En esta página se explica cómo solucionar problemas de inaccesibilidad de los dispositivos después del bootstrapping. Puede que te encuentres con los siguientes problemas:
- Mensajes de error como
Unable to connect to the server: dial tcp 198.18.0.64:443: i/o timeoutal intentar hacer una consulta con kubectl. - Error
Webpage not availableal intentar acceder a la interfaz de usuario. - Las aplicaciones implementadas en el dispositivo no funcionan o no puedes implementar ninguna aplicación nueva.
Solucionar problemas de inaccesibilidad de la interfaz de usuario
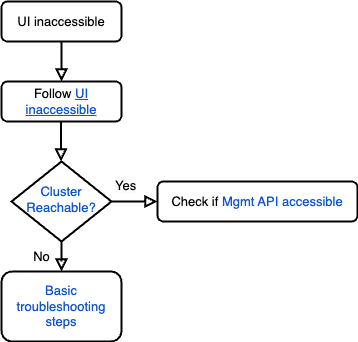
- Sigue el runbook Interfaz de usuario inaccesible para solucionar el problema.
- Para comprobar si se puede acceder al clúster, consulta la sección Accesibilidad del clúster.
- Si el clúster responde, comprueba si se puede acceder a la API Management siguiendo las instrucciones de la sección Se puede acceder a la API Management.
- Si no se puede acceder al clúster y devuelve errores como
Connection timed outoi/o timeout error, consulta la guía de solución de problemas para ver más pasos.
Pasos básicos para solucionar incidencias

Verifica la fuente de alimentación del chasis comprobando si las luces indicadoras (verdes) de cualquiera de las dos fuentes de alimentación están encendidas, tal como se indica con las flechas de la imagen.
Estado de la luz LED Descripción Verde fijo Sistema activado y funcionamiento normal Verde parpadeante Hay alimentación de reserva (fuente de alimentación apagada) Ámbar macizo Fallo de la fuente de alimentación (sobretensión, subtensión, sobretemperatura, sobrecorriente o cortocircuito), fallo del ventilador o protección contra sobretensión de entrada Ámbar intermitente Error de la fuente de alimentación Desactivado No hay corriente o la corriente de espera ha fallado (sobretensión, subtensión, sobretemperatura, sobrecorriente, cortocircuito, bloqueo del ventilador) Si las luces indicadoras están apagadas, primero asegúrate de que el cable de alimentación recibe corriente. Si el cable de alimentación funciona correctamente, es probable que las fuentes de alimentación estén defectuosas y deban sustituirse. Para obtener instrucciones sobre cómo sustituirla, consulta la guía de sustitución de la fuente de alimentación.
Si las fuentes de alimentación funcionan, pero el dispositivo sigue sin funcionar, comprueba si hay conexiones sueltas o dañadas.
Comprueba que los LEDs del conmutador y los servidores estén iluminados como indican las flechas de la imagen.
Si el LED de enlace del interruptor es de color verde fijo, comprueba que funciona siguiendo las instrucciones de la sección Verificar que el interruptor funciona.
Si el estado y la configuración del conmutador son correctos, inicia sesión en iLO siguiendo los pasos que se indican en Pasos para iniciar sesión en iLO para comprobar el estado del dispositivo.
- Si alguno de los ventiladores es crítico, póngase en contacto con el equipo de asistencia de HPE para obtener un ventilador de sustitución y siga la guía de sustitución de ventiladores para cambiarlo.
- Si alguna cuchilla está apagada, enciéndela. Para ello, ve a la sección Cuchillas, selecciona la cuchilla y pulsa el botón de encendido.
- Si alguna de las cuchillas está en un estado crítico, vaya a la sección Cuchillas, seleccione la cuchilla crítica, vaya a la sección Alimentación e inicie un restablecimiento forzado del sistema.
- Si el estado del chasis es crítico, también puedes probar a restablecerlo. Para ello, ve a la pestaña Alimentación y temperatura. Selecciona la sección Gestión de energía y haz clic en Restablecer botón EL8000CM. Este proceso restablece el firmware del gestor del chasis y puede tardar unos minutos, durante los cuales el chasis no estará disponible.
- Si el problema persiste, vaya a la pestaña Información, seleccione Registros, elija Registros de estado en el menú desplegable y descárguelos como archivo CSV. Abre una incidencia con Google y adjunta los registros para solicitar la sustitución del hardware.
Si los LEDs de encendido de las cuchillas están iluminados, realiza una prueba de ping a las siguientes direcciones IP de las cuchillas desde un equipo conectado al dispositivo:
ping 198.18.0.7 //BM01 ping 198.18.0.8 //BM02 ping 198.18.0.9 //BM03Si la prueba de ping se realiza correctamente, significa que los nodos funcionan.
Si todos los nodos fallan en la prueba de ping, deriva el caso al equipo de Asistencia de Google.
Si el problema persiste después de seguir todos los pasos descritos en esta sección, deriva el caso al equipo de Asistencia de Google para obtener más ayuda.
Conexiones sueltas o dañadas
Comprueba que todas las conexiones estén bien conectadas. Para obtener información sobre cómo comprobar y asegurar las conexiones de los cables dentro del aparato, consulta la sección Comprobar los cables.
Comprueba que los cables no presenten daños visibles. Si algún cable está dañado, sustitúyelo.
Verificar que el interruptor funciona
Inicia sesión en la consola serie del switch. Si el inicio de sesión se realiza correctamente, ejecuta el siguiente comando para comprobar el estado del conmutador. Este comando muestra el tiempo de actividad y el consumo de recursos del interruptor.
show versionSi la consola serie responde, valida la configuración de BGP en el conmutador consultando Validar resumen de BGP.
Si el LED de enlace está apagado o la consola serie no responde, es posible que el interruptor esté defectuoso. Deriva el problema al equipo de Asistencia de Google para solicitar una sustitución.
Verificar la accesibilidad del clúster
Inicia sesión en la sesión de gdcloud con las credenciales de IO:
gdcloud auth loginSi no puedes iniciar sesión, busca la credencial de emergencia de la que se hizo una copia de seguridad durante la configuración del dispositivo para usarla con el comando -: root-admin-kubeconfig.
Comprueba si se puede acceder al clúster:
kubectl --kubeconfig root-admin-kubeconfig get servers -A
Verificar la accesibilidad de la API Management
Inicia sesión en la sesión de gdcloud con las credenciales de IO:
gdcloud auth loginSi no puedes iniciar sesión, hazlo con las credenciales del plano de gestión.
A veces, la base de datos del SIA puede fallar o estar mal configurada, lo que provoca un error al iniciar sesión. Consulta IAM-R0009 - Base de datos del SIA.
Si no puedes resolver los problemas de inicio de sesión, busca la credencial de emergencia de la que se hizo una copia de seguridad durante la configuración del dispositivo para usarla con el comando -: root-admin-kubeconfig.
Obtén el archivo kubeconfig del plano de gestión:
kubectl --kubeconfig root-admin-kubeconfig -n management-kube-system get secret kube-admin-remote-kubeconfig -ojsonpath='{.data.value}' | base64 -d > kube-admin-remote-kubeconfigObtén el estado de salud del clúster:
kubectl --kubeconfig kube-admin-remote-kubeconfig get --raw='/readyz?verbose'