本页面介绍如何查找和解决 Dataflow 中的内存不足 (OOM) 错误。
发现内存不足错误
如需确定流水线是否会耗尽内存,请使用以下方法之一。
- 在作业详情页面的日志窗格中,查看诊断标签页。 此标签页显示与内存问题相关的错误以及错误发生的频率。
- 在 Dataflow 监控界面中,使用内存利用率图表监控工作器内存容量和使用情况。
- 在作业详情页面的日志窗格中,选择工作器日志以查找工作器日志中的内存不足错误。
内存不足错误也可能会出现在系统日志中。如需查看这些内容,请前往 Logs Explorer 并使用以下查询:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"将 JOB_ID 替换为您的作业的 ID。
对于 Java 作业,Java 内存监控器会定期报告垃圾回收指标。如果用于垃圾回收的 CPU 时间在较长的一段时间内所占的比例超过 50% 的阈值,则 SDK 自动化测试框架会失败。您可能会看到类似于以下示例的错误:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...在仍有可用的物理内存时,可能会发生此错误,这通常表示流水线的内存使用效率不高。如需解决此问题,请优化流水线。
Java 内存监控器通过
MemoryMonitorOptions接口进行配置。
如果您的作业存在高内存用量或内存不足错误,请按照本页面上的建议优化内存用量或增加可用内存量。
解决内存不足错误
更改 Dataflow 流水线可能会解决内存不足错误或减少内存用量。可能的更改包括以下操作:
下图展示了本页面介绍的 Dataflow 问题排查工作流。
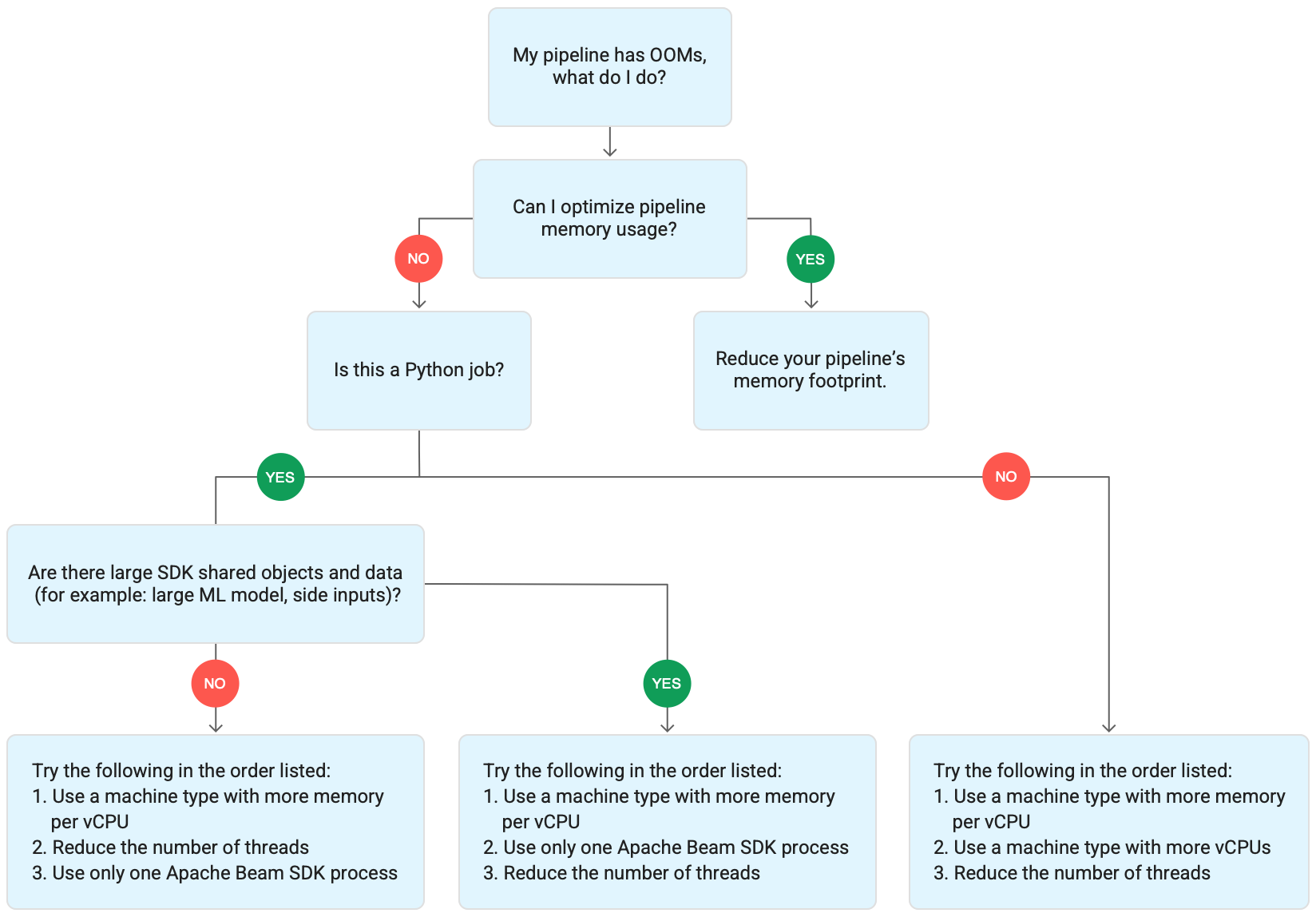
请尝试以下缓解措施:
- 如果可能,请优化流水线以减少内存用量。
- 如果作业是批量作业,请按列出的顺序尝试以下步骤:
- 使用每个 vCPU 具有更多内存的机器类型
- 将线程数减少到小于每个工作器的 vCPU 数量。
- 使用每个 vCPU 具有更多内存的自定义机器类型
- 如果作业是使用 Python 的流式作业,请将线程数减少到 12 以下。
- 如果作业是使用 Java 或 Go 的流式作业,请尝试以下操作:
- 对于 Runner v2 作业,请将线程数减至 500 以下;对于不使用 Runner v2 的作业,请将线程数减至 300 以下。
- 使用具有更多内存的机器类型。
优化流水线
多项流水线操作可能会导致内存不足错误。本部分提供了用于减少流水线内存用量的选项。如需确定消耗最多内存的流水线阶段,请使用 Cloud Profiler 来监控流水线性能。
您可以按照以下最佳实践来优化流水线:
- 使用 Apache Beam 内置 I/O 连接器读取文件
- 使用
GroupByKeyPTransform 时重新设计操作 - 减少来自外部来源的入站流量数据
- 跨线程共享对象
- 使用内存高效的元素表示法
- 减小辅助输入的大小
- 使用 Apache Beam 可拆分 DoFn
使用 Apache Beam 内置 I/O 连接器读取文件
请勿在 DoFn 中打开大型文件。如需读取文件,请使用 Apache Beam 内置 I/O 连接器。
在 DoFn 中打开的文件必须适合内存。由于多个 DoFn 实例并发运行,因此在 DoFn 中打开的大型文件可能会导致内存不足错误。
使用 GroupByKey PTransform 时重新设计操作
在 Dataflow 中使用 GroupByKey PTransform 时,生成的每个键值和每个窗口值都会在单个线程上进行处理。由于此数据以数据流的形式从 Dataflow 后端服务传递到工作器,因此不需要适合工作器内存。但是,如果这些值是在内存中收集的,则处理逻辑可能会导致内存不足错误。
例如,如果您有一个包含窗口数据的键,并且将该键值添加到内存中对象(例如列表),则可能会发生内存不足错误。在这种情况下,工作器可能没有足够的内存容量来容纳所有对象。
如需详细了解 GroupByKey PTransforms,请参阅 Apache Beam Python GroupByKey 和 Java GroupByKey 文档。
以下列表包含有关设计流水线以在使用 GroupByKey PTransform 时最大限度地减少内存消耗量的建议。
- 如需减少每个键和每个窗口的数据量,请避免使用具有多个值的键(也称为热键)。
- 如需减少每个窗口收集的数据量,请使用较小的窗口。
- 如果您要在窗口中使用键值来计算数量,请使用
Combine转换。 请勿在收集值后在单个DoFn实例中执行计算。 - 在处理之前,先过滤值或重复项。如需了解详情,请参阅 Python
Filter和 JavaFilter转换文档。
减少来自外部来源的入站流量数据
如果您要调用外部 API 或数据库来丰富数据,则返回的数据必须适合工作器内存。
如果要批量调用,建议使用 GroupIntoBatches 转换。
如果您遇到内存不足错误,请减小批次大小。如需详细了解如何分组成多个批次,请参阅 Python GroupIntoBatches 和 Java GroupIntoBatches 转换文档。
跨线程之间共享对象
跨 DoFn 实例共享内存中数据对象可以提高空间和访问效率。在 DoFn 的任何方法(包括 Setup、StartBundle、Process、FinishBundle 和 Teardown)中创建的数据对象都会针对每个 DoFn 调用。在 Dataflow 中,每个工作器可能有多个 DoFn 实例。为了实现更高效的内存用量,请将数据对象作为单例传递,以便在多个 DoFn 之间共享该数据对象。如需了解详情,请参阅在 DoFn 之间重复使用缓存博文。
使用内存高效的元素表示法
评估是否可以为使用较少内存的 PCollection 元素使用表示法。在流水线中使用编码器时,请同时考虑经过编码和解码的 PCollection 元素表示法。稀疏矩阵通常可从此类优化中获益。
减小辅助输入的大小
如果 DoFn 使用辅助输入,请减小辅助输入的大小。对于属于元素集合的辅助输入,请考虑使用可迭代视图(例如 AsIterable 或 AsMultimap),而不是同时具体化整个辅助输入的视图(例如 AsList)。
减少线程数
您可以通过减少运行 DoFn 实例的线程数上限,来增加每个线程的可用内存。此更改会降低并行数,但会为每个 DoFn 提供更多可用内存。
下表显示了 Dataflow 创建的默认线程数:
| 作业类型 | Python SDK | Java/Go SDK |
|---|---|---|
| 批量 | 每个 vCPU 1 个线程 | 每个 vCPU 1 个线程 |
| 使用 Runner v2 进行流式传输 | 每个 vCPU 12 个线程 | 每个工作器虚拟机 500 个线程 |
| 不使用 Runner v2 进行流式传输 | 每个 vCPU 12 个线程 | 每个工作器虚拟机 300 个线程 |
如需减少 Apache Beam SDK 线程数,请设置以下流水线选项:
Java
使用 --numberOfWorkerHarnessThreads 流水线选项。
Python
使用 --number_of_worker_harness_threads 流水线选项。
Go
使用 --number_of_worker_harness_threads 流水线选项。
对于批量作业,请将该值设置为小于 vCPU 数量的数字。
对于流式作业,请先将该值减半。如果此步骤未缓解问题,请继续将值减半,并观察每个步骤的结果。例如,使用 Python 时,请尝试使用值 6、3 和 1。
使用每个 vCPU 具有更多内存的机器类型
如需选择每个 vCPU 具有更多内存的工作器,请使用以下方法之一。
- 使用通用机器家族中的高内存机器类型。与标准机器类型相比,高内存机器类型的每个 vCPU 具有更高内存。使用高内存机器类型会增加可供每个工作器使用的内存和每个线程的可用内存,因为 vCPU 的数量保持不变。因此,使用高内存机器类型是用于选择每个 vCPU 具有更多内存的工作器的经济实惠方法。
- 为了在指定 vCPU 数量和内存量时提高灵活性,您可以使用自定义机器类型。借助自定义机器类型,您可以以 256 MB 为增量增加内存。这些机器类型的价格与标准机器类型不同。
- 某些机器系列允许您使用扩展内存自定义机器类型。 扩展内存可实现更高的每 vCPU 内存比率。费用较高。
如需设置工作器类型,请使用以下流水线选项。如需了解详情,请参阅设置流水线选项和流水线选项。
Java
使用 --workerMachineType 流水线选项。
Python
使用 --machine_type 流水线选项。
Go
使用 --worker_machine_type 流水线选项。
仅使用一个 Apache Beam SDK 进程
对于 Python 流处理流水线和使用 Runner v2 的 Python 流水线,您可以强制 Dataflow 仅为每个工作器启动一个 Apache Beam SDK 进程。在尝试此选项之前,请先尝试使用其他方法解决问题。如需将 Dataflow 工作器虚拟机配置为仅启动一个容器化 Python 进程,请使用以下流水线选项:
--experiments=no_use_multiple_sdk_containers
使用此配置时,Python 流水线会为每个工作器创建一个 Apache Beam SDK 进程。此配置可以防止针对每个 Apache Beam SDK 进程多次复制共享对象和数据。但是,它限制了工作器上提供的计算资源的高效使用。
将 Apache Beam SDK 进程数减少到一个不一定会减少工作器上启动的线程总数。此外,将所有线程置于单个 Apache Beam SDK 进程可能会导致处理速度降低或导致流水线卡住。因此,您可能还必须减少线程数,如本页面中的减少线程数部分所述。
您也可以通过使用仅具有一个 vCPU 的机器类型来强制工作器仅使用一个 Apache Beam SDK 进程。
了解 Dataflow 内存用量
如需排查内存不足错误,了解 Dataflow 流水线如何使用内存会很有帮助。
当 Dataflow 运行流水线时,系统会在多个 Compute Engine 虚拟机 (VM) 之间进行分布式处理,通常称为工作器。工作器处理 Dataflow 服务中的工作项,并将工作项委托给 Apache Beam SDK 进程。Apache Beam SDK 进程会创建 DoFn 的实例。DoFn 是一个用于定义分布式处理函数的 Apache Beam SDK 类。
Dataflow 会在每个工作器上启动多个线程,并且每个工作器的内存会在所有线程之间共享。线程是在较大的进程中运行的单个可执行任务。默认线程数取决于多种因素,并且因批量作业和流式作业而异。
如果流水线需要的内存超过工作器上可用的默认内存量,您可能会遇到内存不足错误。
Dataflow 流水线主要通过以下三种方式使用工作器内存:
工作器运行内存
Dataflow 工作器的操作系统和系统进程需要内存。工作器内存用量通常不超过 1 GB。用量通常少于 1 GB。
- 工作器上的各种进程使用内存来确保流水线处于正常运行状态。每个进程都可能为其运行保留少量内存。
- 如果您的流水线不使用 Streaming Engine,其他工作器进程会使用内存。
SDK 进程内存
Apache Beam SDK 进程可能会创建在该进程中的线程之间共享的对象和数据,在本页面上称为 SDK 共享对象和数据。这些 SDK 共享对象和数据的内存用量称为 SDK 进程内存。以下列表包含 SDK 共享对象和数据示例:
- 辅助输入
- 机器学习模型
- 内存内单例对象
- 使用
apache_beam.utils.shared模块创建的 Python 对象 - 从外部来源(如 Cloud Storage 或 BigQuery)加载数据
不使用 Streaming Engine 的流式传输作业会将辅助输入存储在内存中。对于 Java 和 Go 流水线,每个工作器都有一个辅助输入副本。对于 Python 流水线,每个 Apache Beam SDK 进程都有一个辅助输入副本。
使用 Streaming Engine 的流式作业的辅助输入大小上限为 80 MB。辅助输入存储在工作器内存之外。
SDK 共享对象和数据的内存用量与 Apache Beam SDK 进程数呈线性增长关系。在 Java 和 Go 流水线中,每个工作器会启动一个 Apache Beam SDK 进程。在 Python 流水线中,每个 vCPU 会启动一个 Apache Beam SDK 进程。 SDK 共享对象和数据会在同一 Apache Beam SDK 进程内的线程中重复使用。
DoFn 内存用量
DoFn 是一个用于定义分布式处理函数的 Apache Beam SDK 类。每个工作器可以运行并发 DoFn 实例。每个线程运行一个 DoFn 实例。在评估总内存用量时,计算工作集大小或应用继续正常运行所需的内存量可能会有帮助。例如,如果单个 DoFn 最多使用 5 MB 内存并且一个工作器具有 300 个线程,则 DoFn 内存用量峰值可能为 1.5 GB,或者是内存的字节数乘以线程数。内存用量激增可能会导致工作器耗尽内存,具体取决于工作器使用内存的方式。
很难估算 DoFn Dataflow 创建的实例数。具体数字取决于 SDK、机器类型等各种因素。此外,DoFn 可能会由多个线程连续使用。Dataflow 服务无法保证 DoFn 的调用次数,也无法保证在流水线过程中创建的确切 DoFn 实例数量。但是,下表让您可以了解预期的并行级别,并估算了 DoFn 实例数上限。
Beam Python SDK
| 批量 | 不使用 Streaming Engine 进行流式传输 | Streaming Engine | |
|---|---|---|---|
| 最大并行数量 |
每个 vCPU 1 个进程 每个进程 1 个线程 每个 vCPU 1 个线程
|
每个 vCPU 1 个进程 每个进程 12 个线程 每个 vCPU 12 个线程 |
每个 vCPU 1 个进程 每个进程 12 个线程 每个 vCPU 12 个线程
|
并发 DoFn 实例数上限(所有这些数字随时可能更改)。 |
每个线程 1 个 DoFn每个 vCPU 1 个
|
每个线程 1 个 DoFn每个 vCPU 12 个
|
每个线程 1 个 DoFn每个 vCPU 12 个
|
Beam Java/Go SDK
| 批量 | 未使用 runner v2 的 Streaming Appliance 和 Streaming Engine | 使用 runner v2 的 Streaming Engine | |
|---|---|---|---|
| 最大并行数量 |
每个工作器虚拟机 1 个进程 每个 vCPU 1 个线程
|
每个工作器虚拟机 1 个进程 每个进程 300 个线程 每个工作器虚拟机 300 个线程
|
每个工作器虚拟机 1 个进程 每个进程 500 个线程 每个工作器虚拟机 500 个线程
|
并发 DoFn 实例数上限(所有这些数字随时可能更改)。 |
每个线程 1 个 DoFn每个 vCPU 1 个
|
每个线程 1 个 DoFn
每个工作器虚拟机 300 个
|
每个线程 1 个 DoFn
每个工作器虚拟机 500 个
|
例如,将 Python SDK 与 n1-standard-2 Dataflow 工作器搭配使用时,以下情况适用:
- 批量作业:Dataflow 为每个 vCPU 启动一个进程(在本例中为两个)。每个进程使用一个线程,每个线程创建一个
DoFn实例。 - 使用 Streaming Engine 的流式作业:Dataflow 为每个 vCPU 启动一个进程(总共两个)。不过,每个进程最多可以衍生 12 个线程,每个线程都有其自己的 DoFn 实例。
当您设计复杂的流水线时,请务必了解 DoFn 生命周期。确保 DoFn 函数可序列化,并避免在其中直接修改元素参数。
如果您有多语言流水线,并且在工作器上运行多个 Apache Beam SDK,则工作器会使用尽可能低的每进程线程并行度。
Java、Go 和 Python 区别
Java、Go 和 Python 管理进程和内存的方式有所不同。因此,排查内存不足错误时应采用的方法因流水线是使用 Java、Go 还是 Python 而异。
Java 和 Go 流水线
在 Java 和 Go 流水线中:
- 每个工作器启动一个 Apache Beam SDK 进程。
- SDK 共享对象和数据(如辅助输入和缓存)在工作器上的所有线程之间共享。
- SDK 共享对象和数据使用的内存通常不会根据工作器上的 vCPU 数量进行扩缩。
Python 流水线
在 Python 流水线中:
- 每个工作器会为每个 vCPU 启动一个 Apache Beam SDK 进程。
- SDK 共享对象和数据(如辅助输入和缓存)在每个 Apache Beam SDK 进程中的所有线程之间共享。
- 工作器上的线程总数根据 vCPU 数量进行线性扩缩。因此,SDK 共享对象和数据使用的内存与 vCPU 数量呈线性增长。
- 执行工作的线程分布在多个进程中。新的工作单元会分配给没有工作项的进程,或者当前分配的工作项最少的进程。