O Datastream aceita streaming de dados dos bancos de dados Oracle, MySQL e PostgreSQL diretamente para os conjuntos de dados do BigQuery. No entanto, se você precisar de mais controle sobre a lógica de processamento de fluxo, como transformação de dados ou configuração manual de chaves primárias lógicas, é possível integrar o Datastream aos modelos de jobs do Dataflow.
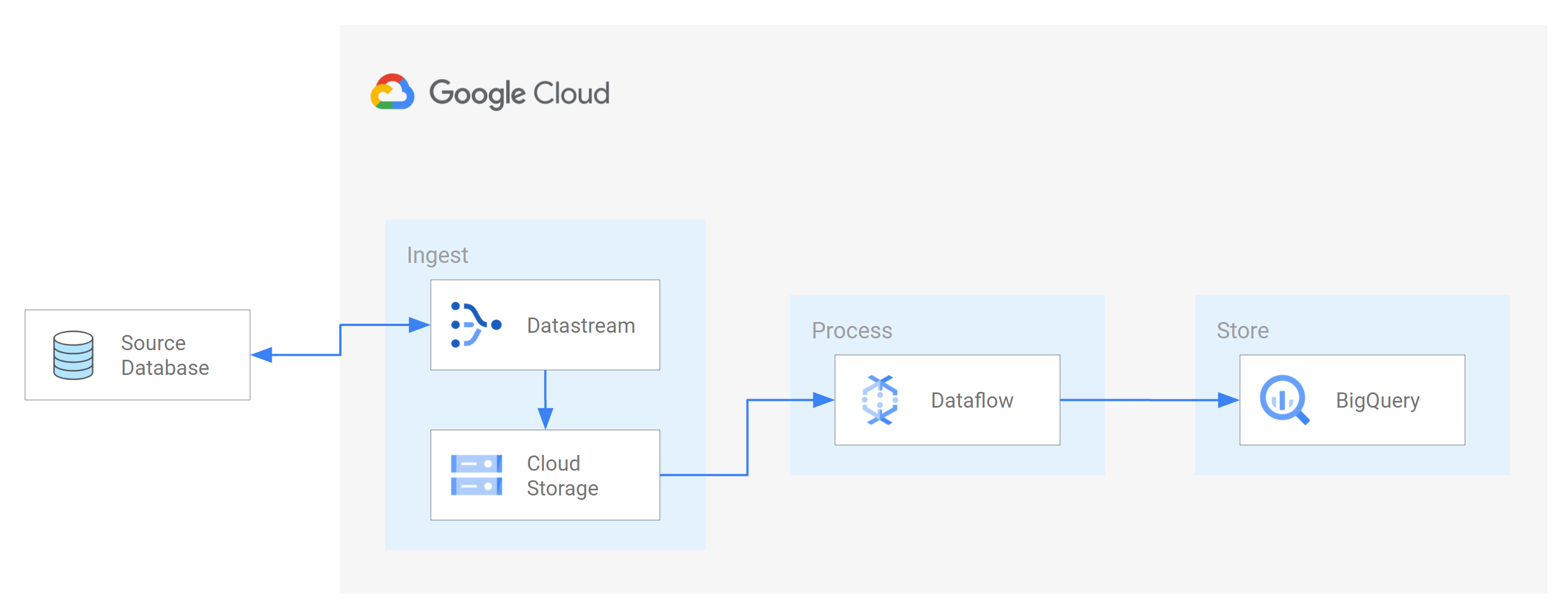
Neste tutorial, mostramos como o Datastream se integra ao Dataflow usando modelos de job do Dataflow para fazer streaming de visualizações materializadas atualizadas no BigQuery para análise.
Para organizações com muitas fontes de dados isoladas, o acesso aos dados corporativos em toda a organização, principalmente em tempo real, pode ser limitado e lento. Isso restringe a capacidade da organização de introspecção.
O Datastream fornece acesso quase em tempo real para alterar dados de várias fontes de dados locais e baseadas na nuvem. O Datastream oferece uma experiência de configuração em que você não precisa configurar muito os dados de streaming. O Datastream faz isso por você. O Datastream também tem uma API de consumo unificado que democratiza o acesso da sua organização aos dados corporativos mais recentes disponíveis para criar cenários integrados.
Um desses cenários é a transferência de dados de um banco de dados de origem para um serviço de armazenamento baseado em nuvem ou fila de mensagens. Depois que o Datastream transmite os dados, eles são transformados em um formato que outros aplicativos e serviços podem ler. Neste tutorial, o Dataflow é o serviço da Web que se comunica com o serviço de armazenamento ou a fila de mensagens para capturar e processar dados no Google Cloud.
Você vai aprender a usar o Datastream para transmitir alterações (dados inseridos, atualizados ou excluídos) de um banco de dados MySQL de origem para uma pasta em um bucket do Cloud Storage. Em seguida, você vai configurar o bucket do Cloud Storage para enviar notificações que o Dataflow usa para aprender sobre novos arquivos que contenham alterações de dados que o Datastream transmite do banco de dados de origem. Depois, um job do Dataflow processa os arquivos e transfere as alterações para o BigQuery.
Objetivos
Neste tutorial, você aprenderá a:- Criar um bucket no Cloud Storage. Esse é o bucket de destino para onde o Datastream transmite esquemas, tabelas e dados de um banco de dados MySQL de origem.
- Ative as notificações do Pub/Sub para o bucket do Cloud Storage. Ao fazer isso, você configura o bucket para enviar notificações que o Dataflow usa para aprender sobre novos arquivos prontos para processamento. Esses arquivos contêm alterações nos dados que o Datastream transmite do banco de dados de origem para o bucket.
- Crie conjuntos de dados no BigQuery. O BigQuery usa conjuntos de dados para conter os dados recebidos do Dataflow. Esses dados representam as alterações no banco de dados de origem que o Datastream transmite para o bucket do Cloud Storage.
- Crie e gerencie perfis de conexão para um banco de dados de origem e um bucket de destino no Cloud Storage. Um fluxo no Datastream usa as informações dos perfis de conexão para transferir dados do banco de dados de origem para o bucket.
- Criar e iniciar um stream. Esse stream transfere dados, esquemas e tabelas do banco de dados de origem para o bucket.
- Verifique se o Datastream transfere os dados e as tabelas associados a um esquema do banco de dados de origem para o bucket.
- Crie um job no Dataflow. Depois que o Datastream faz streaming das alterações de dados do banco de dados de origem para o bucket do Cloud Storage, o Dataflow envia notificações sobre novos arquivos que contêm as alterações. O job do Dataflow processa os arquivos e transfere as alterações para o BigQuery.
- Verifique se o Dataflow processa os arquivos que contêm as alterações associadas a esses dados e transfere as alterações para o BigQuery. Como resultado, você tem uma integração completa entre o Datastream e o BigQuery.
- Limpe os recursos criados no Datastream, Cloud Storage, Pub/Sub, Dataflow e BigQuery para que eles não ocupem cota e você não receba cobranças por eles no futuro.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Datastream
- Cloud Storage
- Pub/Sub
- Dataflow
- BigQuery
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Ative a API Datastream.
- Verifique se você tem o papel de administrador do Datastream atribuído à sua conta de usuário.
- Verifique se você tem um banco de dados MySQL de origem que o Datastream possa acessar. Além disso, verifique se você tem dados, tabelas e esquemas no banco de dados.
- Configure seu banco de dados MySQL para permitir conexões de entrada de endereços IP públicos do Datastream. Para conferir uma lista de todas as regiões do Datastream e os endereços IP públicos associados, consulte Regiões e listas de permissões de IP.
- Configure a captura de dados de alteração (CDC, na sigla em inglês) do banco de dados de origem. Para mais informações, consulte Configurar um banco de dados MySQL de origem.
Verifique se você atende a todos os pré-requisitos para ativar as notificações do Pub/Sub para Cloud Storage.
Neste tutorial, você vai criar um bucket de destino no Cloud Storage e ativar as notificações do Pub/Sub para o bucket. Ao fazer isso, o Dataflow pode receber notificações sobre novos arquivos que o Datastream grava no bucket. Esses arquivos contêm alterações nos dados que o Datastream transmite do banco de dados de origem para o bucket.
Requisitos
O Datastream oferece várias opções de origem, opções de destino e métodos de conectividade de rede.
Neste tutorial, presumimos que você esteja usando um banco de dados MySQL independente e um serviço de destino do Cloud Storage. Para o banco de dados de origem, configure a rede para adicionar uma regra de firewall de entrada. O banco de dados de origem pode ser local ou em um provedor de nuvem. Para o destino do Cloud Storage, não é necessária nenhuma configuração de conectividade.
Como não sabemos as especificidades do seu ambiente, não podemos fornecer etapas detalhadas sobre a configuração de rede.
Neste tutorial, você seleciona Lista de permissões de IP como o método de conectividade de rede. As listas de permissões de IP são um recurso de segurança usado com frequência para limitar e controlar o acesso de usuários confiáveis ao seu banco de dados de origem. É possível usar listas de permissões de IP para criar listas de endereços IP ou intervalos de IP confiáveis. Esses usuários e outros serviços do Google Cloud, como o Datastream, podem acessar esses dados. Para usar as listas de permissões de IP, você precisa abrir o banco de dados ou o firewall de origem para conexões de entrada do Datastream.
Criar um bucket no Cloud Storage
Criar um bucket de destino no Cloud Storage para onde o Datastream transmite esquemas, tabelas e dados de um banco de dados MySQL de origem.
No console do Google Cloud, acesse a página Navegador do Cloud Storage.
Clique em Criar bucket. A página Criar um bucket é exibida.
No campo de texto da região Nomeie seu bucket, insira um nome exclusivo para seu bucket e, em seguida, clique em Continuar.
Aceite as configurações padrão para cada região restante da página. No final de cada região, clique em Continuar.
Clique em Criar.
Ative as notificações do Pub/Sub para o bucket do Cloud Storage
Nesta seção, você ativa as notificações do Pub/Sub para o bucket do Cloud Storage criado. Ao fazer isso, você configura o bucket para notificar o Dataflow sobre novos arquivos que o Datastream grava no bucket. Esses arquivos contêm alterações nos dados que o Datastream transmite de um banco de dados MySQL de origem para o bucket.
Acesse o bucket do Cloud Storage criado. A página Detalhes do bucket é exibida.
Clique em Ativar o Cloud Shell.
No prompt, insira o seguinte comando:
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/Opcional: se a janela Autorizar o Cloud Shell for exibida, clique em Autorizar.
Verifique se as seguintes linhas de código são exibidas:
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
No console do Google Cloud, acesse a página Tópicos do Pub/Sub.
Clique no tópico my_integration_notifs que você criou.
Na página my_integration_notifs, role até a parte inferior da página. Verifique se a guia Assinaturas está ativa e se a mensagem Nenhuma assinatura para exibir aparece.
Clique em Criar assinatura.
No menu exibido, selecione Criar assinatura.
Na página Adicionar assinatura ao tópico:
- No campo ID da assinatura, insira
my_integration_notifs_sub. - Defina o valor de Prazo de confirmação como
120segundos. Isso permite que o Dataflow tenha tempo suficiente para reconhecer os arquivos processados e ajuda a melhorar o desempenho geral do job do Dataflow. Para mais informações sobre as propriedades de assinatura do Pub/Sub, consulte Propriedades de assinatura. - Deixe todos os outros valores padrão na página.
- Clique em Criar.
- No campo ID da assinatura, insira
Mais adiante neste tutorial, você criará um job do Dataflow. Como parte da criação desse job, você atribui o Dataflow como assinante da assinatura my_integration_notifs_sub. Ao fazer isso, o Dataflow pode receber notificações sobre novos arquivos que o Datastream grava no Cloud Storage, processar os arquivos e transferir as alterações de dados para o BigQuery.
Criar conjuntos de dados no BigQuery
Nesta seção, você criará conjuntos de dados no BigQuery. O BigQuery usa conjuntos de dados para conter os dados recebidos do Dataflow. Esses dados representam as alterações no banco de dados MySQL de origem que o Datastream transmite para seu bucket do Cloud Storage.
Acesse a página do espaço de trabalho do SQL para BigQuery no console do Google Cloud.
No painel Explorer, ao lado do nome do projeto do Google Cloud, clique em Ver ações.
Selecione Criar conjunto de dados.
Na janela Criar conjunto de dados:
- No campo ID do conjunto de dados, insira um ID para o conjunto de dados. Neste tutorial, insira
My_integration_dataset_logno campo. - Deixe todos os outros valores padrão na janela.
- Clique em Criar conjunto de dados.
- No campo ID do conjunto de dados, insira um ID para o conjunto de dados. Neste tutorial, insira
No painel Explorer, ao lado do nome do projeto do Google Cloud, clique em Expandir nó e verifique se você encontra o conjunto de dados que criou.
Use as etapas neste procedimento para criar um segundo conjunto de dados: My_integration_dataset_final.
Ao lado de cada conjunto de dados, expanda Expandir nó.
Verifique se cada conjunto de dados está vazio.
Depois que o Datastream faz streaming das alterações de dados do banco de dados de origem para o bucket do Cloud Storage, um job do Dataflow processa os arquivos que contêm as alterações e as transfere para os conjuntos de dados do BigQuery.
Criar perfis de conexão no Datastream
Nesta seção, você cria perfis de conexão no Datastream para um banco de dados de origem e um destino. Como parte da criação dos perfis de conexão, selecione MySQL como o tipo de perfil para o perfil de conexão de origem e Cloud Storage como o tipo de perfil para o perfil de conexão de destino.
O Datastream usa as informações definidas nos perfis de conexão para se conectar à origem e ao destino. Assim, é possível fazer streaming de dados do banco de dados de origem para o bucket de destino no Cloud Storage.
Criar um perfil de conexão de origem para o banco de dados MySQL
No console do Google Cloud, acesse a página Perfis de conexão do Datastream.
Clique em Create profile.
Para criar um perfil de conexão de origem para seu banco de dados MySQL, na página Criar um perfil de conexão, clique no tipo de perfil MySQL.
Na seção Definir configurações de conexão da página Criar perfil do MySQL, forneça estas informações:
- No campo Nome do perfil de conexão, insira
My Source Connection Profile. - Mantenha o ID do perfil de conexão gerado automaticamente.
Selecione a Região em que você quer armazenar o perfil de conexão.
Insira os Detalhes da conexão:
- No campo Nome do host ou IP, digite um nome do host ou endereço IP público que o Datastream possa usar para se conectar ao banco de dados de origem. Você está fornecendo um endereço IP público porque usa a lista de permissões de IP como o método de conectividade de rede para este tutorial.
- No campo Porta, insira o número reservado para o banco de dados de origem. Para um banco de dados MySQL, a porta padrão é
3306. - Insira um Nome de usuário e uma Senha para autenticar no banco de dados de origem.
- No campo Nome do perfil de conexão, insira
Na seção Definir as configurações de conexão, clique em Continuar. A seção Secure your connection to your source da página Create MySQL profile está ativa.
No menu Tipo de criptografia, selecione Nenhum. Para mais informações sobre esse menu, consulte Criar um perfil de conexão para o banco de dados MySQL.
Na seção Proteger sua conexão com a origem, clique em Continuar. A seção Definir método de conectividade da página Criar perfil do MySQL está ativa.
No menu suspenso Método de conectividade, escolha o método de rede que você quer usar para estabelecer a conectividade entre o Datastream e o banco de dados de origem. Para este tutorial, selecione Lista de permissões de IP como o método de conectividade.
Configure seu banco de dados de origem para permitir conexões de entrada dos endereços IP públicos do Datastream que aparecem.
Na seção Definir método de conectividade, clique em Continuar. A seção Testar perfil de conexão da página Criar perfil do MySQL está ativa.
Clique em Executar teste para verificar se o banco de dados de origem e o Datastream podem se comunicar entre si.
Verifique se o status Aprovado no teste é exibido.
Clique em Criar.
Criar um perfil de conexão de destino para o Cloud Storage
No console do Google Cloud, acesse a página Perfis de conexão do Datastream.
Clique em Create profile.
Para criar um perfil de conexão de destino para o Cloud Storage, na página Criar um perfil de conexão, clique no tipo de perfil do Cloud Storage.
Na página Criar perfil do Cloud Storage, forneça estas informações:
- No campo Nome do perfil de conexão, insira
My Destination Connection Profile. - Mantenha o ID do perfil de conexão gerado automaticamente.
- Selecione a Região em que você quer armazenar o perfil de conexão.
No painel Detalhes da conexão, clique em Procurar para selecionar o bucket do Cloud Storage que você criou anteriormente neste tutorial. É o bucket para onde o Datastream transfere dados do banco de dados de origem. Depois de fazer sua seleção, clique em Selecionar.
Seu bucket aparece no campo Nome do bucket do painel Detalhes da conexão.
No campo Prefixo do caminho do perfil de conexão, forneça um prefixo para o caminho que você quer anexar ao nome do bucket quando o Datastream transmitir dados para o destino. O Datastream precisa gravar os dados em um caminho dentro do bucket, não na pasta raiz do bucket. Para este tutorial, use o caminho que você definiu quando configurou sua notificação do Pub/Sub. Insira
/integration/tutorialno campo.
- No campo Nome do perfil de conexão, insira
Clique em Criar.
Depois de criar um perfil de conexão de origem para seu banco de dados MySQL e um perfil de conexão de destino para o Cloud Storage, use-os para criar um stream.
Criar um fluxo no Datastream
Nesta seção, você criará um fluxo. Esse fluxo usa as informações dos perfis de conexão para transferir dados de um banco de dados MySQL de origem para um bucket de destino no Cloud Storage.
Definir configurações do stream
No console do Google Cloud, acesse a página Streams do Datastream.
Clique em Criar stream.
Forneça as seguintes informações no painel Definir detalhes do fluxo da página Criar stream:
- No campo Nome do fluxo, digite
My Stream. - Mantenha o ID do stream gerado automaticamente.
- No menu Região, selecione a região onde você criou os perfis de conexão de origem e de destino.
- No menu Tipo de origem, selecione o tipo de perfil MySQL.
- No menu Tipo de destino, selecione o tipo de perfil Cloud Storage.
- No campo Nome do fluxo, digite
Revise os pré-requisitos necessários que são gerados automaticamente para refletir como o ambiente precisa estar preparado para um stream. Esses pré-requisitos podem incluir como configurar o banco de dados de origem e como conectar o Datastream ao bucket de destino no Cloud Storage.
Clique em Continuar. O painel Definir perfil de conexão do MySQL da página Criar stream é exibido.
Especificar informações sobre o perfil de conexão de origem
Nesta seção, você seleciona o perfil de conexão criado para o banco de dados de origem (o perfil de conexão de origem). Para este tutorial, é chamado Meu perfil de conexão de origem.
No menu Perfil de conexão de origem, selecione o perfil de conexão de origem do banco de dados MySQL.
Clique em Executar teste para verificar se o banco de dados de origem e o Datastream podem se comunicar entre si.
Se o teste falhar, o problema associado ao perfil de conexão será exibido. Consulte a página Como diagnosticar problemas para ver as etapas de solução de problemas. Faça as alterações necessárias para corrigir o problema e teste novamente.
Clique em Continuar. O painel Configurar origem da transmissão é exibido na página Criar stream.
Configurar informações sobre o banco de dados de origem para o fluxo
Nesta seção, você configura informações sobre o banco de dados de origem para o fluxo especificando as tabelas e os esquemas no banco de dados de origem que o Datastream:
- Pode ser transferido para o destino.
- esteja impedido de ser transferido para o destino;
Você também determina se o Datastream preenche os dados históricos, transmite as alterações contínuas no destino ou apenas as alterações feitas nos dados.
Use o menu Objetos para incluir para especificar as tabelas e esquemas no banco de dados de origem que o Datastream pode transferir para uma pasta no bucket de destino do Cloud Storage. O menu só será carregado se o banco de dados tiver até 5.000 objetos.
Neste tutorial, você quer que o Datastream transfira todas as tabelas e esquemas. Selecione Todas as tabelas de todos os esquemas no menu.
Verifique se o painel Selecionar objetos a serem excluídos está definido como Nenhum. Você não quer impedir que o Datastream transfira tabelas e esquemas do seu banco de dados de origem para o Cloud Storage.
Verifique se o painel Escolha o modo de preenchimento para dados históricos está definido como Automático. O Datastream transmite todos os dados atuais, além das alterações, da origem para o destino.
Clique em Continuar. O painel Definir perfil de conexão do Cloud Storage é exibido na página Criar stream.
Selecione um perfil de conexão de destino
Nesta seção, você vai selecionar o perfil de conexão criado para o Cloud Storage (o perfil de conexão de destino). Para este tutorial, é chamado Meu perfil de conexão de destino.
No menu Perfil de conexão de destino, selecione seu perfil de conexão de destino para o Cloud Storage.
Clique em Continuar. O painel Configurar destino do stream é exibido na página Criar stream.
Configurar informações sobre o destino do stream
Nesta seção, você configura informações sobre o bucket de destino do stream. Essas informações incluem:
- O formato de saída dos arquivos gravados no Cloud Storage.
- A pasta do bucket de destino para o qual o Datastream transfere esquemas, tabelas e dados do banco de dados de origem.
No campo Formato de saída, selecione o formato de arquivos gravados no Cloud Storage. O Datastream aceita dois formatos de saída: Avro e JSON. Neste tutorial, Avro é o formato de arquivo.
Clique em Continuar. Aparecerá a página Criar detalhes da transmissão e a página Criar stream.
Criar o stream
Verificar os detalhes do stream, bem como os perfis de conexão de origem e destino que o stream usa para transferir dados de um banco de dados MySQL de origem para um bucket de destino no Cloud Storage.
Para validar o stream, clique em Executar validação. Ao validar um stream, o Datastream verifica se a origem está configurada corretamente, verifica se o stream pode se conectar à origem e ao destino e verifica a configuração de ponta a ponta do stream.
Depois que todas as verificações de validação forem aprovadas, clique em Criar.
Na caixa de diálogo Criar fluxo?, clique em Criar.
Iniciar o stream
Para este tutorial, você cria e inicia um stream separadamente caso o processo de criação de stream intensifique a carga no banco de dados de origem. Para adiar essa carga, crie o stream sem iniciá-lo e inicie-o quando seu banco de dados puder lidar com a carga.
Ao iniciar o stream, ele pode transferir dados, esquemas e tabelas do banco de dados de origem para o destino.
No console do Google Cloud, acesse a página Streams do Datastream.
Marque a caixa de seleção ao lado da transmissão que você quer iniciar. Neste tutorial, usamos Meu stream.
Clique em Iniciar.
Na caixa de diálogo, clique em Iniciar. O status do stream muda de
Not startedparaStartingeRunning.
Depois de iniciar um stream, você pode verificar se o Datastream transferiu dados do banco de dados de origem para o destino.
Verificar o stream
Nesta seção, você confirma que o Datastream transfere os dados de todas as tabelas de um banco de dados MySQL de origem para a pasta /integration/tutorial do seu bucket de destino do Cloud Storage.
No console do Google Cloud, acesse a página Streams do Datastream.
Clique no stream que você criou. Neste tutorial, usamos Meu stream.
Na página Detalhes do fluxo, clique no link bucket-name/integração/tutorial, em que bucket-name é o nome que você deu ao bucket do Cloud Storage. Esse link aparece após o campo Caminho de gravação de destino. A página Detalhes do bucket do Cloud Storage é aberta em outra guia.
Verifique se há pastas que representam tabelas do banco de dados de origem.
Clique em uma das pastas da tabela e em cada subpasta até ver os dados associados a ela.
Criar um job do Dataflow
Nesta seção, você criará um job no Dataflow. Depois que o Datastream transmite as alterações de um banco de dados MySQL de origem para seu bucket do Cloud Storage, o Pub/Sub envia notificações ao Dataflow sobre novos arquivos com as mudanças. O job do Dataflow processa os arquivos e transfere as alterações para o BigQuery.
No console do Google Cloud, acesse a página Jobs do Dataflow.
Clique em Criar job usando um modelo.
No campo Nome do job, insira o nome do job do Dataflow que você está criando na página Criar job usando um modelo. Neste tutorial, insira
my-dataflow-integration-jobno campo.No menu Endpoint regional, selecione a região em que você quer armazenar o job. Essa é a mesma região que você selecionou para o perfil de conexão de origem, o perfil de conexão de destino e o stream que você criou.
No menu Modelo do Dataflow, selecione o modelo que você está usando para criar o job. Neste tutorial, selecione Datastream para o BigQuery.
Após a seleção, serão exibidos campos adicionais relacionados a esse modelo.
No campo Local do arquivo para a saída do arquivo do Datastream no Cloud Storage, insira o nome do bucket do Cloud Storage usando o seguinte formato:
gs://bucket-name.No campo Assinatura do Pub/Sub que está sendo usada em uma política de notificação do Cloud Storage, digite o caminho que contém o nome da sua assinatura do Pub/Sub. Para este tutorial, insira
projects/project-name/subscriptions/my_integration_notifs_sub.No campo Formato do arquivo de saída Datastream (avro/json)., digite
avroporque, neste tutorial, o Avro é o formato de arquivo que o Datastream grava no Cloud Storage.No campo Nome ou modelo do conjunto de dados para conter tabelas de preparo, insira
My_integration_dataset_logporque o Dataflow usa esse conjunto de dados para organizar as alterações de dados que recebe do Datastream.No campo Modelo para que o conjunto de dados contenha tabelas de réplica, digite
My_integration_dataset_finalporque as mudanças testadas no conjunto de dados My_integration_dataset_log são mescladas para criar uma réplica individual das tabelas no banco de dados de origem.No campo Diretório da fila de mensagens inativas, insira o caminho que contém o nome do bucket do Cloud Storage e uma pasta para a fila de mensagens inativas. Não use um caminho na pasta raiz e se ele é diferente daquele em que o Datastream grava dados. Todas as alterações de dados que o Dataflow não transferir para o BigQuery são armazenadas na fila. É possível corrigir o conteúdo na fila para que o Dataflow possa processá-lo novamente.
Para este tutorial, digite
gs://bucket-name/dlqno campo Diretório de fila de mensagens inativas (em que bucket-name é o nome do bucket e dlq é a pasta da fila de mensagens inativas).Cliquem em Executar job.
Verificar a integração
Na seção Verificar o stream deste tutorial, você confirmou que o Datastream transferiu os dados de todas as tabelas de um banco de dados MySQL de origem para a pasta /integration/tutorial do bucket de destino do Cloud Storage.
Nesta seção, você verá como o Dataflow processa os arquivos que contêm as alterações associadas a esses dados e as transfere para o BigQuery. Como resultado, você tem uma integração completa entre o Datastream e o BigQuery.
No console do Google Cloud, acesse a página do espaço de trabalho do SQL para BigQuery.
No painel Explorador, expanda o nó ao lado do nome do seu projeto do Google Cloud.
Expanda os nós ao lado dos conjuntos de dados My_integration_dataset_log e My_integration_dataset_final.
Verifique se cada conjunto de dados agora contém dados. Isso confirma que o Dataflow processou os arquivos com as alterações associadas aos dados transmitidos pelo Datastream para o Cloud Storage e os transferiu para o BigQuery.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, use o console do Google Cloud para fazer o seguinte:
- Exclua o projeto, o fluxo do Datastream e os perfis de conexão do Datastream.
- Interrompa o job do Dataflow.
- Exclua os conjuntos de dados do BigQuery, o tópico e a assinatura do Pub/Sub e o bucket do Cloud Storage.
Ao limpar os recursos criados no Datastream, Dataflow, BigQuery, Pub/Sub e Cloud Storage, você evita que eles ocupem cota e não recebe cobranças por eles no futuro.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para este tutorial.
No console do Google Cloud, acesse a página Gerenciar recursos.
Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
Para excluir o projeto, digite o ID do projeto na caixa de diálogo e clique em Encerrar.
Excluir o stream
No console do Google Cloud, acesse a página Streams do Datastream.
Clique no stream que você quer excluir. Neste tutorial, usamos Meu stream.
Clique em Pausar.
Na caixa de diálogo, clique em Pausar.
No painel Status do stream da página Detalhes do stream, verifique se o status do stream é
Paused.Clique em Excluir.
Na caixa de diálogo, no campo de texto, digite
Deletee clique em Excluir.
Excluir os perfis de conexão
No console do Google Cloud, acesse a página Perfis de conexão do Datastream.
Marque a caixa de seleção de cada perfil de conexão que você quer excluir: Meu perfil de conexão de origem e Meu perfil de conexão de destino.
Clique em Excluir.
Na caixa de diálogo, clique em Excluir.
interrompa o job do Dataflow
No console do Google Cloud, acesse a página Jobs do Dataflow.
Clique no job que você quer interromper. Para este tutorial, o nome é my-dataflow-integration-job.
Clique em Interromper.
Na caixa de diálogo Interromper job, selecione a opção Drenar e clique em Interromper job.
Excluir os conjuntos de dados do BigQuery
No console do Google Cloud, acesse a página do espaço de trabalho do SQL para BigQuery.
No painel Explorer, expanda o nó ao lado do nome do projeto do Google Cloud.
Clique no botão Ver ações à direita de um dos conjuntos de dados que você criou em Criar conjuntos de dados no BigQuery. Esse botão parece uma reticência vertical.
Para este tutorial, clique no botão Exibir ações à direita de My_integration_dataset_log.
Selecione Excluir no menu suspenso exibido.
Na caixa de diálogo Excluir conjunto de dados?, insira
deleteno campo de texto e clique em Excluir.Repita as etapas deste procedimento para excluir o segundo conjunto de dados que você criou: My_integration_dataset_final.
Exclua a assinatura e o tópico do Pub/Sub
No console do Google Cloud, acesse a página Assinaturas do Pub/Sub.
Clique na caixa de seleção ao lado da assinatura que você quer excluir. Para este tutorial, clique na caixa de seleção ao lado da assinatura my_integration_notifs_sub.
Clique em Excluir.
Na caixa de diálogo Excluir assinatura, clique em Excluir.
No console do Google Cloud, acesse a página Tópicos do Pub/Sub.
Clique na caixa de seleção ao lado do tópico my_integration_notifs.
Clique em Excluir.
Na caixa de diálogo Excluir tópico, insira
deleteno campo de texto e clique em Excluir.
Exclua o bucket do Cloud Storage
No console do Google Cloud, acesse a página Navegador do Cloud Storage.
Marque a caixa de seleção ao lado do bucket.
Clique em Excluir.
Na caixa de diálogo, digite
Deleteno campo de texto e clique em Excluir.
A seguir
- Saiba mais sobre o Datastream.
- Usar a API de streaming legada para executar recursos avançados com dados de streaming no BigQuery.
- Teste outros recursos do Google Cloud. Veja nossos tutoriais.