In diesem Dokument werden die Bereitstellungs-, Cluster- und Netzwerkarchitektur der Air-Gap-Appliance von Google Distributed Cloud (GDC) beschrieben.
Bereitstellungsarchitektur
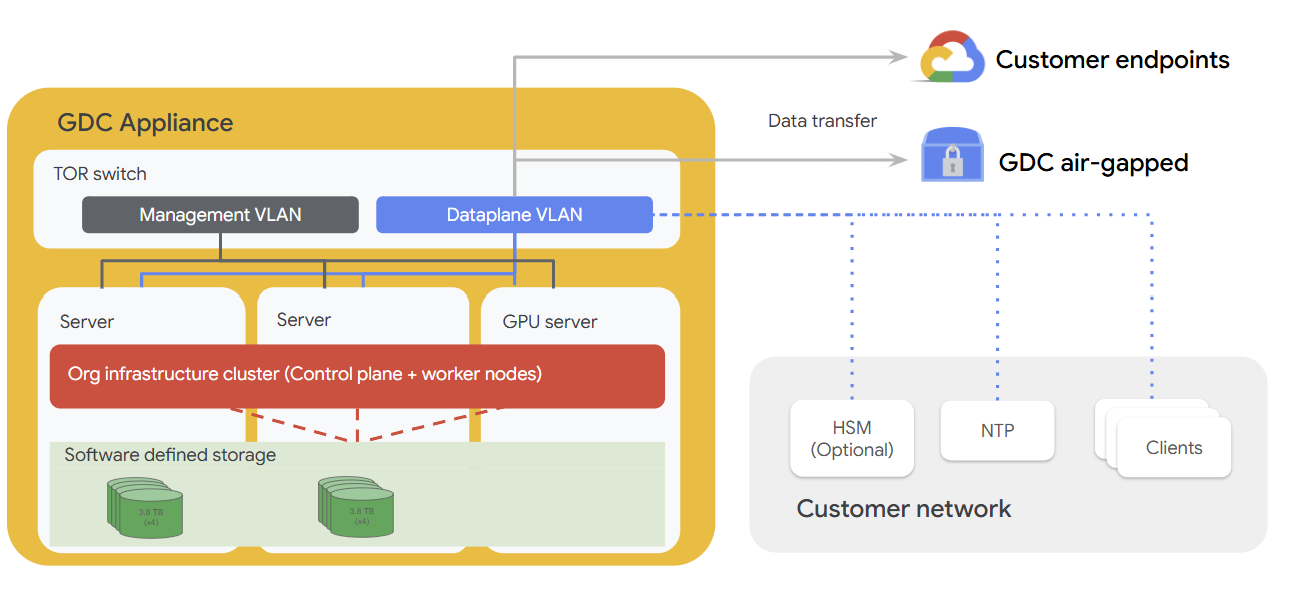
Das folgende Diagramm veranschaulicht, wie die Appliance-Hardware in ein Kundennetzwerk eingebunden wird, das optionale Komponenten wie HSMs, einen NTP-Server und zusätzliche Clients im Netzwerk umfasst. Die Appliance ist mit einer Verwaltungsebene, einer Datenebene, Servern und einem Server mit einer GPU ausgestattet, die alle für die Ausführung von Arbeitslasten direkt am Edge konzipiert sind.
Clusterarchitektur
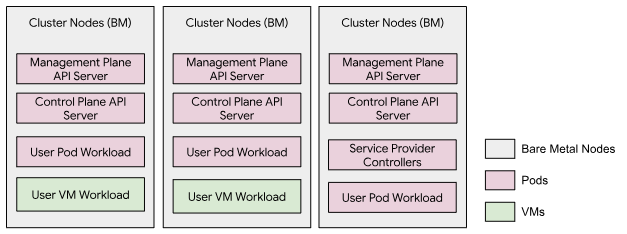
Auf der GDC Air-Gapped Appliance wird ein einzelner Cluster ausgeführt, der alle drei Bare-Metal-Knoten umfasst. Dieser Cluster wird als Organisationsinfrastrukturcluster bezeichnet. Ein dedizierter Management-API-Server, der als Pod-Arbeitslasten im Cluster ausgeführt wird, hostet Management-Ebene-APIs. Auf diesem Cluster können Nutzerarbeitslasten ausgeführt werden, darunter sowohl VMs als auch Kubernetes-Pods. Dieses Clustermodell enthält keinen Nutzercluster.
Netzwerkarchitektur
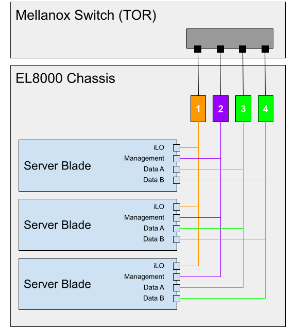
Der EL8000 enthält eine Backplane, die vier separate Layer-2-Netzwerke (L2) im Gerät erstellt:
- Integrated Lights-Out-Konsole (iLO) (1 GbE)
- Verwaltungsnetzwerk (1 GbEth)
- Datennetzwerk A (10GbEth)
- Datennetzwerk B (10GbEth)
Das folgende Diagramm zeigt, wie die L2-Netzwerke mit dem Mellanox-Switch (https://www.hpe.com/psnow/doc/a00043975enw.html?jumpid=in_pdp-psnow-qs) verbunden sind. Jedes Netzwerk in einem Blade ist mit einem einzelnen Netzwerk-Switch verbunden. Alle iLO-Konsolennetzwerke in jedem Server-Blade sind mit Netzwerk-Switch 1 verbunden. Die Verwaltungsnetzwerke sind mit Netzwerk-Switch 2 und die Datennetzwerke mit den Switches 3 und 4 verbunden.
Die Kundennetzwerkports 15 und 17 haben Zugriff auf den Cluster (VLAN 100) und nur Traffic zum Ingress-CIDR ist zulässig. Der Ingress-CIDR ist für Dienste verfügbar und der Bereich wird über das Border Gateway Protocol (BGP) im Kundennetzwerk beworben.
Die Managementnetzwerkports 16 und 18 haben Zugriff auf die Systemverwaltung (VLAN 501), sodass Kunden das Gerät in einem größeren Netzwerk verwenden und Systemverwaltungsaufgaben nur über lokale Verbindungen ausführen können.
Untergeordnete Netzwerktopologie
Physisches Netzwerk
Das GDC besteht aus einem Hybridcluster, der im Single-Tenant-Modus betrieben wird. Der Hybridcluster, den wir als Infrastrukturcluster bezeichnen, besteht aus dem System- und dem Administratorcluster, die zusammengeführt wurden:
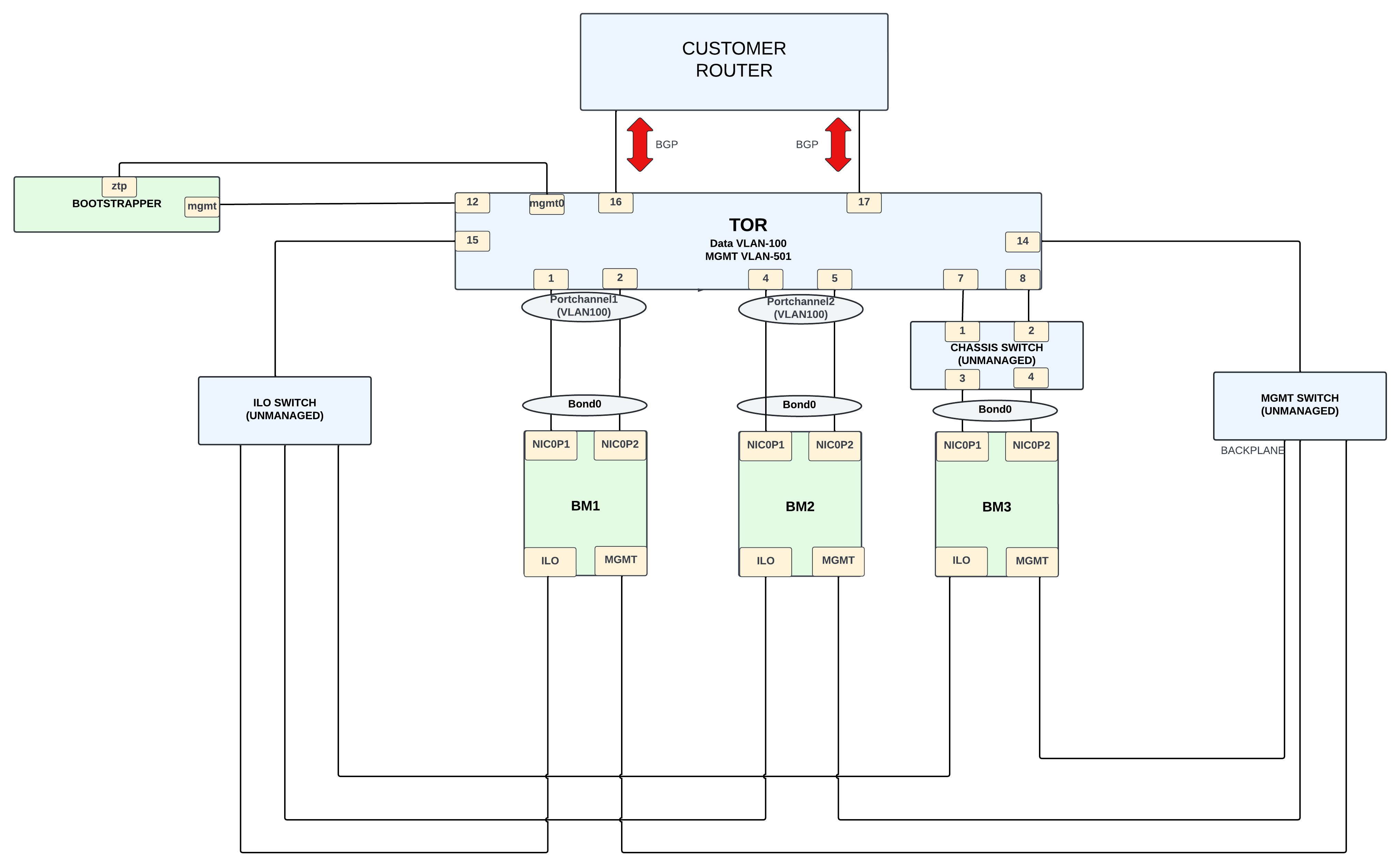
Das physische Design basiert auf einem Mellanox SN2010, der als Gateway zwischen dem Appliance Infra Cluster und dem externen Kundennetzwerk fungiert.
Der Infrastrukturcluster besteht aus drei Bare-Metal-Knoten. Die Verbindungen auf den BMs lassen sich in folgende Kategorien einteilen:
- Datennetzwerkverbindung (Subnetz 198.18.2.0/24) über VLAN 100.
Der BM hat eine NIC mit zwei Ports,
NIC0P1undNIC0P2, die gebündelt und mit dem TOR-Switch verbunden sind.BM1undBM2werden direkt mit dem Switch verbunden, währendBM3über einen nicht verwalteten Switch mit dem TOR verbunden wird. - Die Verbindung zum Verwaltungsnetzwerk ( Subnetz 198.18..0/24) erfolgt über VLAN 501. Die ILO- und MGMT-Schnittstellen sind über dieses VLAN mit 1G-Schnittstellen verbunden. Die ILO-Schnittstellen und die MGMT-Schnittstellen auf den BM-Knoten werden über nicht verwaltete Switches mit dem Switch verbunden.
- Vielleicht: OTS-Netzwerk in VLANs 200–203(?) hinzufügen, Subnetz 198.18.1.x
Die Verbindung vom Mellanox-Switch zum Kundenrouter ermöglicht eine externe Verbindung. Für diese Verbindung werden 10‑G-Schnittstellen verwendet und das BGP-Protokoll wird verwendet, um die externen Netzwerk-IPs für den Kunden anzukündigen. Kunden verwenden die externen IPs, um auf die erforderlichen Dienste zuzugreifen, die von der Appliance-Einheit bereitgestellt werden.
Logisches Netzwerk
Es gibt zwei virtuelle lokale Netzwerke (VLANs), die den verschiedenen Traffic trennen:
- VLAN 100: Cluster (Ingress-VIPs, Cluster-/Knoten-IPs) mit IPv4-Subnetz, das von Kunden bereitgestellt wird.
- VLAN 501: Verwaltung (iLO, Mgmt) mit vom Kunden bereitgestelltem IPv4-Subnetz.

Obere Netzwerktopologie
Der Cluster wird mit Layer-2-Load-Balancing (L2) konfiguriert. Die Ingress-VIPs für den Cluster stammen aus demselben Subnetz wie die Knoten. Wenn einem Knoten eine Ingress-VIP zugewiesen ist, verwendet der Knoten das Address Resolution Protocol (ARP), damit der Knoten vom TOR aus erreichbar ist.
Die TOR-Peers verwenden BGP mit dem Kundennetzwerk und bewerben den Ingress-Bereich des Clusters (aggregiertes Präfix, das vom Kunden bereitgestellt wird) im Kundennetzwerk. Wenn das Rack an einen neuen Standort verlagert wird, können wir den Ingress-Bereich des Clusters im neuen Kundennetzwerk bewerben. Wenn das Rack an einen neuen Standort verlegt wird, müssen Sie die IP-Adressen auf den TOR-Schnittstellen, die mit dem Kundennetzwerk verbunden sind, manuell aktualisieren und die BGP-Peering-Informationen aktualisieren, um die neuen BGP-Peers hinzuzufügen.
Alle vom Cluster verwendeten IPs werden entweder aus dem externalCidrBlock des Racks zugewiesen oder sind fest codiert (für clusterinterne IPs). Im folgenden Diagramm ist das externalCidrBlock-Beispiel 10.0.0.0/24:
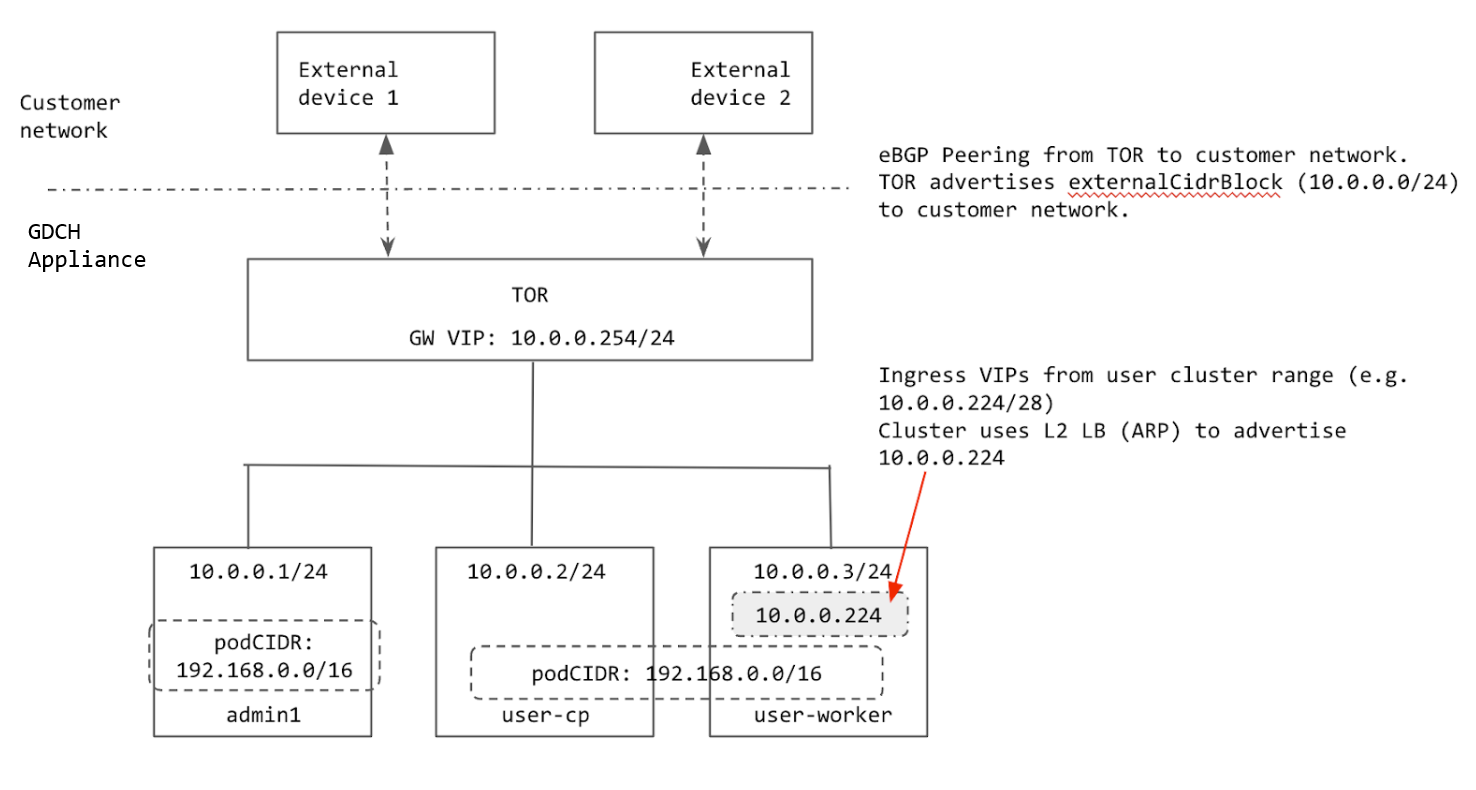
Cluster-IP-Bereiche
In einem Bare-Metal-Cluster müssen mehrere IP-Bereiche konfiguriert werden.
- Pod-CIDR: Der IP-Bereich, der zum Zuweisen von IP-Adressen an die Pods im Cluster verwendet wird. Für diesen Bereich wird der Inselmodus verwendet, sodass das physische Netzwerk (ToR) den Pod-CIDR nicht kennen muss. Die einzige Voraussetzung ist, dass sich der Bereich nicht mit Diensten überschneiden darf, auf die die Cluster-Pods zugreifen müssen. Der Pod-CIDR kann nach dem Erstellen des Clusters nicht mehr geändert werden.
- Service-CIDR: Wird für interne Clusterdienste mit derselben Anforderung wie die Pod-CIDR verwendet.
- Knoten-CIDR: IP-Adressen der Kubernetes-Clusterknoten. Diese Adressen können nach dem Erstellen des Clusters nicht mehr geändert werden.
- Eingehender Traffic-Bereich: Ein Bereich von IP-Adressen, der für alle Dienste im Cluster verwendet wird, die extern verfügbar sind. Externe Clients verwenden diese IPs, um auf Dienste im Cluster zuzugreifen. Dieser Bereich muss im Kundennetzwerk beworben werden, damit Clients die Ingress-IPs erreichen können.
- VIP der Steuerungsebene: Wird vom Cluster für den Zugriff auf die Kubernetes-
api-serverbeworben (ähnlich wie die Ingress-VIPs). Diese VIP muss aus demselben Subnetz wie der Knoten stammen, wenn sich der Cluster im L2-Load-Balancing-Modus befindet.
Die Pod-CIDR und die Dienst-CIDRs für die Cluster sind fest codiert.
Die Pod-CIDR ist 192.168.0.0/16 und die Dienst-CIDR ist 10.96.0.0/12. Der Cluster verwendet dieselben beiden CIDRs, da diese IPs nicht außerhalb des Clusters verfügbar gemacht werden.
Die Knoten werden mit IP-Adressen aus dem externalCidrBlock bereitgestellt, das in der GDC cell.yaml festgelegt ist. Diese IP-Adressen werden vom Kunden bereitgestellt, bevor das Rack bereitgestellt wird.
Der Ingress-Bereich und die VIP der Steuerungsebene für den Cluster werden ebenfalls aus externalCidrBlock zugewiesen. Der TOR muss die externalCidrBlock im Kundennetzwerk bewerben, damit diese VIPs für Clients außerhalb des Racks zugänglich sind.