Dataflow ジョブを停止するには、Google Cloud コンソール、Cloud Shell、Google Cloud CLI がインストールされているローカル ターミナル、または Dataflow REST API のいずれかを使用します。
Dataflow ジョブは、次のいずれかの方法で停止できます。
ジョブをキャンセルする。この方法は、ストリーミング パイプラインとバッチ パイプラインの両方に適用されます。ジョブをキャンセルすると、Dataflow サービスはバッファデータなどのデータの処理を停止します。詳細については、ジョブをキャンセルするをご覧ください。
ジョブをドレインする。この方法は、ストリーミング パイプラインにのみ適用されます。ジョブをドレインすると、Dataflow サービスはバッファ内のデータの処理を完了すると同時に、新しいデータの取り込みを中止できます。詳細については、ジョブをドレインするをご覧ください。
ジョブを強制的にキャンセルする。この方法は、ストリーミング パイプラインとバッチ パイプラインの両方に適用されます。ジョブを強制的にキャンセルすると、Dataflow サービスはバッファデータなどのデータの処理を停止します。強制キャンセルを行う前に、まず通常のキャンセルを試す必要があります。強制キャンセルは、通常のキャンセル プロセスで先に進まないジョブにのみ行います。詳細については、ジョブの強制キャンセルをご覧ください。
ジョブをキャンセルすると、再開できません。Flex テンプレートを使用していない場合は、キャンセルされたパイプラインのクローンを作成し、そのクローンから新しいジョブを開始できます。
ストリーミング パイプラインを停止する前に、ジョブのスナップショットを作成することを検討してください。Dataflow スナップショットはストリーミング パイプラインの状態を保存します。これにより、Dataflow ジョブの新しいバージョンを、状態を保持したまま開始できます。詳細については、Dataflow スナップショットの使用をご覧ください。
複雑なパイプラインがある場合は、テンプレートを作成し、そのテンプレートからジョブを実行することを検討してください。
Dataflow ジョブは削除できませんが、完了したジョブはアーカイブできます。アーカイブされたジョブリスト内のジョブを含め、完了したジョブはすべて、30 日間の保持期間後に削除されます。
Dataflow ジョブをキャンセルする
ジョブをキャンセルすると、Dataflow サービスはジョブを直ちに停止します。
ジョブをキャンセルすると、次の処理が行われます。
Dataflow サービスが、すべてのデータの取り込みと処理を停止します。
Dataflow サービスが、ジョブに接続している Google Cloudリソースのクリーンアップを開始します。
これらのリソースには、Compute Engine ワーカー インスタンスのシャットダウンと、I/O ソースまたはシンクへのアクティブな接続の終了が含まれることがあります。
ジョブのキャンセルに関する重要な情報
ジョブをキャンセルすると、パイプラインの処理が直ちに停止します。
ジョブのキャンセルにより、処理中のデータが失われる可能性があります。処理中のデータとは、すでに読み込まれているがパイプラインによって処理中のデータを指します。
ジョブをキャンセルする前にパイプラインから出力シンクに書き込まれたデータは、出力シンクでまだアクセス可能な場合があります。
データ損失が問題にならない場合は、ジョブをキャンセルすることで、ジョブに関連するGoogle Cloud リソースをできるだけ早くシャットダウンするようにします。
Dataflow ジョブをドレインする
ジョブをドレインすると、Dataflow サービスは現在の状態でジョブを終了します。ストリーミング パイプラインの停止時にデータの消失を防ぐには、ジョブのドレインが最適な方法です。
ジョブをドレインすると、次の処理が行われます。
ドレイン リクエストの受信後すぐに(通常、数分以内)入力ソースからの新しいデータの取り込みを停止します。
Dataflow サービスは、既存のリソース(ワーカー インスタンスなど)を保持し、パイプラインのバッファ内のデータの処理と書き込みを終了します。
保留中の処理と書き込みオペレーションがすべて完了すると、Dataflow サービスはジョブに関連付けられた Google Cloud リソースをシャットダウンします。
ジョブをドレインするために、Dataflow は新しい入力の読み取りを停止し、ソースに無限大のイベント タイムスタンプを付けてパイプラインに伝播します。そのため、ドレイン プロセスのパイプラインには無限のウォーターマークが含まれている可能性があります。
ジョブのドレインに関する重要な情報
バッチ パイプラインではジョブのドレインはサポートされていません。
すべての処理と書き込みが完了するまで、パイプラインには、関連付けられたGoogle Cloud リソースの維持コストが発生します。
ドレイン中のパイプラインは更新できます。パイプラインが停止している場合は、問題の原因となっているエラーを修正するコードを使用してパイプラインを更新すると、データ損失なしで正常にドレインできます。
ドレイン中のジョブをキャンセルできます。
パイプラインに大量のバッファ内データがある場合など、ジョブのドレインが完了するまでに非常に時間がかかることがあります。
ストリーミング パイプラインに Splittable DoFn が含まれている場合、ドレイン オプションの実行前に結果を切り捨てる必要があります。Splittable DoFn の切り捨ての詳細については、Apache Beam のドキュメントをご覧ください。
場合によっては、Dataflow ジョブでドレイン オペレーションを完了できないことがあります。ジョブのログを確認して根本原因を特定し、適切な措置を講じることができます。
データの保持
Dataflow のストリーミングではワーカーの再起動が許容され、エラーの発生時にストリーミング ジョブが失敗することはありません。代わりに、ジョブのキャンセルや再起動などの操作を行うまで Dataflow サービスは再試行します。ジョブをドレインすると、Dataflow は引き続き再試行を継続し、パイプラインが停止する場合があります。この状況で、データ損失なしでドレインを正常に行うには、問題の原因となっているエラーを修正するコードを使用してパイプラインを更新します。
Dataflow は、Dataflow サービスがメッセージを永続的に commit するまで、メッセージの確認応答を行いません。たとえば、Kafka を使用すると、このプロセスにより Kafka から Dataflow にメッセージの所有権が安全に受け渡されるので、データ損失のリスクを排除できます。
停止したジョブ
- ドレインでは、停止したパイプラインは修正されません。データの移動がブロックされた場合、ドレイン コマンドの後、パイプラインは停止したままになります。停止したパイプラインに対処するには、update コマンドを使用して、問題を起こしているエラーを解決するコードを使用してパイプラインを更新します。停止したジョブをキャンセルすることもできますが、ジョブをキャンセルするとデータが失われる可能性があります。
タイマー
ストリーミング パイプラインのコードにループタイマーが含まれている場合、ジョブの速度が遅くなったり、ジョブがドレインできなくなる可能性があります。すべてのタイマーが完了するまでドレイン完了しないため、無限ループタイマーを使用するパイプラインではドレインが終了しません。
Dataflow は、すべての処理時間タイマーをすぐに起動するのではなく、すべての処理時間タイマーが完了するまで待機します。このため、ドレインが遅くなる可能性があります。
ジョブのドレインの影響
ストリーミング パイプラインをドレインすると、Dataflow は処理中のウィンドウを直ちに終了し、すべてのトリガーを呼び出します。
システムは、ドレイン オペレーションで未処理の時間ベースのウィンドウの終了を待機しません。
たとえば、ジョブのドレイン時にパイプラインが 2 時間のウィンドウまで残り 10 分の場合、Dataflow はウィンドウ終了までの残り時間を待機しません。部分的な結果でウィンドウを即時に終了します。Dataflow は、データ ウォーターマークを無期限まで進めることで、開いているウィンドウを終了します。この機能は、カスタム データソースでも機能します。
カスタム データソース クラスを使用するパイプラインをドレインすると、Dataflow は新規データのリクエスト発行を停止し、データ ウォーターマークを無期限まで進めて、最後のチェックポイントでソースの finalize() メソッドを呼び出します。
ドレインで、ウィンドウが部分的にいっぱいになる場合があります。その場合、ドレインされたパイプラインを再起動すると、同じウィンドウが再度呼び出され、データに問題が発生する可能性があります。たとえば、次のシナリオでは、ファイル名が競合し、データが上書きされる可能性があります。
午後 12 時 34 分に 1 時間のウィンドウ処理を使用してパイプラインをドレインすると、午後 12 時から午後 1 時のウィンドウは、ウィンドウの最初の 34 分間に発生したデータのみを使用して閉じられます。パイプラインは午後 12 時 34 分以降に新しいデータを読み取りません。
その後すぐにパイプラインを再起動すると、午後 12 時分から午後 1 時のウィンドウは午後 12 時 35 分から午後 1 時まで読み取られたデータのみを使用して、再びトリガーされます。重複は送信されませんが、ファイル名が繰り返されるとデータが上書きされます。
Google Cloud コンソールで、パイプラインの変換の詳細を確認できます。次の図は、処理中のドレイン オペレーションの影響を示しています。ウォーターマークは最大値まで進められていることに注意してください。
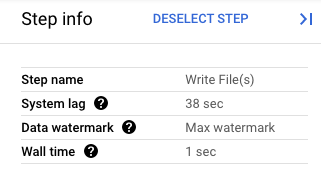
図 1. ドレイン オペレーションのステップビュー。
Dataflow ジョブを強制的にキャンセルする
強制キャンセルは、他の方法でジョブをキャンセルできない場合にのみ使用してください。強制キャンセルは、すべてのリソースをクリーンアップせずにジョブを終了します。強制キャンセルを繰り返し使用すると、リークされたリソースが蓄積され、それにより割り当てが使用される可能性があります。
ジョブを強制的にキャンセルすると、Dataflow サービスはジョブを直ちに停止し、Dataflow ジョブによって作成された VM がリークされます。通常のキャンセルは、強制キャンセルの 30 分以上前に行う必要があります。
ジョブを強制的にキャンセルすると、次の処理が行われます。
- Dataflow サービスが、すべてのデータの取り込みと処理を停止します。
ジョブの強制キャンセルに関する重要な情報
ジョブを強制的にキャンセルすると、パイプラインの処理が直ちに停止します。
ジョブの強制キャンセルは、通常のキャンセル プロセスで先に進まないジョブにのみ行います。
Dataflow ジョブによって作成されたワーカー インスタンスはすべて解放されないので、ワーカー インスタンスがリークする可能性があります。リークされたワーカー インスタンスはジョブの費用に影響しませんが、割り当てを使用する可能性があります。ジョブのキャンセルが完了したら、これらのリソースを削除できます。
Dataflow Prime ジョブの場合、リークされた VM を表示または削除することはできません。ほとんどの場合、これらの VM で問題は発生しません。ただし、リークされた VM によって VM 割り当ての消費などの問題が発生した場合は、サポートにお問い合わせください。
Dataflow ジョブを停止する
ジョブを停止する前に、ジョブのキャンセル、ドレイン、強制キャンセルの影響を理解する必要があります。
コンソール
Dataflow の [ジョブ] ページに移動します。
停止するジョブをクリックします。
ジョブを停止するには、ジョブのステータスが「実行中」でなければなりません。
ジョブの詳細ページで、[停止] をクリックします。
次のいずれかを行います。
バッチ パイプラインの場合は、[キャンセル] または [強制キャンセル] をクリックします。
ストリーミング パイプラインの場合は、[キャンセル]、[ドレイン]、または [強制キャンセル] をクリックします。
選択を確定するには、[ジョブの停止] をクリックします。
gcloud
Dataflow ジョブをドレインまたはキャンセルするには、Cloud Shell または gcloud CLI がインストールされたローカル ターミナルで gcloud dataflow jobs コマンドを使用します。
シェルにログインします。
現在実行中の Dataflow ジョブのジョブ ID を一覧表示し、停止するジョブのジョブ ID をメモします。
gcloud dataflow jobs list--regionフラグが設定されていない場合、使用可能なすべてのリージョンの Dataflow ジョブが表示されます。次のいずれかを行います。
ストリーミング ジョブをドレインするには:
gcloud dataflow jobs drain JOB_IDJOB_IDを、先ほどコピーしたジョブ ID に置き換えます。バッチまたはストリーミング ジョブをキャンセルするには:
gcloud dataflow jobs cancel JOB_IDJOB_IDを、先ほどコピーしたジョブ ID に置き換えます。バッチまたはストリーミング ジョブを強制的にキャンセルするには:
gcloud dataflow jobs cancel JOB_ID --forceJOB_IDを、先ほどコピーしたジョブ ID に置き換えます。
API
Dataflow REST API を使用してジョブをキャンセルまたはドレインするには、projects.locations.jobs.update または projects.jobs.update を選択します。リクエストの本文で、選択した API のジョブ インスタンスの requestedState フィールドに必要なジョブの状態を渡します。
重要: projects.locations.jobs.update を使用することをおすすめします。projects.jobs.update で状態を更新できるのは us-central1 で実行中のジョブだけです。
ジョブをキャンセルするには、ジョブのステータスを
JOB_STATE_CANCELLEDに設定します。ジョブをドレインするには、ジョブのステータスを
JOB_STATE_DRAINEDに設定します。ジョブを強制的にキャンセルするには、ジョブの状態を
JOB_STATE_CANCELLEDに設定し、ラベル"force_cancel_job": "true"を使用します。リクエストの本文は次のようになります。{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Dataflow ジョブの完了を検出する
ジョブのキャンセルやドレインの完了を検出するには、次のいずれかの方法を使用します。
- Cloud Composer などのワークフロー オーケストレーション サービスを使用して、Dataflow ジョブをモニタリングします。
- パイプラインを同期して実行し、パイプラインが完了するまでタスクがブロックされるようにします。詳細については、パイプライン オプションの設定の実行モードの制御をご覧ください。
Google Cloud CLI のコマンドライン ツールを使用して、ジョブのステータスをポーリングします。プロジェクト内の Dataflow ジョブの一覧を取得するには、シェルまたはターミナルで次のコマンドを実行します。
gcloud dataflow jobs list出力には、ジョブごとにジョブ ID、名前、ステータス(
STATE)などの情報が含まれます。詳細については、Google Cloud CLI を使用してジョブを一覧取得するをご覧ください。
完了した Dataflow ジョブをアーカイブする
Dataflow ジョブをアーカイブすると、そのジョブはコンソールの Dataflow の [ジョブ] ページのジョブリストから削除されます。ジョブは、アーカイブされたジョブのリストに移動します。アーカイブできるのは完了したジョブのみです。これには、次の状態のジョブが含まれます。
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
これらの状態の確認の詳細については、Dataflow ジョブの完了を検出するをご覧ください。
ジョブのアーカイブ時のトラブルシューティング情報については、「Dataflow エラーのトラブルシューティング」のアーカイブ ジョブ エラーをご覧ください。
アーカイブされたジョブはすべて、30 日間の保持期間後に削除されます。
ジョブをアーカイブする
Dataflow の [ジョブ] ページのメイン ジョブリストから完了したジョブを削除するには、次の操作を行います。
コンソール
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
Dataflow ジョブのリストとそれぞれのステータスが表示されます。
ジョブを選択します。
[ジョブの詳細] ページで、[アーカイブ] をクリックします。ジョブが完了していない場合、[アーカイブ] オプションは使用できません。
REST
API を使用してジョブをアーカイブするには、projects.locations.jobs.update メソッドを使用します。
このリクエストでは、更新された JobMetadata オブジェクトを指定する必要があります。JobMetadata.userDisplayProperties オブジェクトで、Key-Value ペア "archived":"true" を使用します。
API リクエストには、更新された JobMetadata オブジェクトのほか、リクエスト URL に updateMask クエリ パラメータも含める必要があります。
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- REGION: Dataflow リージョン
- JOB_ID: Dataflow ジョブの ID
HTTP メソッドと URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
リクエストの本文(JSON):
{
"job_metadata": {
"userDisplayProperties": {
"archived": "true"
}
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "true"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
gcloud
このコマンドは、単一のジョブをアーカイブします。ジョブをアーカイブするには、ジョブが終了状態である必要があります。それ以外の場合、リクエストは拒否されます。コマンドを送信した後、そのコマンドを実行することを確認する必要があります。
後述のコマンドデータを使用する前に、次のように置き換えます。
JOB_ID: アーカイブする Dataflow ジョブの ID。REGION: 省略可。ジョブの Dataflow リージョン。
次のコマンドを実行します。
Linux、macOS、Cloud Shell
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows(PowerShell)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows(cmd.exe)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
次のようなレスポンスが返されます。
Archived job [JOB_ID].
createTime: '2025-06-29T11:00:02.432552Z'
currentState: JOB_STATE_DONE
currentStateTime: '2025-06-29T11:04:25.125921Z'
id: JOB_ID
jobMetadata:
userDisplayProperties:
archived: 'true'
projectId: PROJECT_ID
startTime: '2025-06-29T11:00:02.432552Z'
アーカイブされたジョブを表示して復元する
アーカイブされたジョブを表示するか、アーカイブされたジョブを Dataflow の [ジョブ] ページのメイン ジョブリストに復元するには、次の操作を行います。
コンソール
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
[アーカイブ済み] 切り替えボタンをクリックします。アーカイブされた Dataflow ジョブのリストが表示されます。
ジョブを選択します。
ジョブを Dataflow の [ジョブ] ページのメイン ジョブリストに復元するには、[ジョブの詳細] ページで [復元] をクリックします。
REST
API を使用してアーカイブされたジョブを復元するには、projects.locations.jobs.update メソッドを使用します。
このリクエストでは、更新された JobMetadata オブジェクトを指定する必要があります。JobMetadata.userDisplayProperties オブジェクトで、Key-Value ペア "archived":"false" を使用します。
API リクエストには、更新された JobMetadata オブジェクトのほか、リクエスト URL に updateMask クエリ パラメータも含める必要があります。
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- REGION: Dataflow リージョン
- JOB_ID: Dataflow ジョブの ID
HTTP メソッドと URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
リクエストの本文(JSON):
{
"job_metadata": {
"userDisplayProperties": {
"archived": "false"
}
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "false"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
次のステップ
- Dataflow REST API を確認する。
- Google Cloud コンソールで、Dataflow モニタリング インターフェースを確認する。
- パイプラインの更新を確認する。