Nachdem Sie Benachrichtigungsregeln in Ihrem Google Distributed Cloud-Projekt (GDC) für Air-Gap-Appliances erstellt haben, können Sie Benachrichtigungen in Dashboards abfragen und ansehen über die Benutzeroberfläche der Systemmonitoring-Instanz des Projekts oder Benachrichtigungen über die GDC Observability HTTP API abfragen.
Benachrichtigungen in Dashboards abfragen und ansehen
Sie können sich Benachrichtigungen in Dashboards in der
Systemmonitoring-Instanz des Projekts platform-obs.
Die Systemüberwachungsinstanz umfasst Messwerte, Logs und Benachrichtigungen auf Projektebene, um Überwachungsprozesse wie Netzwerk- und Serverüberwachung durchzuführen.
Hinweise
Bevor Sie Benachrichtigungen in Dashboards abfragen und ansehen können, müssen Sie Zugriff auf die Instanz zur Systemüberwachung erhalten. Weitere Informationen finden Sie unter Zugriff auf Dashboards erhalten.
Bitten Sie Ihren Projekt-IAM-Administrator, Ihnen die Rolle „Projekt-Grafana-Betrachter“ (project-grafana-viewer) zuzuweisen, damit Sie sich anmelden und Benachrichtigungen visualisieren können. Mit diesem rollenbasierten Verfahren zur Zugriffssteuerung können Sie sicher auf Datenvisualisierungen zugreifen.
Instanzendpunkt für das Systemmonitoring
Für Application Operator (AO):
Öffnen Sie die folgende URL, um auf den Endpunkt Ihres Projekts zuzugreifen:
https://GDC_URL/PROJECT_NAMESPACE/grafana
Ersetzen Sie Folgendes:
- GDC_URL: Die URL Ihrer Organisation in GDC.
- PROJECT_NAMESPACE: Der Namespace Ihres Projekts.
Die Benutzeroberfläche des Projekts enthält Standarddashboards wie das Dashboard Benachrichtigungen – Übersicht mit Informationen zu Benachrichtigungen. Wenn Sie Benachrichtigungen über die Benutzeroberfläche abfragen, können Sie Benachrichtigungsinformationen aus Ihrem Projekt visuell abrufen und erhalten eine integrierte Ansicht der Ressourcen, um Probleme zu erkennen und schnell zu beheben.
Für Plattformadministratoren:
Öffnen Sie die folgende URL, um auf den Endpunkt Ihres platform-obs-Projekts zuzugreifen:
https://GDC_URL/platform-obs/grafana
Ersetzen Sie GDC_URL durch die URL Ihrer Organisation in GDC.
Die Benutzeroberfläche der Systemüberwachungsinstanz enthält Standarddashboards wie das Dashboard Benachrichtigungen – Übersicht mit Informationen zu Benachrichtigungen für die Datenbeobachtbarkeit. Wenn Sie Benachrichtigungen über die Benutzeroberfläche abfragen, können Sie Benachrichtigungsinformationen aus Ihrem Projekt visuell abrufen und erhalten eine integrierte Ansicht der Ressourcen, um Probleme zu erkennen und schnell zu beheben.

Abbildung 1. Das Dashboard Alerts – Overview (Benachrichtigungen – Übersicht) in der Grafana-Benutzeroberfläche.
Alertmanager
Mit Alertmanager können Sie Benachrichtigungen von Clientanwendungen überwachen. Sie können Benachrichtigungen mit Alertmanager prüfen und stummschalten sowie filtern oder gruppieren:
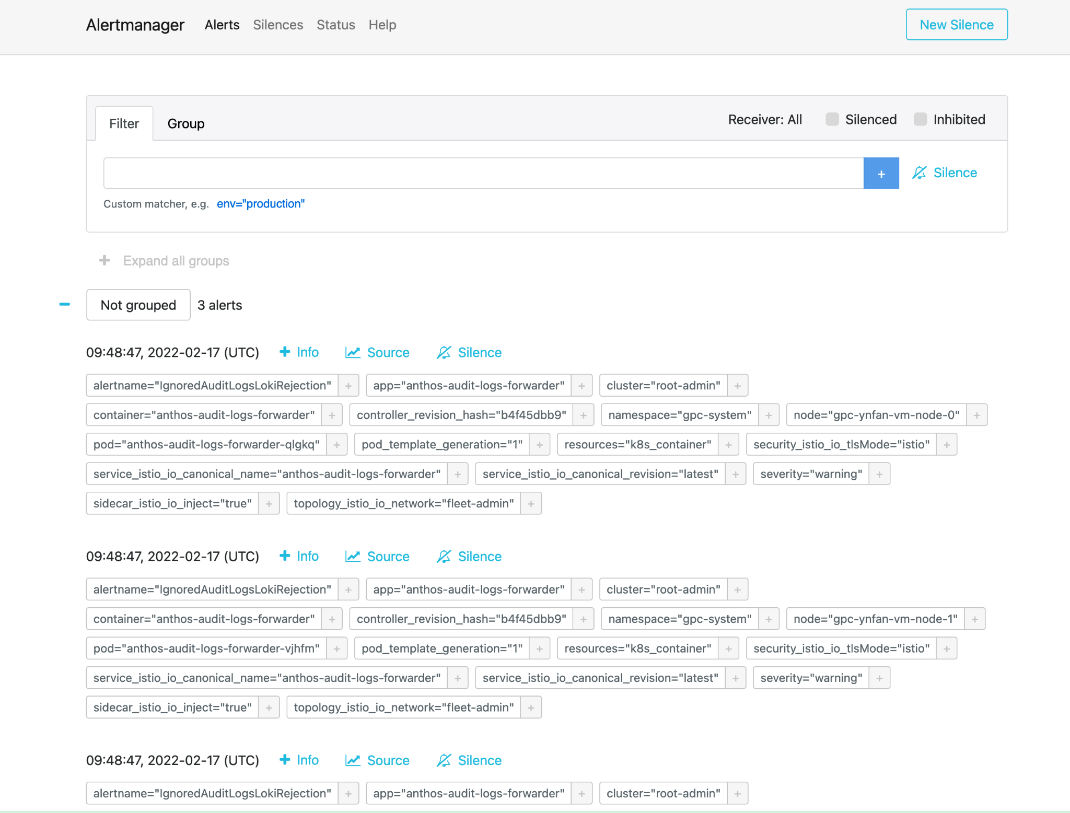
Abbildung 2. Menüoption zum Abfragen von Audit-Logs aus dem Alertmanager.
Vordefinierte Benachrichtigungsrichtlinien
In der folgenden Tabelle sind die vorinstallierten Benachrichtigungsregeln in Prometheus aufgeführt:
| Name | Beschreibung |
|---|---|
| KubeAPIDown (kritisch) | KubeAPI ist seit 15 Minuten nicht mehr in der Prometheus-Zielerkennung enthalten. |
| KubeClientErrors (Warnung) | Fehlerrate der Kubernetes API-Serverfehler > 0,01 für 15 Minuten |
| KubeClientErrors (kritisch) | Fehlerrate der Kubernetes API-Serverfehler > 0,1 für 15 Minuten |
| KubePodCrashLooping (Warnung) | Der Pod befindet sich seit mehr als 15 Minuten im Absturzstatus. |
| KubePodNotReady (Warnung) | Der Pod ist seit mehr als 15 Minuten nicht bereit. |
| KubePersistentVolumeFillingUp (kritisch) | Kostenlose Byte eines beanspruchten PersistentVolumes < 0,03. |
| KubePersistentVolumeFillingUp (Warnung) | Kostenlose Byte eines beanspruchten PersistentVolumes < 0,15. |
| KubePersistentVolumeErrors (kritisch) | Das nichtflüchtige Volume ist fünf Minuten lang in der Phase „Fehlgeschlagen“ oder „Ausstehend“. |
| KubeNodeNotReady (Warnung) | Der Knoten ist seit mehr als 15 Minuten nicht mehr bereit. |
| KubeNodeCPUUsageHigh (kritisch) | Die CPU-Auslastung des Knotens beträgt > 80%. |
| KubeNodeMemoryUsageHigh (kritisch) | Die Speichernutzung des Knotens beträgt > 80 %. |
| NodeFilesystemSpaceFillingUp (Warnung) | Die Nutzung des Knotendateisystems beträgt über 60%. |
| NodeFilesystemSpaceFillingUp (kritisch) | Die Nutzung des Knotendateisystems beträgt mehr als 85%. |
| CertManagerCertExpirySoon (Warnung) | Ein Zertifikat läuft in 21 Tagen ab. |
| CertManagerCertNotReady (kritisch) | Ein Zertifikat kann nach 10 Minuten noch nicht für die Bereitstellung von Traffic verwendet werden. |
| CertManagerHittingRateLimits (kritisch) | Eine Ratenbegrenzung wurde erreicht, nachdem fünf Minuten lang Zertifikate erstellt und verlängert wurden. |
| DeploymentNotReady (kritisch). | Ein Deployment im Administratorcluster der Organisation ist seit mehr als 15 Minuten nicht bereit. |
Beispiel für AlertmanagerConfigurationConfigmaps
Die Syntax von Konfigurationen in ConfigMaps, die in alertmanagerConfigurationConfigmaps aufgeführt sind, muss https://prometheus.io/docs/alerting/latest/configuration/ entsprechen.
apiVersion: observability.gdc.goog/v1alpha1
kind: ObservabilityPipeline
metadata:
# Choose namespace that matches the project's namespace
namespace: kube-system
name: observability-config
# Configure Alertmanager
alerting:
# Storage size for alerting data within organization
# Permission: PA
localStorageSize: 1Gi
# Permission: PA & AO
# alertmanager config must be under the key "alertmanager.yml" in the configMap
alertmanagerConfig: <configmap-for-alertmanager-config>
# Permission: PA
volumes:
- <volume referenced in volumeMounts>
# Permission: PA
volumeMounts:
- <volumeMount referenced in alertmanagerConfig>
Beispielkonfiguration für Regeln
# Configures either an alert or a target record for precomputation
apiVersion: monitoring.gdc.goog/v1alpha1
kind: MonitoringRule
metadata:
# Choose namespace that contains the metrics that rules are based on
# Note: alert/record will be produced in the same namespace
namespace: g-fleetns-a
name: alerting-config
spec:
# Rule evaluation interval
interval: <duration>
# Configure limit for number of alerts (0: no limit)
# Optional, Default: 0 (no limit)
limit: <int>
# Configure record rules
recordRules:
# Define which timeseries to write to (must be a valid metric name)
- record: <string>
# Define PromQL expression to evaluate for this rule
expr: <string>
# Define labels to add or overwrite
# Optional, Map of {key, value} pairs
labels:
<labelname>: <labelvalue>
# Configure alert rules
alertRules:
# Define alert name
- alert: <string>
# Define PromQL expression to evaluate for this rule
# https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
expr: <string>
# Define when an active alert moves from pending to firing
# Optional, Default: 0s
for: <duration>
# Define labels to add or overwrite
# Required, Map of {key, value} pairs
# Required labels:
# severity: [error, critical, warning, info]
# code:
# resource: component/service/hardware related to alert
# additional labels are optional
labels:
severity: <enum: [error, critical, warning, info]>
code:
resource: <Short name of the related operable component>
<labelname>: <tmpl_string>
# Define annotations to add
# Optional, Map of {key, value} pairs
# Recommended annotations:
# message: value of Message field in UI
# expression: value of Rule field in UI
# runbookurl: URL for link in Actions to take field in UI
annotations:
<labelname>: <tmpl_string>
# Configures either an alert or a target record for precomputation
apiVersion: logging.gdc.goog/v1alpha1
kind: LoggingRule
metadata:
# Choose namespace that contains the logs that rules are based on
# Note: alert/record will be produced in the same namespace
namespace: g-fleetns-a
name: alerting-config
spec:
# Choose which log source to base alerts on (Operational/Audit/Security Logs)
# Optional, Default: Operational
source: <string>
# Rule evaluation interval
interval: <duration>
# Configure limit for number of alerts (0: no limit)
# Optional, Default: 0 (no limit)
limit: <int>
# Configure record rules
recordRules:
# Define which timeseries to write to (must be a valid metric name)
- record: <string>
# Define LogQL expression to evaluate for this rule
# https://grafana.com/docs/loki/latest/rules/
expr: <string>
# Define labels to add or overwrite
# Optional, Map of {key, value} pairs
labels:
<labelname>: <labelvalue>
# Configure alert rules
alertRules:
# Define alert name
- alert: <string>
# Define LogQL expression to evaluate for this rule
expr: <string>
# Define when an active alert moves from pending to firing
# Optional, Default: 0s
for: <duration>
# Define labels to add or overwrite
# Required, Map of {key, value} pairs
# Required labels:
# severity: [error, critical, warning, info]
# code:
# resource: component/service/hardware related to alert
# additional labels are optional
labels:
severity: <enum: [error, critical, warning, info]>
code:
resource: <Short name of the related operable component>
<labelname>: <tmpl_string>
# Define annotations to add
# Optional, Map of {key, value} pairs
# Recommended annotations:
# message: value of Message field in UI
# expression: value of Rule field in UI
# runbookurl: URL for link in Actions to take field in UI
annotations:
<labelname>: <tmpl_string>
Benachrichtigungen über die HTTP API abfragen
Die Observability-Plattform stellt einen HTTP-API-Endpunkt zum Abfragen und Lesen von Messwerten, Benachrichtigungen und anderen Zeitachsendaten aus Ihrem Projekt für die Systemüberwachung bereit.Sie können Abfragebenachrichtigungen direkt über die Observability HTTP API abrufen, um automatisierte Aufgaben einzurichten, Antworten anzupassen und Integrationen entsprechend Ihrem Anwendungsfall zu erstellen. Sie können die Ausgabe beispielsweise in einen anderen Befehl einfügen, Details in Textdateiformate exportieren oder einen Linux-Cronjob konfigurieren. Sie können die Observability HTTP API über die Befehlszeilenschnittstelle (CLI) oder einen Webbrowser aufrufen und das Ergebnis im JSON-Format abrufen.
In diesem Abschnitt wird erläutert, wie Sie den Observability HTTP API-Endpunkt über die CLI aufrufen, um mithilfe derAPI-Spezifikation Benachrichtigungen abzufragen.
Sie können Abfragebenachrichtigungen direkt über die Observability HTTP API abrufen, um automatisierte Aufgaben einzurichten, Antworten anzupassen und Integrationen entsprechend Ihrem Anwendungsfall zu erstellen. Sie können die Ausgabe beispielsweise in einen anderen Befehl einfügen, Details in Textdateiformate exportieren oder einen Linux-Cronjob konfigurieren. Sie können die Observability HTTP API über die Befehlszeilenschnittstelle (CLI) oder einen Webbrowser aufrufen und das Ergebnis im JSON-Format abrufen.
In diesem Abschnitt wird beschrieben, wie Sie den Observability HTTP API-Endpunkt über die CLI aufrufen, um Messwerte abzufragen. Dazu verwenden Sie die Alertmanager API-Spezifikation.
Hinweise
Bitten Sie Ihren Projekt-IAM-Administrator, Ihnen die Rolle „Project Cortex Alertmanager Viewer“ (project-cortex-alertmanager-viewer) in Ihrem Projektnamespace zuzuweisen, um die Berechtigungen zu erhalten, die Sie für den Zugriff auf den Observability HTTP API-Endpunkt benötigen.
Der Projekt-IAM-Administrator kann Ihnen Zugriff gewähren, indem er eine Rollenbindung erstellt:
a. Infrastructure Operator (IO) Root-Admin – Project Cortex Alertmanager Viewer:
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
io-cortex-alertmanager-viewer-binding -n infra-obs
--user=fop-infrastructure-operator@example.com
--role=project-cortex-alertmanager-viewer
b. Plattformadministrator (PA) – Root-Administrator – Project Cortex Alertmanager Viewer:
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
pa-cortex-alertmanager-viewer-binding -n platform-obs
--user=fop-platform-admin@example.com
--role=project-cortex-alertmanager-viewer
c. Application Operator (AO) Root-Admin – Project Cortex Alertmanager Viewer: Projekt: $AO_PROJECT AO-Nutzername: $AO_USER
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
project-cortex-alertmanager-viewer-binding -n $AO_PROJECT
--user=$AO_USER
--role=project-cortex-alertmanager-viewer
Nachdem die Rollenbindung erstellt wurde, können Sie mit Ihrem Anmeldenamen auf den entsprechenden Alertmanager zugreifen.
Rollenbindung prüfen
kubectl --kubeconfig $HOME/org-1-admin-kubeconfig get rolebinding -n platform-obs
Informationen zum Festlegen von Rollenbindungen über die GDC-Konsole finden Sie unter Zugriff auf Ressourcen gewähren.
Cortex-Endpunkt
Die folgende URL ist der Cortex-Endpunkt für den Zugriff auf Benachrichtigungen:
https://GDC_URL/PROJECT_NAME/cortex/alertmanager/
Ersetzen Sie Folgendes:
- GDC_URL: Die URL Ihrer Organisation in GDC.
- PROJECT_NAME ist der Name Ihres Projekts.
API-Endpunkt aufrufen
So greifen Sie über die CLI auf den Cortex API-Endpunkt zu und fragen Benachrichtigungen ab:
- Prüfen Sie, ob Sie die Voraussetzungen erfüllen.
- Öffnen Sie die Befehlszeilenschnittstelle.
Verwenden Sie das Tool
curl, um die Cortex-Endpunkt-URL aufzurufen und die URL mit dem Standard https://prometheus.io/docs/prometheus/latest/querying/api/#alertmanagers zu erweitern, um Benachrichtigungen abzufragen. Beispiel:curl https://console.org-1.zone1.google.gdch.test/alice/cortex/alertmanager/api/v1/alertmanagers
Die Ausgabe wird in der CLI nach dem Befehl angezeigt. Das API-Antwortformat ist JSON.