Cette page présente le cycle de vie du pipeline, depuis le code de pipeline jusqu'au job Dataflow.
Cette page explique les concepts suivants :
- Qu'est-ce qu'un graphique d'exécution et comment un pipeline Apache Beam devient-il un job Dataflow ?
- Comment Dataflow gère-t-il les erreurs ?
- Comment Dataflow parallélise-t-il la logique de traitement de votre pipeline pour ensuite la distribuer automatiquement aux nœuds de calcul qui exécutent votre job ?
- Quelles sont les optimisations de job applicables par Dataflow ?
Graphique d'exécution
Lorsque vous exécutez votre pipeline Dataflow, le service crée à partir du code qui construit votre objet Pipeline un graphique d'exécution comprenant toutes les transformations et leurs fonctions de traitement associées (par exemple, des objets DoFn). Il s'agit du graphique d'exécution du pipeline, la phase étant appelée le temps de construction du graphique.
Durant la construction du graphique, Apache Beam exécute localement le code à partir du point d'entrée principal du code du pipeline, en s'arrêtant aux appels à une source, à un récepteur ou à une étape de transformation, puis en convertissant ces appels en nœuds du graphique.
Par conséquent, une partie du code du point d'entrée d'un pipeline (méthode main de Java et Go ou niveau supérieur d'un script Python) s'exécute localement sur la machine qui exécute le pipeline Le même code déclaré dans une méthode d'objet DoFn s'exécute dans les nœuds de calcul Dataflow.
Par exemple, l'extrait de code WordCount inclus dans les SDK Apache Beam contient une série de transformations permettant de lire, d'extraire, de compter, de formater et d'écrire les mots individuels d'une collection de texte, ainsi que le nombre d'occurrences de chaque mot. Le diagramme suivant montre comment les transformations dans le pipeline WordCount sont développées dans un graphique d'exécution :
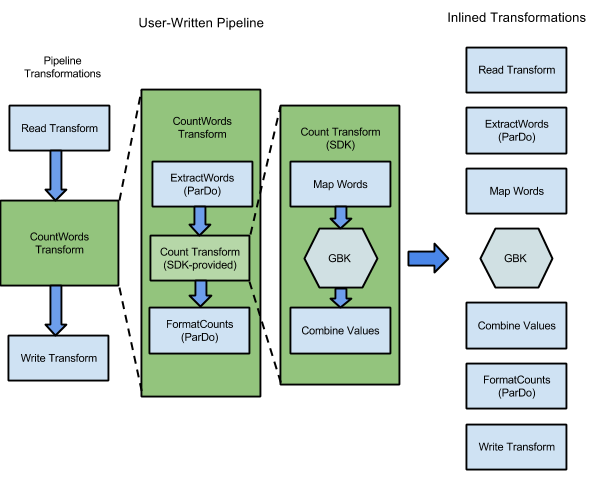
Figure 1 : Exemple de graphique d'exécution WordCount
Le graphique d'exécution diffère souvent de l'ordre dans lequel vous avez spécifié vos transformations lors de la construction du pipeline. Cette différence existe car le service Dataflow effectue diverses optimisations et fusions sur le graphique d'exécution avant de s'exécuter sur des ressources de cloud gérées. Le service Dataflow respecte les dépendances de données lors de l'exécution de votre pipeline. Cependant, les étapes sans dépendance de données entre elles peuvent être exécutées dans n'importe quel ordre.
Pour afficher le graphique d'exécution non optimisé généré par Dataflow pour votre pipeline, sélectionnez votre job dans l'interface de surveillance de Dataflow. Pour en savoir plus sur l'affichage des jobs, consultez la section Utiliser l'interface de surveillance Dataflow.
Durant la construction du graphique, Apache Beam vérifie que toutes les ressources référencées par le pipeline (telles que les buckets Cloud Storage, les tables BigQuery, et les sujets ou abonnements Pub/Sub) existent et sont accessibles. Cette vérification est effectuée via des appels d'API standards aux services respectifs. Il est donc essentiel que le compte utilisateur utilisé pour exécuter un pipeline dispose d'une connectivité appropriée aux services nécessaires et soit autorisé à appeler leurs API. Avant d'envoyer le pipeline au service Dataflow, Apache Beam recherche également d'autres erreurs et s'assure que le graphique du pipeline ne contient aucune opération non conforme.
Le graphique d'exécution est ensuite converti au format JSON, puis il est transmis au point de terminaison du service Dataflow.
Le service Dataflow valide ensuite le graphique d'exécution JSON. Une fois le graphique validé, il devient un job sur le service Dataflow. Vous pouvez consulter votre job, son graphique d'exécution, son état et ses informations de journalisation à l'aide de l'interface de surveillance de Dataflow.
Java
Le service Dataflow envoie une réponse à la machine sur laquelle vous avez exécuté votre programme Dataflow. Cette réponse est encapsulée dans l'objet DataflowPipelineJob, qui contient le paramètre jobId de votre job Dataflow.
Pour surveiller votre job, le suivre et résoudre les problèmes le concernant, utilisez le paramètre jobId dans l'interface de surveillance de Dataflow et l'interface de ligne de commande de Dataflow.
Pour en savoir plus, consultez la documentation de référence de l'API pour DataflowPipelineJob.
Python
Le service Dataflow envoie une réponse à la machine sur laquelle vous avez exécuté votre programme Dataflow. Cette réponse est encapsulée dans l'objet DataflowPipelineResult, qui contient le paramètre job_id de votre job Dataflow.
Pour surveiller votre job, le suivre et résoudre les problèmes le concernant, utilisez le paramètre job_id dans l'interface de surveillance de Dataflow et l'interface de ligne de commande de Dataflow.
Go
Le service Dataflow envoie une réponse à la machine sur laquelle vous avez exécuté votre programme Dataflow. Cette réponse est encapsulée dans l'objet dataflowPipelineResult, qui contient le paramètre jobID de votre job Dataflow.
Pour surveiller votre job, le suivre et résoudre les problèmes le concernant, utilisez le paramètre jobID dans l'interface de surveillance de Dataflow et l'interface de ligne de commande de Dataflow.
La construction du graphique se produit également lorsque vous exécutez votre pipeline localement. Cependant, le graphique n'est pas converti au format JSON ni transmis au service. Au lieu de cela, il est exécuté localement sur la machine sur laquelle vous avez lancé votre programme Dataflow. Pour en savoir plus, consultez la section Configurer PipelineOptions pour une exécution locale.
Traitement des erreurs et des exceptions
Votre pipeline peut générer des exceptions lors du traitement des données. Certaines de ces erreurs sont temporaires, par exemple lorsque vous rencontrez des difficultés pour accéder à un service externe. D'autres erreurs sont permanentes, par exemple les erreurs causées par des données d'entrée corrompues ou impossibles à analyser, ou par des pointeurs vides lors du calcul.
Dataflow traite les éléments sous forme d'ensembles arbitraires et relance l'ensemble complet lorsqu'une erreur est générée pour l'un des éléments qu'il contient. Lors de l'exécution en mode de traitement par lots, les ensembles comprenant un élément défaillant sont relancés quatre fois. Le pipeline échoue complètement lorsqu'un ensemble échoue quatre fois. Lors de l'exécution en mode de traitement par flux, un ensemble comprenant un élément défaillant est relancé indéfiniment, ce qui risque de bloquer votre pipeline de manière permanente.
En cas de traitement par lots, vous risquez de rencontrer un grand nombre d'échecs individuels avant qu'un job de pipeline n'échoue complètement (ce qui se produit lorsqu'un ensemble donné échoue après quatre tentatives répétées). Par exemple, si votre pipeline tente de traiter 100 ensembles, Dataflow peut générer plusieurs centaines d'échecs individuels jusqu'à ce qu'un seul ensemble atteigne la condition de quatre échecs pour être ignoré.
Les erreurs liées aux nœuds de calcul de démarrage, telles que l'échec de l'installation de packages sur les nœuds de calcul, sont temporaires. Ce scénario entraîne un nombre de nouvelles tentatives illimité et peut bloquer votre pipeline de manière permanente.
Parallélisation et distribution
Le service Dataflow parallélise la logique de traitement de votre pipeline et la distribue automatiquement aux nœuds de calcul que vous affectez à l'exécution de votre job. Dataflow utilise les abstractions du modèle de programmation pour représenter les fonctions de parallélisation. Par exemple, les transformations ParDo d'un pipeline obligent Dataflow à distribuer automatiquement le code de traitement, représenté par des objets DoFn, à plusieurs nœuds de calcul qui doivent s'exécuter en parallèle.
Il existe deux types de parallélisme des jobs :
Le parallélisme horizontal se produit lorsque les données du pipeline sont réparties et traitées sur plusieurs nœuds de calcul en même temps. L'environnement d'exécution Dataflow repose sur un pool de nœuds de calcul distribués. Un pipeline présente un parallélisme potentiel plus élevé lorsque le pool contient plus de nœuds de calcul, mais cette configuration présente également un coût plus élevé. En théorie, le parallélisme horizontal n'a pas de limite supérieure. Toutefois, Dataflow limite le pool de nœuds de calcul à 4 000 nœuds de calcul afin d'optimiser l'utilisation des ressources sur l'ensemble du parc.
Le parallélisme vertical se produit lorsque les données de pipeline sont réparties et traitées par plusieurs cœurs de processeur sur le même nœud de calcul. Chaque nœud de calcul repose sur une VM Compute Engine. Une VM peut exécuter plusieurs processus pour saturer tous ses cœurs de processeur. Une VM comportant davantage de cœurs présente un parallélisme vertical potentiel plus élevé, mais cette configuration entraîne des coûts plus élevés. Un nombre plus élevé de cœurs entraîne souvent une augmentation de l'utilisation de la mémoire. Par conséquent, le nombre de cœurs est généralement proportionnel à la taille de la mémoire. Compte tenu de la limite physique des architectures informatiques, la limite supérieure du parallélisme vertical est bien inférieure à la limite supérieure du parallélisme horizontal.
Parallélisme géré
Par défaut, Dataflow gère automatiquement le parallélisme des jobs. Dataflow surveille les statistiques d'exécution du job, telles que l'utilisation du processeur et de la mémoire, afin de déterminer comment procéder au scaling du job en question. En fonction des paramètres de votre job, Dataflow peut effectuer un scaling des jobs horizontalement (Autoscaling horizontal) ou verticalement (Scaling vertical). Le scaling automatique pour le parallélisme optimise le coût et les performances des jobs.
Pour améliorer les performances des jobs, Dataflow optimise également les pipelines en interne. Les optimisations types sont l'optimisation de la fusion et combiner l'optimisation. En fusionnant les étapes du pipeline, Dataflow élimine les coûts inutiles associés à la coordination des étapes dans un système distribué et à l'exécution de chaque étape séparément.
Facteurs ayant une incidence sur le parallélisme
Les facteurs suivants ont une incidence sur le fonctionnement du parallélisme dans les jobs Dataflow.
Source d'entrée
Lorsqu'une source d'entrée n'autorise pas le parallélisme, l'étape d'ingestion de la source d'entrée peut devenir un goulot d'étranglement dans un job Dataflow. Par exemple, lorsque vous ingérez des données à partir d'un seul fichier texte compressé, Dataflow ne peut pas paralléliser les données d'entrée. Étant donné que la plupart des formats de compression ne peuvent pas être divisés de manière arbitraire en segments lors de l'ingestion, Dataflow doit lire les données de manière séquentielle depuis le début du fichier. Le débit global du pipeline est ralenti par la partie non parallèle du pipeline. La solution à ce problème consiste à utiliser une source d'entrée plus évolutive.
Dans certaines instances, la fusion des étapes réduit également le parallélisme. Lorsque la source d'entrée n'autorise pas le parallélisme, si Dataflow fusionne l'étape d'ingestion de données avec les étapes suivantes et attribue cette étape fusionnée à un seul thread, l'ensemble du pipeline peut s'exécuter plus lentement.
Pour éviter ce cas de figure, insérez une étape Reshuffle après l'étape d'ingestion de la source d'entrée. Pour en savoir plus, consultez la section Empêcher la fusion de ce document.
Distribution ramifiée et forme des données par défaut
La distribution ramifiée par défaut d'une seule étape de transformation peut devenir un goulot d'étranglement et limiter le parallélisme. Par exemple, la transformation ParDo à "distribution ramifiée élevée" peut entraîner une fusion limitant la capacité de Dataflow à optimiser l'utilisation des nœuds de calcul. Avec ce type d'opération, vous pouvez avoir une collection d'entrées avec relativement peu d'éléments, mais l'opération ParDo génère une sortie avec des éléments cent fois, voire mille fois plus nombreux, suivis d'une autre opération ParDo. Si le service Dataflow fusionne ces opérations ParDo, le parallélisme de cette étape est limité au maximum au nombre d'éléments de la collection d'entrée, même si la PCollection intermédiaire contient beaucoup plus d'éléments.
Pour connaître les solutions potentielles, consultez la section Empêcher la fusion de ce document.
Forme des données
La forme des données, qu'il s'agisse de données d'entrée ou de données intermédiaires, peut limiter le parallélisme.
Par exemple, lorsqu'une étape GroupByKey sur une clé naturelle, telle qu'une ville, est suivie d'une étape map ou Combine, Dataflow fusionne les deux étapes. Lorsque l'espace clé est petit (par exemple, cinq villes) et qu'une clé est très sollicitée (par exemple, une grande ville), la plupart des éléments dans la sortie de l'étape GroupByKey sont distribués à un processus. Ce processus devient un goulot d'étranglement et ralentit le job.
Dans cet exemple, vous pouvez redistribuer les résultats de l'étape GroupByKey dans un espace clé artificiel plus grand au lieu d'utiliser les clés naturelles. Insérez une étape Reshuffle entre l'étape GroupByKey et l'étape map ou Combine.
Dans l'étape Reshuffle, créez l'espace clé artificiel, par exemple en utilisant une fonction hash, pour contourner le parallélisme limité causé par la forme des données.
Pour en savoir plus, consultez la section Empêcher la fusion de ce document.
Récepteur de sortie
Un récepteur est une transformation qui écrit dans un système de stockage de données externe, tel qu'un fichier ou une base de données. En pratique, les récepteurs sont modélisés et implémentés en tant qu'objets DoFn standards, et sont utilisés pour matérialiser une PCollection dans des systèmes externes.
Dans ce cas, PCollection contient les résultats finaux du pipeline. Les threads qui appellent des API de récepteurs peuvent s'exécuter en parallèle pour écrire des données sur les systèmes externes. Par défaut, aucune coordination entre les threads ne se produit. Sans couche intermédiaire pour mettre en mémoire tampon les requêtes d'écriture et contrôler les flux, le système externe peut être surchargé et réduire le débit en écriture. Le scaling à la hausse des ressources par l'ajout de plus de parallélisme peut ralentir encore davantage le pipeline.
La solution à ce problème consiste à réduire le parallélisme dans l'étape d'écriture.
Vous pouvez ajouter une étape GroupByKey juste avant l'étape d'écriture. L'étape GroupByKey regroupe les données de sortie en un plus petit ensemble de lots afin de réduire le nombre total d'appels RPC et de connexions aux systèmes externes. Par exemple, utilisez une étape GroupByKey pour créer un espace de hachage de 50 points de données sur 1 million.
L'inconvénient de cette approche est qu'elle introduit une limite codée en dur au parallélisme. Une autre option consiste à implémenter un intervalle exponentiel entre les tentatives dans le récepteur lors de l'écriture des données. Cette option permet d'obtenir un étranglement minimal du client.
Surveiller le parallélisme
Pour surveiller le parallélisme, vous pouvez utiliser la console Google Cloud afin d'afficher les retardataires détectés. Pour en savoir plus, consultez les sections Résoudre les problèmes liés aux retardataires dans les jobs par lot et Résoudre les problèmes liés aux retardataires dans les jobs de traitement par flux.
Optimisation de la fusion
Une fois que le format JSON du graphique d'exécution de votre pipeline a été validé, le service Dataflow peut modifier le graphique pour effectuer des optimisations.
Ces optimisations peuvent inclure la fusion de plusieurs étapes ou transformations du graphique d'exécution de votre pipeline en une seule étape. La fusion des étapes évite au service Dataflow de matérialiser chaque classe PCollection intermédiaire de votre pipeline, ce qui peut être coûteux en termes de surcharge de mémoire et de traitement.
Bien que toutes les transformations que vous spécifiez dans votre construction de pipeline soient exécutées sur le service, pour assurer l'exécution la plus efficace de votre pipeline, les transformations peuvent être exécutées dans un ordre différent ou dans le cadre d'une transformation fusionnée plus importante. Le service Dataflow respecte les dépendances de données entre les étapes du graphique d'exécution, mais les autres étapes peuvent être exécutées dans n'importe quel ordre.
Exemple de fusion
Le diagramme suivant montre comment le service Dataflow peut optimiser et fusionner le graphique d'exécution de l'exemple WordCount inclus avec le SDK Apache Beam pour Java pour une exécution efficace :
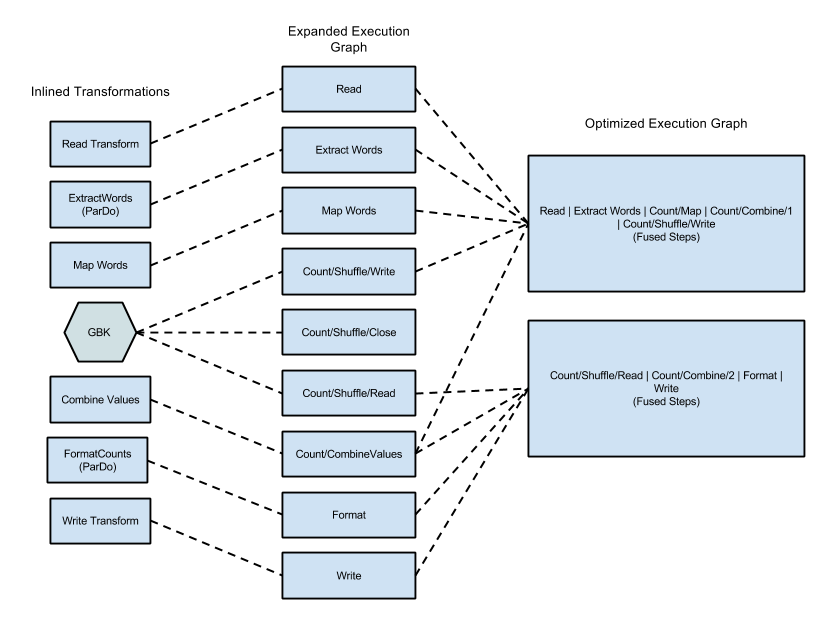
Figure 2 : Exemple de graphique d'exécution optimisé pour WordCount
Empêcher la fusion
Dans certains cas, Dataflow pourrait mal déterminer le moyen optimal pour fusionner des opérations dans le pipeline, ce qui pourrait limiter sa capacité à utiliser tous les nœuds de calcul disponibles. Dans de tels cas, vous pouvez empêcher Dataflow d'effectuer des optimisations de fusion.
Vous pouvez empêcher la fusion d'étapes en ajoutant à votre pipeline une opération qui oblige le service Dataflow à matérialiser votre PCollection intermédiaire. Envisagez d'utiliser l'une des opérations suivantes :
- Insérez une fonction
GroupByKeyet dissociez le groupe après votre première opérationParDo. Le service Dataflow ne fusionne jamais les opérationsParDosur une agrégation. - Transmettez votre
PCollectionintermédiaire en tant qu'entrée secondaire à une autre opérationParDo. Le service Dataflow matérialise toujours les entrées secondaires. - Insérez une étape
Reshuffle.Reshuffleempêche la fusion, contrôle les données et effectue la déduplication des enregistrements. Le rebrassage des données est pris en charge par Dataflow, même s'il est marqué comme obsolète dans la documentation d'Apache Beam.
Surveiller la fusion
Vous pouvez accéder à votre graphique optimisé et à vos étapes fusionnées dans la console Google Cloud, en utilisant gcloud CLI ou l'API.
Console
Pour afficher les étapes et les étapes fusionnées de votre graphique dans la console, ouvrez l'onglet dans l'onglet Détails de l'exécution de votre job Dataflow, ouvrez la vue graphique Workflow des étapes.
Pour afficher les étapes du composant fusionnées pour une étape, cliquez sur l'étape fusionnée dans le graphique. Dans le volet Informations sur l'étape, la ligne Étapes du composant affiche les étapes fusionnées. Parfois, des parties d'une transformation composite unique sont fusionnées en plusieurs étapes.
gcloud
Pour accéder au graphique optimisé et aux étapes fusionnées à l'aide de gcloud CLI, exécutez la commande gcloud suivante :
gcloud dataflow jobs describe --full JOB_ID --format json
Remplacez JOB_ID par l'ID de votre job Dataflow.
Pour extraire les bits pertinents, redirigez la sortie de la commande gcloud vers jq :
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Pour consulter la description des étapes fusionnées dans le fichier de réponse de sortie, dans le tableau ComponentTransform, consultez l'objet ExecutionStageSummary.
API
Pour accéder au graphique optimisé et aux étapes fusionnées à l'aide de l'API, appelez project.locations.jobs.get.
Pour consulter la description des étapes fusionnées dans le fichier de réponse de sortie, dans le tableau ComponentTransform, consultez l'objet ExecutionStageSummary.
Combiner l'optimisation
Les opérations d'agrégation forment un concept important dans le traitement de données à grande échelle.
L'agrégation regroupe des données conceptuellement très éloignées, afin de les rendre extrêmement utiles pour la corrélation. Le modèle de programmation de Dataflow représente les opérations d'agrégation sous la forme des transformations GroupByKey, CoGroupByKey et Combine.
Les opérations d'agrégation de Dataflow combinent des données sur l'intégralité de l'ensemble de données, y compris des données pouvant être réparties sur plusieurs nœuds de calcul. Lors de telles opérations d'agrégation, il est souvent plus efficace de combiner le plus de données possible localement avant de combiner des données sur plusieurs instances. Lorsque vous appliquez une opération GroupByKey ou une autre transformation d'agrégation, le service Dataflow effectue automatiquement une combinaison locale partielle avant l'opération de regroupement principale.
Lors d'une combinaison partielle ou à plusieurs niveaux, le service Dataflow prend différentes décisions selon que votre pipeline utilise des données par lot ou par flux. Pour les données limitées, le service favorise l'efficacité et effectue autant que possible des combinaisons localement. Pour les données non limitées, le service favorise la faible latence et peut éviter d'effectuer des combinaisons partielles, qui risquent d'augmenter la latence.