En esta página, se proporciona una descripción general del ciclo de vida de la canalización desde el código de canalización hasta un trabajo de Dataflow.
En esta página, se explican los siguientes conceptos:
- Qué es un grafo de ejecución y cómo una canalización de Apache Beam se convierte en un trabajo de Dataflow
- Cómo maneja Dataflow los errores
- Cómo Dataflow paraleliza y distribuye de forma automática la lógica de procesamiento de la canalización a los trabajadores que realizan el trabajo
- Optimizaciones de trabajos que Dataflow podría realizar
Grafo de ejecución
Cuando ejecutas la canalización de Dataflow, Dataflow crea un gráfico de ejecución a partir del código que construye tu objeto Pipeline, incluidas todas las transformaciones y sus funciones de procesamiento asociadas, como los objetos DoFn. Este es el grafo de ejecución de la canalización, y la fase se denomina tiempo de construcción del grafo.
Durante la construcción del gráfico, Apache Beam ejecuta de forma local el código desde el punto de entrada principal del código de la canalización, detiene las llamadas a un paso de origen, receptor o transformación y convierte estas llamadas en nodos del gráfico.
En consecuencia, un fragmento de código en el punto de entrada de una canalización (método main de Java y Go, o el nivel superior de una secuencia de comandos de Python) se ejecuta de forma local en la máquina que ejecuta la canalización. El mismo código declarado en un método de un objeto DoFn se ejecuta en los trabajadores de Dataflow.
El ejemplo de WordCount, que se incluye con los SDKs de Apache Beam, contiene una serie de transformaciones a fin de leer, extraer, contar, dar formato y escribir las palabras individuales de una colección de texto, junto con un conteo de casos para cada palabra. En el siguiente diagrama, se muestra cómo las transformaciones en la canalización de WordCount se expanden en un grafo de ejecución:
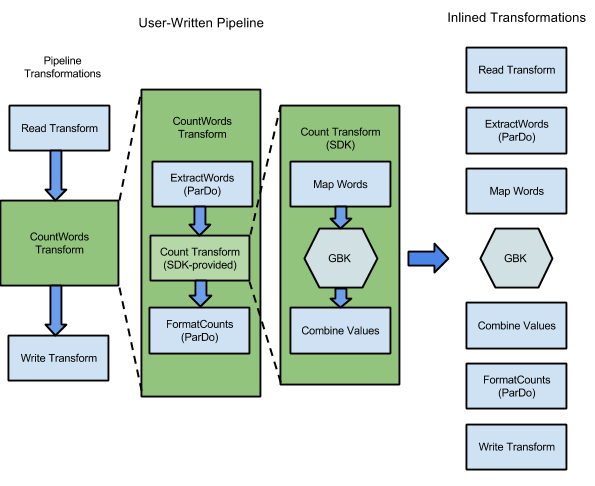
Figura 1: Grafo de ejecución de ejemplo de WordCount
El grafo de ejecución a menudo difiere del orden en el que especificas las transformaciones cuando creas la canalización. Esta diferencia existe debido a que el servicio de Dataflow realiza varias optimizaciones y fusiones en el grafo de ejecución antes de que se ejecute en recursos de nube administrados. El servicio de Dataflow respeta las dependencias de datos cuando ejecuta la canalización. Sin embargo, los pasos sin dependencias de datos entre ellos pueden ejecutarse en cualquier orden.
A fin de ver el gráfico de ejecución no optimizado que Dataflow generó para la canalización, selecciona el trabajo en la interfaz de supervisión de Dataflow. Para obtener más información sobre cómo ver los trabajos, consulta Usa la interfaz de supervisión de Dataflow.
Durante la construcción del gráfico, Apache Beam valida que todos los recursos a los que hace referencia la canalización (como los depósitos de Cloud Storage, las tablas de BigQuery y los temas o suscripciones de Pub/Sub) existan en realidad y sean accesibles. La validación se realiza mediante llamadas estándar a la API a los servicios respectivos, por lo que es fundamental que la cuenta de usuario que se usa para ejecutar una canalización tenga la conectividad adecuada a los servicios necesarios y esté autorizada para llamar a las APIs de los servicios. Antes de enviar la canalización al servicio de Dataflow, Apache Beam también verifica otros errores y se asegura de que el gráfico de la canalización no contenga operaciones ilegales.
El gráfico de ejecución se traduce al formato JSON, y el gráfico de ejecución JSON se transmite al extremo del servicio de Dataflow.
Luego, el servicio de Dataflow valida el grafo de ejecución de JSON. Cuando se valida el grafo, se convierte en un trabajo en el servicio de Dataflow. Puedes ver el trabajo, su grafo de ejecución, el estado y la información de registro mediante la interfaz de supervisión de Dataflow.
Java
El servicio de Dataflow envía una respuesta a la máquina en la que se ejecutó el programa de Dataflow. Esta respuesta se encapsula en el objeto DataflowPipelineJob, que contiene el jobId de tu trabajo de Dataflow.
Usa el jobId para supervisar, hacer seguimiento y solucionar problemas del trabajo mediante la interfaz de supervisión de Dataflow y la interfaz de línea de comandos de Dataflow.
Si deseas obtener más información, consulta la referencia de la API para DataflowPipelineJob.
Python
El servicio de Dataflow envía una respuesta a la máquina en la que se ejecutó el programa de Dataflow. Esta respuesta se encapsula en el objeto DataflowPipelineResult, que contiene el job_id de tu trabajo de Dataflow.
Usa el job_id para supervisar, hacer seguimiento y solucionar problemas del trabajo mediante la interfaz de supervisión de Dataflow y la interfaz de línea de comandos de Dataflow.
Go
El servicio de Dataflow envía una respuesta a la máquina en la que se ejecutó el programa de Dataflow. Esta respuesta se encapsula en el objeto dataflowPipelineResult, que contiene el jobID de tu trabajo de Dataflow.
Usa el jobID para supervisar, hacer seguimiento y solucionar problemas del trabajo mediante la interfaz de supervisión de Dataflow y la interfaz de línea de comandos de Dataflow.
La creación del grafo también se da cuando ejecutas la canalización de forma local, pero el grafo no se traduce a JSON ni se transmite al servicio. En su lugar, el grafo se ejecuta de forma local en la misma máquina en la que se inició el programa de Dataflow. Si deseas obtener más información, consulta Configura PipelineOptions para la ejecución local.
Manejo de errores y excepciones
Tu canalización puede arrojar excepciones durante el procesamiento de datos. Algunos de estos errores son transitorios, como la dificultad temporal para acceder a un servicio externo. Otros errores son permanentes, como los errores causados por datos de entrada corruptos o no analizables, o punteros nulos durante el procesamiento.
Dataflow procesa los elementos en paquetes arbitrarios y vuelve a probar el paquete completo cuando se produce un error de cualquier elemento de ese paquete. Cuando se ejecutan en modo por lotes, los paquetes que incluyen un artículo defectuoso se reintentan cuatro veces. Si un paquete individual falla cuatro veces, la canalización fallará por completo. Cuando se ejecuta en modo de transmisión, un paquete que incluye un elemento defectuoso se reintenta de forma indefinida, lo que puede hacer que la canalización se estanque de forma permanente.
Cuando se procesa en modo por lotes, es posible que veas una gran cantidad de fallas individuales antes de que un trabajo de canalización falle por completo, lo cual ocurre cuando un paquete determinado falla después de cuatro reintentos. Por ejemplo, si la canalización intenta procesar 100 paquetes, en teoría, Dataflow podría generar varios cientos de fallas individuales hasta que un solo paquete alcance la condición de cuatro fallas para la salida.
Los errores de los trabajadores de inicio, como la falta de instalación de paquetes en los trabajadores, son transitorios. Esta situación da como resultado reintentos indefinidos y podría provocar que la canalización se detenga de forma permanente.
Paralelización y distribución
El servicio de Dataflow paraleliza y distribuye de forma automática la lógica de procesamiento de la canalización a los trabajadores que asignas para que realicen el trabajo. Dataflow usa las abstracciones en el modelo de programación para representar las funciones de procesamiento paralelo. Por ejemplo, las transformaciones ParDo en una canalización hacen que Dataflow distribuya de forma automática el código de procesamiento, representado por objetos DoFn, a varios trabajadores para que se ejecuten en paralelo.
Existen dos tipos de paralelismo de trabajos:
El paralelismo horizontal ocurre cuando los datos de canalización se dividen y se procesan en varios trabajadores al mismo tiempo. El entorno de ejecución de Dataflow funciona con un grupo de trabajadores distribuidos. Una canalización tiene un paralelismo mayor cuando el grupo contiene más trabajadores, pero esa configuración también tiene un costo más alto. En teoría, el paralelismo horizontal no tiene un límite superior. Sin embargo, Dataflow limita el grupo de trabajadores a 4,000 trabajadores para optimizar el uso de recursos en toda la flota.
El paralelismo vertical ocurre cuando varios núcleos de CPU dividen y procesan los datos de canalización en el mismo trabajador. Cada trabajador cuenta con la tecnología de una VM de Compute Engine. Una VM puede ejecutar varios procesos para saturar todos sus núcleos de CPU. Una VM con más núcleos tiene un paralelismo vertical potencial más alto, pero esta configuración genera costos más altos. Una mayor cantidad de núcleos a menudo genera un aumento en el uso de memoria, por lo que la cantidad de núcleos suele escalar junto con el tamaño de la memoria. Dado el límite físico de las arquitecturas de computadora, el límite superior del paralelismo vertical es mucho menor que el límite superior del paralelismo horizontal.
Paralelismo administrado
De forma predeterminada, Dataflow administra de forma automática el paralelismo de trabajos. Dataflow supervisa las estadísticas de entorno de ejecución del trabajo, como el uso de la CPU y la memoria, para determinar cómo escalar el trabajo. Según la configuración de tu trabajo, Dataflow puede escalar trabajos de forma horizontal, lo que se denomina Ajuste de escala automático horizontal o verticalmente, lo que se denomina Escalamiento vertical. El ajuste de escala automático para el paralelismo optimiza el costo y su rendimiento.
Para mejorar el rendimiento del trabajo, Dataflow también optimiza las canalizaciones de forma interna. Las optimizaciones típicas son la optimización de fusiones y la optimización de combinaciones. Cuando fusionas los pasos de canalización, Dataflow elimina los costos innecesarios asociados con la coordinación de pasos en un sistema distribuido y la ejecución de cada paso individual por separado.
Factores que afectan el paralelismo
Los siguientes factores afectan el funcionamiento del paralelismo en los trabajos de Dataflow.
Fuente de entrada
Cuando una fuente de entrada no permite el paralelismo, el paso de transferencia de la fuente de entrada puede convertirse en un cuello de botella en un trabajo de Dataflow. Por ejemplo, cuando transfieres datos desde un solo archivo de texto comprimido, Dataflow no puede paralelizar los datos de entrada. Debido a que la mayoría de los formatos de compresión no se pueden dividir de forma arbitraria en fragmentos durante la transferencia, Dataflow debe leer los datos de forma secuencial desde el comienzo del archivo. La capacidad de procesamiento general de la canalización ralentiza la parte no paralela de la canalización. La solución a este problema es usar una fuente de entrada más escalable.
En algunos casos, la fusión de pasos también reduce el paralelismo. Cuando la fuente de entrada no permite el paralelismo, si Dataflow fusiona el paso de transferencia de datos con los pasos posteriores y asigna este paso fusionado a un solo subproceso, toda la canalización podría ejecutarse más lento.
Para evitar esta situación, inserta un paso Reshuffle después del paso de transferencia de la fuente de entrada. Para obtener más información, consulta la sección Evita la fusión de este documento.
Fanout predeterminado y forma de datos
El fanout predeterminado de un solo paso de transformación puede convertirse en un cuello de botella y limitar el paralelismo. Por ejemplo, la transformación ParDo con “fan-out alto” puede hacer que la fusión limite la capacidad de Dataflow de optimizar el uso de los trabajadores. En esta operación, podrías tener una colección de entrada con pocos elementos, pero la ParDo genera una salida que tiene cientos o miles de veces esa cantidad, seguida de otra ParDo. Si el servicio de Dataflow fusiona estas operaciones ParDo, el paralelismo en este paso se limita a la cantidad máxima de elementos en la colección de entrada, aunque la PCollection intermedia contenga muchos más elementos.
Para encontrar posibles soluciones, consulta la sección Evita la fusión de este documento.
Forma de los datos
La forma de los datos, ya sean datos de entrada o intermedios, puede limitar el paralelismo.
Por ejemplo, cuando a un paso GroupByKey en una clave natural, como una ciudad, le sigue un paso map o Combine, Dataflow fusiona los dos pasos. Cuando el espacio clave es pequeño, por ejemplo, cinco ciudades y una clave es muy activa, por ejemplo, una ciudad grande, la mayoría de los elementos del resultado del paso GroupByKey se distribuyen en un proceso. Este proceso se convierte en un cuello de botella y ralentiza el trabajo.
En este ejemplo, puedes redistribuir los resultados del paso GroupByKey en un espacio de claves artificial más grande en lugar de usar las claves naturales. Inserta un paso Reshuffle entre el paso GroupByKey y el paso map o Combine.
En el paso Reshuffle, crea el espacio de claves artificial, por ejemplo, mediante una función hash, para superar el paralelismo limitado causado por la forma de datos.
Para obtener más información, consulta la sección Evita la fusión de este documento.
Receptor de salida
Un receptor es una transformación que escribe en un sistema de almacenamiento de datos externo, como un archivo o una base de datos. En la práctica, los receptores se modelan y se implementan como objetos DoFn estándar y se usan para materializar un PCollection en sistemas externos.
En este caso, PCollection contiene los resultados finales de la canalización. Los subprocesos que llaman a las APIs de receptor pueden ejecutarse en paralelo para escribir datos en los sistemas externos. De forma predeterminada, no se produce ninguna coordinación entre los subprocesos. Sin una capa intermedia para almacenar en búfer las solicitudes de escritura y el flujo de control, el sistema externo puede sobrecargarse y reducir la capacidad de procesamiento de escritura. Escalar los recursos mediante la adición de más paralelismo puede ralentizar aún más la canalización.
La solución a este problema es reducir el paralelismo en el paso de escritura.
Puedes agregar un paso GroupByKey justo antes del paso de escritura. El paso GroupByKey agrupa los datos de salida en un conjunto más pequeño de lotes para reducir el total de llamadas RPC y conexiones a sistemas externos. Por ejemplo, usa un GroupByKey para crear un espacio de hash de 50 de 1 millón de datos.
La desventaja de este enfoque es que ingresa un límite codificado para el paralelismo. Otra opción es implementar la retirada exponencial en el receptor cuando se escriben datos. Esta opción puede proporcionar una limitación de clientes mínima.
Supervisa el paralelismo
A fin de supervisar el paralelismo, puedes usar la consola de Google Cloud para ver los retrasos demorados. Para obtener más información, consulta Solución de problemas de rezagados en trabajos por lotes y Solución de problemas de rezagados en trabajos de transmisión.
Optimización de fusiones
Una vez que se haya validado el formulario JSON del grafo de ejecución de canalización, es posible que el servicio de Dataflow modifique el grafo para realizar optimizaciones.
Las optimizaciones pueden incluir la fusión de varios pasos o transformaciones en el grafo de ejecución de tu canalización en pasos únicos. Los pasos de fusión evitan que el servicio de Dataflow tenga que materializar cada PCollection intermedia en la canalización, lo que podría ser costoso en términos de sobrecarga de procesamiento y memoria.
Aunque todas las transformaciones que especificas en la construcción de tu canalización se ejecutan en el servicio, para garantizar la ejecución más eficiente de tu canalización, las transformaciones pueden ejecutarse en un orden diferente o como parte de una transformación fusionada más grande. El servicio de Dataflow respeta las dependencias de datos entre los pasos en el grafo de ejecución, pero los demás pasos se pueden ejecutar en cualquier orden.
Ejemplo de fusión
En el siguiente diagrama, se muestra cómo el grafo de ejecución del ejemplo de WordCount incluido en el SDK de Apache Beam para Java podría optimizarse y fusionarse mediante el servicio de Dataflow a fin de obtener una ejecución eficiente:
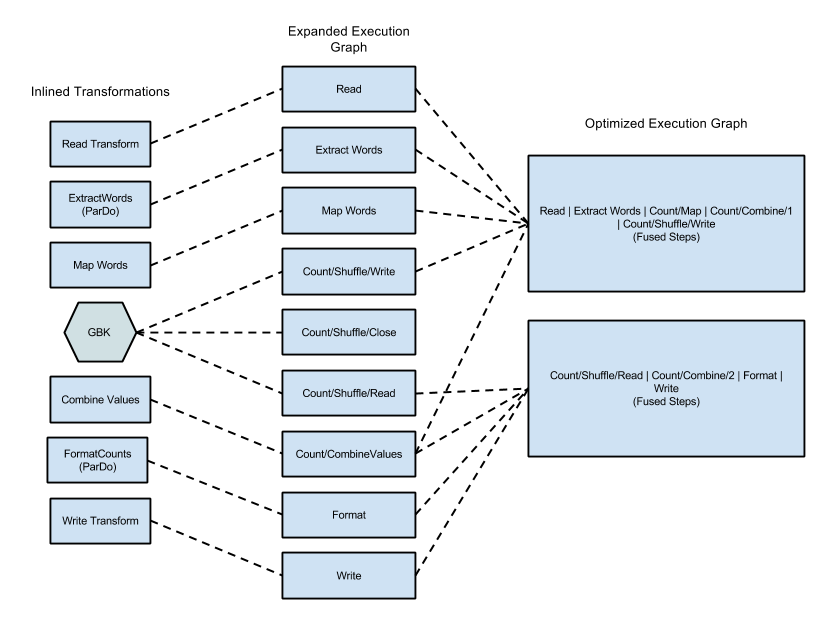
Figura 2: Grafo de ejecución optimizado del ejemplo de WordCount
Evita la fusión
En algunos casos, Dataflow podría suponer de forma incorrecta la mejor manera de fusionar operaciones en la canalización, lo que puede limitar la capacidad de Dataflow de usar todos los trabajadores disponibles. En esos casos, puedes evitar que Dataflow realice optimizaciones de fusión.
Para evitar la fusión de pasos, agrega una operación a la canalización que obligue al servicio de Dataflow a materializar la PCollection intermedia. Considera usar una de las siguientes operaciones:
- Inserta una
GroupByKeyy desagrupa después de tu primerParDo. El servicio de Dataflow nunca fusiona las operacionesParDoen una agregación. - Pasa la
PCollectionintermedia como una entrada complementaria a otroParDo. El servicio de Dataflow siempre materializa las entradas complementarias. - Inserta un paso
Reshuffle.Reshuffleevita la fusión, controla los datos y realiza la anulación de duplicación de registros. Dataflow admite que se vuelva a reproducir aleatoriamente, aunque está marcada como obsoleta en la documentación de Apache Beam.
Supervisa la fusión
Puedes acceder a tu grafo optimizado y a las etapas fusionadas en la consola de Google Cloud, a través de la CLI de gcloud o la API.
Console
Para ver las etapas y pasos fusionados del grafo en la consola, en la pestaña Detalles de la ejecución del trabajo de Dataflow, abre la vista de grafo Flujo de trabajo de la etapa.
Si deseas ver los pasos de los componentes fusionados para una etapa, en el grafo, haz clic en la etapa fusionada. En el panel Información de la etapa, la fila Pasos de los componentes muestra las etapas fusionadas. A veces, las partes de una sola transformación compuesta se fusionan en varias etapas.
gcloud
Para acceder a tu grafo optimizado y a las etapas fusionadas a través de la CLI de gcloud, ejecuta el siguiente comando de gcloud:
gcloud dataflow jobs describe --full JOB_ID --format json
Reemplaza JOB_ID por el ID de tu trabajo de Dataflow.
Para extraer los bits relevantes, canaliza el resultado del comando gcloud a jq:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Para ver la descripción de las etapas fusionadas en el archivo de respuesta de salida, dentro del array ComponentTransform, consulta el objeto ExecutionStageSummary.
API
Para acceder a tu grafo optimizado y a las etapas fusionadas a través de la API, llama a project.locations.jobs.get.
Para ver la descripción de las etapas fusionadas en el archivo de respuesta de salida, dentro del array ComponentTransform, consulta el objeto ExecutionStageSummary.
Optimización de combinaciones
Las operaciones de agregación son un concepto importante en el procesamiento de datos a gran escala.
La agregación reúne datos que están muy separados en lo conceptual, por lo que es muy útil para la correlación. El modelo de programación de Dataflow representa las operaciones de agregación como las transformaciones GroupByKey, CoGroupByKey y Combine.
Las operaciones de agregación de Dataflow combinan datos de todo el conjunto de datos, incluidos los que se podrían distribuir entre varios trabajadores. Durante estas operaciones de agregación, a menudo es más eficiente combinar la mayor cantidad de datos posible de forma local antes de combinarlos entre instancias. Cuando aplicas una GroupByKey o alguna otra transformación de agregación, el servicio de Dataflow realiza una combinación parcial a nivel local de forma automática antes de la operación de agrupación principal.
Cuando se realiza una combinación parcial o multinivel, el servicio de Dataflow toma decisiones diferentes en función de si la canalización funciona con datos de transmisión o por lotes. Para datos limitados, el servicio favorece la eficiencia y realizará toda la combinación local posible. Para datos ilimitados, el servicio prefiere una latencia más baja y puede que no realice una combinación parcial, ya que podría aumentar la latencia.