Cloud Monitoring では、クラウドで実行されるアプリケーションのパフォーマンスや稼働時間、全体的な動作状況を確認できます。Google Cloud のオペレーション スイートは、Dataproc クラスタから指標、イベント、メタデータを収集し、取り込むことで、ダッシュボード、グラフ、アラートを介してクラスタごとの HDFS、YARN、ジョブ、オペレーション指標などの分析情報を提供します(Cloud Monitoring Dataproc の指標をご覧ください)。
Dataproc クラスタのパフォーマンスと動作状況をモニタリングするには、Cloud Monitoring クラスタの指標を使用します。
コストを確認するには、Cloud Monitoring の料金をご覧ください。
指標データの保存については、Monitoring の割り当てと制限をご覧ください。
Dataproc クラスタの指標
Dataproc は、Monitoring で表示できるクラスタ リソース指標を収集します。
クラスタ指標を表示
Google Cloud Console または Monitoring API から Monitoring を確認できます。
コンソール
-
クラスタを作成したら、Google Cloud コンソールで [Monitoring] に移動して、クラスタのモニタリング データを表示します。
Monitoring Console が表示されたら、追加の設定手順として、プロジェクト内の VM に Monitoring エージェントをインストールできます。この手順は Dataproc クラスタを作成するときに自動的に実行されるため、Dataproc クラスタの VM にエージェントをインストールする必要はありません。
- [Metrics Explorer] を選択し、[Find resource type and metric] プルダウン リストから [Cloud Dataproc Cluster] リソースを選択します(または、ボックスに「cloud_dataproc_cluster」と入力します)。

- 入力ボックスをもう一度クリックし、プルダウン リストから指標を選択します。
次のスクリーンショットでは、「YARN memory size」が選択されています。指標名にカーソルを合わせると、指標に関する情報が表示されます。
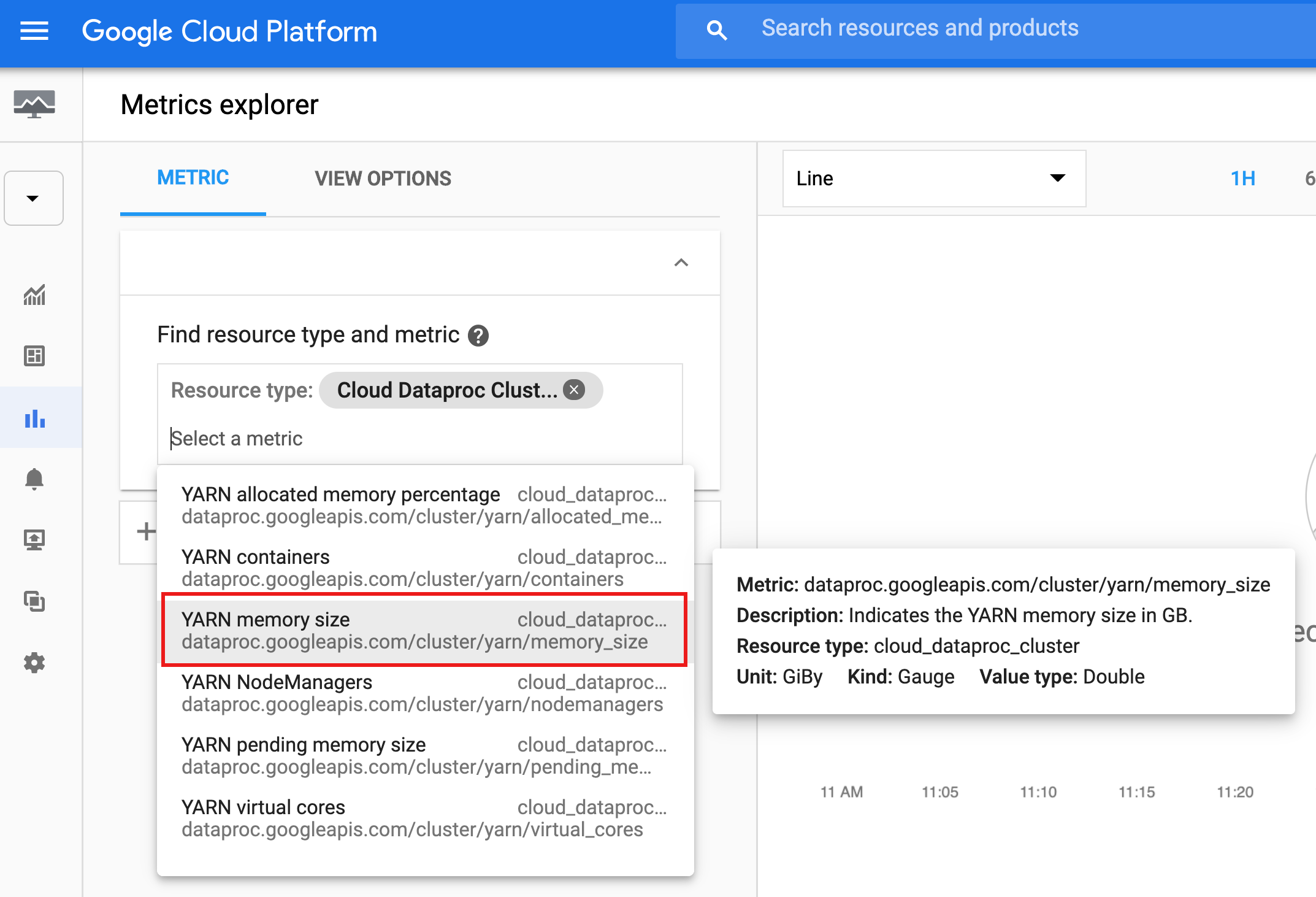
フィルタの選択、指標ラベルによるグループ化、集計、グラフ表示オプションの選択を行えます(Monitoring ドキュメントを参照)。
API
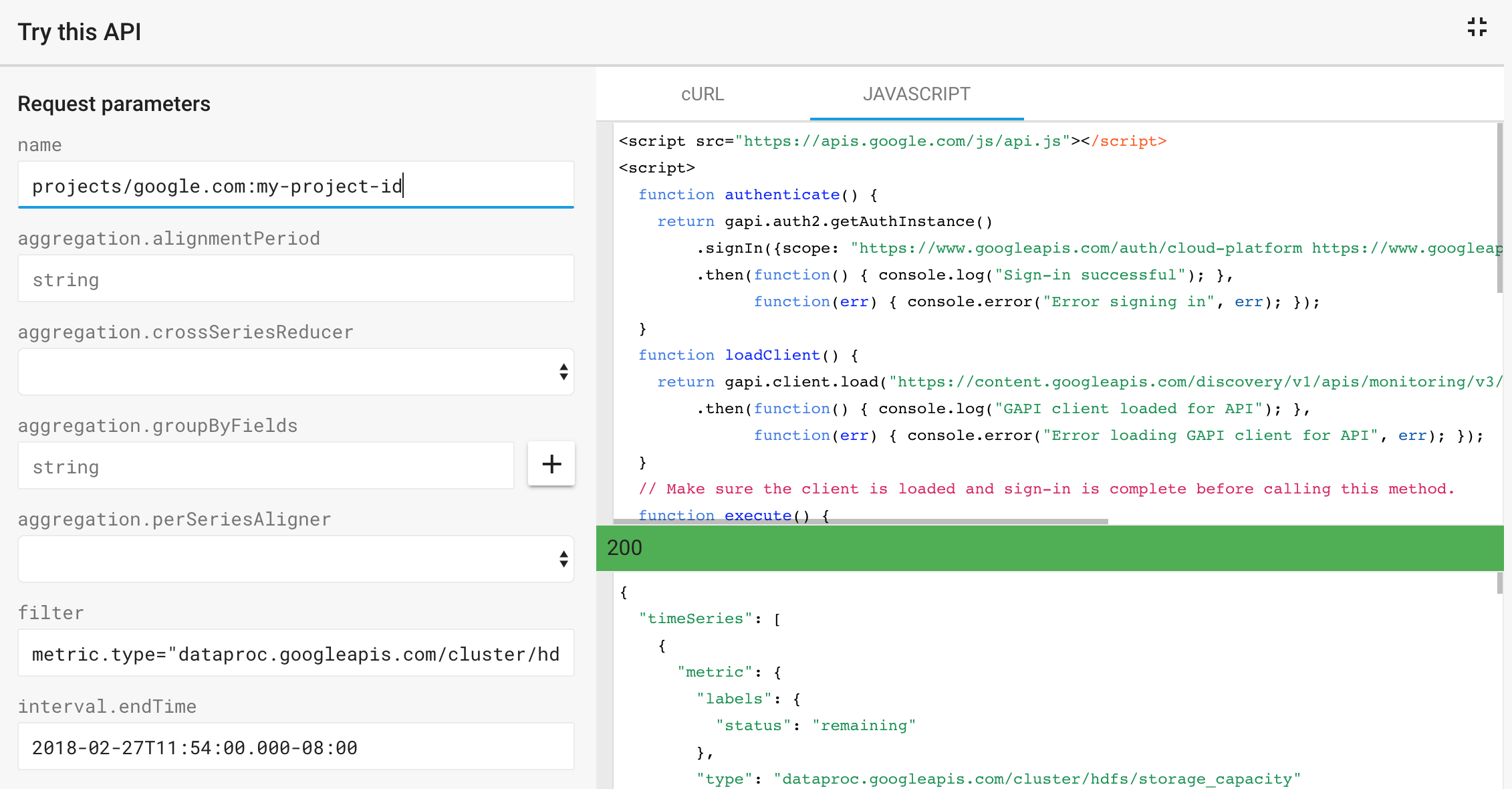
Monitoring の timeSeries.list API を使用して、filter 式で定義された指標を取得し、一覧表示できます。API ページの [この API を試す] テンプレートを使用して、API リクエストを送信し、レスポンスを表示します。
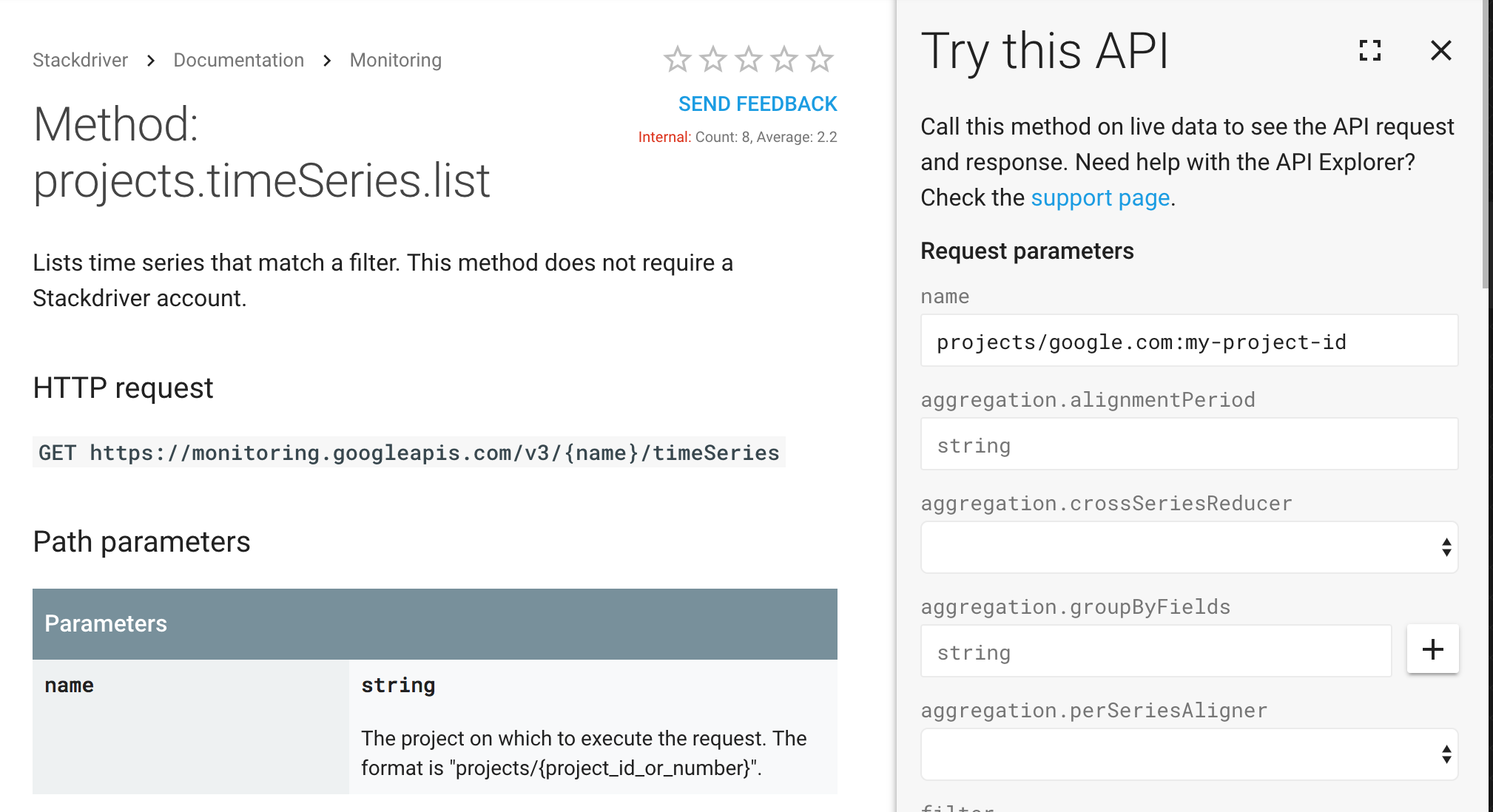
例: これは、次の Monitoring timeSeries.list パラメータに対して返された JSON レスポンスと、テンプレート リクエストのスナップショットです。
- name: projects/example-project-id
- filter: metric.type="dataproc.googleapis.com/cluster/hdfs/storage_capacity"
- interval.endTime: 2018-02-27T11:54:00.000-08:00
- interval.startTime: 2018-02-20T00:00:00.000-08:00
OSS 指標
Dataproc で、Monitoring に表示するクラスタ OSS コンポーネントの指標を収集できます。Dataproc OSS の指標は、次の形式で収集されます。
custom.googleapis.com/OSS_COMPONENT/METRIC。
OSS 指標の例:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
利用可能な OSS 指標
Dataproc を有効にすると、次の表に示す OSS 指標を収集できます。関連付けられた指標ソースを有効にするときに Dataproc がデフォルトで指標を収集する場合、[Collected by default] 列は「y」とマークされます。指標ソースに指定されたすべての指標と、すべての Spark 指標は、指標ソースのデフォルトの指標のコレクションをオーバーライドすると、収集に対して有効にできます(OSS 指標の収集を有効にするをご覧ください)。
Hadoop 指標
HDFS の指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartbeats | dfs/FSNamesystem/ExpiredHeartbeats | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastCheckpoint | dfs/FSNamesystem/TransactionsSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastLogRoll | dfs/FSNamesystem/TransactionsSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWrittenTransactionId | dfs/FSNamesystem/LastWrittenTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduledReplicationBlocks | dfs/FSNamesystem/ScheduledReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExcessBlocks | dfs/FSNamesystem/ExcessBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisreplicatedBlocks | dfs/FSNamesystem/PostponedMisreplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
YARN 指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNMs | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNMs | yarn/ClusterMetrics/NumDecommissionedNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNMs | yarn/ClusterMetrics/NumUnhealthyNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNMs | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AllocatedMB | yarn/QueueMetrics/AllocatedMB | n |
| yarn:ResourceManager:QueueMetrics:AllocatedVCores | yarn/QueueMetrics/AllocatedVCores | n |
| yarn:ResourceManager:QueueMetrics:AllocatedContainers | yarn/QueueMetrics/AllocatedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAllocated | yarn/QueueMetrics/AggregateContainersAllocated | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedMB | yarn/QueueMetrics/ReservedMB | n |
| yarn:ResourceManager:QueueMetrics:ReservedVCores | yarn/QueueMetrics/ReservedVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedContainers | yarn/QueueMetrics/ReservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Spark の指標
Spark ドライバの指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJobs | spark/driver/DAGScheduler/job/allJobs | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Spark エグゼキュータの指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWritten | spark/executor/bytesWritten | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWritten | spark/executor/recordsWritten | y |
| spark:executor:executor:runTime | spark/executor/runTime | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWritten | spark/executor/shuffleRecordsWritten | y |
Spark 履歴サーバーの指標
Dataproc は、次の Spark 履歴サービスの JVM メモリ指標を収集します。
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
HiveServer 2 の指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.committed | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.committed | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Hive メタストア指標
| 指標 | Metrics Explorer 名 | デフォルトで収集 |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:Mean | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:Mean | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_names/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Hive メタストア指標の測定値
| 統計的測定値 | 指標の例 | 指標名の例 |
|---|---|---|
| 最大 | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| 最小 | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| 平均 | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| カウント | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 50 パーセンタイル | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 75 パーセンタイル | hivemetastore:API:GetDatabase:75thPercentile | hivemetastore/get_database/75th_percentile |
| 95 パーセンタイル | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95th_percentile |
| 98 パーセンタイル | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/98th_percentile |
| 99 パーセンタイル | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 999 パーセンタイル | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| 標準偏差 | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| 15 分レート | hivemetastore:API:GetDatabase:FifteenMinuteRate | hivemetastore/get_database/15min_rate |
| 5 分レート | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| 1 分レート | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| 平均レート | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Dataproc モニタリング エージェントの指標
デフォルトでは、Dataproc は agent.googleapis.com 接頭辞でパブリッシュされる次の Dataproc モニタリング エージェントのデフォルト指標を収集します。
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
ディスク
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
agent.googleapis.com/disk/read_bytes_count
スワップ
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
メモリー
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
プロセス - (一部の属性ではわずかに異なる割り当てポリシーに従います)
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/process/fork_count
agent.googleapis.com/processes/rss_usage
agent.googleapis.com/processes/vm_usage
インターフェース
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
ネットワーク
agent.googleapis.com/network/tcp_connections
OSS 指標の収集を有効にする
Dataproc クラスタを作成する際、gcloud CLI または Dataproc API を使用して、次の 2 つの方法で OSS 指標の収集を有効にできます。
- 1 つ以上の OSS 指標のソースからデフォルトの指標のみの収集を有効にします
- 1 つ以上の OSS 指標のソースから指定された「オーバーライド」指標のみの収集を有効にします
gcloud コマンド
デフォルトの指標収集
gcloud dataproc clusters create --metric-sources フラグを使用して、1 つ以上の指標ソースからデフォルトの利用可能な OSS 指標の収集を有効にします。
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
注:
--metric-sources: デフォルトの指標収集を有効にするために必要です。指標のソースとしてspark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore、monitoring-agent-defaultsを 1 つ以上指定します。指標のソース名は大文字と小文字が区別されません(たとえば、「yarn」または「YARN」のいずれかが許容されます)。
指標の収集をオーバーライドする
--metric-overrides フラグまたは --metric-overrides-file フラグを追加して、1 つ以上の指標ソースから 1 つ以上の利用可能な OSS 指標の収集を有効にします。
-
利用可能な OSS 指標とすべての Spark 指標は、指標オーバーライドとして収集用に表示されます。オーバーライド指標の値は大文字と小文字が区別され、必要に応じて CamelCase 形式で指定する必要があります。
例
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
指定した指標ソースからのみ、指定したオーバーライド指標のみが収集されます。たとえば、1 つ以上の
spark:executive指標が指標オーバーライドとしてリストされている場合、他のSPARK指標は収集されません。他の指標ソースからのデフォルトの OSS 指標の収集は影響を受けません。たとえば、SPARKとYARNの両方の指標ソースが有効で、Spark の指標に対してのみオーバーライドが指定されている場合、デフォルトの YARN 指標がすべて収集されます。 -
指定した指標のオーバーライドのソースを有効にする必要があります。たとえば、1 つ以上の
spark:driver指標が指標オーバーライドとして指定されている場合は、spark指標ソースを有効にする必要があります(--metric-sources=spark)。
指標リストをオーバーライドする
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
注:
--metric-sources: デフォルトの指標収集を有効にするために必要です。指標のソースとしてspark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore、monitoring-agent-defaultsを 1 つ以上指定します。指標のソース名は大文字と小文字が区別されません。たとえば、「yarn」または「YARN」のいずれかが許容されます。--metric-overrides: 指標のリストを次の形式で指定します。METRIC_SOURCE:INSTANCE:GROUP:METRIC
例:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed- このフラグは
--metric-overrides-fileフラグに代わるもので、使用できません。
指標ファイルをオーバーライドする
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
注:
-
--metric-sources: デフォルトの指標収集を有効にするために必要です。 指標のソースとしてspark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore、monitoring-agent-defaultsを 1 つ以上指定します。指標のソース名は大文字と小文字が区別されません。たとえば、「yarn」または「YARN」のいずれかが許容されます。 -
--metric-overrides-file: 次の形式で 1 つ以上の指標を含むローカルまたは Cloud Storage ファイル(gs://bucket/filename)を指定します。METRIC_SOURCE:INSTANCE:GROUP:METRIC
必要に応じてキャメルケース形式を使用します。例
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txt
- このフラグは
--metric-overridesフラグに代わるもので、使用できません。
REST API
clusters.create リクエストの一部として DataprocMetricConfig を使用して、OSS 指標の収集を有効にします。
Monitoring ダッシュボードの構築
選択した Cloud Dataproc クラスタ指標のグラフを表示するカスタム Monitoring ダッシュボードを構築できます。
Monitoring の [ダッシュボードの概要] ページから [+ Create Dashboard] を選択します。ダッシュボードの名前を入力し、右上にあるメニューで [Add Chart] をクリックして、[Add Chart] ウィンドウを開きます。リソースタイプとして [Cloud Dataproc Cluster] を選択します。 1 つ以上の指標と、指標およびチャートのプロパティを選択します。グラフを保存します。

ダッシュボードにグラフを追加できます。ダッシュボードを保存すると、そのタイトルが Monitoring の [ダッシュボードの概要] ページに表示されます。ダッシュボードのグラフは、ダッシュボード表示ページから表示、更新、削除ができます。
次のステップ
- Cloud Monitoring のドキュメントを読む
- Dataproc 指標アラートを作成する方法を学習する。