Classificação rápida e confiável no Datastore
Classificação: um problema nem tão simples assim
Tomoaki Suzuki (Figura 1), engenheiro-chefe do App Engine na Applibot, tenta resolver um problema muito comum, porém, bastante difícil, enfrentado por todos os grandes serviços relacionados a jogos: a classificação.

A Applibot é um dos maiores provedores de aplicativos sociais do Japão. Essa empresa é única devido ao amplo conhecimento e à extensa experiência na criação de serviços relacionados a jogos sociais superescaláveis utilizando o Google App Engine, a solução de plataforma como serviço (PaaS, na sigla em inglês) oferecida pelo Google. A Applibot aproveita ao máximo a plataforma. Isso garante o sucesso da empresa em atrair oportunidades de negócios no mercado de jogos sociais, tanto no Japão como nos Estados Unidos. E o que não faltam são provas desse sucesso. Por exemplo, o Legend of the Cryptids (Figura 2), um dos principais títulos da empresa, chegou ao primeiro lugar na categoria de jogos da Apple App Store da América do Norte em outubro de 2012. A série Legend já alcançou 4,7 milhões de downloads. Além disso, o jogo Gang Road chegou ao primeiro lugar na classificação de vendas totais da App Store do Japão em dezembro de 2012.

A empresa conseguiu escalar esses títulos e lidar com o tráfego cada vez maior sem grandes dificuldades. A Applibot não encontrou obstáculos na criação de clusters complexos de servidores virtuais ou bancos de dados fragmentados. Ela contou com o poder do App Engine para escalar e disponibilizar seus títulos com eficiência.
No entanto, manter a classificação atualizada, principalmente nessa escala, não é um problema fácil de solucionar para Tomoaki nem para muitos desenvolvedores. Os requisitos são simples:
- Seu jogo tem centenas de milhares (ou mais) jogadores.
- Sempre que um jogador luta contra inimigos ou realiza outras atividades, a pontuação dele muda.
- O ideal é exibir a classificação mais recente do jogador em um portal da Web.
Como calcular a classificação?
Chegar a uma classificação é fácil quando ela não precisa ser escalável nem disponibilizada rapidamente. Por exemplo, é possível executar a consulta a seguir:
SELECT count(key) FROM Players WHERE Score > YourScore
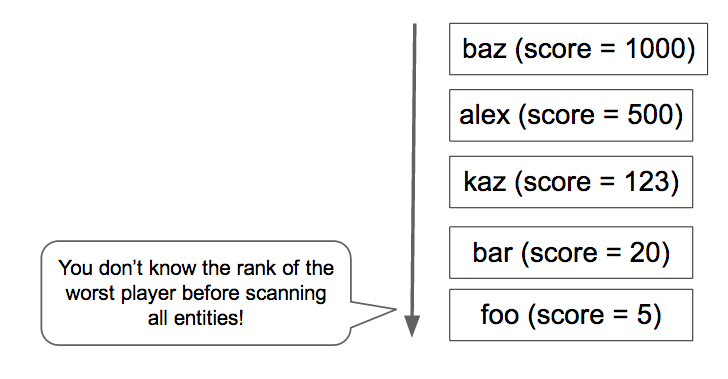
Ela conta todos os jogadores com a pontuação maior do que a sua (Figura 4). Mas você quer mesmo executar essa consulta para cada solicitação na página de classificações do portal? Quanto tempo isso vai demorar se você tiver milhões de jogadores?
Inicialmente, Tomoaki implementou essa abordagem. No entanto, cada resposta demorava alguns segundos. Essa abordagem se mostrou muito lenta e cara, além de ter um desempenho gradualmente pior à medida que a escala aumentava.
Em seguida, Tomoaki tentou manter os dados de classificação no Memcache. Essa abordagem oferecia rapidez, mas não confiança. No Memcache, as entradas poderiam ser removidas a qualquer momento. Além disso, em algumas ocasiões, o sistema ficava indisponível. Com um serviço de classificação que dependia somente de valores-chave na memória, era difícil manter a consistência e a disponibilidade.
Como alternativa temporária, Tomoaki decidiu reduzir o nível de serviço. Em vez de calcular a classificação em cada solicitação, ele programou uma tarefa para verificar e atualizar a classificação de cada jogador de hora em hora. Dessa maneira, as solicitações da página do portal recebiam a classificação do jogador instantaneamente, mas esse valor poderia ser de uma hora atrás.
Por fim, Tomoaki decidiu procurar uma implementação permanente, transacional, rápida e escalável que pudesse aceitar 300 solicitações de atualização de pontuação por segundo. Além disso, seria necessário receber a classificação de cada jogador em centenas de milésimos de segundo. Para encontrar uma solução, Tomoaki buscou a ajuda de Kaz Sato, arquiteto de soluções e gerente técnico de contas da equipe do Google Cloud Platform. Ele assinou um contrato de suporte nível Premium em nome da Applibot.
Uma forma rápida de solucionar problemas
Muitos clientes ou parceiros de grande porte do Google Cloud Platform como a Applibot assinam um contrato de suporte nível Premium. Ele oferece o suporte técnico e comercial ininterrupto das equipes de Suporte ao Cliente e de Vendas do Google Cloud. O contrato também disponibiliza um gerente técnico de contas (TAM, na sigla em inglês) para cada cliente.
O TAM fornece ao cliente informações sobre a Engenharia do Google, responsável por desenvolver a real infraestrutura de nuvem. Os TAMs conhecem todos os detalhes do sistema e da arquitetura do cliente. Além disso, eles usam o conhecimento e a rede de contatos adquiridos como representantes da Engenharia do Google para solucionar problemas importantes. Os TAMs encaminham esses problemas aos arquitetos de soluções da equipe ou aos engenheiros de software do Cloud Platform. Portanto, o contrato de suporte nível Premium é a forma mais rápida de encontrar soluções com o Google Cloud Platform.
Kaz, o TAM da Applibot, sabia que a classificação era um problema clássico, mas de difícil solução, para qualquer serviço distribuído escalável. Para encontrar uma solução que atendesse aos requisitos da Applibot, ele começou analisando as implementações de classificação já conhecidas no Google Cloud Datastore e em outros armazenamentos de dados NoSQL.
À procura de um algoritmo O(log n)
A solução de consulta simples exige a verificação de todos os jogadores com uma pontuação mais alta para determinar a classificação de um único jogador. A complexidade temporal desse algoritmo é O(n), ou seja, o tempo necessário para executar cada consulta aumenta proporcionalmente ao número de jogadores. Na prática, isso significa que o algoritmo não é escalável. Em vez disso, precisamos de um algoritmo O(log n) ou mais veloz, que provoca o aumento logarítmico do tempo à medida que o número de jogadores cresce.
Se você já estudou ciência da computação, talvez se lembre de que os algoritmos em árvore, como as árvores binárias ou árvores B, podem ser executados em complexidade temporal O(log n) para encontrar um elemento. Também é possível usar os algoritmos em árvore para calcular um valor agregado de um intervalo de elementos como contagens máxima, mínima e média, detendo os valores agregados em cada node de ramificação. Ao usar essa técnica, é possível implementar um algoritmo de classificação com o desempenho de O(log n).
Kaz encontrou uma implementação de código aberto de um algoritmo de classificação em árvore para o Datastore, escrito por um engenheiro do Google: a biblioteca de classificação do Google Code Jam.
Essa biblioteca baseada em Python expõe dois métodos:
SetScorepara definir a pontuação de um jogador.FindRankpara obter a classificação de uma determinada pontuação.
À medida que os pares jogador-pontuação são criados e atualizados com o método SetScore, a biblioteca de classificação Code Jam cria uma árvore N-ária 1. Por exemplo, vamos pensar em uma árvore terciária que pode contar o número de jogadores com pontuação contida no intervalo de 0 a 80 (Figura 5). A biblioteca armazena o node raiz, que guarda três números, como uma entidade. Cada número corresponde ao número de jogadores com pontuação contida nos subintervalos 0 a 26, 27 a 53 e 54 a 80, respectivamente. O node raiz tem um filho para cada intervalo que, por sua vez, guarda três valores para os jogadores nos subintervalos do subintervalo. A hierarquia precisa de quatro níveis para armazenar o número de jogadores correspondente a 81 valores de pontuação diferentes.
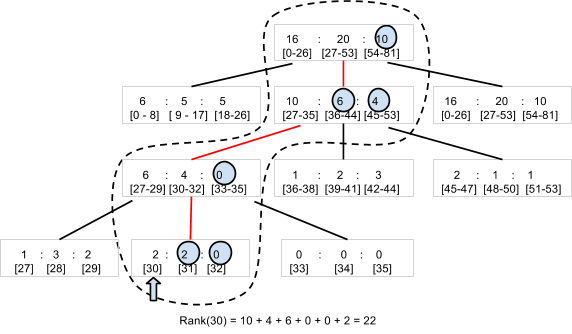
Para determinar a classificação de um jogador com pontuação igual a 30, basta que a biblioteca leia quatro entidades (os nós rodeados pela linha tracejada no diagrama) para somar o número de jogadores com pontuação acima de 30. Com 22 jogadores à direita em quatro entidades, a classificação do jogador é 23º.
Da mesma forma, uma chamada para SetScore precisa atualizar apenas quatro entidades. Mesmo se houver uma variação maior de pontuações diferentes, o acesso do Datastore aumentará somente em O(log n) e não será afetado pelo número de jogadores. Na prática, a biblioteca de classificação do Code Jam usa, por padrão, 100 valores por node em vez de três. Portanto, será necessário acessar somente duas entidades ou três se o intervalo de pontuações for maior que 100.000.
Kaz usou a popular ferramenta Apache JMeter para realizar um teste de carga na biblioteca de classificação do Code Jam e confirmou que a biblioteca responde rapidamente. Ambos os métodos SetScore e FindRank terminam a operação em centenas de milésimos de segundo usando o algoritmo em árvore n-ária executado em complexidade temporal de O(log n).
Escalabilidade limitada em atualizações simultâneas
No entanto, durante o teste de carga, Kaz encontrou uma limitação importante na biblioteca de classificação do Code Jam. A escalabilidade era muito baixa em termos de capacidade de atualização. Quando ele aumentou a carga para três atualizações por segundo, a biblioteca passou a retornar erros de repetição de transação. Era óbvio que a biblioteca não atenderia ao requisito da Applibot de 300 atualizações por segundo. Ela poderia processar somente cerca de 1% dessa capacidade.
E qual a explicação? O motivo está no custo em manter a consistência da árvore. No Datastore, é necessário usar um grupo de entidades para garantir uma consistência forte na atualização de diversas entidades em uma transação. Veja Como equilibrar a consistência forte e eventual com o Google Cloud Datastore. A biblioteca de classificação do Code Jam usa um único grupo de entidades que contém a árvore inteira. Isso garante a consistência das contagens nos elementos da árvore.
No entanto, um grupo de entidades no Datastore tem uma limitação de desempenho. O Datastore é compatível com só uma transação por segundo no grupo de entidades. Além disso, se o mesmo grupo de entidades for modificado em transações simultâneas, provavelmente elas falharão e precisarão ser repetidas. A biblioteca de classificação do Code Jam é fortemente consistente, transacional e relativamente rápida, mas não é compatível com um volume elevado de atualizações simultâneas.
A solução da equipe do Datastore: agregação de jobs
Kaz se lembrou de que um engenheiro de software da equipe do Datastore havia mencionado uma técnica para receber uma capacidade muito maior do que uma atualização por segundo em um grupo de entidades. Isso seria possível por meio da agregação de um lote de atualizações em uma única transação, em vez de executar cada atualização como uma transação individual. Porém, por conter um grande número de atualizações, cada transação levaria mais tempo, aumentando a possibilidade de conflito nas simultâneas.
Em resposta à solicitação de Kaz, a equipe do Datastore começou a discutir esse problema e nos aconselhou a testar a agregação de jobs, um dos padrões de design usados com o Megastore.
Megastore é a camada de armazenamento subjacente do Datastore que gerencia a consistência e a transacionalidade dos grupos de entidades. Ela é fonte do limite de uma atualização por segundo. Como o Megastore é muito usado por diversos serviços do Google, os engenheiros coletam e compartilham as práticas recomendadas e os padrões de design da empresa. Assim, eles criam um sistema escalável e consistente com esse armazenamento de dados NoSQL.
A ideia básica da agregação de jobs é usar um único thread para processar um lote de atualizações. Como há somente um único thread e uma única transação aberta no grupo de entidades, não ocorrem falhas na transação causadas por atualizações simultâneas. É possível encontrar ideias semelhantes em outros produtos de armazenamento, como VoltDb e Redis.
Entretanto, o padrão de agregação de jobs tem uma desvantagem. Ele usa somente um thread para agregar todas as atualizações e impõe um limite de velocidade para o envio de atualizações ao Datastore. Portanto, era importante determinar se a agregação de jobs poderia atender ao requisito de capacidade de 300 atualizações por segundo, exigido pela Applibot.
Agregação de jobs por fila pull
Com base no conselho da equipe do Datastore, Kaz escreveu o código de prova de conceito (PoC, na sigla em inglês) que combina o padrão de agregação de jobs com a biblioteca de classificação do Code Jam. A PoC tem os seguintes componentes:
- Frontend: aceita solicitações
SetScorede usuários e as adiciona como tarefas a uma fila pull. - Fila pull: recebe e retém as solicitações de atualização
SetScoredo front-end. - Back-end: executa um loop infinito com um único thread que extrai as solicitações de atualização da fila e as executa com a biblioteca de classificação do Code Jam.
A PoC cria uma fila pull, um tipo de fila de tarefas no App Engine. Com ela, os desenvolvedores implementam um ou vários workers que consomem as tarefas adicionadas à lista. A instância de back-end tem um único thread em um loop infinito que continua extraindo a maior quantidade possível de tarefas (até mil) da fila. O thread transmite cada solicitação de atualização à biblioteca de classificação do Code Jam que, por sua vez, executa as solicitações como um lote em uma única transação. Mesmo que a transação seja aberta por um segundo ou mais, como há um único thread conduzindo a biblioteca e o Datastore, não há contenção nem problema de modificações simultâneas.
A instância de back-end é definida como um módulo, um recurso do App Engine que permite aos desenvolvedores definir uma instância de aplicativo com várias características. Nessa PoC, a instância de back-end é definida como uma instância de escalonamento manual. Somente uma única instância desse tipo é executada em cada momento.
Kaz realizou o teste de carga da PoC usando o JMeter. Ele confirmou que a PoC era capaz de processar 200 solicitações SetScore por segundo, com lotes de 500 a 600 atualizações por transação. A agregação de jobs funciona de verdade!
Fragmentação de fila para um desempenho estável
No entanto, em pouco tempo, Kaz se deparou com outro problema. Ao continuar executando o teste por vários minutos, ele constatou que a capacidade da fila pull flutuava de tempos em tempos (Figura 6). Especificamente, ao adicionar mais solicitações à fila com 200 tarefas por segundo durante vários segundos, de repente a fila parou de transmitir as tarefas para o back-end, aumentando significativamente a latência de cada tarefa.

Kaz perguntou à equipe de Fila de Tarefas por que isso estava acontecendo. A resposta foi que esse é um comportamento conhecido da implementação atual de fila pull que depende do Bigtable como camada permanente. Quando um bloco do Bigtable fica muito grande, ele é dividido em vários blocos. Durante a divisão do bloco, as tarefas não são entregues, resultando na flutuação do desempenho quando a fila recebe tarefas em taxa elevada. A equipe de Fila de Tarefas está trabalhando para aprimorar essas características de desempenho.
Michael Tang, arquiteto de soluções, recomendou uma alternativa usando a fragmentação de fila. Em vez de usar somente uma, ele sugeriu distribuir a carga em várias filas. Cada fila pode ser armazenada em um servidor de bloco diferente do Bigtable para minimizar o efeito da divisão de blocos e manter uma alta taxa de processamento de tarefas. Enquanto uma fila está processando uma divisão, as outras continuam trabalhando. Além disso, a fragmentação reduz a carga em cada fila. Portanto, ocorrem menos divisões de blocos.
O loop da instância de back-end aprimorada executa o algoritmo a seguir:
- Alocar tarefas
SetScorede 10 filas. - Chame o método
SetScorescom as tarefas. - Excluir as tarefas alocadas das filas.
Na etapa 1, cada fila fornece até mil tarefas, cada uma com um nome de usuário e a pontuação. Após agregar todos os pares jogador-pontuação em um dicionário, a etapa 2 transmite o lote de atualizações para o método SetScores da biblioteca de classificação do Code Jam, que abre uma transação para armazená-las no Datastore. Se não ocorrer erros durante a execução desse método, a etapa 3 excluirá as tarefas alocadas das filas.
Se ocorrer um erro ou encerramento inesperado do loop ou da instância de back-end, as tarefas de atualização permanecerão nas filas para que sejam processadas quando a instância reiniciar. Em um sistema de produção, é possível ter outro back-end atuando como um guardião em modo de espera, pronto para assumir se a primeira instância falhar.
A solução proposta executa continuamente 300 atualizações por segundo2
A Figura 7 mostra o resultado do teste de carga da implementação final de PoC com a fragmentação de fila. Com efeito, essa solução minimiza as flutuações no desempenho das filas e suporta 300 atualizações por segundo durante várias horas. Em cargas normais, cada atualização é aplicada ao Datastore em poucos segundos após o recebimento da solicitação.

Essa solução atende a todos os requisitos originais da Applibot:
- escalável para processar dezenas de milhares de jogadores.
- permanente e consistente, já que todas as atualizações são executadas em transações do Datastore
- rápida o suficiente para processar 300 atualizações por segundo
Tendo em mãos os resultados do teste de carga e o código de PoC, Kaz apresentou a solução a Tomoaki e outros engenheiros da Applibot. Tomoaki planeja incorporar a solução no sistema de produção da empresa. Ele espera reduzir a latência da atualização das informações de classificação de uma hora para poucos segundos e, assim, melhorar significativamente a experiência do usuário.
Resumo da árvore de classificação com agregação de jobs
A solução proposta apresenta diversas vantagens e apenas uma desvantagem:
Vantagens:
- Rapidez: a chamada
FindRankleva algumas centenas de milissegundos ou menos. - Agilidade:
SetScoreapenas envia uma tarefa, que é processada pelo back-end em alguns segundos. - Fortemente consistente e permanente no Datastore.
- As classificações são precisas.
- Escalável para qualquer número de jogadores.
Desvantagem:
- Limitação na capacidade (cerca de 300 atualizações por segundo com a implementação atual).
Como essa solução usa o padrão de agregação de jobs, ela depende de um único thread para agregar todas as atualizações. Ainda é necessário trabalhar mais ou elevar a complexidade para conseguir uma capacidade acima de 300 atualizações por segundo com a potência de CPU atual das instâncias do App Engine e o desempenho do Datastore.
Solução mais escalável com uma árvore fragmentada
Para receber uma taxa de atualização ainda maior, talvez seja necessário fragmentar a árvore de classificação. Para tanto, basta criar várias implementações do sistema acima: um conjunto de filas com cada um conduzindo um módulo de back-end que atualiza a própria árvore de classificação.
Em geral, a coordenação das árvores não é obrigatória nem esperada. No caso mais simples, cada atualização SetScore é enviada aleatoriamente para uma fila. Com três árvores desse tipo, cada uma contendo o próprio grupo de entidades do Datastore e servidor de back-end, a capacidade de atualização esperada é três vezes maior. A desvantagem é que FindRank precisa consultar cada árvore de classificação para receber a classificação correspondente a uma determinada pontuação e depois somar a classificação de cada árvore para encontrar o valor verdadeiro. Isso demora um pouco mais. O tempo de consulta para FindRank pode ser reduzido substancialmente mantendo entidades no Memcache.
Isso é semelhante à abordagem conhecida na qual são usados contadores fragmentados: cada contador é incrementado independentemente, e a soma total é computada pelo cliente somente quando necessário.
Por exemplo, com três árvores, FindRank(865) pode encontrar as três classificações 124, 183 e 156, indicando que cada árvore guarda o número respectivo de pontuações acima de 865. O número total computado de pontuações acima de 865 é, portanto, 124 + 183 + 156 = 463.
Essa abordagem não funciona com todos os tipos de algoritmos distribuídos. No entanto, como a classificação é essencialmente um problema de contagem comutativa, a abordagem funciona com um grande volume de problemas de classificação.
Soluções mais escaláveis com abordagens aproximadas
Se seu aplicativo requer mais escalabilidade do que precisão nas classificações e pode tolerar um determinado nível de imprecisão ou aproximação, opte por abordagens estocásticas como estas:
- Buckets com consulta global
- método de contagem com perda
- streaming frugal
Essas abordagens aproximadas são variantes que respondem à pergunta: como compactar o armazenamento das informações de classificação ao permitir um certo comprometimento da precisão?
O uso de buckets com consulta global é uma solução alternativa proposta pela equipe do Datastore e pelo TAM Alex Amies. Alex implementou uma PoC com base na ideia da equipe do Datastore e realizou uma análise de desempenho abrangente. Ele provou que a abordagem de buckets com consulta global é uma solução de classificação escalável, com comprometimento mínimo da precisão e adequada para aplicativos que requerem uma capacidade maior do que a oferecida pela biblioteca de classificação do Code Jam. Leia uma descrição detalhada no Apêndice e confira os resultados do teste.
Tanto o método de contagem com perda quanto o streaming frugal são denominados algoritmos on-line e algoritmos de streaming, respectivamente. Eles permitem o uso de uma quantidade muito pequena de armazenamento na memória para uma estimativa estocástica dos jogadores no topo da classificação, a partir de um fluxo de pares jogador-pontuação. Esses algoritmos são adequados para aplicativos que requerem uma latência muito baixa e altíssima largura de banda, tal como os que realizam milhares de atualizações por segundo, com precisão mais limitada e cobertura dos resultados de classificação. Por exemplo, esses algoritmos são de grande ajuda para quem quer ter um painel em tempo real que exiba as 100 palavras-chave mais digitadas em um streaming de rede social.
Conclusão
Determinar a classificação é um problema clássico, mas de difícil solução se você precisa que o algoritmo seja escalável, consistente e rápido. Neste artigo, descrevemos como os TAMs trabalharam com o cliente e as equipes de Engenharia do Google para solucionar esse desafio e oferecer uma solução capaz de reduzir a latência da atualização da classificação de uma hora para poucos segundos. Os padrões de design descobertos no processo (agregação de jobs e fragmentação de fila) também podem ser aplicados a problemas comuns em outros designs de sistema baseados no Datastore que requerem centenas de atualizações por segundo com uma consistência forte.
Observações
- A biblioteca de classificação do Code Jam usa um parâmetro chamado "fator de ramificação" que especifica quantas pontuações cada entidade guardará. Por padrão, o valor usado pela biblioteca para esse parâmetro é 100. Nesse caso, as pontuações de 0 e 9.999 serão armazenadas em 100 entidades como filhos do node raiz. Para processar um intervalo maior de pontuações, basta alterar o fator de ramificação para um valor maior, a fim de otimizar o número de acessos às entidades.
- Todos os números de desempenho descritos neste artigo são valores de amostra para fins de referência, e não uma garantia de desempenho absoluto do App Engine, do Datastore ou de outros serviços.
Apêndice: solução de buckets com consulta global
Como foi dito na seção Como calcular a classificação, é caro consultar o banco de dados para cada solicitação de classificação. Essa abordagem alternativa recebe periodicamente a contagem de todas as pontuações, calcula a classificação de pontuações selecionadas e fornece esses pontos de dados para o cálculo da classificação de determinados jogadores. O bucket total de pontuações é particionado em "buckets". Cada bucket é caracterizado por um subbucket de pontuações e o número de jogadores com pontuações nesse bucket. Utilizando esses dados, é possível calcular com grande aproximação a classificação correspondente a qualquer pontuação. Esses buckets são semelhantes ao node do nível mais elevado da árvore de classificação. No entanto, em vez de se dividir em nodes mais detalhados, esse algoritmo apenas interpola dentro de um bucket.
A recuperação da classificação pelos usuários no front-end é separada do cálculo da classificação dentro dos buckets no back-end para reduzir o tempo da operação. Quando ocorre a solicitação da classificação de um jogador, o bucket apropriado é encontrado com base na pontuação desse jogador. O bucket inclui um limite de classificação superior e uma contagem de jogadores dentro de um bucket. Utiliza-se o tipo de interpolação linear para estimar a classificação dos jogadores dentro dos buckets. Nos nossos testes, conseguimos receber a classificação de um jogador consistentemente em menos de 400 milésimos de segundo para uma ida e volta total de HTTP. O custo do método FindRank não depende do número de jogadores na população.
Como calcular a classificação de uma pontuação
A contagem e a classificação superior, ou seja, a classificação mais elevada possível nesse bucket, são gravadas em cada bucket. No caso das pontuações localizadas entre os limites superior e inferior em um bucket, usamos o tipo de interpolação linear para estimar a classificação. Por exemplo, se um jogador tiver pontuação igual a 60, analisamos o bucket [50, 74] usando a contagem, isto é, o número de jogadores/pontuações no bucket, (42) e a classificação superior (5) para calcular a classificação, por meio da fórmula:
rank = 5 + (74 - 60)*42/(74 - 50) = 30
Cálculo da contagem e do conjunto de cada bucket
Em segundo plano, usando um cron job ou fila de tarefas, as contagens de cada bucket são calculadas e salvas por meio da iteração de todos os buckets. Chamamos isso de consulta global porque a solução calcula os parâmetros necessários para estimar as classificações ao examinar as pontuações de todos os jogadores. Veja abaixo um exemplo de código Python para fazer isso pelas pontuações no bucket [low_score, high_score] para cada bucket.
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
O método GetCountInRange() conta cada jogador com pontuações no bucket abrangido pelo bucket. Como o Datastore mantém um índice classificado de pontuações de jogadores, essa contagem pode ser calculada com eficácia.
Quando precisamos encontrar a classificação de um jogador em particular, podemos usar o código conforme o demonstrado abaixo.
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
O método GetBucketByScore(score) recupera o bucket que contém a pontuação fornecida. O método RankInBucket() executa uma estimativa de classificação dentro do bucket. A classificação do jogador é o resultado da soma da classificação superior no bucket e a dentro do bucket específico que contém a pontuação desse jogador. Precisamos subtrair 1 do resultado porque a classificação superior do bucket mais elevado será 1 e a classificação do melhor jogador dentro de um bucket específico também será 1.
Os buckets são armazenados tanto no Datastore quanto no Memcache. Para calcular a classificação, leia os buckets do Memcache ou do Datastore se o Memcache não tiver os dados. Na nossa implementação desse algoritmo, usamos a biblioteca cliente NDB para Python, que utiliza o Memcache para guardar em cache os dados armazenados no Datastore.
Como os buckets ou outros métodos são usados para representar os dados de maneira compactada, as classificações calculadas não são exatas. As classificações em um bucket são valores aproximados por interpolação linear. É possível usar outros métodos de interpolação mais precisos para receber uma aproximação mais exata dentro do bucket, como uma fórmula de regressão, por exemplo.
Custo
Tanto o custo para encontrar a classificação quanto para atualizar a pontuação de um jogador é O(1), isto é, independente do número de jogadores.
O custo do job de consulta global é O(Jogadores) * frequência de atualização do cache.
O custo para calcular os dados do bucket no job de back-end também está relacionado ao número de buckets, já que uma consulta de contagem é realizada para cada bucket. A consulta de contagem é otimizada para usar uma consulta apenas de chaves. No entanto, mesmo assim, a lista completa de chaves precisa ser recuperada.
Prós
Esse método é muito rápido para atualizar a pontuação de um jogador e para encontrar a classificação correspondente a uma pontuação. Mesmo recebendo resultados com base em um job em segundo plano, se a pontuação de um jogador mudar, a classificação refletirá a mudança na direção apropriada imediatamente. Isso ocorre devido à interpolação usado no bucket.
Como o cálculo da classificação superior de um bucket é realizado em segundo plano por meio de um job programado, é possível atualizar as pontuações do jogador sem a necessidade de manter os dados do bucket sincronizados. Portanto, a capacidade de atualização das pontuações dos jogadores não é limitada por essa abordagem.
Contras
É preciso levar em consideração o tempo necessário para contar as pontuações de todos os jogadores, calcular as classificações globais e atualizar os buckets. Nos nossos testes, com uma população de 10 milhões de jogadores, o nosso sistema de testes no App Engine demorou 8 minutos e 34 segundos. Isso foi mais rápido do que as horas que seriam necessárias para calcular a classificação de cada jogador. Porém, a desvantagem é a aproximação das pontuações dentro de cada bucket. Por outro lado, o algoritmo em árvore calcula os "conjuntos de intervalos" (o node no topo da árvore) progressivamente a cada poucos segundos. No entanto, a implementação é mais complexa e a capacidade é limitada.
Em todos os casos, o tempo para FindRank também depende da recuperação rápida de dados (buckets ou nós da árvore) do Memcache. Se os dados forem removidos do Memcache, eles deverão ser recuperados novamente do Datastore e armazenados em cache outra vez para as solicitações FindRank subsequentes.
Precisão
A precisão do método de buckets depende de quantos buckets existem, da classificação do jogador e da distribuição das pontuações. A Figura 9 mostra os resultados do nosso estudo sobre a precisão das estimativas de classificação com números diferentes de buckets.
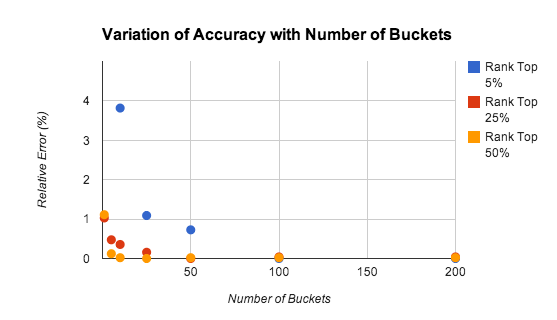
Realizamos os testes para uma população de 10.000 jogadores com pontuações distribuídas uniformemente no conjunto [0-9999]. O erro relativo está em cerca de 1%, mesmo ao usar somente cinco buckets.
A precisão diminui no caso dos jogadores com as melhores classificações, principalmente porque a lei dos grandes números não se aplica quando a análise é realizada apenas nas maiores pontuações. Em muitos casos, é aconselhável usar um algoritmo mais preciso para manter as classificações de mil a dois mil jogadores com as maiores pontuações. O problema é consideravelmente reduzido porque há menos jogadores para rastrear, e a taxa agregada de atualizações é proporcionalmente menor.
No teste acima, o uso de números aleatórios distribuídos de maneira uniforme, em que a função de distribuição cumulativa é linear, favorece o uso da interpolação linear dentro do bucket. No entanto, a interpolação dentro dos buckets funciona satisfatoriamente para qualquer distribuição densa de pontuações. A Figura 10 mostra a classificação estimada e real de uma distribuição aproximadamente normal de pontuações.
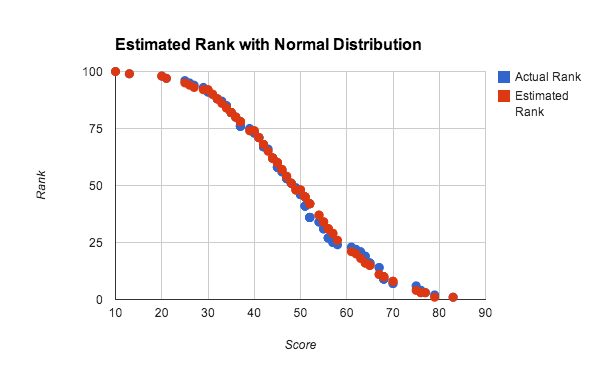
Nesse experimento, usamos uma população de 100 jogadores para testar a precisão com um grupo pequeno de dados. Cada pontuação foi gerada pelo cálculo da média de quatro números aleatórios entre 0 e 100, o que se aproxima de uma distribuição normal de pontuações. A classificação estimada foi calculada por meio do método de consulta global com interpolação linear em dez buckets. É possível observar que os resultados são bons, mesmo em grupos muito pequenos de dados e distribuições não uniformes.