mettre à jour de manière incrémentielle les nœuds de votre modèle.
Le schéma suivant illustre la façon dont GKE Inference Gateway effectue le déploiement de la mise à jour d'un nœud.
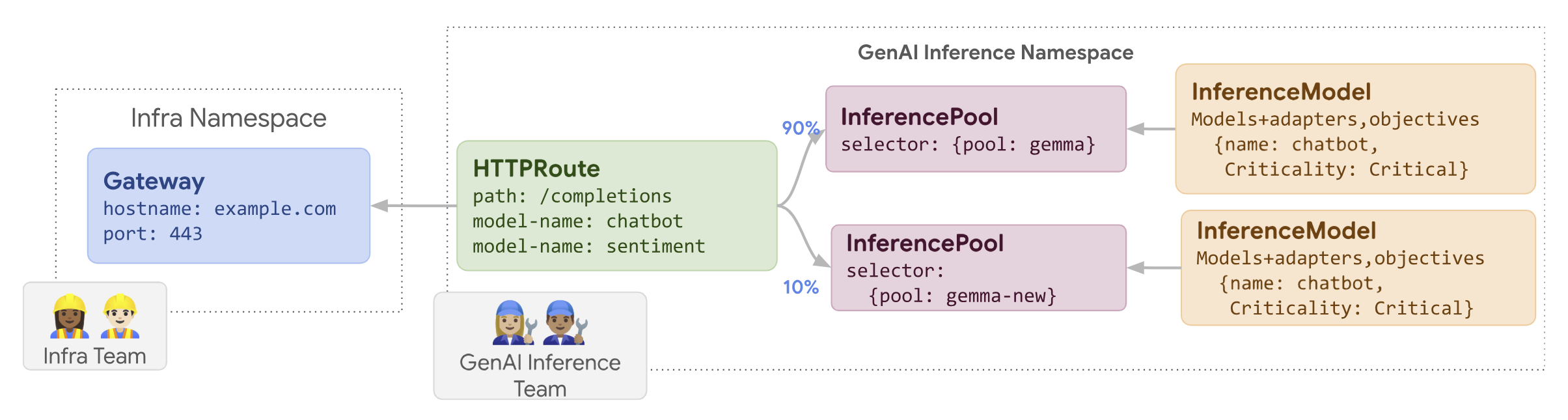
Pour déployer une mise à jour de nœud, procédez comme suit :
Enregistrez l'exemple de fichier manifeste suivant sous le nom
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Appliquez l'exemple de fichier manifeste à votre cluster :
kubectl apply -f routes-to-llm.yaml
La llm InferencePool d'origine reçoit la majeure partie du trafic, tandis que la llm-new InferencePool reçoit le reste. Augmentez progressivement le poids du trafic pour le llm-new InferencePool afin de terminer le déploiement de la mise à jour du nœud.
Déployer un modèle de base
Les mises à jour du modèle de base sont déployées par phases vers un nouveau LLM de base, tout en conservant la compatibilité avec les adaptateurs LoRA existants. Vous pouvez utiliser les déploiements de mise à jour du modèle de base pour passer à des architectures de modèle améliorées ou pour résoudre des problèmes spécifiques aux modèles.
Pour déployer une mise à jour du modèle de base :
- Déployer une nouvelle infrastructure : créez des nœuds et un
InferencePoolconfiguré avec le nouveau modèle de base que vous avez choisi. - Configurer la répartition du trafic : utilisez un
HTTPRoutepour répartir le trafic entre leInferencePoolexistant (qui utilise l'ancien modèle de base) et le nouveauInferencePool(qui utilise le nouveau modèle de base). Le champbackendRefs weightcontrôle le pourcentage de trafic alloué à chaque pool. - Maintenir l'intégrité de
InferenceObjective: conservez la configuration deInferenceObjectivetelle quelle. Cela garantit que le système applique les mêmes adaptateurs LoRA de manière cohérente aux deux versions du modèle de base. - Préserver la capacité de rollback : conservez les nœuds d'origine et
InferencePoollors du déploiement pour faciliter un rollback si nécessaire.
Créez un InferencePool nommé llm-pool-version-2. Ce pool déploie une nouvelle version du modèle de base sur un nouvel ensemble de nœuds. En configurant un HTTPRoute, comme illustré dans l'exemple fourni, vous pouvez répartir progressivement le trafic entre le llm-pool d'origine et llm-pool-version-2. Cela vous permet de contrôler les mises à jour du modèle de base dans votre cluster.
Pour déployer une mise à jour du modèle de base, procédez comme suit :
Enregistrez l'exemple de fichier manifeste suivant sous le nom
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Appliquez l'exemple de fichier manifeste à votre cluster :
kubectl apply -f routes-to-llm.yaml
La llm-pool InferencePool d'origine reçoit la majeure partie du trafic, tandis que la llm-pool-version-2 InferencePool reçoit le reste. Augmentez progressivement le poids du trafic pour le llm-pool-version-2 InferencePool afin de terminer le déploiement de la mise à jour du modèle de base.