Apache Beam SDK에서 기본 제공되는 로깅 인프라를 사용하여 파이프라인을 실행할 때 정보를 로깅할 수 있습니다. Google Cloud Console을 사용하여 파이프라인 실행 중과 실행 후에 로깅 정보를 모니터링 할 수 있습니다.
파이프라인에 로그 메시지 추가
자바
자바용 Apache Beam SDK는 오픈소스 Simple Logging Facade for Java(SLF4J) 라이브러리를 통한 작업자 메시지 로깅을 권장합니다. 자바용 Apache Beam SDK가 필요한 로깅 인프라를 구현하므로, 자바 코드에서는 SLF4J API만 가져옵니다. 그런 다음 파이프라인 코드 내에서 메시지 로깅을 사용 설정하도록 로거를 인스턴스화합니다.
기존 코드 또는 라이브러리의 경우, 자바용 Apache Beam SDK는 로깅 인프라를 추가로 설정합니다. 다음 자바용 로깅 라이브러리를 통해 생성된 로그 메시지가 캡처됩니다.
Python
Python용 Apache Beam SDK는 파이프라인 작업자가 로그 메시지를 출력하게 하는 logging 라이브러리 패키지를 제공합니다. 라이브러리 함수를 사용하려면 라이브러리를 가져와야 합니다.
import logging
Go
Go용 Apache Beam SDK는 파이프라인 작업자가 로그 메시지를 출력하게 하는 log 라이브러리 패키지를 제공합니다. 라이브러리 함수를 사용하려면 라이브러리를 가져와야 합니다.
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
작업자 로그 메시지 코드 예
자바
다음 예시에서는 Dataflow 로깅에 SLF4J를 사용합니다. Dataflow 로깅을 위한 SLF4J 구성에 대한 자세한 내용은 자바 팁 문서를 참조하세요.
Apache Beam WordCount 예시는 처리된 텍스트 줄에서 'love'라는 단어가 발견되면 로그 메시지를 출력하도록 수정될 수 있습니다. 추가된 코드는 다음 예시에서 굵게 표시되었습니다(주변 코드는 이해를 돕기 위해 포함됨).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
Apache Beam wordcount.py 예시는 처리된 텍스트 줄에서 'love' 단어가 발견되면 로그 메시지를 출력하도록 수정될 수 있습니다.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
Apache Beam wordcount.go 예시는 처리된 텍스트 줄에서 'love' 단어가 발견되면 로그 메시지를 출력하도록 수정될 수 있습니다.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
자바
수정된 WordCount 파이프라인이 로컬 파일에 보낸 출력(--output=./local-wordcounts)이 있는 기본 DirectRunner를 사용하여 로컬로 실행되는 경우, Console 출력에 추가된 로그 메시지가 포함됩니다.
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
기본적으로 INFO 이상으로 표시된 로그 줄만 Cloud Logging으로 전송됩니다. 이 동작을 변경하려면 파이프라인 작업자 로그 수준 설정을 참고하세요.
Python
수정된 WordCount 파이프라인이 로컬 파일에 보낸 출력(--output=./local-wordcounts)이 있는 기본 DirectRunner를 사용하여 로컬로 실행되는 경우, Console 출력에 추가된 로그 메시지가 포함됩니다.
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
기본적으로 INFO 이상으로 표시된 로그 줄만 Cloud Logging으로 전송됩니다. 이 동작을 변경하려면 파이프라인 작업자 로그 수준 설정을 참고하세요.
파이프라인 로그를 Dataflow 및 Cloud Logging으로 전송하는 사전 구성된 로그 핸들러가 사용 중지될 수 있으므로 logging.config 함수로 로깅 구성을 덮어쓰지 마세요.
Go
수정된 WordCount 파이프라인이 로컬 파일에 보낸 출력(--output=./local-wordcounts)이 있는 기본 DirectRunner를 사용하여 로컬로 실행되는 경우, Console 출력에 추가된 로그 메시지가 포함됩니다.
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
기본적으로 INFO 이상으로 표시된 로그 줄만 Cloud Logging으로 전송됩니다.
로그 볼륨 제어
또한 파이프라인 로그 수준을 변경하여 생성되는 로그의 양을 줄일 수도 있습니다. Dataflow 로그의 일부 또는 전부를 계속 수집하지 않으려면 Logging 제외를 추가하여 Dataflow 로그를 제외합니다. 그런 다음 BigQuery, Cloud Storage, Pub/Sub 등의 다른 대상으로 로그를 내보냅니다. 자세한 내용은 Dataflow 로그 수집 제어를 참조하세요.
한도 및 제한 로깅
작업자 로그 메시지는 작업자별로 30초마다 15,000개로 제한됩니다. 이 한도에 도달하면 로깅이 제한됨을 알리는 단일 작업자 로그 메시지가 추가됩니다.
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
로그 스토리지 및 보관
작업 로그는 _Default 로그 버킷에 저장됩니다.
Logging API 서비스 이름은 dataflow.googleapis.com입니다. Cloud Logging에 사용되는 Google Cloud 모니터링 리소스 유형 및 서비스에 대한 자세한 내용은 모니터링 리소스 및 서비스를 참조하세요.
Logging에서 로그 항목이 보관되는 기간에 대한 자세한 내용은 할당량 및 한도: 로그 보관 기간의 보관 정보를 참조하세요.
작업 로그 보기에 대한 자세한 내용은 파이프라인 로그 모니터링 및 보기를 참조하세요.
파이프라인 로그 모니터링 및 보기
Dataflow 서비스에서 파이프라인을 실행하면 Dataflow 모니터링 인터페이스를 사용하여 파이프라인에서 방출한 로그를 볼 수 있습니다.
Dataflow 작업자 로그 예시
수정된 WordCount 파이프라인은 다음 옵션으로 클라우드에서 실행될 수 있습니다.
자바
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
로그 보기
WordCount 클라우드 파이프라인은 차단 실행을 사용하므로, 파이프라인 실행 중에 콘솔 메시지가 출력됩니다. 작업이 시작되면 Google Cloud 콘솔 페이지에 대한 링크가 콘솔로 출력되고, 이어서 파이프라인 작업 ID가 출력됩니다.
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
콘솔 URL은 제출된 작업의 요약 페이지가 있는 Dataflow 모니터링 인터페이스로 연결됩니다. 해당 화면의 왼쪽에는 동적 실행 그래프, 오른쪽에는 요약 정보가 표시됩니다. 하단 패널의 keyboard_capslock을 클릭하여 로그 패널을 확장하세요.
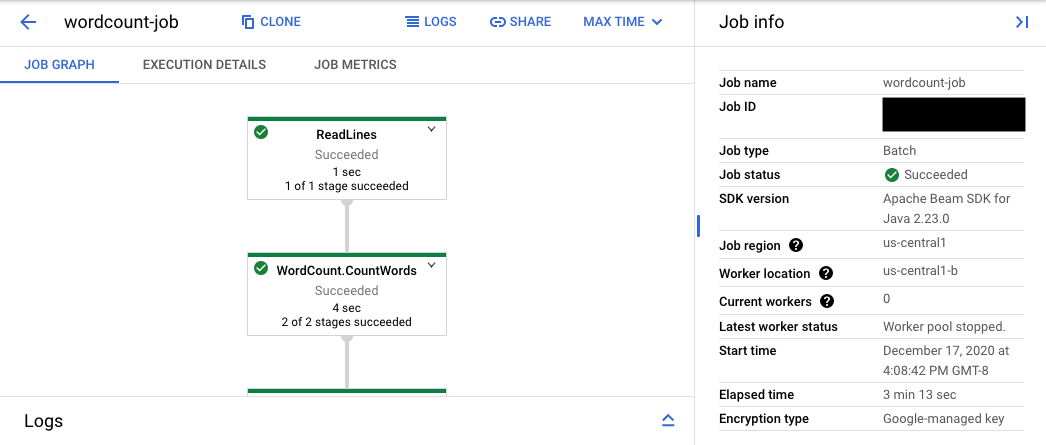
로그 패널에는 기본적으로 작업 상태를 전체적으로 보고하는 작업 로그가 표시됩니다. 정보arrow_drop_down와 filter_list로그 필터링을 클릭하여 로그 패널에 표시되는 메시지를 필터링할 수 있습니다.
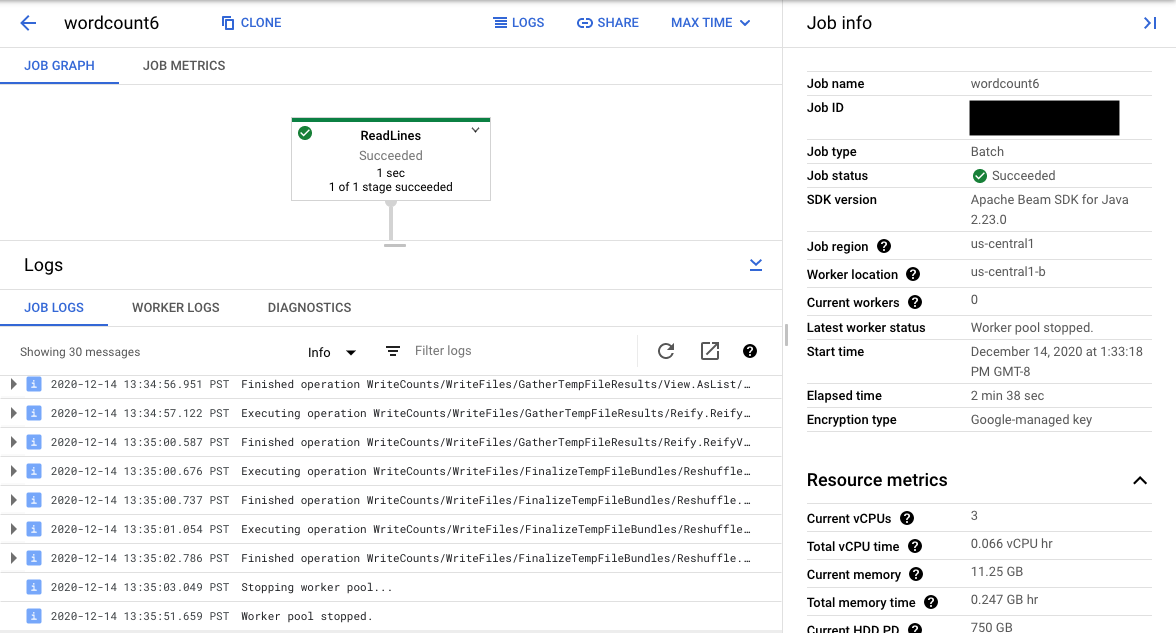
그래프에서 파이프라인 단계를 선택하면 뷰는 사용자 코드 및 파이프라인 단계에서 실행되는 생성 코드를 통해 생성된 단계 로그로 변경됩니다.
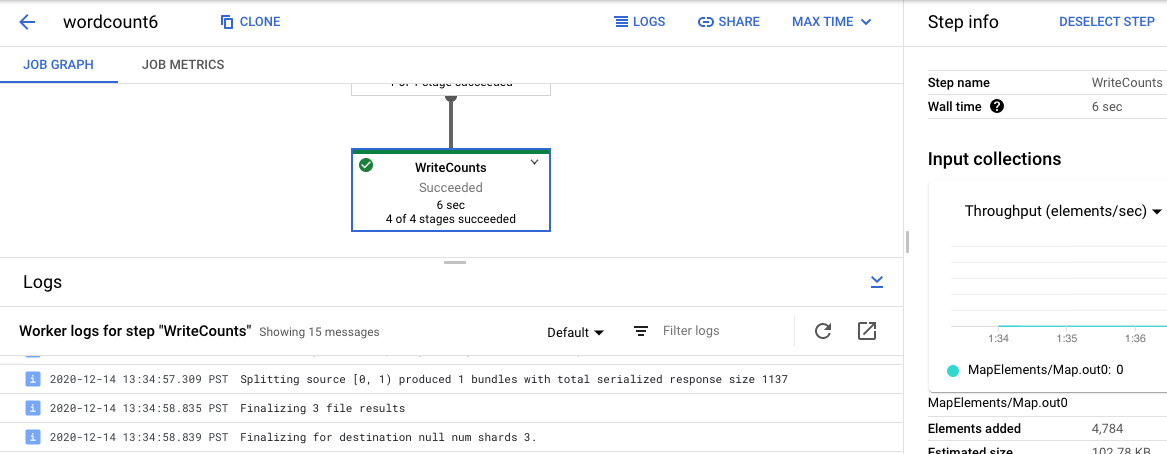
작업 로그로 돌아가려면 그래프 바깥쪽을 클릭하거나 오른쪽 측면 패널에 있는 단계 선택 취소 버튼을 사용하여 단계를 지웁니다.
로그 탐색기로 이동
로그 탐색기를 열고 다른 로그 유형을 선택하려면 로그 패널에서 로그 탐색기에서 보기(외부 링크 버튼)를 클릭합니다.
로그 탐색기에서 다양한 로그 유형이 포함된 패널을 보려면 로그 필드 전환 버튼을 클릭합니다.
로그 탐색기 페이지에서 쿼리는 작업 단계 또는 로그 유형별로 로그를 필터링할 수 있습니다. 필터를 삭제하려면 쿼리 표시 전환 버튼을 클릭하고 쿼리를 수정합니다.
작업에 사용할 수 있는 모든 로그를 보려면 다음 단계를 따르세요.
쿼리 필드에 다음 쿼리를 입력합니다.
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"JOB_ID를 작업 ID로 바꿉니다.
쿼리 실행을 클릭합니다.
이 쿼리를 사용해도 작업 로그가 표시되지 않으면 시간 수정을 클릭합니다.
시작 시간과 종료 시간을 조정한 다음 적용을 클릭합니다.
로그 유형
로그 탐색기에는 파이프라인의 인프라 로그도 포함됩니다. 오류 및 경고 로그를 사용하여 관찰된 파이프라인 문제를 진단합니다. 파이프라인 문제와 관련이 없는 인프라 로그의 오류 및 경고가 반드시 문제를 나타내는 것은 아닙니다.
다음은 로그 탐색기 페이지에서 볼 수 있는 여러 가지 로그 유형의 요약입니다.
- job-message 로그에는 Dataflow의 다양한 구성요소가 생성하는 작업 수준 메시지가 포함됩니다. 대표적인 예시는 자동 확장 구성, 작업자 시작 또는 종료 시간, 작업 단계 진행 상황과 작업 오류입니다. 사용자 코드 비정상 종료 때문에 발생했으며 작업자 로그에 존재하는 작업자 수준 오류도 job-message 로그를 작성합니다.
- worker 로그는 Dataflow 작업자가 생성합니다. 작업자는 대부분의 파이프라인 작업을 수행합니다(예: 데이터에
ParDo적용). Worker 로그에는 개발자 코드와 Dataflow에서 로깅한 메시지가 포함됩니다. - worker-startup 로그는 대부분의 Dataflow 작업에 포함되며 시작 프로세스와 관련된 메시지를 캡처할 수 있습니다. 시작 프로세스에는 Cloud Storage에서 작업의 jar를 다운로드하는 것과 이후의 작업자 시작이 포함됩니다. 작업자를 시작하는 데 문제가 있으면 이 로그를 먼저 보는 것이 좋습니다.
- harness 로그에는 Runner v2 실행기 하네스의 메시지가 포함됩니다.
- shuffler 로그에는 병렬 파이프라인 작업 결과를 통합하는 작업자의 메시지가 포함됩니다.
- system 로그에는 작업자 VM 호스트 운영체제의 메시지가 포함됩니다. 일부 시나리오에서는 프로세스 비정상 종료나 메모리 부족(OOM) 이벤트를 캡처할 수 있습니다.
- docker와 kubelet 로그에는 Dataflow 작업자에서 사용되는 이들 공개 기술과 관련된 메시지가 포함됩니다.
- nvidia-mps 로그에는 NVIDIA Multi-Process Service(MPS) 작업에 대한 메시지가 포함됩니다.
파이프라인 작업자 로그 수준 설정
자바
자바용 Apache Beam SDK를 통해 작업자에 생성되는 기본 SLF4J 로깅 수준은 INFO입니다. INFO 이상(INFO , WARN, ERROR)의 모든 로그 메시지가 방출됩니다. 더 낮은 SLF4J 로깅 수준(TRACE 또는 DEBUG)을 지원하도록 다른 기본 로그 수준을 설정하거나 코드의 여러 클래스 패키지에 대해 서로 다른 로그 수준을 설정할 수 있습니다.
명령줄 또는 프로그래매틱 방식으로 작업자 로그 수준을 설정할 수 있도록 다음 파이프라인 옵션이 제공됩니다.
--defaultSdkHarnessLogLevel=<level>: 이 옵션을 사용하면 모든 로거를 지정된 기본 수준으로 설정합니다. 예를 들어 다음 명령줄 옵션은 기본 DataflowINFO로그 수준을 재정의하고 이를DEBUG:
--defaultSdkHarnessLogLevel=DEBUG로 설정합니다.--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: 이 옵션을 사용하면 지정된 패키지 또는 클래스의 로깅 수준을 설정합니다. 예를 들어org.apache.beam.runners.dataflow패키지의 기본 파이프라인 로그 수준을 재정의하고 이를 다음과 같이TRACE로 설정할 수 있습니다.
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
여러 재정의를 수행하려면 JSON 맵을 제공합니다.
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})- Runner v2 없이 Apache Beam SDK 버전 2.50.0 이하를 사용하는 파이프라인에서는
defaultSdkHarnessLogLevel및sdkHarnessLogLevelOverrides파이프라인 옵션이 지원되지 않습니다. 이 경우--defaultWorkerLogLevel=<level>및--workerLogLevelOverrides={"<package or class>":"<level>"}파이프라인 옵션을 사용합니다. 여러 재정의를 수행하려면 JSON 맵을 제공합니다.
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
다음 예시는 명령줄에서 재정의할 수 있는 기본값과 함께 파이프라인 로깅 옵션을 프로그래매틱 방식으로 설정합니다.
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Python용 Apache Beam SDK를 통해 작업자에 생성되는 기본 로깅 수준은 INFO입니다. INFO 이상(INFO, WARNING, ERROR, CRITICAL)의 모든 로그 메시지가 방출됩니다.
더 낮은 로깅 수준(DEBUG)을 지원하도록 다른 기본 로그 수준을 설정하거나 코드의 여러 모듈에 대해 서로 다른 로그 수준을 설정할 수 있습니다.
명령줄 또는 프로그래매틱 방식으로 작업자 로그 수준을 설정할 수 있도록 파이프라인 옵션 두 개가 제공됩니다.
--default_sdk_harness_log_level=<level>: 이 옵션을 사용하면 모든 로거를 지정된 기본 수준으로 설정합니다. 예를 들어 다음 명령줄 옵션은 기본 DataflowINFO로그 수준을 재정의하고 이를DEBUG로 설정합니다.
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: 이 옵션을 사용하여 지정된 모듈의 로깅 수준을 설정합니다. 예를 들어apache_beam.runners.dataflow모듈의 기본 파이프라인 로그 수준을 재정의하고 이를 다음과 같이DEBUG로 설정할 수 있습니다.
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
여러 재정의를 수행하려면 JSON 맵을 제공합니다.
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...})
다음 예시에서는 WorkerOptions 클래스를 사용하여 명령줄에서 재정의할 수 있는 파이프라인 로깅 옵션을 프로그래매틱 방식으로 설정합니다.
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
다음을 바꿉니다.
PROJECT_NAME: 프로젝트 이름JOB_NAME: 작업의 이름STORAGE_BUCKET: Cloud Storage 이름DATAFLOW_REGION: Dataflow 작업을 배포할 리전--region플래그는 메타데이터 서버, 로컬 클라이언트 또는 환경 변수에 설정된 기본 리전을 재정의합니다.
Go
이 기능은 Go용 Apache Beam SDK에서 사용할 수 없습니다.
시작된 BigQuery 작업 로그 보기
Dataflow 파이프라인에서 BigQuery를 사용하면 다양한 작업을 대신 수행하기 위해 BigQuery 작업이 실행됩니다. 이러한 작업에는 데이터 로드, 데이터 내보내기 등이 포함될 수 있습니다. Dataflow 모니터링 인터페이스에는 로그 패널에서 사용할 수 있는 이러한 BigQuery 작업에 대한 추가 정보가 문제 해결 및 모니터링을 위해 존재합니다.
로그 패널에 표시된 BigQuery 작업 정보는 BigQuery 시스템 테이블에 저장되고 로드됩니다. 기본 BigQuery 테이블을 쿼리할 때 청구 비용이 발생합니다.
BigQuery 작업 세부정보 보기
BigQuery 작업 정보를 보려면 파이프라인에서 Apache Beam 2.24.0 이상을 사용해야 합니다.
BigQuery 작업을 나열하려면 BigQuery 작업 탭을 열고 BigQuery 작업의 위치를 선택합니다. 그런 다음 BigQuery 작업 로드를 클릭하고 대화상자를 확인합니다. 쿼리가 완료되면 작업 목록이 표시됩니다.
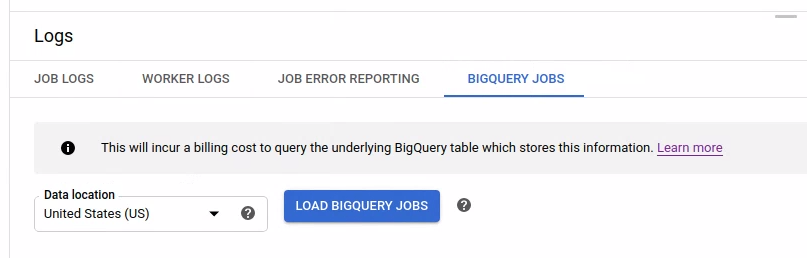
작업 ID, 유형, 기간 등 각 작업에 대한 기본 정보가 제공됩니다.
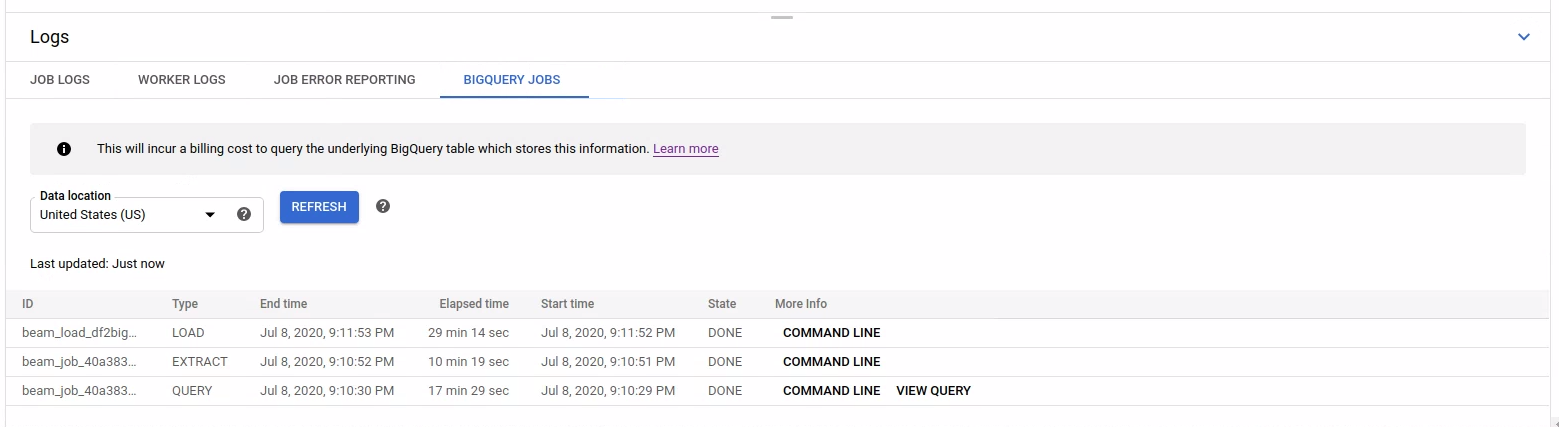
특정 작업에 대한 상세 정보를 보려면 추가 정보 열에서 명령줄을 클릭하세요.
명령줄의 모달 창에서 bq jobs describe 명령어를 복사하여 로컬로 또는 Cloud Shell에서 실행합니다.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
bq jobs describe 명령어는 JobStatistics를 출력합니다. 이 기능은 속도가 느리거나 중단된 BigQuery 작업 진단 시 유용한 추가 세부정보를 제공합니다.
또는 BigQueryIO를 SQL 쿼리와 함께 사용하면 쿼리 작업이 실행됩니다. 작업에서 사용하는 SQL 쿼리를 보려면 추가 정보 열에서 쿼리 보기를 클릭합니다.