En este documento se describe cómo actualizar una tarea de streaming en curso. Puede que quiera actualizar su trabajo de Dataflow por los siguientes motivos:
- Quieres mejorar tu código de canalización.
- Quieres corregir errores en el código de tu canal.
- Quieres actualizar tu canalización para gestionar los cambios en el formato de los datos o para tener en cuenta los cambios de versión u otros cambios en tu fuente de datos.
- Quieres corregir una vulnerabilidad de seguridad relacionada con Container-Optimized OS en todos los trabajadores de Dataflow.
- Quieres escalar una canalización de streaming de Apache Beam para usar un número diferente de trabajadores.
Puedes actualizar los trabajos de dos formas:
- Actualización de tareas en curso: en el caso de las tareas de streaming que usan Streaming Engine, puedes actualizar las opciones de tarea
min-num-workersymax-num-workerssin detener la tarea ni cambiar su ID. - Tarea de sustitución: para ejecutar código de canalización actualizado o para actualizar opciones de tareas que no admiten las actualizaciones de tareas en curso, inicia una tarea nueva que sustituya a la tarea actual. Para verificar si un trabajo de sustitución es válido, valida su gráfico de trabajo antes de iniciar el nuevo trabajo.
Cuando actualizas un trabajo, el servicio Dataflow realiza una comprobación de compatibilidad entre el trabajo que se está ejecutando y el trabajo de sustitución potencial. La comprobación de compatibilidad asegura que se pueda transferir información como el estado intermedio y los datos almacenados en búfer de la tarea anterior a la de sustitución.
También puedes usar la infraestructura de registro integrada del SDK de Apache Beam para registrar información cuando actualices tu trabajo. Para obtener más información, consulta el artículo sobre cómo trabajar con registros de canalizaciones.
Para identificar problemas con el código de la canalización, usa el DEBUGnivel de registro.
- Para obtener instrucciones sobre cómo actualizar los trabajos de streaming que usan plantillas clásicas, consulta Actualizar un trabajo de streaming con una plantilla personalizada.
- Para obtener instrucciones sobre cómo actualizar los trabajos de streaming que usan plantillas flexibles, sigue las instrucciones de la CLI de gcloud que se indican en esta página o consulta el artículo Actualizar un trabajo de plantilla flexible.
Actualización de la opción de trabajo en curso
En el caso de las tareas de streaming que usan Streaming Engine, puedes actualizar las siguientes opciones de la tarea sin detenerla ni cambiar su ID:
min-num-workers: número mínimo de instancias de Compute Engine.max-num-workers: número máximo de instancias de Compute Engine.worker-utilization-hint: el uso de CPU objetivo, en el intervalo [0,1, 0,9]
Para otras actualizaciones de trabajos, debes sustituir el trabajo actual por el actualizado. Para obtener más información, consulta Lanzar un trabajo de sustitución.
Realizar una actualización durante el vuelo
Para actualizar una opción de trabajo en curso, sigue estos pasos.
gcloud
Usa el comando gcloud dataflow jobs update-options:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
Haz los cambios siguientes:
- REGION: el ID de la región del trabajo
- MINIMUM_WORKERS: número mínimo de instancias de Compute Engine
- MAXIMUM_WORKERS: número máximo de instancias de Compute Engine
- TARGET_UTILIZATION: un valor en el intervalo [0,1; 0,9]
- JOB_ID: el ID del trabajo que se va a actualizar
También puedes actualizar --min-num-workers, --max-num-workers y worker-utilization-hint por separado.
REST
Usa el método projects.locations.jobs.update:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
Haz los cambios siguientes:
- MASK: lista de parámetros separados por comas que se van a actualizar, de entre los siguientes:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: el Google Cloud ID de proyecto de la tarea de Dataflow
- REGION: el ID de la región del trabajo
- JOB_ID: el ID del trabajo que se va a actualizar
- MINIMUM_WORKERS: número mínimo de instancias de Compute Engine
- MAXIMUM_WORKERS: número máximo de instancias de Compute Engine
- TARGET_UTILIZATION: un valor en el intervalo [0,1; 0,9]
También puedes actualizar min_num_workers, max_num_workers y worker_utilization_hint por separado.
Especifica qué parámetros quieres actualizar en el parámetro de consulta updateMask e incluye los valores actualizados en el campo runtimeUpdatableParams del cuerpo de la solicitud. En el siguiente ejemplo se actualiza min_num_workers:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
Para poder recibir actualizaciones durante el proceso, el trabajo debe estar en estado de ejecución. Se produce un error si la tarea no se ha iniciado o ya se ha cancelado. Del mismo modo, si inicias un trabajo de sustitución, espera a que empiece a ejecutarse antes de enviar actualizaciones durante el proceso al nuevo trabajo.
Después de enviar una solicitud de actualización, le recomendamos que espere a que se complete antes de enviar otra. Consulta los registros de la tarea para ver cuándo se completa la solicitud.
Validar un trabajo de sustitución
Para verificar si un trabajo de sustitución es válido, antes de iniciar el nuevo trabajo, valida su gráfico de trabajo. En Dataflow, un gráfico de tareas es una representación gráfica de un flujo de procesamiento. Al validar el gráfico de la tarea, se reduce el riesgo de que la canalización tenga errores o falle después de la actualización. Además, puedes validar las actualizaciones sin tener que detener el trabajo original, por lo que no se producirá ningún tiempo de inactividad.
Para validar tu gráfico de trabajo, sigue los pasos para iniciar un trabajo de sustitución. Incluye la graph_validate_only
opción de servicio de Dataflow en el comando de actualización.
Java
- Pasa la opción
--update. - Define la opción
--jobNameenPipelineOptionscon el mismo nombre que el trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Incluye la opción de servicio
--dataflowServiceOptions=graph_validate_only. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transformNameMapping. - Si vas a enviar una tarea de sustitución que usa una versión posterior del SDK de Apache Beam, asigna a
--updateCompatibilityVersionla versión del SDK de Apache Beam que se usó en la tarea original.
Python
- Pasa la opción
--update. - Define la opción
--job_nameenPipelineOptionscon el mismo nombre que el trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Incluye la opción de servicio
--dataflow_service_options=graph_validate_only. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform_name_mapping. - Si vas a enviar una tarea de sustitución que usa una versión posterior del SDK de Apache Beam, asigna a
--updateCompatibilityVersionla versión del SDK de Apache Beam que se usó en la tarea original.
Go
- Pasa la opción
--update. - Asigna a la opción
--job_nameel mismo nombre que el del trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Incluye la opción de servicio
--dataflow_service_options=graph_validate_only. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform_name_mapping.
gcloud
Para validar el gráfico de tareas de una tarea de plantilla flex, usa el comando
gcloud dataflow flex-template run
con la opción additional-experiments:
- Pasa la opción
--update. - Asigna a JOB_NAME el mismo nombre que el trabajo que quieras actualizar.
- Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Incluye la opción
--additional-experiments=graph_validate_only. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform-name-mappings.
Por ejemplo:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
Sustituye JOB_NAME por el nombre del trabajo que quieras actualizar.
REST
Usa el campo additionalExperiments en el objeto
FlexTemplateRuntimeEnvironment
(plantillas Flex) o
RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
La opción de servicio graph_validate_only solo valida las actualizaciones de la canalización. No utilices esta opción al crear o iniciar flujos de trabajo. Para actualizar tu flujo de procesamiento, inicia una tarea de sustitución sin la opción de servicio graph_validate_only.
Cuando la validación del gráfico de tareas se realiza correctamente, el estado de la tarea y los registros de la tarea muestran los siguientes estados:
- El estado del trabajo es
JOB_STATE_DONE. - En la Google Cloud consola, el estado del trabajo
es
Succeeded. Aparece el siguiente mensaje en los registros de trabajos:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
Si falla la validación del gráfico de tareas, el estado de la tarea y los registros de la tarea mostrarán los siguientes estados:
- El estado del trabajo es
JOB_STATE_FAILED. - En la Google Cloud consola, el estado del trabajo
es
Failed. - Aparecerá un mensaje en los registros de trabajos en el que se describirá el error de incompatibilidad. El contenido del mensaje depende del error.
Iniciar una tarea de sustitución
Puede que sustituyas una tarea por los siguientes motivos:
- Para ejecutar el código de la canalización actualizada.
- Para actualizar las opciones de las tareas que no admiten actualizaciones en tiempo real.
Para verificar si un trabajo de sustitución es válido, antes de iniciar el nuevo trabajo, valida su gráfico de trabajo.
Cuando inicies un trabajo de sustitución, define las siguientes opciones de flujo de procesamiento para llevar a cabo el proceso de actualización, además de las opciones habituales del trabajo:
Java
- Pasa la opción
--update. - Define la opción
--jobNameenPipelineOptionscon el mismo nombre que el trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transformNameMapping. - Si vas a enviar una tarea de sustitución que usa una versión posterior del SDK de Apache Beam, asigna a
--updateCompatibilityVersionla versión del SDK de Apache Beam que se usó en la tarea original.
Python
- Pasa la opción
--update. - Define la opción
--job_nameenPipelineOptionscon el mismo nombre que el trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform_name_mapping. - Si vas a enviar una tarea de sustitución que usa una versión posterior del SDK de Apache Beam, asigna a
--updateCompatibilityVersionla versión del SDK de Apache Beam que se usó en la tarea original.
Go
- Pasa la opción
--update. - Asigna a la opción
--job_nameel mismo nombre que el del trabajo que quieras actualizar. - Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform_name_mapping.
gcloud
Para actualizar un trabajo de plantilla Flex mediante la CLI de gcloud, usa el comando
gcloud dataflow flex-template run. No se pueden actualizar otros trabajos mediante la CLI de gcloud.
- Pasa la opción
--update. - Asigna a JOB_NAME el mismo nombre que el trabajo que quieras actualizar.
- Define la opción
--regionen la misma región que la del trabajo que quieras actualizar. - Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante la opción
--transform-name-mappings.
REST
En estas instrucciones se explica cómo actualizar trabajos que no son de plantilla mediante la API REST. Para usar la API REST y actualizar un trabajo de plantilla clásica, consulta Actualizar un trabajo de streaming de plantilla personalizada. Para usar la API REST y actualizar un trabajo de plantilla flex, consulta Actualizar un trabajo de plantilla flex.
Obtén el recurso
jobdel trabajo que quieras sustituir con el métodoprojects.locations.jobs.get. Incluya el parámetro de consultaviewcon el valorJOB_VIEW_DESCRIPTION. Al incluirJOB_VIEW_DESCRIPTION, se limita la cantidad de datos de la respuesta para que la solicitud posterior no supere los límites de tamaño. Si necesitas información más detallada sobre el trabajo, usa el valorJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONSustituye los siguientes valores:
- PROJECT_ID: el Google Cloud ID de proyecto de la tarea de Dataflow
- REGION: la región del trabajo que quieras actualizar
- JOB_ID: el ID del trabajo que quieres actualizar
Para actualizar el trabajo, usa el método
projects.locations.jobs.create. En el cuerpo de la solicitud, usa el recursojobque has obtenido.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }Haz los cambios siguientes:
- JOB_ID: el mismo ID de trabajo que el del trabajo que quiere actualizar.
- JOB_NAME: el mismo nombre del puesto que el del puesto que quieras actualizar.
Si ha cambiado algún nombre de transformación en su canalización, debe proporcionar una asignación de transformaciones y pasarla mediante el campo
transformNameMapping.Opcional: Para enviar tu solicitud con curl (Linux, macOS o Cloud Shell), guarda la solicitud en un archivo JSON y, a continuación, ejecuta el siguiente comando:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsSustituye FILE_PATH por la ruta al archivo JSON que contiene el cuerpo de la solicitud.
Especifica el nombre de la tarea de sustitución
Java
Cuando inicies el trabajo de sustitución, el valor que pases para la opción --jobName
debe coincidir exactamente con el nombre del trabajo que quieras sustituir.
Python
Cuando inicies el trabajo de sustitución, el valor que pases para la opción --job_name
debe coincidir exactamente con el nombre del trabajo que quieras sustituir.
Go
Cuando inicies el trabajo de sustitución, el valor que pases para la opción --job_name
debe coincidir exactamente con el nombre del trabajo que quieras sustituir.
gcloud
Cuando inicies el trabajo de sustitución, el JOB_NAME debe coincidir exactamente con el nombre del trabajo que quieras sustituir.
REST
Asigna al campo replaceJobId el mismo ID de tarea que la tarea que quieras actualizar. Para encontrar el valor correcto del nombre de la tarea, selecciona la tarea anterior en la interfaz de monitorización de Dataflow.
A continuación, en el panel lateral Información del trabajo, busca el campo ID de trabajo.
Para encontrar el valor correcto del nombre de la tarea, selecciona la tarea anterior en la interfaz de monitorización de Dataflow. A continuación, en el panel lateral Información del trabajo, busca el campo Nombre del trabajo:
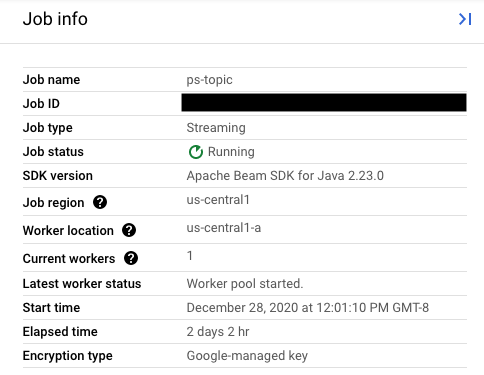
También puedes consultar una lista de las tareas que ya tienes mediante la interfaz de línea de comandos de Dataflow.
Introduce el comando gcloud dataflow jobs list en tu shell o ventana de terminal para obtener una lista de las tareas de Dataflow de tu proyecto de Google Cloud Platform y busca el campo NAME de la tarea que quieras sustituir:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
Crear una asignación de transformación
Si la canalización de sustitución cambia algún nombre de transformación de los nombres de la canalización anterior, el servicio Dataflow requiere una asignación de transformaciones. La asignación de transformaciones asigna las transformaciones con nombre de tu código de la canalización anterior a los nombres de tu código de la canalización de sustitución.
Java
Transfiere la asignación mediante la opción de línea de comandos --transformNameMapping con el siguiente formato general:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Solo tiene que proporcionar entradas de asignación en --transformNameMapping para los nombres de transformación que hayan cambiado entre su canal anterior y el canal de sustitución.
Cuando ejecutes --transformNameMapping, puede que tengas que usar el carácter de escape para las comillas según tu shell. Por ejemplo, en Bash:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
Transfiere la asignación mediante la opción de línea de comandos --transform_name_mapping con el siguiente formato general:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Solo tiene que proporcionar entradas de asignación en --transform_name_mapping para los nombres de transformación que hayan cambiado entre su canal anterior y el canal de sustitución.
Cuando ejecutes --transform_name_mapping, puede que tengas que usar el carácter de escape para las comillas según tu shell. Por ejemplo, en Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
Transfiere la asignación mediante la opción de línea de comandos --transform_name_mapping con el siguiente formato general:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Solo tiene que proporcionar entradas de asignación en --transform_name_mapping para los nombres de transformación que hayan cambiado entre su canal anterior y el canal de sustitución.
Cuando ejecutes --transform_name_mapping, puede que tengas que usar el carácter de escape para las comillas según tu shell. Por ejemplo, en Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
Transfiere la asignación mediante la opción --transform-name-mappings
con el siguiente formato general:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Solo tiene que proporcionar entradas de asignación en --transform-name-mappings para los nombres de transformación que hayan cambiado entre su canal anterior y el canal de sustitución.
Cuando ejecutes --transform-name-mappings,
puede que tengas que usar el carácter de escape para las comillas según tu shell. Por ejemplo, en Bash:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
Transfiere la asignación mediante el campo transformNameMapping
con el siguiente formato general:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
Solo tiene que proporcionar entradas de asignación en transformNameMapping para los nombres de transformación que hayan cambiado entre su canal anterior y el canal de sustitución.
Determinar los nombres de las transformaciones
El nombre de la transformación de cada instancia del mapa es el nombre que proporcionaste al aplicar la transformación en tu canalización. Por ejemplo:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
También puede obtener los nombres de las transformaciones de su trabajo anterior examinando el gráfico de ejecución del trabajo en la interfaz de monitorización de Dataflow:
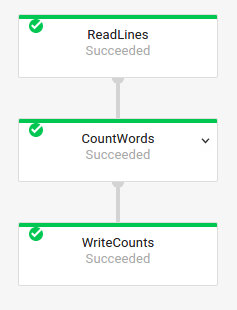
Nombres de las transformaciones compuestas
Los nombres de las transformaciones son jerárquicos y se basan en la jerarquía de transformaciones de tu
pipeline. Si tu canal tiene una transformación compuesta, las transformaciones anidadas se denominan en función de la transformación que las contiene. Por ejemplo, supongamos que tu canalización contiene una transformación compuesta llamada CountWidgets, que contiene una transformación interna llamada Parse. El nombre completo de tu transformación es CountWidgets/Parse y debes especificarlo en la asignación de la transformación.
Si la nueva canalización asigna una transformación compuesta a otro nombre, todas las transformaciones anidadas también se renombrarán automáticamente. Debe especificar los nombres modificados de las transformaciones internas en la asignación de transformaciones.
Refactorizar la jerarquía de transformación
Si tu canalización de sustitución usa una jerarquía de transformación diferente a la de tu canalización anterior, debes declarar explícitamente la asignación. Es posible que tengas una jerarquía de transformaciones diferente porque has refactorizado tus transformaciones compuestas o porque tu canal depende de una transformación compuesta de una biblioteca que ha cambiado.
Por ejemplo, tu anterior flujo de trabajo aplicó una transformación compuesta, CountWidgets,
que contenía una transformación interna llamada Parse. La canalización de sustitución refactoriza CountWidgets y anida Parse en otra transformación llamada Scan. Para que la actualización se realice correctamente, debe asignar explícitamente el nombre completo de la transformación en la canalización anterior (CountWidgets/Parse) al nombre de la transformación en la nueva canalización (CountWidgets/Scan/Parse):
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si eliminas una transformación por completo en tu canalización de sustitución, debes proporcionar una asignación nula. Supongamos que tu flujo de procesamiento de sustitución elimina por completo la transformación CountWidgets/Parse:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si eliminas una transformación por completo en tu canalización de sustitución, debes proporcionar una asignación nula. Supongamos que tu flujo de procesamiento de sustitución elimina por completo la transformación CountWidgets/Parse:
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
Si eliminas una transformación por completo en tu canalización de sustitución, debes proporcionar una asignación nula. Supongamos que tu flujo de procesamiento de sustitución elimina por completo la transformación CountWidgets/Parse:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si eliminas una transformación por completo en tu canalización de sustitución, debes proporcionar una asignación nula. Supongamos que tu flujo de procesamiento de sustitución elimina por completo la transformación CountWidgets/Parse:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
Si eliminas una transformación por completo en tu canalización de sustitución, debes proporcionar una asignación nula. Supongamos que tu flujo de procesamiento de sustitución elimina por completo la transformación CountWidgets/Parse:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
Efectos de sustituir un trabajo
Cuando sustituyes un trabajo, se ejecuta un nuevo trabajo con el código de la canalización actualizado. El servicio Dataflow conserva el nombre de la tarea, pero ejecuta la tarea de sustitución con un ID de tarea actualizado. Este proceso puede provocar un tiempo de inactividad mientras se detiene el trabajo actual, se ejecuta la comprobación de compatibilidad y se inicia el nuevo trabajo.
La tarea de sustitución conserva los siguientes elementos:
- Datos de estado intermedio del trabajo anterior. Las cachés en memoria no se guardan.
- Registros de datos almacenados en búfer o metadatos "en tránsito" del trabajo anterior. Por ejemplo, algunos registros de tu canalización pueden almacenarse en búfer mientras esperan a que se resuelva una ventana.
- Actualizaciones de las opciones de la tarea en curso que hayas aplicado a la tarea anterior.
Datos de estado intermedio
Se conservan los datos de estado intermedio del trabajo anterior. Los datos de estado no incluyen las cachés en memoria. Si quieres conservar los datos de la caché en memoria al actualizar tu canalización, puedes refactorizarla para convertir las cachés en datos de estado o en entradas secundarias. Para obtener más información sobre el uso de entradas secundarias, consulta los patrones de entrada secundaria en la documentación de Apache Beam.
Las canalizaciones de streaming tienen límites de tamaño para ValueState y para las entradas secundarias.
Por lo tanto, si tienes cachés grandes que quieres conservar, es posible que tengas que usar almacenamiento externo, como Memorystore o Bigtable.
Datos durante el vuelo
Los datos en tránsito siguen procesándose mediante las transformaciones de la nueva canalización. Sin embargo, es posible que las transformaciones adicionales que añadas en el código de la canalización de sustitución se apliquen o no, en función de dónde se almacenen en búfer los registros. En este ejemplo, tu canalización tiene las siguientes transformaciones:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
Puedes sustituir el trabajo por un nuevo código de la siguiente manera:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
Aunque añadas una transformación para filtrar las cadenas que empiezan por la letra "A", la siguiente transformación (FormatStrings) podría seguir viendo cadenas almacenadas en búfer o en tránsito que empiezan por "A" y que se han transferido del trabajo anterior.
Cambiar el acoplamiento de ventanas
Puedes cambiar las estrategias de ventanas
y activadores
de los elementos PCollection de tu canalización de sustitución, pero ten cuidado.
Cambiar las estrategias de ventana o de activación no afecta a los datos que ya se han almacenado en el búfer o que están en tránsito.
Te recomendamos que solo intentes hacer cambios pequeños en las ventanas de tu canal, como cambiar la duración de las ventanas de tiempo fijas o deslizantes. Si haces cambios importantes en las ventanas o los activadores, como cambiar el algoritmo de las ventanas, es posible que los resultados de tu canalización sean impredecibles.
Comprobación de compatibilidad de tareas
Cuando inicies la tarea de sustitución, el servicio Dataflow comprobará la compatibilidad entre la tarea de sustitución y la anterior. Si la comprobación de compatibilidad se supera, se detendrá el trabajo anterior. La tarea de sustitución se inicia en el servicio Dataflow y conserva el mismo nombre. Si la comprobación de compatibilidad falla, el trabajo anterior seguirá ejecutándose en el servicio Dataflow y el trabajo de sustitución devolverá un error.
Java
Debido a una limitación, debes usar la ejecución de bloqueo para ver los errores de intentos de actualización fallidos en tu consola o terminal. La solución alternativa actual consta de los siguientes pasos:
- Usa pipeline.run().waitUntilFinish() en el código de tu flujo de procesamiento.
- Ejecuta el programa de sustitución de la canalización con la opción
--update. - Espera a que la tarea de sustitución supere la comprobación de compatibilidad.
- Para salir del proceso de bloqueo, escribe
Ctrl+C.
También puedes monitorizar el estado de tu trabajo de sustitución en la interfaz de monitorización de Dataflow. Si el trabajo se ha iniciado correctamente, también ha superado la comprobación de compatibilidad.
Python
Debido a una limitación, debes usar la ejecución de bloqueo para ver los errores de intentos de actualización fallidos en tu consola o terminal. La solución alternativa actual consta de los siguientes pasos:
- Usa pipeline.run().wait_until_finish() en el código de tu canalización.
- Ejecuta el programa de sustitución de la canalización con la opción
--update. - Espera a que la tarea de sustitución supere la comprobación de compatibilidad.
- Para salir del proceso de bloqueo, escribe
Ctrl+C.
También puedes monitorizar el estado de tu trabajo de sustitución en la interfaz de monitorización de Dataflow. Si el trabajo se ha iniciado correctamente, también ha superado la comprobación de compatibilidad.
Go
Debido a una limitación, debes usar la ejecución de bloqueo para ver los errores de intentos de actualización fallidos en tu consola o terminal.
En concreto, debes especificar la ejecución sin bloqueo mediante las marcas --execute_async o --async. La solución alternativa actual consta de los siguientes pasos:
- Ejecuta el programa de la canalización de sustitución con la opción
--updatey sin las marcas--execute_asyncni--async. - Espera a que la tarea de sustitución supere la comprobación de compatibilidad.
- Para salir del proceso de bloqueo, escribe
Ctrl+C.
gcloud
Debido a una limitación, debes usar la ejecución de bloqueo para ver los errores de intentos de actualización fallidos en tu consola o terminal. La solución alternativa actual consta de los siguientes pasos:
- En las canalizaciones de Java, usa pipeline.run().waitUntilFinish() en el código de la canalización. En las canalizaciones de Python, usa pipeline.run().wait_until_finish() en el código de la canalización. En el caso de las canalizaciones de Go, sigue los pasos que se indican en la pestaña Go.
- Ejecuta el programa de sustitución de la canalización con la opción
--update. - Espera a que la tarea de sustitución supere la comprobación de compatibilidad.
- Para salir del proceso de bloqueo, escribe
Ctrl+C.
REST
Debido a una limitación, debes usar la ejecución de bloqueo para ver los errores de intentos de actualización fallidos en tu consola o terminal. La solución alternativa actual consta de los siguientes pasos:
- En las canalizaciones de Java, usa pipeline.run().waitUntilFinish() en el código de la canalización. En las canalizaciones de Python, usa pipeline.run().wait_until_finish() en el código de la canalización. En el caso de las canalizaciones de Go, sigue los pasos que se indican en la pestaña Go.
- Ejecuta el programa de la canalización de sustitución con el campo
replaceJobId. - Espera a que la tarea de sustitución supere la comprobación de compatibilidad.
- Para salir del proceso de bloqueo, escribe
Ctrl+C.
La comprobación de compatibilidad usa la asignación de transformación proporcionada para asegurarse de que Dataflow pueda transferir datos de estado intermedio de los pasos de tu trabajo anterior al trabajo de sustitución. La comprobación de compatibilidad también asegura que los PCollections de tu canalización usen los mismos codificadores.
Si se cambia un Coder, puede que la comprobación de compatibilidad falle porque es posible que los datos en tránsito o los registros almacenados en búfer no se serialicen correctamente en la canalización de sustitución.
Evitar problemas de compatibilidad
Algunas diferencias entre la canalización anterior y la de sustitución pueden provocar que falle la comprobación de compatibilidad. Entre estas diferencias, se incluyen las siguientes:
- Cambiar el gráfico de la canalización sin proporcionar una asignación. Cuando actualizas un trabajo, Dataflow intenta hacer coincidir las transformaciones del trabajo anterior con las del trabajo de sustitución. Este proceso de coincidencia ayuda a Dataflow a transferir datos de estado intermedio de cada paso. Si cambia el nombre o elimina algún paso, debe proporcionar una asignación de transformación para que Dataflow pueda asociar los datos de estado correctamente.
- Cambiar las entradas laterales de un paso Si añades entradas secundarias a una transformación de tu canalización de sustitución o las quitas, se producirá un error en la comprobación de compatibilidad.
- Cambiar el codificador de un paso Cuando actualizas una tarea, Dataflow conserva los registros de datos almacenados en búfer y los gestiona en la tarea de sustitución. Por ejemplo, los datos almacenados en búfer pueden producirse mientras se resuelve la ventana. Si el trabajo de sustitución usa una codificación de datos diferente o incompatible, Dataflow no podrá serializar ni deserializar estos registros.
Eliminar una operación con estado de tu canal. Si quitas operaciones con estado de tu canalización, es posible que el trabajo de sustitución no supere la comprobación de compatibilidad. Dataflow puede fusionar varios pasos para aumentar la eficiencia. Si quitas una operación dependiente del estado de dentro de un paso combinado, la comprobación fallará. Entre las operaciones con estado se incluyen las siguientes:
- Transformaciones que producen o consumen entradas secundarias.
- Lecturas de E/S.
- Transformaciones que usan el estado con clave.
- Transformaciones que tienen una fusión de ventanas.
Cambiar variables
DoFncon reconocimiento del estado. En el caso de los trabajos de streaming en curso, si tu canalización incluyeDoFns con estado, cambiar las variables de losDoFns con estado puede provocar un error en la canalización.Intentando ejecutar el trabajo de sustitución en otra zona geográfica. Ejecuta la tarea de sustitución en la misma zona en la que ejecutaste la tarea anterior.
Actualizar esquemas
Apache Beam permite que los PCollections tengan esquemas con campos con nombre, en cuyo caso no se necesitan codificadores explícitos. Si los nombres y los tipos de los campos de un esquema determinado no cambian (incluidos los campos anidados), ese esquema no provocará que falle la comprobación de la actualización. Sin embargo, es posible que la actualización siga bloqueada si otros segmentos de la nueva canalización no son compatibles.
Evolucionar esquemas
A menudo, es necesario desarrollar el esquema de un PCollection debido a la evolución de los requisitos empresariales. El servicio Dataflow permite hacer los siguientes cambios en un esquema al actualizar una canalización:
- Añadir uno o varios campos nuevos a un esquema, incluidos los campos anidados.
- Hacer que un tipo de campo obligatorio (no aceptable como valor nulo) sea opcional (aceptable como valor nulo).
No se permite quitar campos, cambiar sus nombres ni modificar sus tipos durante la actualización.
Transferir datos adicionales a una operación ParDo
Puedes transferir datos adicionales (fuera de banda) a una operación ParDo que ya exista mediante uno de los siguientes métodos, en función de tu caso práctico:
- Serializa la información como campos en tu subclase
DoFn. - Las variables a las que hacen referencia los métodos de un
DoFnanónimo se serializan automáticamente. - Computar datos en
DoFn.startBundle(). - Transfiere datos mediante
ParDo.withSideInputs.
Para obtener más información, consulta las siguientes páginas:
- Guía de programación de Apache Beam: ParDo, en concreto las secciones sobre cómo crear un DoFn y entradas secundarias.
- Referencia del SDK de Apache Beam para Java: ParDo