In diesem Thema wird ausführlich beschrieben, wie Sie einen Inspektionsjob zum Schutz sensibler Daten erstellen und wiederkehrende Inspektionsjobs durch Erstellen eines Job-Triggers planen. Eine kurze Anleitung zum Erstellen eines neuen Job-Triggers über die Sensitive Data Protection-UI finden Sie unter Kurzanleitung: Job-Trigger für Sensitive Data Protection erstellen.
Informationen zu Inspektionsjobs und Job-Triggern
Wenn der Schutz sensibler Daten einen Inspektionsscan zur Identifizierung vertraulicher Daten durchführt, wird jeder Scan als Job ausgeführt. Der Schutz sensibler Daten erstellt dann eine Jobressource und führt diese aus, wenn Sie es anweisen, Ihre Google Cloud Storage-Repositories zu prüfen, einschließlich Cloud Storage-Buckets, BigQuery-Tabellen, Cloud Datastore-Arten und externer Daten.
Sie planen Scanjobs für die Prüfung auf sensible Daten durch Erstellen von Job-Triggern. Ein Job-Trigger automatisiert die Erstellung von Sensitive Data Protection-Jobs regelmäßig und kann auch on demand ausgeführt werden.
Weitere Informationen zu Jobs und Job-Triggern beim Schutz sensibler Daten finden Sie auf der Konzeptseite Jobs und Job-Trigger.
Einen neuen Inspektionsjob erstellen
So erstellen Sie einen neuen Job für den Schutz sensibler Daten:
Console
Rufen Sie in der Google Cloud Console im Bereich „Schutz sensibler Daten“ die Seite Job oder Jobtrigger erstellen auf.
Zur Seite „Job oder Job-Trigger erstellen“
Die Seite Job oder Job-Trigger erstellen enthält die folgenden Abschnitte:
Eingabedaten auswählen
Name
Geben Sie einen Namen für den Job ein. Sie können Buchstaben, Zahlen und Bindestriche verwenden. Die Benennung des Jobs ist optional. Wenn Sie keinen Namen eingeben, erhält der Job vom Schutz sensibler Daten eine eindeutige Nummernkennzeichnung.
Standort
Wählen Sie im Menü Speichertyp die Art des Repositorys aus, in dem die zu suchenden Daten gespeichert sind:
- Cloud Storage: Geben Sie entweder die URL des Buckets an, den Sie prüfen möchten, oder wählen Sie im Menü Standorttyp die Option Einschließen/Ausschließen aus und klicken Sie dann auf Durchsuchen, um zum Bucket oder Unterordner zu wechseln, den Sie prüfen möchten. Klicken Sie auf das Kästchen Ordner rekursiv scannen, um das angegebene Verzeichnis und alle enthaltenen Verzeichnisse zu prüfen. Wenn Sie nur das angegebene Verzeichnis ohne Unterverzeichnisse prüfen möchten, klicken Sie das Kästchen nicht an.
- BigQuery: Geben Sie die IDs für das Projekt, das Dataset und die Tabelle ein, die Sie prüfen möchten.
- Datastore: Geben Sie die IDs für das Projekt, den Namespace (optional) und die Art ein, die Sie prüfen möchten.
- Hybrid: Sie können erforderliche Labels, optionale Labels und Optionen für die Verarbeitung tabellarischer Daten hinzufügen. Weitere Informationen finden Sie unter Arten von Metadaten, die Sie bereitstellen können.
Probenahme
Eine Probenahme ist eine Alternative, um Ressourcen einzusparen, wenn Sie eine sehr große Datenmenge haben.
Unter Probenahme können Sie wählen, ob alle ausgewählten Daten oder ob nur ein bestimmter Prozentsatz gescannt werden soll. Die Probenahme funktioniert je nach Art des zu durchsuchenden Speicher-Repositorys unterschiedlich:
- Bei BigQuery können Sie in einer Teilmenge der ausgewählten Zeilen suchen, je nach dem Prozentsatz an Dateien, den Sie für den Scan angeben.
- Wenn bei Cloud Storage eine Datei den Wert überschreitet, der unter Max. zu scannende Bytegröße pro Datei angegeben ist, durchsucht der Schutz sensibler Daten diese Datei bis zu dieser maximalen Dateigröße und springt dann zur nächsten Datei.
Wählen Sie im ersten Menü eine der folgenden Optionen aus, um die Probenahme zu aktivieren:
- Probenahme absteigend vom Anfang: Sensitive Data Protection startet den partiellen Scan am Anfang der Daten. Bei BigQuery beginnt der Scan in der ersten Zeile. Bei Cloud Storage beginnt der Scan am Anfang jeder Datei und wird beendet, wenn Sensitive Data Protection bei der Suche eine festgelegte maximale Dateigröße erreicht hat.
- Probenahme an zufälliger Position beginnen: Sensitive Data Protection startet den partiellen Scan an einer zufälligen Position innerhalb der Daten. Bei BigQuery beginnt der Scan in einer zufälligen Zeile. Bei Cloud Storage wirkt sich diese Einstellung nur auf Dateien aus, die eine festgelegte maximale Größe überschreiten. Dateien, die unter dieser maximalen Dateigröße liegen, werden vom Schutz sensibler Daten vollständig gescannt. Dateien über der maximalen Dateigröße werden bis zu diesem Wert gescannt.
Wenn Sie einen partiellen Scan ausführen möchten, müssen Sie außerdem auswählen, welcher Prozentsatz der Daten gescannt werden soll. Diesen Prozentsatz können Sie mit dem Schieberegler einstellen.
Sie können die zu durchsuchenden Dateien oder Datensätze auch nach Datum begrenzen. Weitere Informationen finden Sie weiter unten in diesem Thema unter „Planen“.
Erweiterte Konfiguration
Wenn Sie einen Job für eine Suche in Cloud Storage-Buckets oder BigQuery-Tabellen erstellen, können Sie die Suche durch Angabe einer erweiterten Konfiguration weiter eingrenzen. Dabei haben Sie folgende Konfigurationsoptionen:
- Dateien (nur Cloud Storage): Die zu durchsuchenden Dateitypen, unter anderem Text-, Binär- und Bilddateien.
- Identifizierende Felder (nur BigQuery): Eindeutige Zeilenkennzeichnungen in der Tabelle.
- Wenn bei Cloud Storage eine Datei den Wert überschreitet, der unter Max. zu scannende Bytegröße pro Datei angegeben ist, durchsucht der Schutz sensibler Daten diese Datei bis zu dieser maximalen Dateigröße und springt dann zur nächsten Datei.
Wählen Sie zum Aktivieren der Probenahme den Prozentsatz der Daten aus, die Sie scannen möchten. Diesen Prozentsatz können Sie mit dem Schieberegler einstellen. Wählen Sie dann im ersten Menü eine der folgenden Optionen aus:
- Probenahme absteigend vom Anfang: Sensitive Data Protection startet den partiellen Scan am Anfang der Daten. Bei BigQuery beginnt der Scan in der ersten Zeile. Bei Cloud Storage beginnt der Scan am Anfang jeder Datei und wird beendet, wenn der Schutz sensibler Daten bei der Suche eine festgelegte maximale Dateigröße erreicht hat (siehe oben).
- Probenahme an zufälliger Position beginnen: Sensitive Data Protection startet den partiellen Scan an einer zufälligen Position innerhalb der Daten. Bei BigQuery beginnt der Scan in einer zufälligen Zeile. Bei Cloud Storage wirkt sich diese Einstellung nur auf Dateien aus, die eine festgelegte maximale Größe überschreiten. Dateien, die unter dieser maximalen Dateigröße liegen, werden vom Schutz sensibler Daten vollständig gescannt. Dateien über der maximalen Dateigröße werden bis zu diesem Wert gescannt.
Dateien
Für Dateien, die in Cloud Storage gespeichert sind, können Sie unter Dateien angeben, welche Typen in den Scan einbezogen werden sollen.
Sie können zwischen Binär-, Text-, Bild-, CSV-, TSV-, Microsoft Word-, Microsoft Excel-, Microsoft PowerPoint-, PDF- und Apache Avro-Dateien wählen. Eine umfassende Liste der Dateitypen, die von Sensitive Data Protection in Cloud Storage-Buckets gescannt werden können, finden Sie unter FileType.
Wenn Sie Binärdateien auswählen, werden mit Sensitive Data Protection auch Dateitypen gescannt, die nicht erkannt wurden.
Identifizierende Felder
Bei Tabellen in BigQuery können Sie im Feld Identifizierende Felder angeben, dass der Schutz sensibler Daten die Werte der primären Schlüsselspalten der Tabelle in die Ergebnisse aufnehmen soll. So können Sie die Ergebnisse mit den zugehörigen Tabellenzeilen verknüpfen.
Geben Sie die Namen der Spalten ein, mit denen jede Zeile in der Tabelle eindeutig identifiziert wird. Verwenden Sie ggf. Punkte, um verschachtelte Felder anzugeben. Sie können beliebig viele Felder hinzufügen.
Außerdem müssen Sie die Aktion In BigQuery speichern aktivieren, um die Ergebnisse nach BigQuery zu exportieren. Wenn die Ergebnisse nach BigQuery exportiert werden, enthält jedes Ergebnis die entsprechenden Werte der identifizierenden Felder. Weitere Informationen finden Sie unter identifyingFields.
Erkennung konfigurieren
Im Abschnitt Erkennung konfigurieren legen Sie die Typen sensibler Daten fest, nach denen Sie suchen möchten. Das Bearbeiten dieses Abschnitts ist optional. Wenn Sie diesen Abschnitt überspringen, sucht der Schutz sensibler Daten in Ihren Daten nach einem Standardsatz von infoTypes.
Vorlage
Sie können optional eine Vorlage für den Schutz sensibler Daten verwenden, um zuvor angegebene Konfigurationsinformationen wiederzuverwenden.
Wenn Sie bereits eine Vorlage erstellt haben, die Sie verwenden möchten, klicken Sie in das Feld Vorlagenname, um eine Liste der vorhandenen Inspektionsvorlagen anzusehen. Geben Sie den Namen der Vorlage ein, die Sie verwenden möchten, oder wählen Sie diese aus.
Weitere Informationen zum Erstellen von Vorlagen finden Sie unter Inspektionsvorlagen für den Schutz sensibler Daten erstellen.
infoTypes
infoType-Detektoren finden sensible Daten eines bestimmten Typs. Der in der Funktion zum Schutz sensibler Daten integrierte infoType-Detektor US_SOCIAL_SECURITY_NUMBER findet beispielsweise US-amerikanische Sozialversicherungsnummern. Zusätzlich zu den integrierten infoType-Detektoren können Sie eigene benutzerdefinierte infoType-Detektoren erstellen.
Wählen Sie unter infoTypes den infoType-Detektor aus, der einem Datentyp entspricht, nach dem Sie scannen möchten. Wir empfehlen, diesen Abschnitt nicht leer zu lassen. Dadurch werden Ihre Daten mit einem Standardsatz von infoTypes gescannt, der möglicherweise infoTypes enthält, die Sie nicht benötigen. Weitere Informationen zu den einzelnen Detektoren finden Sie in der InfoType-Detektorreferenz.
Weitere Informationen zum Verwalten von vordefinierten und benutzerdefinierten infoTypes in diesem Abschnitt finden Sie unter InfoTypes über die Google Cloud Console verwalten.
Inspektionsregelsätze
Mit Inspektionsregelsätzen können Sie sowohl integrierte als auch benutzerdefinierte infoType-Detektoren mithilfe von Kontextregeln anpassen. Die zwei Arten von Prüfregeln sind:
- Ausschlussregeln, die helfen, falsche oder unerwünschte Ergebnisse auszuschließen.
- Hotword-Regeln, die helfen, zusätzliche Ergebnisse zu erkennen.
Wenn Sie einen neuen Regelsatz hinzufügen möchten, müssen Sie zuerst einen oder mehrere integrierte oder benutzerdefinierte infoType-Detektoren im Bereich InfoTypes angeben. Das sind die infoType-Detektoren, die von Ihren Regelsätzen geändert werden. Gehen Sie anschließend so vor:
- Klicken Sie in das Feld InfoTypes auswählen. Die zuvor angegebene(n) infoType(s) werden in einem Menü unter dem Feld angezeigt, wie hier dargestellt:
- Wählen Sie im Menü einen infoType aus und klicken Sie dann auf Regel hinzufügen. Ein Menü mit den beiden Optionen Hotword-Regel und Ausschlussregel wird angezeigt.
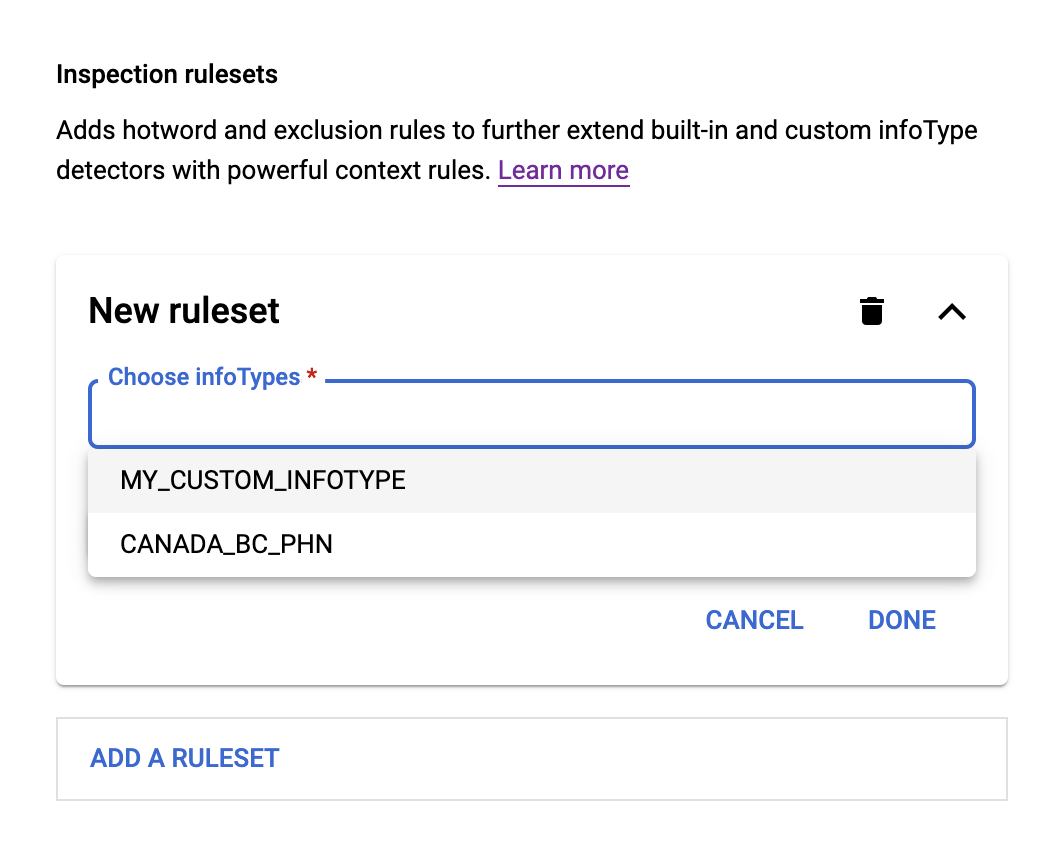
Wählen Sie für Hotword-Regeln Hotword-Regeln aus. Gehen Sie anschließend so vor:
- Geben Sie im Feld Hotword einen regulären Ausdruck ein, nach dem die Funktion „Schutz sensibler Daten“ suchen soll.
- Wählen Sie im Menü Hotword-Nähe aus, ob das eingegebene Hotword vor oder nach dem ausgewählten infoType gefunden werden soll.
- Geben Sie unter Hotword-Abstand von infoType die ungefähre Anzahl der Zeichen zwischen dem Hotword und dem ausgewählten infoType ein.
- Wählen Sie unter Anpassung des Konfidenzniveaus aus, ob Übereinstimmungen ein festes Wahrscheinlichkeitsniveau zugewiesen werden sollen oder ob das Standardwahrscheinlichkeitsniveau um einen bestimmten Wert erhöht oder verringert werden soll.
Wählen Sie für Ausschlussregeln die Option Ausschlussregeln aus. Gehen Sie anschließend so vor:
- Geben Sie im Feld Ausschließen einen regulären Ausdruck ein, nach dem bei der Prüfung auf sensible Daten gesucht werden soll.
- Wählen Sie im Menü Abgleichstyp eine der folgenden Optionen aus:
- Vollständige Übereinstimmung: Der Suchbegriff muss vollständig mit dem regulären Ausdruck übereinstimmen.
- Teilübereinstimmung: Ein Teilstring des Ergebnisses kann mit dem regulären Ausdruck übereinstimmen.
- Invertierte Übereinstimmung: Der Begriff stimmt nicht mit dem Regex überein.
Sie können zusätzliche Hotword- oder Ausschlussregeln und Regelsätze hinzufügen, um die Ergebnisse der Suche weiter zu verfeinern.
Konfidenzwert
Jedes Mal, wenn der Schutz sensibler Daten eine potenzielle Übereinstimmung mit sensiblen Daten erkennt, wird ihr ein Wahrscheinlichkeitswert auf einer Skala von „Sehr unwahrscheinlich“ bis „Sehr wahrscheinlich“ zugewiesen. Wenn Sie hier einen Wahrscheinlichkeitswert festlegen, wird Sensitive Data Protection angewiesen, nur Daten abzugleichen, die diesem Wahrscheinlichkeitswert oder einem höheren entsprechen.
Der Standardwert "Möglich" ist für die meisten Zwecke ausreichend. Wenn Sie regelmäßig zu viele Übereinstimmungen erhalten, können Sie den Wert über den Schieberegler erhöhen. Wenn Sie zu wenige Übereinstimmungen erhalten, verringern Sie den erforderlichen Wahrscheinlichkeitswert über den Schieberegler.
Wenn Sie fertig sind, klicken Sie auf Weiter.
Aktionen hinzufügen
Wählen Sie im Schritt Aktionen hinzufügen eine oder mehrere Aktionen aus, die der Schutz sensibler Daten nach Abschluss des Jobs ausführen soll.
Sie können die folgenden Aktionen konfigurieren:
In BigQuery speichern: Speichern Sie die Ergebnisse des Jobs zum Schutz sensibler Daten in einer BigQuery. Bevor Sie die Ergebnisse ansehen oder analysieren, sollten Sie zuerst prüfen, ob der Job abgeschlossen wurde.
Bei jeder Ausführung eines Scans speichert der Schutz sensibler Daten die Scanergebnisse in der von Ihnen angegebenen BigQuery-Tabelle. Die exportierten Ergebnisse enthalten Details zum Speicherort der einzelnen Übereinstimmungen und zur Übereinstimmungswahrscheinlichkeit. Wenn jeder Treffer den String enthalten soll, der mit dem infoType-Detektor übereinstimmt, aktivieren Sie die Option Zitat einschließen.
Wenn Sie keine Tabellen-ID angeben, weist BigQuery einer neuen Tabelle einen Standardnamen zu, wenn der Scan zum ersten Mal ausgeführt wird. Wenn Sie eine vorhandene Tabelle angeben, hängt der Schutz sensibler Daten Scanergebnisse an diese an.
Wenn Sie die Ergebnisse nicht in BigQuery speichern, enthalten die Scanergebnisse nur Statistiken zur Anzahl und zu den infoTypes der Ergebnisse.
Wenn Daten in eine BigQuery-Tabelle geschrieben werden, werden die Abrechnung und Kontingentnutzung auf das Projekt angewendet, das die Zieltabelle enthält.
In Pub/Sub veröffentlichen: Veröffentlichen Sie eine Benachrichtigung, die den Namen des Jobs zum Schutz sensibler Daten als Attribut für einen Pub/Sub-Kanal enthält. Sie können eine oder mehrere Themen angeben, an die die Benachrichtigung gesendet werden soll. Das Dienstkonto für den Schutz sensibler Daten, mit dem der Scanjob ausgeführt wird, muss Veröffentlichungszugriff auf das Thema haben.
In Security Command Center veröffentlichen: Hiermit wird eine Zusammenfassung der Jobergebnisse im Security Command Center veröffentlicht. Weitere Informationen finden Sie unter Scanergebnisse zum Schutz sensibler Daten an das Security Command Center senden.
In Dataplex veröffentlichen: Jobergebnisse werden an Dataplex, den Metadatenverwaltungsdienst von Google Cloud, gesendet.
Per E-Mail benachrichtigen: Es wird eine E-Mail gesendet, wenn der Job abgeschlossen ist. Die E-Mail wird an IAM-Projektinhaber und wichtige technische Kontakte gesendet.
In Cloud Monitoring veröffentlichen: Senden Sie Inspektionsergebnisse an Cloud Monitoring in Google Cloud Observability.
De-identifizierte Kopie erstellen: De-identifizieren Sie alle Ergebnisse in den geprüften Daten und schreiben Sie die de-identifizierten Inhalte in eine neue Datei. Sie können die de-identifizierte Kopie dann in Ihren Geschäftsprozessen anstelle von Daten verwenden, die vertrauliche Informationen enthalten. Weitere Informationen finden Sie unter De-identifizierte Kopie von Cloud Storage-Daten mit Sensitive Data Protection in der Google Cloud Console erstellen.
Weitere Informationen finden Sie unter Aktionen.
Wenn Sie fertig sind, klicken Sie auf Continue (Weiter).
Prüfen
Der Abschnitt Prüfen enthält eine Zusammenfassung der gerade angegebenen Jobeinstellungen im JSON-Format.
Klicken Sie auf Erstellen, um den Job zu erstellen und den Job einmal auszuführen (falls Sie keinen Zeitplan angegeben haben). Die Informationsseite des Jobs wird angezeigt. Sie enthält den Status und andere Informationen. Während der Job ausgeführt wird, können Sie auf die Schaltfläche Abbrechen klicken, um ihn zu stoppen. Um den Job zu löschen klicken Sie auf Löschen.
Klicken Sie in der Google Cloud Console auf den Pfeil Zurück, um zur Hauptseite zum Schutz sensibler Daten zurückzukehren.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Jobs werden in der DLP API durch die Ressource DlpJobs dargestellt. Sie können einen neuen Job unter Einsatz der Methode projects.dlpJobs.create der Ressource DlpJob erstellen.
Dieses JSON-Beispiel kann in einer POST-Anfrage an den angegebenen REST-Endpunkt für den Schutz sensibler Daten gesendet werden. In diesem Beispiel für JSON-Code wird veranschaulicht, wie in der Funktion zum Schutz sensibler Daten ein Job erstellt wird. Der Job ist ein Datastore-Inspektionsscan.
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Beachten Sie, dass eine erfolgreiche Anfrage, auch wenn sie im API Explorer erstellt wurde, einen Job erzeugt. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
JSON-Eingabe:
{
"inspectJob": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"excludeInfoTypes": false,
"includeQuote": true,
"minLikelihood": "LIKELY"
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]"
}
}
}
}
]
}
}
JSON-Ausgabe:
Die folgende Ausgabe zeigt an, dass der Job erfolgreich erstellt wurde.
{
"name": "projects/[PROJECT-ID]/dlpJobs/[JOB-ID]",
"type": "INSPECT_JOB",
"state": "PENDING",
"inspectDetails": {
"requestedOptions": {
"snapshotInspectTemplate": {},
"jobConfig": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"minLikelihood": "LIKELY",
"limits": {},
"includeQuote": true
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]",
"tableId": "[TABLE-ID]"
}
}
}
}
]
}
},
"result": {}
},
"createTime": "2020-07-10T07:26:33.643Z"
}
Einen neuen Job-Trigger erstellen
So erstellen Sie einen neuen Jobtrigger für den Schutz sensibler Daten:
Console
Rufen Sie in der Google Cloud Console im Bereich „Schutz sensibler Daten“ die Seite Job oder Jobtrigger erstellen auf.
Zur Seite „Job oder Job-Trigger erstellen“
Die Seite Job oder Job-Trigger erstellen enthält die folgenden Abschnitte:
Eingabedaten auswählen
Name
Geben Sie einen Namen für den Job-Trigger ein. Sie können Buchstaben, Zahlen und Bindestriche verwenden. Das Benennen des Job-Triggers ist optional. Wenn Sie keinen Namen eingeben, erhält der Job-Trigger vom Schutz sensibler Daten eine eindeutige Nummernkennzeichnung.
Standort
Wählen Sie im Menü Speichertyp die Art des Repositorys aus, in dem die zu suchenden Daten gespeichert sind:
- Cloud Storage: Geben Sie entweder die URL des Buckets an, den Sie prüfen möchten, oder wählen Sie im Menü Standorttyp die Option Einschließen/Ausschließen aus und klicken Sie dann auf Durchsuchen, um zum Bucket oder Unterordner zu wechseln, den Sie prüfen möchten. Klicken Sie auf das Kästchen Ordner rekursiv scannen, um das angegebene Verzeichnis und alle enthaltenen Verzeichnisse zu prüfen. Wenn Sie nur das angegebene Verzeichnis ohne Unterverzeichnisse prüfen möchten, klicken Sie das Kästchen nicht an.
- BigQuery: Geben Sie die IDs für das Projekt, das Dataset und die Tabelle ein, die Sie prüfen möchten.
- Datastore: Geben Sie die IDs für das Projekt, den Namespace (optional) und die Art ein, die Sie prüfen möchten.
Probenahme
Eine Probenahme ist eine Alternative, um Ressourcen einzusparen, wenn Sie eine sehr große Datenmenge haben.
Unter Probenahme können Sie wählen, ob alle ausgewählten Daten oder ob nur ein bestimmter Prozentsatz gescannt werden soll. Die Probenahme funktioniert je nach Art des zu durchsuchenden Speicher-Repositorys unterschiedlich:
- Bei BigQuery können Sie in einer Teilmenge der ausgewählten Zeilen suchen, je nach dem Prozentsatz an Dateien, den Sie für den Scan angeben.
- Wenn bei Cloud Storage eine Datei den Wert überschreitet, der unter Max. zu scannende Bytegröße pro Datei angegeben ist, durchsucht der Schutz sensibler Daten diese Datei bis zu dieser maximalen Dateigröße und springt dann zur nächsten Datei.
Wählen Sie im ersten Menü eine der folgenden Optionen aus, um die Probenahme zu aktivieren:
- Probenahme absteigend vom Anfang: Sensitive Data Protection startet den partiellen Scan am Anfang der Daten. Bei BigQuery beginnt der Scan in der ersten Zeile. Bei Cloud Storage beginnt der Scan am Anfang jeder Datei und wird beendet, wenn der Schutz sensibler Daten bei der Suche eine festgelegte maximale Dateigröße erreicht hat (siehe oben).
- Probenahme an zufälliger Position beginnen: Sensitive Data Protection startet den partiellen Scan an einer zufälligen Position innerhalb der Daten. Bei BigQuery beginnt der Scan in einer zufälligen Zeile. Bei Cloud Storage wirkt sich diese Einstellung nur auf Dateien aus, die eine festgelegte maximale Größe überschreiten. Dateien, die unter dieser maximalen Dateigröße liegen, werden vom Schutz sensibler Daten vollständig gescannt. Dateien über der maximalen Dateigröße werden bis zu diesem Wert gescannt.
Wenn Sie einen partiellen Scan ausführen möchten, müssen Sie außerdem auswählen, welcher Prozentsatz der Daten gescannt werden soll. Diesen Prozentsatz können Sie mit dem Schieberegler einstellen.
Erweiterte Konfiguration
Wenn Sie einen Job-Trigger erstellen, um in Cloud Storage-Buckets oder BigQuery-Tabellen zu suchen, können Sie die Suche mit einer erweiterten Konfiguration weiter eingrenzen. Dabei haben Sie folgende Konfigurationsoptionen:
- Dateien (nur Cloud Storage): Die zu durchsuchenden Dateitypen, unter anderem Text-, Binär- und Bilddateien.
- Identifizierende Felder (nur BigQuery): Eindeutige Zeilenkennzeichnungen in der Tabelle.
- Wenn bei Cloud Storage eine Datei den Wert überschreitet, der unter Max. zu scannende Bytegröße pro Datei angegeben ist, durchsucht der Schutz sensibler Daten diese Datei bis zu dieser maximalen Dateigröße und springt dann zur nächsten Datei.
Wählen Sie zum Aktivieren der Probenahme den Prozentsatz der Daten aus, die Sie scannen möchten. Diesen Prozentsatz können Sie mit dem Schieberegler einstellen. Wählen Sie dann im ersten Menü eine der folgenden Optionen aus:
- Probenahme absteigend vom Anfang: Sensitive Data Protection startet den partiellen Scan am Anfang der Daten. Bei BigQuery beginnt der Scan in der ersten Zeile. Bei Cloud Storage beginnt der Scan am Anfang jeder Datei und wird beendet, wenn der Schutz sensibler Daten bei der Suche eine festgelegte maximale Dateigröße erreicht hat (siehe oben).
- Probenahme an zufälliger Position beginnen: Sensitive Data Protection startet den partiellen Scan an einer zufälligen Position innerhalb der Daten. Bei BigQuery beginnt der Scan in einer zufälligen Zeile. Bei Cloud Storage wirkt sich diese Einstellung nur auf Dateien aus, die eine festgelegte maximale Größe überschreiten. Dateien, die unter dieser maximalen Dateigröße liegen, werden vom Schutz sensibler Daten vollständig gescannt. Dateien über der maximalen Dateigröße werden bis zu diesem Wert gescannt.
Dateien
Für Dateien, die in Cloud Storage gespeichert sind, können Sie unter Dateien angeben, welche Typen in den Scan einbezogen werden sollen.
Sie können zwischen Binär-, Text-, Bild-, Microsoft Word-, Microsoft Excel-, Microsoft PowerPoint-, PDF- und Apache Avro-Dateien wählen. Eine vollständige Liste der Dateiendungen, die mit dem Schutz sensibler Daten in Cloud Storage-Buckets gescannt werden können, finden Sie unter FileType.
Wenn Sie Binärdateien auswählen, werden mit Sensitive Data Protection auch Dateitypen gescannt, die nicht erkannt wurden.
Identifizierende Felder
Bei Tabellen in BigQuery können Sie im Feld Identifizierende Felder angeben, dass der Schutz sensibler Daten die Werte der primären Schlüsselspalten der Tabelle in die Ergebnisse aufnehmen soll. So können Sie die Ergebnisse mit den zugehörigen Tabellenzeilen verknüpfen.
Geben Sie die Namen der Spalten ein, mit denen jede Zeile in der Tabelle eindeutig identifiziert wird. Verwenden Sie ggf. Punkte, um verschachtelte Felder anzugeben. Sie können beliebig viele Felder hinzufügen.
Außerdem müssen Sie die Aktion In BigQuery speichern aktivieren, um die Ergebnisse nach BigQuery zu exportieren. Wenn die Ergebnisse nach BigQuery exportiert werden, enthält jedes Ergebnis die entsprechenden Werte der identifizierenden Felder. Weitere Informationen finden Sie unter identifyingFields.
Erkennung konfigurieren
Im Abschnitt Erkennung konfigurieren legen Sie die Typen sensibler Daten fest, nach denen Sie suchen möchten. Das Bearbeiten dieses Abschnitts ist optional. Wenn Sie diesen Abschnitt überspringen, sucht der Schutz sensibler Daten in Ihren Daten nach einem Standardsatz von infoTypes.
Vorlage
Sie können optional eine Vorlage für den Schutz sensibler Daten verwenden, um zuvor angegebene Konfigurationsinformationen wiederzuverwenden.
Wenn Sie bereits eine Vorlage erstellt haben, die Sie verwenden möchten, klicken Sie in das Feld Vorlagenname, um eine Liste der vorhandenen Inspektionsvorlagen anzusehen. Geben Sie den Namen der Vorlage ein, die Sie verwenden möchten, oder wählen Sie diese aus.
Weitere Informationen zum Erstellen von Vorlagen finden Sie unter Inspektionsvorlagen für den Schutz sensibler Daten erstellen.
infoTypes
infoType-Detektoren finden sensible Daten eines bestimmten Typs. Der in der Funktion zum Schutz sensibler Daten integrierte infoType-Detektor US_SOCIAL_SECURITY_NUMBER findet beispielsweise US-amerikanische Sozialversicherungsnummern. Zusätzlich zu den integrierten infoType-Detektoren können Sie eigene benutzerdefinierte infoType-Detektoren erstellen.
Wählen Sie unter infoTypes den infoType-Detektor aus, der einem Datentyp entspricht, nach dem Sie scannen möchten. Sie können dieses Feld auch leer lassen, um nach allen Standard-infoTypes zu suchen. Weitere Informationen zu jedem Detektor finden Sie in der infoType-Detektorreferenz.
Sie können auch benutzerdefinierte infoType-Detektoren im Bereich Benutzerdefinierte infoTypes hinzufügen. Im Bereich Inspektionsregelsätze können Sie sowohl integrierte als auch benutzerdefinierte infoType-Detektoren anpassen.
Benutzerdefinierte infoTypes
Inspektionsregelsätze
Mit Inspektionsregelsätzen können Sie sowohl integrierte als auch benutzerdefinierte infoType-Detektoren mithilfe von Kontextregeln anpassen. Die zwei Arten von Prüfregeln sind:
- Ausschlussregeln, die helfen, falsche oder unerwünschte Ergebnisse auszuschließen.
- Hotword-Regeln, die helfen, zusätzliche Ergebnisse zu erkennen.
Wenn Sie einen neuen Regelsatz hinzufügen möchten, müssen Sie zuerst einen oder mehrere integrierte oder benutzerdefinierte infoType-Detektoren im Bereich InfoTypes angeben. Das sind die infoType-Detektoren, die von Ihren Regelsätzen geändert werden. Gehen Sie anschließend so vor:
- Klicken Sie in das Feld InfoTypes auswählen. Die zuvor angegebene(n) infoType(s) werden in einem Menü unter dem Feld angezeigt, wie hier dargestellt:
- Wählen Sie im Menü einen infoType aus und klicken Sie dann auf Regel hinzufügen. Ein Menü mit den beiden Optionen Hotword-Regel und Ausschlussregel wird angezeigt.
Wählen Sie für Hotword-Regeln Hotword-Regeln aus. Gehen Sie anschließend so vor:
- Geben Sie im Feld Hotword einen regulären Ausdruck ein, nach dem die Funktion „Schutz sensibler Daten“ suchen soll.
- Wählen Sie im Menü Hotword-Nähe aus, ob das eingegebene Hotword vor oder nach dem ausgewählten infoType gefunden werden soll.
- Geben Sie unter Hotword-Abstand von infoType die ungefähre Anzahl der Zeichen zwischen dem Hotword und dem ausgewählten infoType ein.
- Wählen Sie unter Anpassung des Konfidenzniveaus aus, ob Übereinstimmungen ein festes Wahrscheinlichkeitsniveau zugewiesen werden sollen oder ob das Standardwahrscheinlichkeitsniveau um einen bestimmten Wert erhöht oder verringert werden soll.
Wählen Sie für Ausschlussregeln die Option Ausschlussregeln aus. Gehen Sie anschließend so vor:
- Geben Sie im Feld Ausschließen einen regulären Ausdruck ein, nach dem bei der Prüfung auf sensible Daten gesucht werden soll.
- Wählen Sie im Menü Abgleichstyp eine der folgenden Optionen aus:
- Vollständige Übereinstimmung: Der Suchbegriff muss vollständig mit dem regulären Ausdruck übereinstimmen.
- Teilübereinstimmung: Ein Teilstring des Ergebnisses kann mit dem regulären Ausdruck übereinstimmen.
- Invertierte Übereinstimmung: Der Begriff stimmt nicht mit dem Regex überein.
Sie können zusätzliche Hotword- oder Ausschlussregeln und Regelsätze hinzufügen, um die Ergebnisse der Suche weiter zu verfeinern.
Konfidenzwert
Jedes Mal, wenn der Schutz sensibler Daten eine potenzielle Übereinstimmung mit sensiblen Daten erkennt, wird ihr ein Wahrscheinlichkeitswert auf einer Skala von „Sehr unwahrscheinlich“ bis „Sehr wahrscheinlich“ zugewiesen. Wenn Sie hier einen Wahrscheinlichkeitswert festlegen, wird Sensitive Data Protection angewiesen, nur Daten abzugleichen, die diesem Wahrscheinlichkeitswert oder einem höheren entsprechen.
Der Standardwert "Möglich" ist für die meisten Zwecke ausreichend. Wenn Sie regelmäßig zu viele Übereinstimmungen erhalten, können Sie den Wert über den Schieberegler erhöhen. Wenn Sie zu wenige Übereinstimmungen erhalten, verringern Sie den erforderlichen Wahrscheinlichkeitswert über den Schieberegler.
Wenn Sie fertig sind, klicken Sie auf Weiter.
Aktionen hinzufügen
Wählen Sie im Schritt Aktionen hinzufügen eine oder mehrere Aktionen aus, die der Schutz sensibler Daten nach Abschluss des Jobs ausführen soll.
Sie können die folgenden Aktionen konfigurieren:
In BigQuery speichern: Speichern Sie die Ergebnisse des Jobs zum Schutz sensibler Daten in einer BigQuery. Bevor Sie die Ergebnisse ansehen oder analysieren, sollten Sie zuerst prüfen, ob der Job abgeschlossen wurde.
Bei jeder Ausführung eines Scans speichert der Schutz sensibler Daten die Scanergebnisse in der von Ihnen angegebenen BigQuery-Tabelle. Die exportierten Ergebnisse enthalten Details zum Speicherort der einzelnen Übereinstimmungen und zur Übereinstimmungswahrscheinlichkeit. Wenn jeder Treffer den String enthalten soll, der mit dem infoType-Detektor übereinstimmt, aktivieren Sie die Option Zitat einschließen.
Wenn Sie keine Tabellen-ID angeben, weist BigQuery einer neuen Tabelle einen Standardnamen zu, wenn der Scan zum ersten Mal ausgeführt wird. Wenn Sie eine vorhandene Tabelle angeben, hängt der Schutz sensibler Daten Scanergebnisse an diese an.
Wenn Sie die Ergebnisse nicht in BigQuery speichern, enthalten die Scanergebnisse nur Statistiken zur Anzahl und zu den infoTypes der Ergebnisse.
Wenn Daten in eine BigQuery-Tabelle geschrieben werden, werden die Abrechnung und Kontingentnutzung auf das Projekt angewendet, das die Zieltabelle enthält.
In Pub/Sub veröffentlichen: Veröffentlichen Sie eine Benachrichtigung, die den Namen des Jobs zum Schutz sensibler Daten als Attribut für einen Pub/Sub-Kanal enthält. Sie können eine oder mehrere Themen angeben, an die die Benachrichtigung gesendet werden soll. Das Dienstkonto für den Schutz sensibler Daten, mit dem der Scanjob ausgeführt wird, muss Veröffentlichungszugriff auf das Thema haben.
In Security Command Center veröffentlichen: Hiermit wird eine Zusammenfassung der Jobergebnisse im Security Command Center veröffentlicht. Weitere Informationen finden Sie unter Scanergebnisse zum Schutz sensibler Daten an das Security Command Center senden.
In Dataplex veröffentlichen: Jobergebnisse werden an Dataplex, den Metadatenverwaltungsdienst von Google Cloud, gesendet.
Per E-Mail benachrichtigen: Es wird eine E-Mail gesendet, wenn der Job abgeschlossen ist. Die E-Mail wird an IAM-Projektinhaber und wichtige technische Kontakte gesendet.
In Cloud Monitoring veröffentlichen: Senden Sie Inspektionsergebnisse an Cloud Monitoring in Google Cloud Observability.
De-identifizierte Kopie erstellen: De-identifizieren Sie alle Ergebnisse in den geprüften Daten und schreiben Sie die de-identifizierten Inhalte in eine neue Datei. Sie können die de-identifizierte Kopie dann in Ihren Geschäftsprozessen anstelle von Daten verwenden, die vertrauliche Informationen enthalten. Weitere Informationen finden Sie unter De-identifizierte Kopie von Cloud Storage-Daten mit Sensitive Data Protection in der Google Cloud Console erstellen.
Weitere Informationen finden Sie unter Aktionen.
Wenn Sie fertig sind, klicken Sie auf Continue (Weiter).
Planen
Im Abschnitt Schedule (Planen) haben Sie zwei Möglichkeiten:
- Specify time span (Zeitraum angeben): Mit dieser Option können Sie die zu durchsuchenden Dateien oder Zeilen nach Datum begrenzen. Klicken Sie auf Beginn, um den frühesten Zeitstempel der Dateien anzugeben, die in die Suche einbezogen werden sollen. Lassen Sie diesen Wert leer, wenn alle Dateien durchsucht werden sollen. Klicken Sie auf Ende, um den Zeitstempel der neuesten Dateien anzugeben, die einbezogen werden sollen. Wenn Sie diesen Wert leer lassen, wird kein oberes Zeitstempel-Limit festgelegt.
Trigger zum Ausführen des Jobs nach einem regelmäßigen Zeitplan erstellen: Mit dieser Option wird der Job in einen Job-Trigger umgewandelt, der nach einem regelmäßigen Zeitplan ausgeführt wird. Wenn Sie keinen Zeitplan angeben, erstellen Sie einen einzelnen Job, der sofort gestartet und einmal ausgeführt wird. Wenn Sie einen Job-Trigger erstellen möchten, der regelmäßig einen Job ausführt, müssen Sie diese Option festlegen.
Der Standardwert ist die Mindestdauer: 24 Stunden. Der maximale Wert ist 60 Tage.
Wenn der Schutz sensibler Daten nur neue Dateien oder Zeilen scannen soll, wählen Sie Scans ausschließlich auf neuen Inhalt beschränken aus. Bei der BigQuery-Prüfung werden nur Zeilen, die mindestens drei Stunden alt sind, in den Scan einbezogen. Weitere Informationen finden Sie im Hilfeartikel zu bekannten Problemen mit diesem Vorgang.
Überprüfen
Der Abschnitt Prüfen enthält eine Zusammenfassung der gerade angegebenen Jobeinstellungen im JSON-Format.
Klicken Sie auf Erstellen, um den Job-Trigger zu erstellen (wenn Sie einen Zeitplan angegeben haben). Die Informationsseite des Job-Triggers wird angezeigt. Sie enthält Status- und andere Informationen. Wenn der Job gerade ausgeführt wird, können Sie auf die Schaltfläche Abbrechen klicken, um ihn zu stoppen. Um den Job zu löschen klicken Sie auf Löschen.
Klicken Sie in der Google Cloud Console auf den Pfeil Zurück, um zur Hauptseite zum Schutz sensibler Daten zurückzukehren.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Ein Job-Trigger wird in der DLP API durch die JobTrigger-Ressource dargestellt. Sie können einen neuen Job-Trigger mit der Methode projects.jobTriggers.create der Ressource JobTrigger erstellen.
Dieses JSON-Beispiel kann in einer POST-Anfrage an den angegebenen REST-Endpunkt für den Schutz sensibler Daten gesendet werden. In diesem Beispiel für JSON-Code wird veranschaulicht, wie in der Funktion zum Schutz sensibler Daten ein Job-Trigger erstellt wird. Der Job, den dieser Trigger auslöst, ist ein Cloud Datastore-Inspektionsscan. Der erstellte Job-Trigger wird alle 86.400 Sekunden (bzw. alle 24 Stunden) ausgeführt.
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Beachten Sie, dass eine erfolgreiche Anfrage, auch wenn sie im API Explorer erstellt wurde, einen neuen geplanten Job-Trigger erzeugt. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie im JSON-Schnellstart.
JSON-Eingabe:
{
"jobTrigger":{
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"status":"HEALTHY",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"kind":{
"name":"Example-Kind"
},
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"excludeInfoTypes":false,
"includeQuote":true,
"minLikelihood":"LIKELY"
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
}
}
}
JSON-Ausgabe:
Die folgende Ausgabe zeigt an, dass der Job-Trigger erfolgreich erstellt wurde.
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
}
Alle Jobs auflisten
So listen Sie alle Jobs für das aktuelle Projekt auf:
Console
Rufen Sie in der Google Cloud Console die Seite zum Schutz sensibler Daten auf.
Klicken Sie auf den Tab Prüfung und dann auf den Untertab Prüfjobs.
Die Console zeigt eine Liste aller Jobs für das aktuelle Projekt an, einschließlich Job-IDs, Status, Erstellungszeit und Endzeit. Sie können zu sämtlichen Jobs weitere Informationen abrufen, einschließlich einer Zusammenfassung der Ergebnisse, indem Sie auf die ID klicken.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Die Ressource DlpJob verfügt über die Methode projects.dlpJobs.list, mit der Sie alle Jobs auflisten können.
Um alle derzeit in Ihrem Projekt definierten Jobs aufzulisten, senden Sie eine GET-Anfrage an den Endpunkt dlpJobs, wie hier gezeigt:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs?key={YOUR_API_KEY}
In der folgenden JSON-Ausgabe wird einer der zurückgegebenen Jobs aufgelistet. Die Struktur des Jobs entspricht der Struktur der Ressource DlpJob.
JSON-Ausgabe:
{
"jobs":[
{
"name":"projects/[PROJECT-ID]/dlpJobs/i-5270277269264714623",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"[CLOUD-STORAGE-URL]"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"startTime":"2019-09-08T22:43:16.623Z",
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"CANADA_SOCIAL_INSURANCE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT-ID]",
"datasetId":"[DATASET-ID]",
"tableId":"[TABLE-ID]"
}
}
}
}
]
}
},
"result":{
...
}
},
"createTime":"2019-09-09T22:43:16.918Z",
"startTime":"2019-09-09T22:43:16.918Z",
"endTime":"2019-09-09T22:43:53.091Z",
"jobTriggerName":"projects/[PROJECT-ID]/jobTriggers/sample-trigger2"
},
...
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Alle Job-Trigger auflisten
So listen Sie alle Job-Trigger des aktuellen Projekts auf:
Console
Rufen Sie in der Google Cloud Console die Seite zum Schutz sensibler Daten auf.
Gehen Sie Sensitive Data Protection
Auf dem Tab Inspection (Prüfung) auf dem Untertab Job triggers (Job-Trigger) wird eine Liste aller Job-Trigger für das aktuelle Projekt angezeigt.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Die Ressource JobTrigger verfügt über eine Methode projects.jobTriggers.list, mit der Sie alle Job-Trigger auflisten können.
Senden Sie eine GET-Anfrage an den Endpunkt jobTriggers, wie im Folgenden gezeigt, um alle derzeit in Ihrem Projekt definierten Job-Trigger aufzulisten:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers?key={YOUR_API_KEY}
Die folgende JSON-Ausgabe listet den Job-Trigger auf, den wir im vorherigen Abschnitt erstellt haben. Die Struktur des Job-Triggers entspricht der Struktur der Ressource JobTrigger.
JSON-Ausgabe:
{
"jobTriggers":[
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
},
...
],
"nextPageToken":"KkwKCQjivJ2UpPreAgo_Kj1wcm9qZWN0cy92ZWx2ZXR5LXN0dWR5LTE5NjEwMS9qb2JUcmlnZ2Vycy8xNTA5NzEyOTczMDI0MDc1NzY0"
}
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Job löschen
So löschen Sie einen Job aus Ihrem Projekt, der die zugehörigen Ergebnisse enthält: Alle extern gespeicherten Ergebnisse (z. B. in BigQuery) bleiben von diesem Vorgang unberührt.
Console
Rufen Sie in der Google Cloud Console die Seite zum Schutz sensibler Daten auf.
Klicken Sie auf den Tab Prüfung und dann auf den Untertab Prüfjobs. In der Google Cloud Console wird eine Liste aller Jobs für das aktuelle Projekt angezeigt.
In der Spalte Aktionen für den Job-Trigger, den Sie löschen möchten, klicken Sie auf das Menü Weitere Aktionen Menü (drei vertikal angeordnete Punkte) und klicken Sie dann auf Löschen.
Alternativ können Sie auch in der Liste der Jobs auf die ID des zu löschenden Jobs klicken. Klicken Sie auf der Detailseite des Jobs auf Löschen.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Wenn Sie aus Ihrem aktuellen Projekt einen Job löschen möchten, senden Sie eine DELETE-Anfrage an den Endpunkt dlpJobs, wie hier gezeigt. Ersetzen Sie das Feld [JOB-IDENTIFIER] durch die ID des Jobs, die mit i- beginnt.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Wenn die Anfrage erfolgreich war, gibt die DLP API eine Erfolgsantwort zurück. Prüfen Sie dann, ob der Job erfolgreich gelöscht wurde. Listen Sie hierzu alle Jobs auf.
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Job-Trigger löschen
Console
Rufen Sie in der Google Cloud Console die Seite zum Schutz sensibler Daten auf.
Gehen Sie Sensitive Data Protection
Auf dem Tab Prüfung, im Untertab Job-Trigger, wird in der Console eine Liste aller Job-Trigger für das aktuelle Projekt angezeigt.
In der Spalte Aktionen für den Job-Trigger, den Sie löschen möchten, klicken Sie auf das Menü Weitere Aktionen Menü (drei vertikal angeordnete Punkte) und klicken Sie dann auf Löschen.
Alternativ können Sie in der Liste der Job-Trigger auf den Namen des Jobs klicken, den Sie löschen möchten. Auf der Detailseite des Job-Triggers klicken Sie dann auf Löschen.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Wenn Sie aus Ihrem aktuellen Projekt einen Job-Trigger löschen möchten, senden Sie eine DELETE-Anfrage an den Endpunkt jobTriggers, wie hier gezeigt. Ersetzen Sie dabei das Feld [JOB-TRIGGER-NAME] durch den Namen des Job-Triggers.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers/[JOB-TRIGGER-NAME]?key={YOUR_API_KEY}
Wenn die Anfrage erfolgreich war, gibt die DLP API eine Erfolgsantwort zurück. Prüfen Sie dann, ob der Job-Trigger erfolgreich gelöscht wurde. Listen Sie hierzu alle Job-Trigger auf.
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Job abrufen
So rufen Sie einen Job nebst dessen Ergebnissen aus Ihrem Projekt ab: Alle extern gespeicherten Ergebnisse (z. B. in BigQuery) bleiben von diesem Vorgang unberührt.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Senden Sie zum Abrufen eines Jobs aus dem aktuellen Projekt eine GET-Anfrage an den Endpunkt dlpJobs, wie hier gezeigt. Ersetzen Sie das Feld [JOB-IDENTIFIER] durch die ID des Jobs, die mit i- beginnt.
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Wenn die Anfrage erfolgreich war, gibt die DLP API eine Erfolgsantwort zurück.
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Sofortige Ausführung eines Job-Triggers erzwingen
Nachdem ein Job-Trigger erstellt wurde, können Sie die sofortige Ausführung des Triggers für Tests erzwingen, indem Sie ihn aktivieren. Führen Sie dazu den folgenden Befehl aus:
curl --request POST \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "X-Goog-User-Project: PROJECT_ID" \
'https://dlp.googleapis.com/v2/JOB_TRIGGER_NAME:activate'
Ersetzen Sie Folgendes:
- PROJECT_ID: die ID des Google Cloud-Projekts, für das die Zugriffskosten in Rechnung gestellt werden sollen, die mit der Anfrage verbunden sind.
- JOB_TRIGGER_NAME: der vollständige Ressourcenname des Jobtriggers, z. B.
projects/my-project/locations/global/jobTriggers/123456789.
Vorhandenen Job-Trigger aktualisieren
Sie können Job-Trigger nicht nur erstellen, auflisten und löschen, sondern auch aktualisieren. So ändern Sie die Konfiguration eines vorhandenen Job-Triggers:
Console
Rufen Sie in der Google Cloud Console die Seite zum Schutz sensibler Daten auf.
Klicken Sie auf den Tab Prüfung und dann auf den Untertab Job-Trigger.
In der Console wird eine Liste aller Job-Trigger für das aktuelle Projekt angezeigt.
Klicken Sie in der Spalte Aktionen für den Job-Trigger, den Sie löschen möchten, auf Mehr more_vert und dann auf Details ansehen.
Klicken Sie auf der Detailseite des Job-Triggers auf Bearbeiten.
Auf der Seite "Trigger bearbeiten" können Sie den Speicherort der Eingabedaten, Erkennungsdetails wie Vorlagen, infoTypes oder Wahrscheinlichkeit, alle nach dem Scan ausgeführten Aktionen und den Zeitplan des Job-Triggers ändern. Wenn Sie alle Änderungen vorgenommen haben, klicken Sie auf Speichern.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Verwenden Sie die Methode projects.jobTriggers.patch, um neue JobTrigger-Werte an die DLP API zu senden, um die betreffenden Werte innerhalb eines angegebenen Job-Triggers zu aktualisieren.
Betrachten Sie den folgenden einfachen Job-Trigger. Diese JSON-Ausgabe stellt den Job-Trigger dar und wurde zurückgegeben, nachdem eine GET-Anfrage an den Job-Trigger-Endpunkt des aktuellen Projekts gesendet wurde.
JSON-Ausgabe:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:19:45.774841Z",
"status":"HEALTHY"
}
Wenn die folgende JSON-Eingabe mit einer PATCH-Anfrage an den angegebenen Endpunkt gesendet wird, werden der zu suchende infoType und die Mindestwahrscheinlichkeit des entsprechenden Job-Triggers aktualisiert. Dabei müssen Sie auch das updateMask-Attribut angeben und sein Wert muss im FieldMask-Format vorliegen.
JSON-Eingabe:
PATCH https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]?key={YOUR_API_KEY}
{
"jobTrigger":{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY"
}
}
},
"updateMask":"inspectJob(inspectConfig(infoTypes,minLikelihood))"
}
Nachdem Sie diese JSON-Eingabe an die angegebene URL gesendet haben, wird die folgende Ausgabe zurückgegeben, die den aktualisierten Job-Trigger darstellt. Beachten Sie, dass die ursprünglichen Werte für infoType und Wahrscheinlichkeit durch die neuen Werte ersetzt wurden.
JSON-Ausgabe:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:27:01.650183Z",
"lastRunTime":"1970-01-01T00:00:00Z",
"status":"HEALTHY"
}
Um dies schnell auszuprobieren, können Sie den unten eingebetteten API Explorer verwenden. Allgemeine Informationen zum Einsatz von JSON für das Senden von Anfragen an die DLP API finden Sie in der JSON-Kurzanleitung.
Joblatenz
Für Jobs und Jobtrigger werden keine Service Level Objectives (SLOs) garantiert. Die Latenz hängt von mehreren Faktoren ab, darunter die zu scannende Datenmenge, das zu scannende Speicher-Repository, der Typ und die Anzahl der Infotypen, nach denen Sie suchen, die Region, in der der Job verarbeitet wird, und die in dieser Region verfügbaren Rechenressourcen. Daher kann die Latenz von Inspektionsjobs nicht im Voraus bestimmt werden.
Versuchen Sie Folgendes, um die Joblatenz zu reduzieren:
- Wenn Stichprobenerhebung für Ihren Job oder Job-Trigger verfügbar ist, aktivieren Sie sie.
Aktivieren Sie nicht benötigte infoTypes. Die folgenden „infoTypes“ sind in bestimmten Szenarien zwar nützlich, können aber dazu führen, dass Anfragen viel langsamer ausgeführt werden als Anfragen ohne diese „infoTypes“:
PERSON_NAMEFEMALE_NAMEMALE_NAMEFIRST_NAMELAST_NAMEDATE_OF_BIRTHLOCATIONSTREET_ADDRESSORGANIZATION_NAME
Geben Sie infoTypes immer explizit an. Verwenden Sie keine leere infoTypes-Liste.
Verwenden Sie nach Möglichkeit eine andere Verarbeitungsregion.
Wenn Sie nach dem Ausprobieren dieser Methoden weiterhin Latenzprobleme mit Jobs haben, sollten Sie anstelle von Jobs content.inspect- oder content.deidentify-Anfragen verwenden. Für diese Methoden gilt das Service Level Agreement. Weitere Informationen finden Sie in der Service Level Agreement zum Schutz sensibler Daten.
Scans ausschließlich auf neuen Inhalt beschränken
Sie können Ihren Job-Trigger so konfigurieren, dass der Zeitraum für Dateien, die in Cloud Storage oder BigQuery gespeichert sind, automatisch festgelegt wird. Wenn Sie das TimespanConfig-Objekt automatisch ausfüllen, werden vom Schutz sensibler Daten nur Daten gescannt, die seit der letzten Ausführung des Triggers hinzugefügt oder geändert wurden:
...
timespan_config {
enable_auto_population_of_timespan_config: true
}
...
Bei der BigQuery-Prüfung werden nur Zeilen, die mindestens drei Stunden alt sind, in den Scan einbezogen. Weitere Informationen finden Sie im Hilfeartikel zu bekannten Problemen.
Jobs beim Hochladen von Dateien auslösen
Zusätzlich zur Unterstützung von Job-Triggern, die in den Schutz sensibler Daten eingebunden sind, bietet Google Cloud eine Vielzahl anderer Komponenten, mit denen Sie Jobs für den Schutz sensibler Daten einbinden oder auslösen können. Beispielsweise können Sie Cloud Run-Funktionen verwenden, um bei jedem Hochladen einer Datei in Cloud Storage einen Scan für den Schutz sensibler Daten auszulösen.
Informationen zum Einrichten dieses Vorgangs finden Sie unter Klassifizierung der in Cloud Storage hochgeladenen Daten automatisieren.
Erfolgreiche Jobs ohne geprüfte Daten
Ein Job kann auch dann erfolgreich abgeschlossen werden, wenn keine Daten gescannt wurden. Die folgenden Beispielszenarien können dazu führen:
- Der Job ist so konfiguriert, dass ein bestimmtes Daten-Asset wie eine Datei geprüft wird, die vorhanden, aber leer ist.
- Der Job ist so konfiguriert, dass ein Daten-Asset geprüft wird, das nicht vorhanden ist oder nicht mehr vorhanden ist.
- Der Job ist so konfiguriert, dass ein leerer Cloud Storage-Bucket geprüft wird.
- Der Job ist für die Prüfung eines Buckets konfiguriert und die rekursive Suche ist deaktiviert. Auf der obersten Ebene enthält der Bucket nur Ordner, die wiederum die Dateien enthalten.
- Der Job ist so konfiguriert, dass nur ein bestimmter Dateityp in einem Bucket geprüft wird, der Bucket aber keine Dateien dieses Typs enthält.
- Der Job ist so konfiguriert, dass nur neue Inhalte geprüft werden. Nach der letzten Ausführung des Jobs gab es jedoch keine Aktualisierungen.
In der Google Cloud Console wird auf der Seite Jobdetails im Feld Gescannte Bytes angegeben, wie viele Daten vom Job geprüft wurden. In der DLP API gibt das Feld processedBytes an, wie viele Daten geprüft wurden.