Dataflow 会收集您的作业指标,这可以帮助您调试错误、排查性能问题或优化流水线。Dataflow 监控界面会显示这些指标的可视化图表。您还可以使用 Cloud Monitoring 创建提醒或构建 Metrics Explorer 查询。
访问作业指标
如需查看作业的作业指标,请执行以下步骤:
在 Google Cloud 控制台中,依次前往 Dataflow > 作业页面。
选择一个作业。
点击作业指标标签页。
选择要查看的指标。
如需访问作业指标图表中的其他信息,请点击 探索数据。
每个指标都会整理到以下信息中心内:
支持和限制
使用 Dataflow 指标时,请注意以下详细信息。
有时,作业数据间歇性不可用。如果缺少数据,作业监控图表中将显示缺口。
其中一些图表特定于流式处理流水线。
如需写入指标数据,用户管理的服务账号必须具有 IAM API 权限
monitoring.timeSeries.create。此权限包含在 Dataflow Worker 角色中。Dataflow 服务在作业完成后报告预留的 CPU 时间。对于无界限(流式)作业,仅在作业取消或失败后才会报告预留 CPU 时间。因此,作业指标不包括流式作业的预留 CPU 时间。
自动扩缩指标
横向自动扩缩使 Dataflow 能够为作业选择适当数量的工作器实例,并根据需要添加或移除工作器。
作业指标标签页的自动扩缩部分会显示一段时间内的工作器数量和目标工作器数量。如果您的作业使用 Streaming Engine,还会显示工作器数量下限和上限。
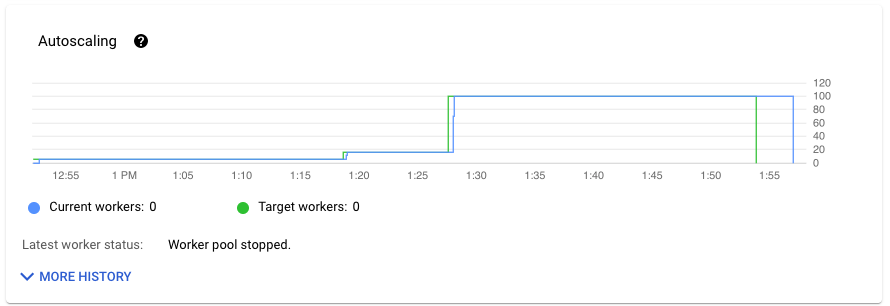
如需查看自动扩缩更改历史记录,请点击更多历史记录。此时会显示一个表格,其中包含作业的工作器历史记录信息。
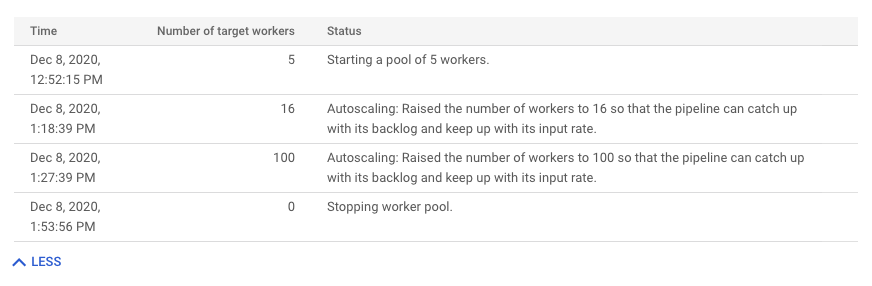
如需查看流式作业的其他自动扩缩信息,请点击自动扩缩标签页。如需了解详情,请参阅监控 Dataflow 自动扩缩。
指标概览
以下指标会显示在概览指标下。
数据新鲜度
此指标仅适用于流式作业。
数据新鲜度是处理数据元素的时间(处理时间)与数据元素的时间戳(事件时间)之间的差值。值越高,事件时间和处理时间之间的延迟就越长。
数据新鲜度图表会显示任意时间点的最大数据新鲜度值。Dataflow 会并行处理多个元素,因此该图表会反映相对于事件时间具有最长延迟时间的元素。
如果尚未处理某些输入数据,则输出水印可能会延迟,从而影响数据新鲜度。如果水印时间与事件时间之间存在显著差异,则表示操作缓慢或停滞。 如需了解详情,请参阅 Apache Beam 文档中的水印和延迟数据部分。
信息中心包括以下两个图表:
- 数据新鲜度(按阶段)
- 数据新鲜度
在下图中,突出显示的区域表明事件时间和输出水印时间之间存在显著差异,这表示操作缓慢。
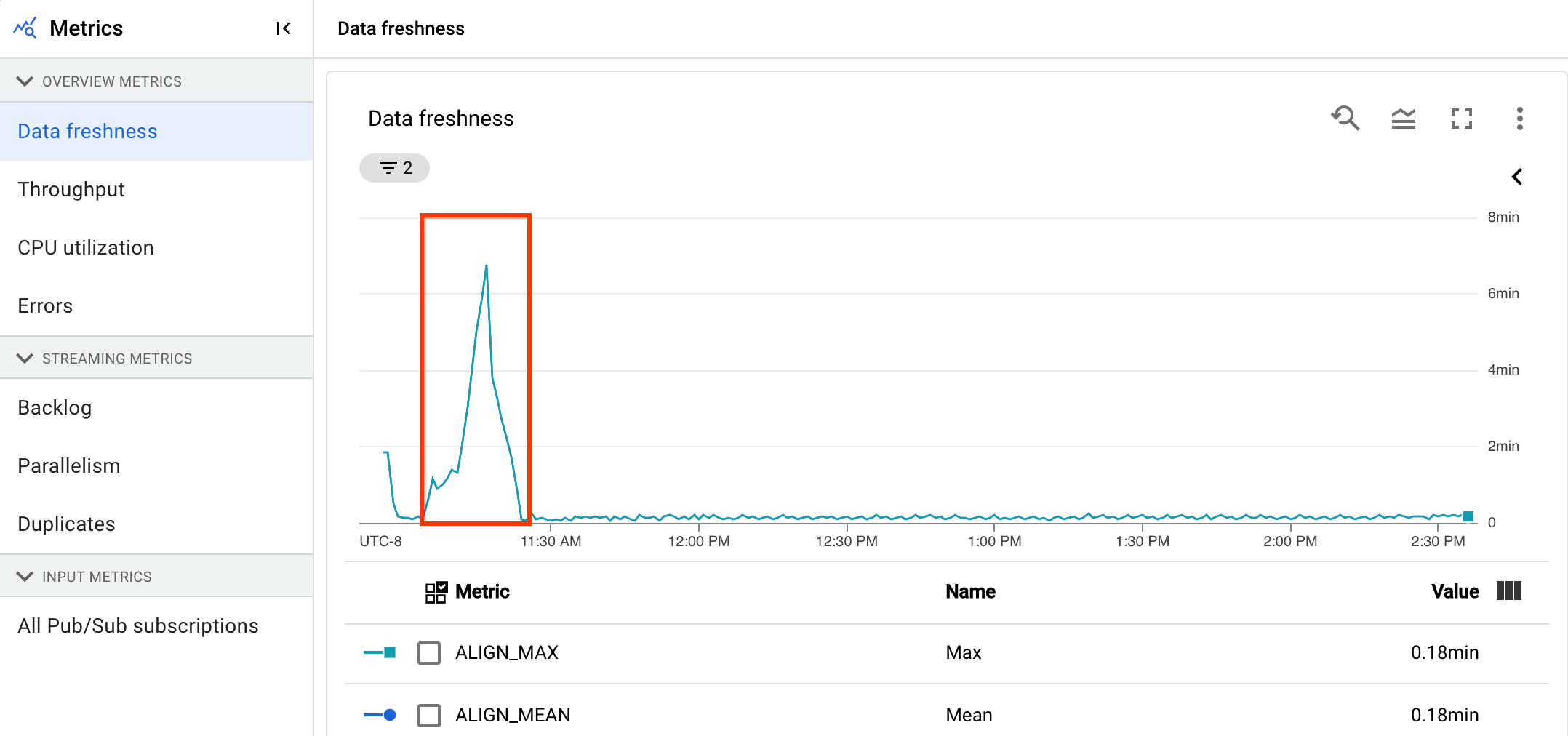
以下问题可能会导致此指标的值较高:
- 性能瓶颈:如果流水线的某些阶段具有较长的系统延迟时间或流水线的日志指示转换卡住,则流水线可能存在可能会提高数据新鲜度的性能问题。如需进一步调查,请参阅排查流处理作业缓慢或卡住的问题。
- 数据源瓶颈:如果数据源的积压工作不断增长,元素的事件时间戳可能与水印不同,因为它们要等待处理。积压工作过多通常是由性能瓶颈或数据源问题引起的,检测这些问题的最佳方式为监控流水线所用的来源。
- 注意:即使以高速率输出,无序来源(如 Pub/Sub)也会生成延迟的水印。出现这种情况是因为元素不是按时间戳顺序输出的,而水印则基于未处理的时间戳下限。
- 频繁重试:如果您发现有错误表明元素无法处理和重试,则重试的元素中较早的时间戳可能会提高数据新鲜度。常见 Dataflow 错误列表可帮助您进行问题排查。
对于最近更新的流式作业,有关作业状态和水印的信息可能不可用。更新操作会进行一些更改,这些更改需要几分钟才能传播到 Dataflow 监控界面。请试试在更新作业 5 分钟后刷新监控界面。
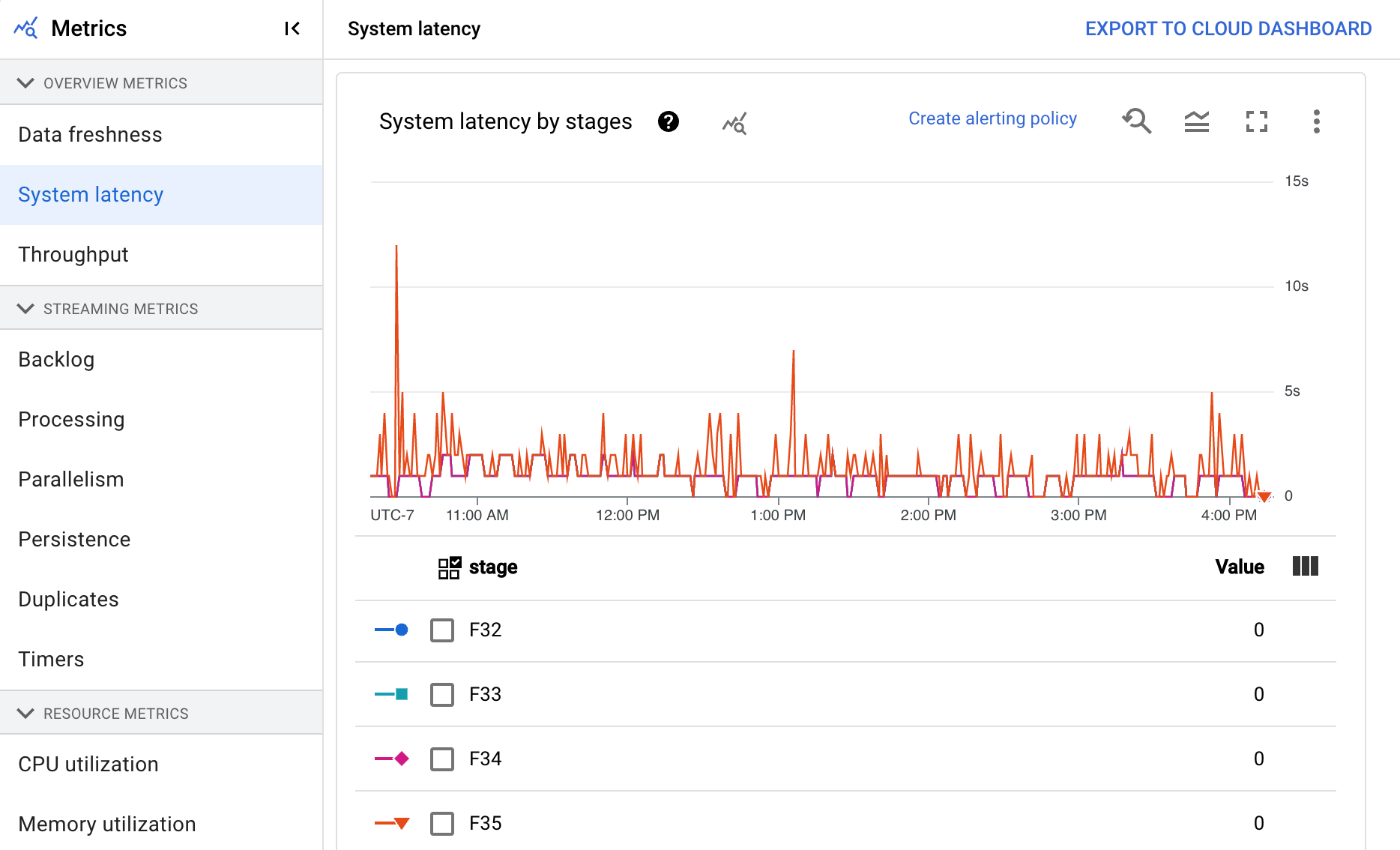
系统延迟时间
此指标仅适用于流式作业。
系统延迟时间是指某数据项已处理或等待处理的当前最长秒数。此指标包括元素在来源中等待的时间。例如,如果输出目标在一段时间内停止接受写入请求,数据可能会在来源处累积,导致系统延迟时间增加。如果写入操作继续,并且流水线能够跟上,系统延迟时间就会恢复到基准水平。
以下是其他注意事项:
- 对于多个来源和接收器,系统延迟时间是指元素在写入到所有接收器之前在来源内等待的最长时长。
- 有时,来源不会为元素在来源内等待的时间段提供值。此外,该元素可能没有用于定义其事件时间的元数据。 在这种情况下,系统延迟时间从流水线最初收到该元素的时间开始计算。
信息中心包括以下两个图表:
- 各阶段的系统延迟时间
- 系统延迟时间
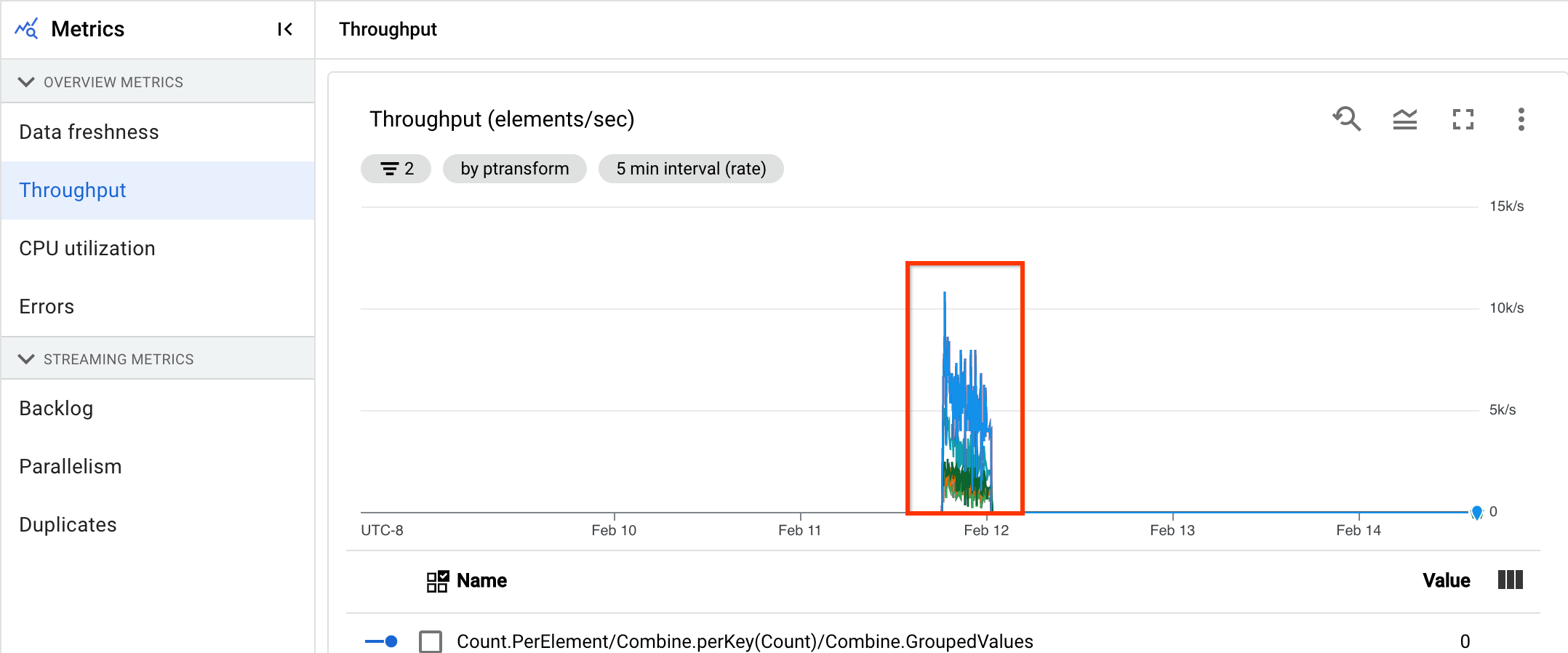
吞吐量
吞吐量是指在任何时间点处理的数据量。信息中心包含以下图表:
- 每步骤吞吐量(每秒处理的元素数)
- 每步骤吞吐量(每秒字节数)
工作器错误日志计数
工作器错误日志计数显示任何时间点在所有工作器中观察到的错误率。

流式指标
以下指标会显示在流式指标下。
积压
此指标仅适用于流式作业。
积压信息中心提供有关等待处理的元素的信息。信息中心包括以下两个图表:
- 积压消息秒数(仅限 Streaming Engine)
- 积压字节数(无论是否使用 Streaming Engine)
积压消息秒数图表显示了在没有新数据到达且吞吐量未变化的情况下处理当前积压消息需要的时间(以秒为单位)。预估的积压时间是根据吞吐量和来自输入源的待处理积压字节数计算的。流式自动扩缩功能使用此指标来确定何时扩容或缩容。
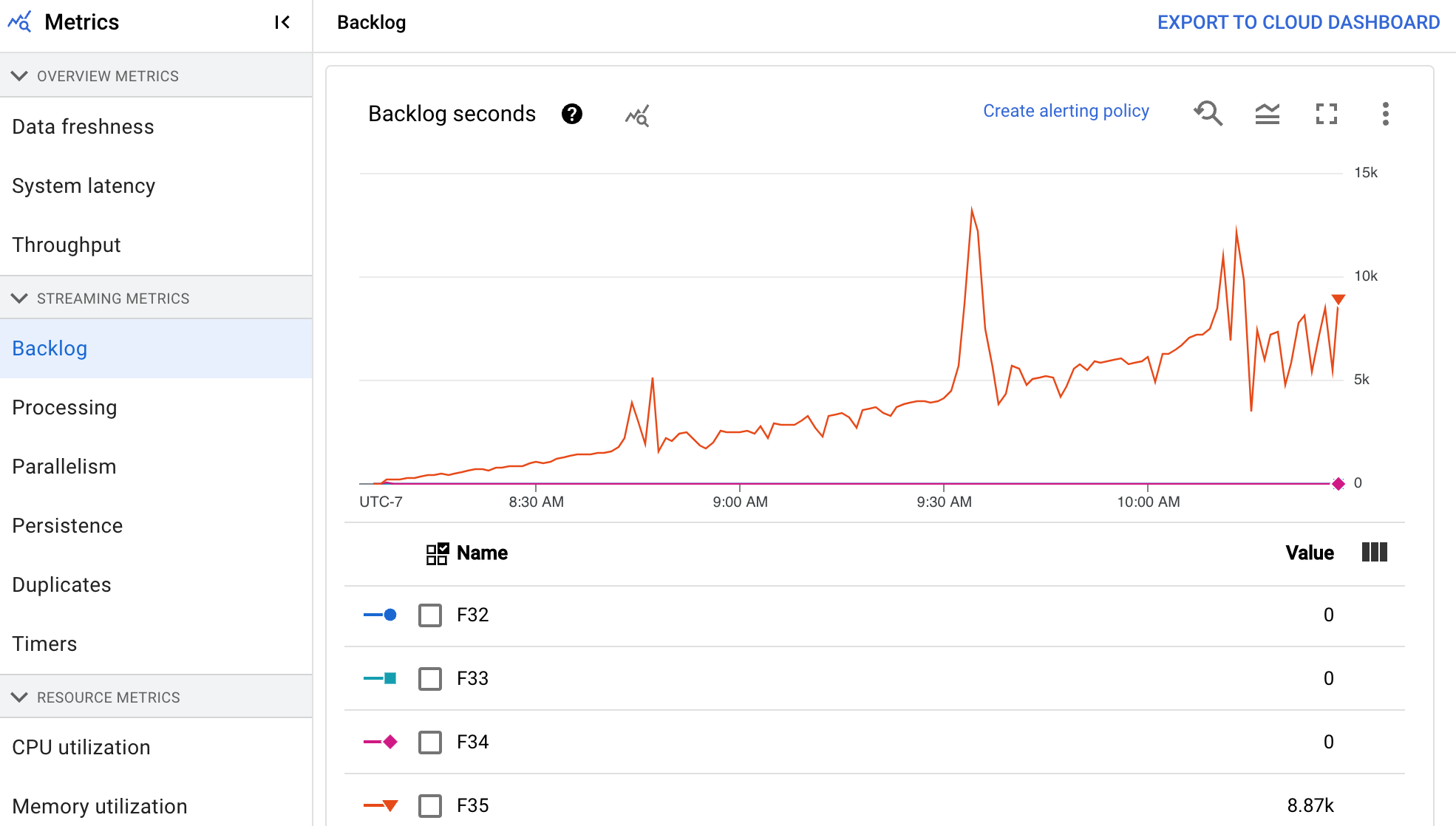
积压字节数图表显示了某个阶段的已知未处理输入的数量(以字节为单位)。此指标将可供每个阶段使用的剩余字节数与上游阶段进行比较。为准确报告此指标,必须正确配置流水线提取的每个来源。Pub/Sub 和 BigQuery 等内置来源已受到开箱支持,但自定义来源需要一些额外的实现。如需了解详情,请参阅自定义无界限来源的自动扩缩。

正在处理
此指标仅适用于流式作业。
在 Dataflow 服务上运行 Apache Beam 流水线时,流水线任务会在工作器虚拟机上运行。处理信息中心提供有关任务在工作器虚拟机上的已处理时间的信息。信息中心包括以下两个图表:
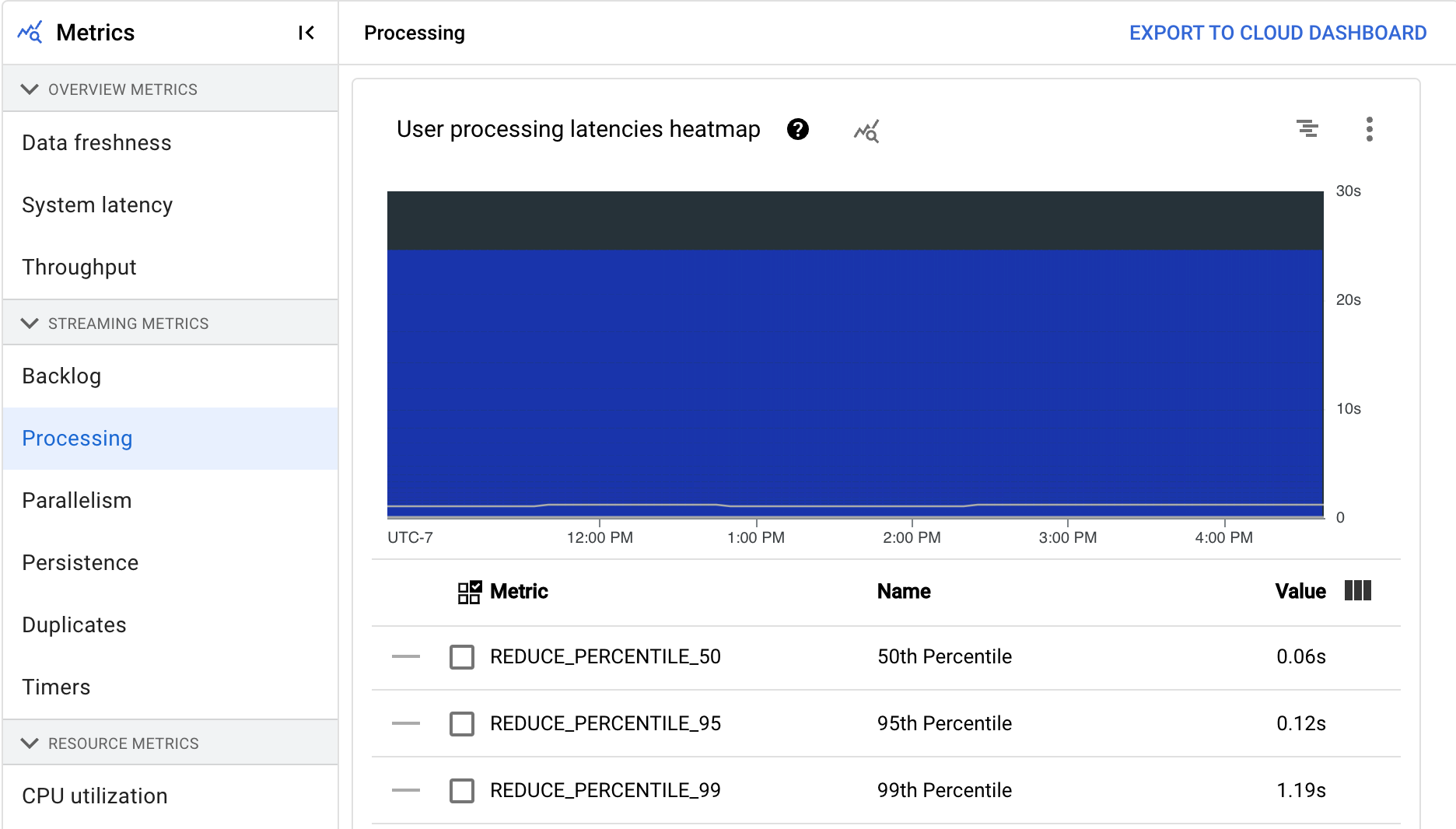
- 用户处理延迟时间热图
- 各阶段的用户处理延迟时间
用户处理延迟时间热图显示第 50、95 和 99 百分位分布的最大操作延迟时间。使用热图来查看是否有任何长尾操作导致了较高的整体系统延迟或对整体数据新鲜度产生了负面影响。
要在上游问题成为下游问题之前解决它,请设置第 50 百分位的高延迟提醒政策。
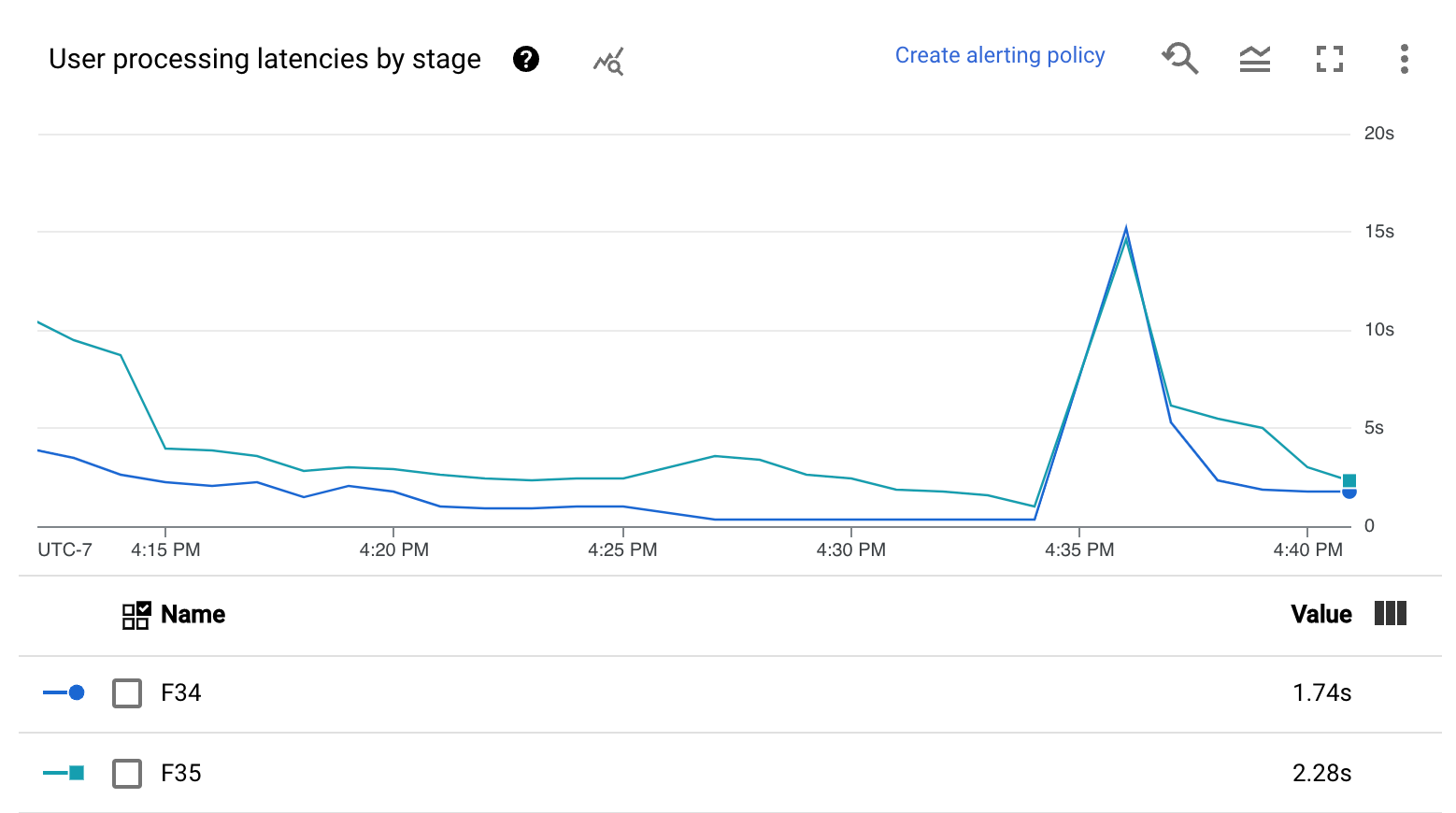
各阶段的用户处理延迟时间图表显示按阶段细分的工作器正在处理的所有任务的第 99 百分位。如果用户代码导致了瓶颈,此图表会显示哪个阶段包含瓶颈。您可以按照以下步骤调试流水线:
使用图表找到延迟异常高的阶段。
在作业详情页面的执行详情标签页中,对于图表视图,选择阶段工作流。在阶段工作流图表中,找到延迟异常高的阶段。
要查找关联的用户操作,请在图表中点击该阶段的节点。
如需查找更多详细信息,请打开 Cloud Profiler,并使用 Cloud Profiler 在正确的时间范围内调试堆栈轨迹。查找您在上一步中确定的用户操作。
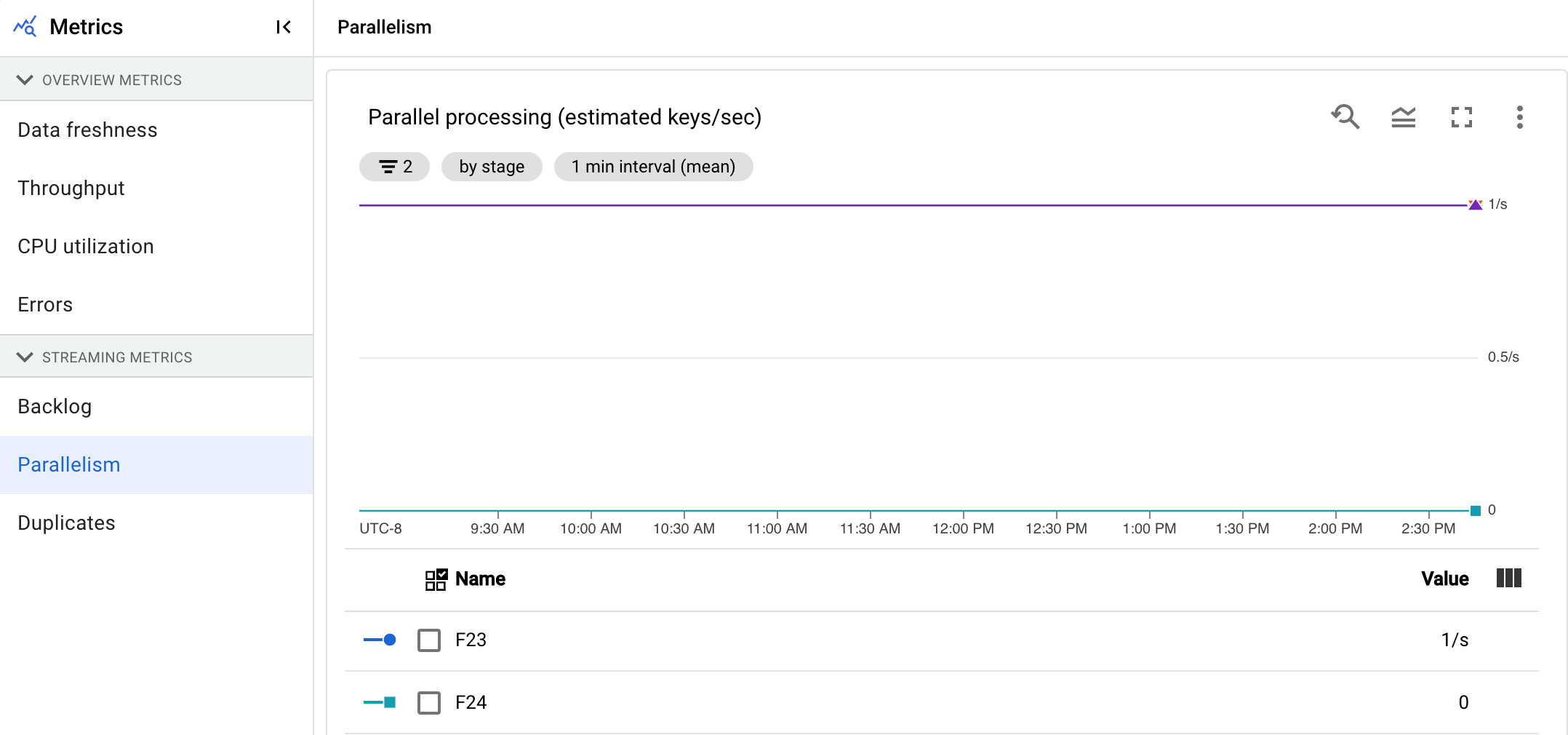
最大并行数量
此指标仅适用于 Streaming Engine 作业。
并行处理图表显示用于每个阶段的数据处理的大致键数。Dataflow 根据流水线的并行性进行扩缩。
当 Dataflow 运行流水线时,系统会在多个 Compute Engine 虚拟机 (VM) 之间进行分布式处理,也称为工作器。Dataflow 服务会自动对流水线中的处理逻辑进行并行化处理,并将其分布到各个工作器。任何给定键的处理都是序列化的,因此一个阶段的键总数表示该阶段的最大可用并行性。
在查找运行缓慢或卡住的流水线的热键或瓶颈时,并行性指标非常有用。
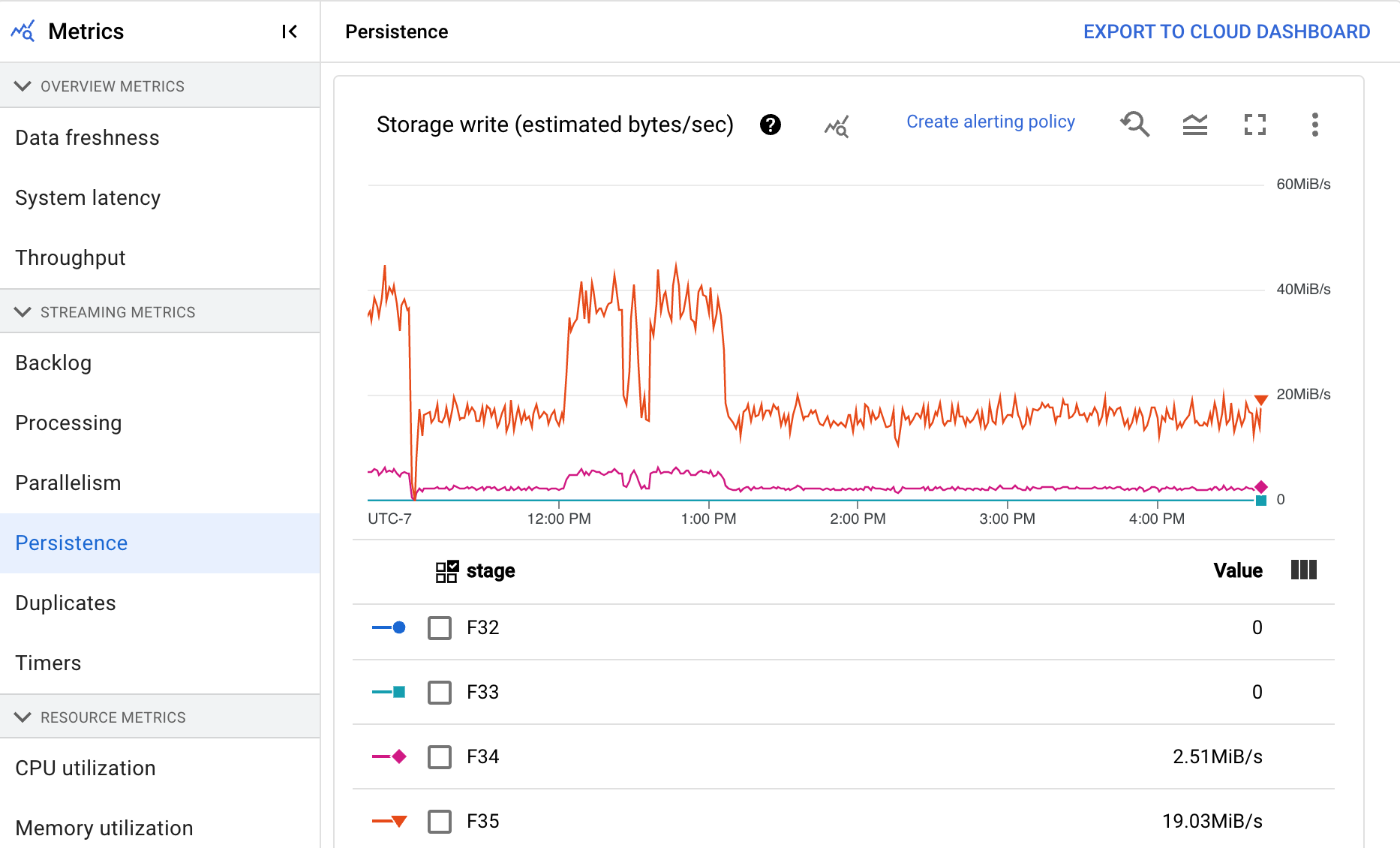
持久性
此指标仅适用于流式作业。
持久性信息中心显示特定流水线阶段写入和读取永久性存储的速率(以每秒字节数为单位)。读取和写入的字节数包括用户状态操作和持久性 shuffle、重复项移除、侧边输入和水印跟踪的状态。流水线编码器和缓存会影响读取和写入的字节数。由于内部存储空间用量和缓存,存储字节数可能与已处理的字节数不同。
信息中心包括以下两个图表:
- 存储写入
- 存储读取
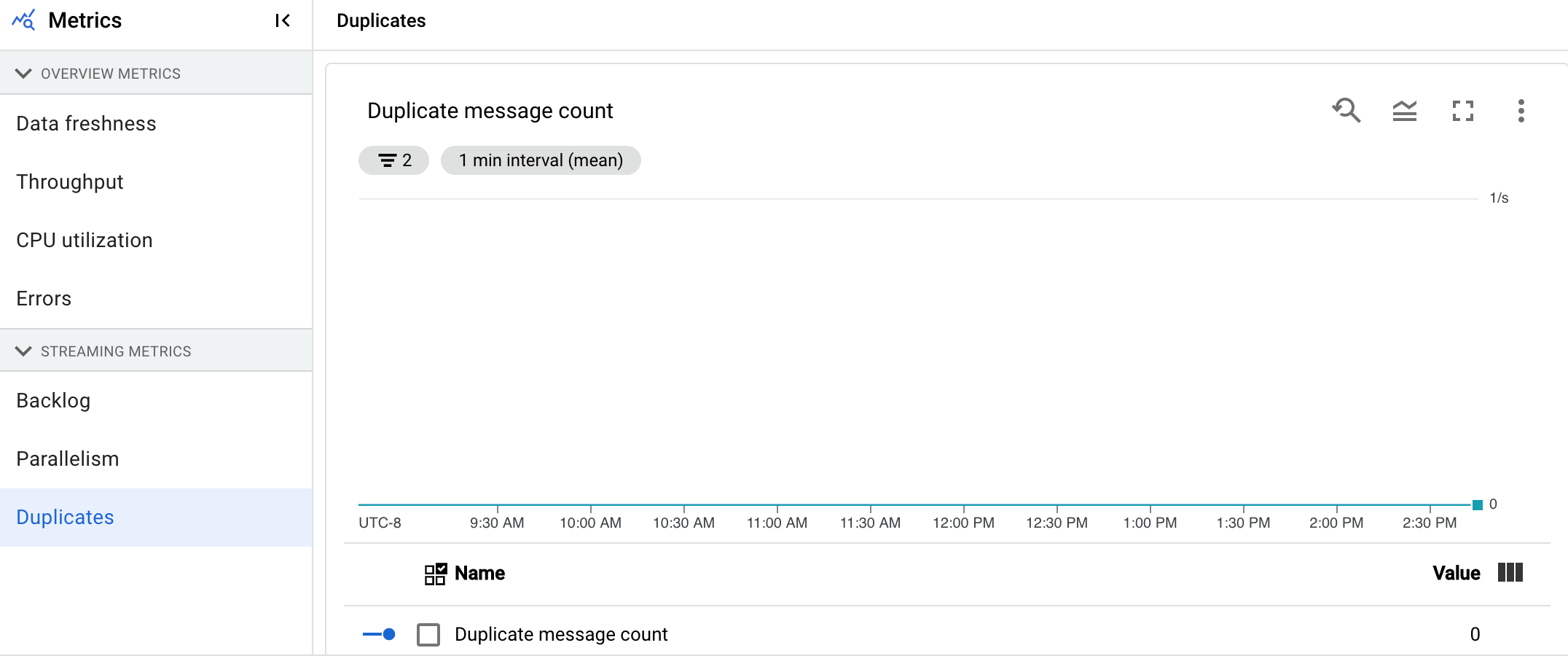
重复消息
此指标仅适用于流式作业。
重复项图表显示已作为重复项过滤掉的特定阶段所处理的消息数量。Dataflow 支持许多保证 at least once 传送的来源和接收器。at least once 传送的缺点是可能会产生重复项。Dataflow 可保证 exactly once 传送,这意味着系统会自动过滤掉重复项。通过重新处理相同的元素来保存下游阶段,从而确保状态和输出不受影响。通过减少每个阶段产生的重复项数量,可以优化流水线以减少占用的资源数量并提升性能。
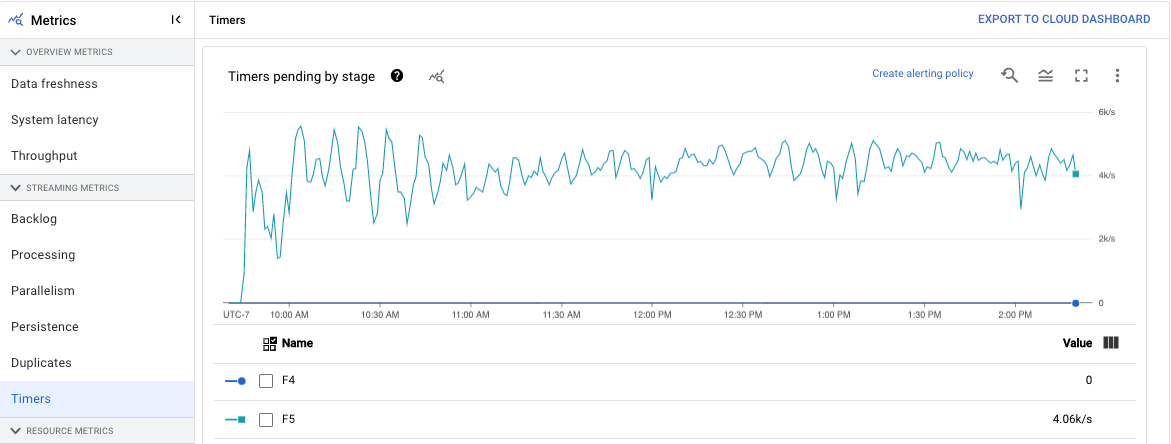
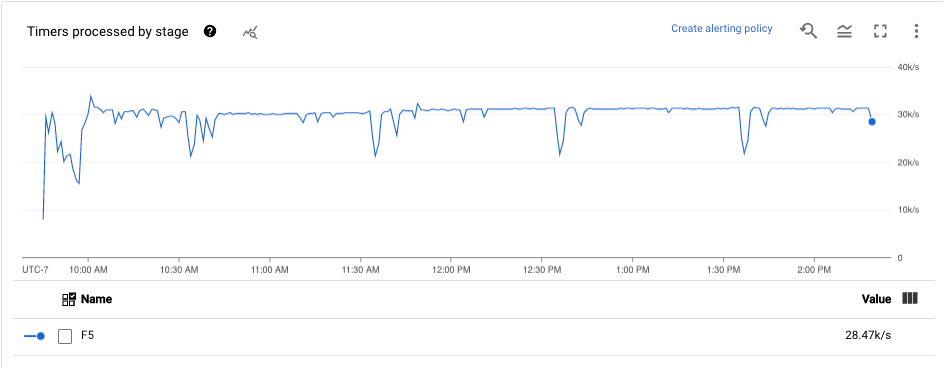
计时器
此指标仅适用于流式作业。
计时器信息中心显示特定流水线阶段中的待处理计时器数量以及已处理计时器数量。由于窗口依赖于计时器,因此这一指标可让您跟踪窗口的进度。
信息中心包括以下两个图表:
- 各阶段的待处理计时器
- 各阶段的处理中计时器
这些图表显示特定时间点的窗口待处理或处理速率。各阶段的待处理计时器图表显示由于瓶颈而延迟的窗口数量。各阶段的处理中计时器图表指示正在收集元素的窗口数量。
这些图表显示所有作业计时器,因此如果代码中的其他位置在使用计时器,这些计时器也会出现在这些图表中。
资源指标
以下指标会显示在资源指标下。
CPU 利用率
CPU 利用率是用 CPU 的使用量除以可用于处理的 CPU 数量得到的值。 该指标针对每个工作器计量,显示为百分比。 信息中心包括以下四个图表:
- CPU 利用率(所有工作器)
- CPU 利用率(统计数据)
- CPU 利用率(前 4 名)
- CPU 利用率(后 4 名)

内存利用率
内存利用率是工作器使用的内存估算量,以每秒字节数为单位。信息中心包括以下两个图表:
- 工作器内存利用率上限(估算的每秒字节数)
- 内存利用率(估算的每秒字节数)
工作器内存利用率上限图表提供有关每个时间点在 Dataflow 作业中使用最多内存的工作器的信息。 如果在作业执行期间的不同时间点,使用最多内存的工作器发生变化,则图表中的同一条线会显示多个工作器的数据。 线条中的每个数据点均显示在该时间点使用最大内存量的工作器的数据。该图表会将工作器使用的估算内存量与内存限制进行比较(以字节为单位)。
您可以使用此图表来排查内存不足 (OOM) 问题。此图表未显示工作器内存不足崩溃问题。
内存利用率图表显示 Dataflow 作业中所有工作器使用的内存用量与内存限制进行比较的估算量(以字节为单位)。
输入和输出指标
如果您的流式 Dataflow 作业使用 Pub/Sub 读取或写入记录,作业指标标签页会显示 Pub/Sub 读取或写入的指标。
同一类型的所有输入指标会组合在一起,所有输出指标也会组合在一起。 例如,所有 Pub/Sub 指标都将分组到一个部分中。 每个指标类型都将组织到单独的部分中。如需更改所显示的指标,请从左侧选择最能代表您要查找的指标的部分。 下图显示了所有可用的部分。
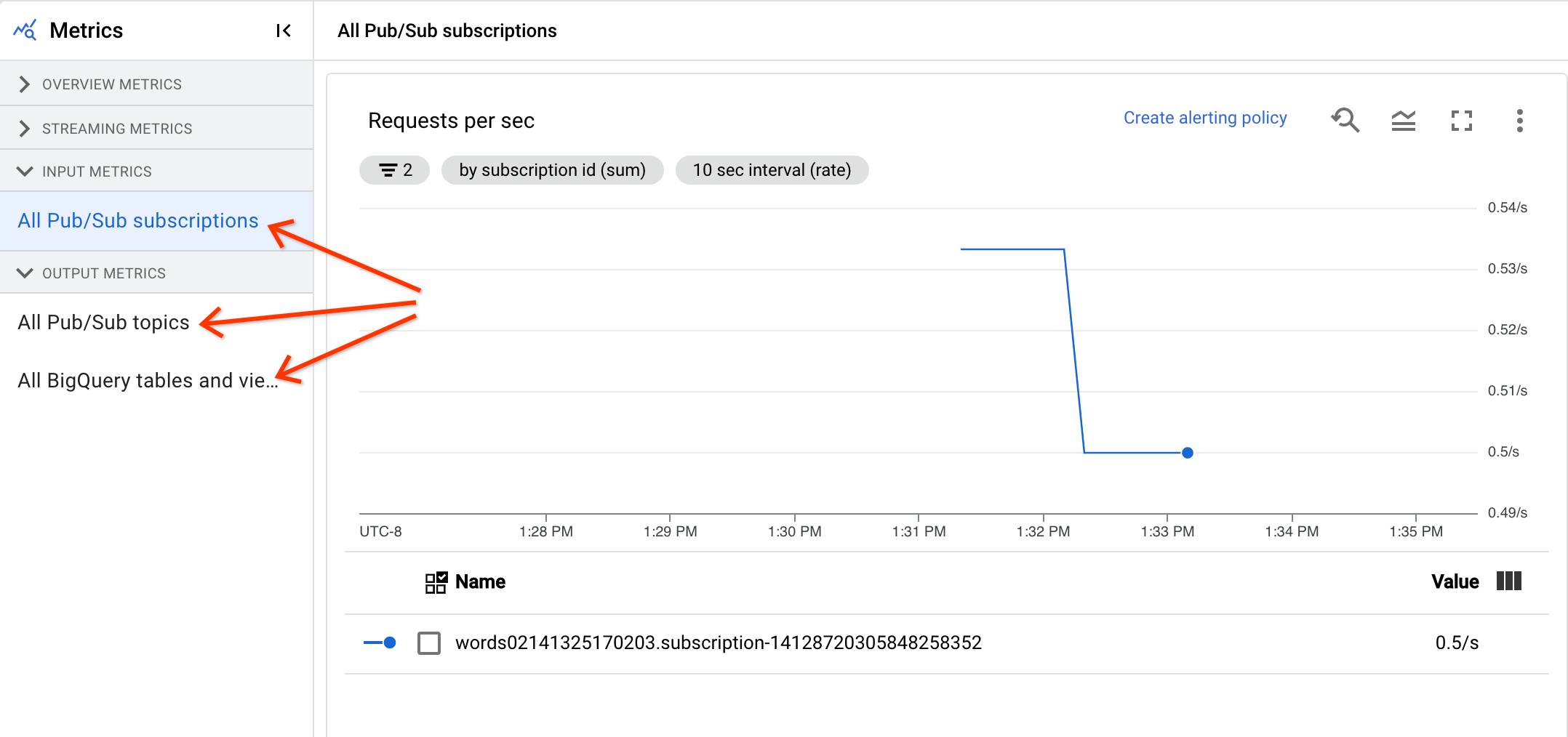
输入指标和输出指标部分都将显示以下两个图表。
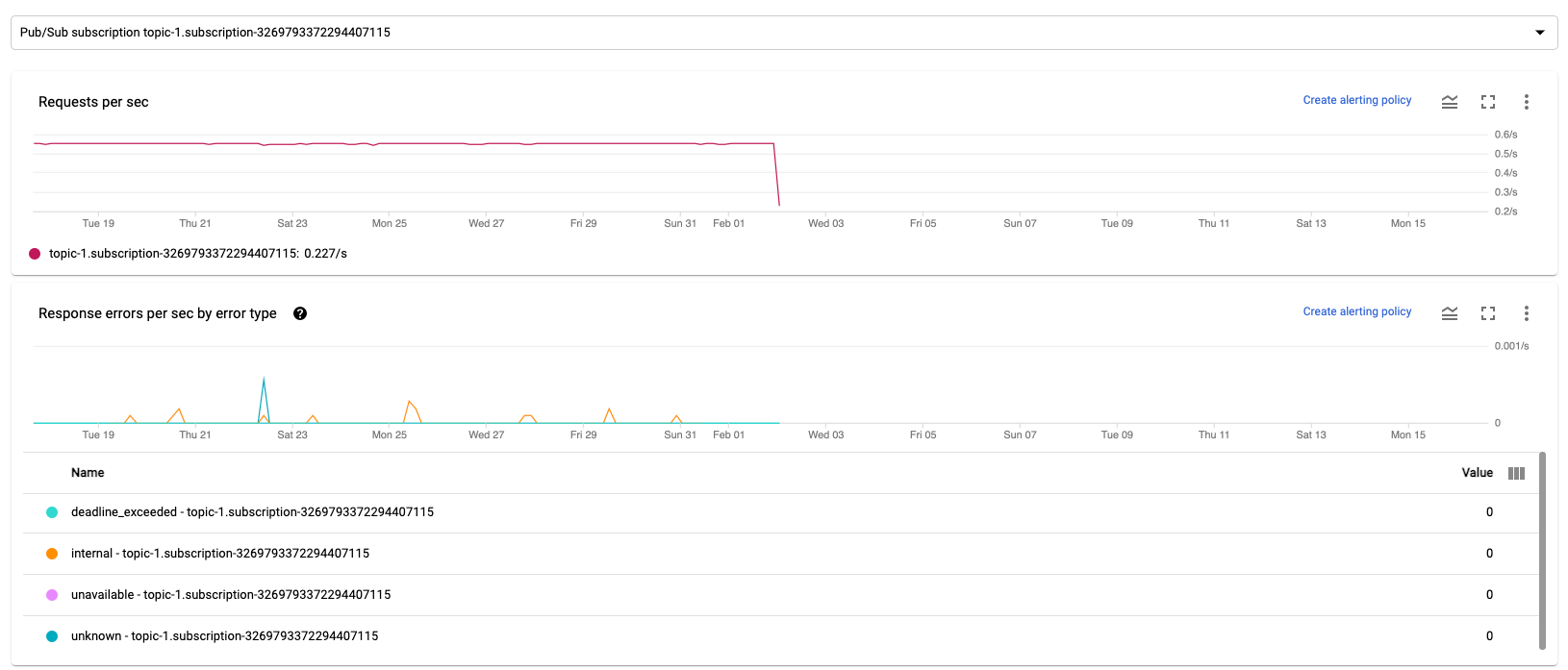
每秒请求数
每秒请求数是指来源或接收器在一段时间内读取或写入数据的 API 请求速率。 如果此速率下降到零,或者相对于预期行为而言,在很长一段时间内大幅降低,则流水线可能无法执行某些操作。此外,也可能没有任何可读取的数据。在这种情况下,请检查具有较大系统水印的作业步骤。此外,您还应该检查工作器日志,看看是否存在错误或表明处理速度缓慢的迹象。

每秒响应错误数(按错误类型划分)
每秒响应错误数(按错误类型划分)是指来源或接收器在一段时间内读取或写入数据失败的 API 请求速率。如果此类错误频繁出现,则这些 API 请求可能会拖慢处理速度。您必须调查此类失败的 API 请求。为帮助排查这些问题,请查看常规输入和输出错误代码。此外,请查看来源或接收器使用的任何具体错误代码文档,例如 Pub/Sub 错误代码。

如需详细了解可以使用这些指标进行调试的场景,请参阅“排查作业速度缓慢或卡住的问题”中的调试工具。
使用 Cloud Monitoring
Dataflow 与 Cloud Monitoring 完全集成。使用 Cloud Monitoring 执行以下任务:
- 当您的作业超过用户定义的阈值时,请创建提醒。
- 使用 Metrics Explorer 构建查询并调整指标的时间范围。
- 查看未显示在 Dataflow 监控界面中的指标。
如需了解如何创建提醒和使用 Metrics Explorer,请参阅使用 Cloud Monitoring for Dataflow 流水线。
如需查看 Dataflow 指标的完整列表,请参阅 Google Cloud Platform 指标文档。
创建 Cloud Monitoring 提醒
借助 Cloud Monitoring,您可以在 Dataflow 作业超出用户定义的阈值时创建提醒。如需从指标图表创建 Cloud Monitoring 提醒,请点击创建提醒政策。
如果您看不到监控图或无法创建提醒,则可能需要额外的 Monitoring 权限。
在 Metrics Explorer 中查看
您可以在 Metrics Explorer 中查看 Dataflow 指标图表,您可以在其中构建查询并调整指标的时间范围。
如需在 Metrics Explorer 中查看 Dataflow 图表,请在作业指标视图中打开更多图表选项,然后点击 在 Metrics Explorer 中查看。
调整指标的时间范围时,您可以选择预定义的持续时间或自定义时间间隔来分析作业。
默认情况下,对于流处理作业和运行中的批处理作业,将显示该作业的前六个小时的指标。对于已停止或已完成的流处理作业,默认显示作业持续时间的整个运行时间。
Dataflow I/O 指标
您可以在 Metrics Explorer 中查看以下 Dataflow I/O 指标:
job/pubsub/write_count:来自 Dataflow 作业中 PubsubIO.Write 的 Pub/Sub 发布请求。job/pubsub/read_count:来自 Dataflow 作业中 PubsubIO.Read 的 Pub/Sub 拉取请求。job/bigquery/write_count:来自 Dataflow 作业中 BigQueryIO.Write 的 BigQuery 发布请求。job/bigquery/write_count指标在使用 WriteToBigQuery 转换 并在 Apache Beam 2.28.0 版或更高版本上启用了method='STREAMING_INSERTS'的 Python 流水线中提供。 此指标适用于批处理流水线和流式处理流水线。- 如果您的流水线使用 BigQuery 来源或接收器,如需排查配额问题,请使用 BigQuery Storage API 指标。
DoFn 指标
对于使用 Streaming Engine 但不使用 Runner v2 的流式作业,您可以查看个别用户定义的 DoFns 的以下指标:
job/dofn_latency_average:过去 3 分钟内单个DoFn的平均消息处理时间(以毫秒为单位)。job/dofn_latency_max:过去 3 分钟内单个DoFn的最长消息处理时间(以毫秒为单位)。job/dofn_latency_min:过去 3 分钟内单个DoFn的最短消息处理时间(以毫秒为单位)。job/dofn_latency_num_messages:过去 3 分钟内单个DoFn处理的消息数量。job/dofn_latency_total:过去 3 分钟内单个DoFn中所有消息的总消息处理时间(以毫秒为单位)。job/oldest_active_message_age:最早的活跃消息在DoFn中已处理的时间(以毫秒为单位)。
这些指标需要 Apache Beam SDK 2.53.0 版或更高版本。如需查看这些指标,请使用 Metrics Explorer。
您可以使用这些指标来查找哪些 DoFns 对作业处理延迟时间的贡献最大。例如,如果某个作业卡住,请使用 job/oldest_active_message_age 指标查找具有最早活跃消息的 DoFn。下图显示了此指标中出现较大峰值的 DoFn:
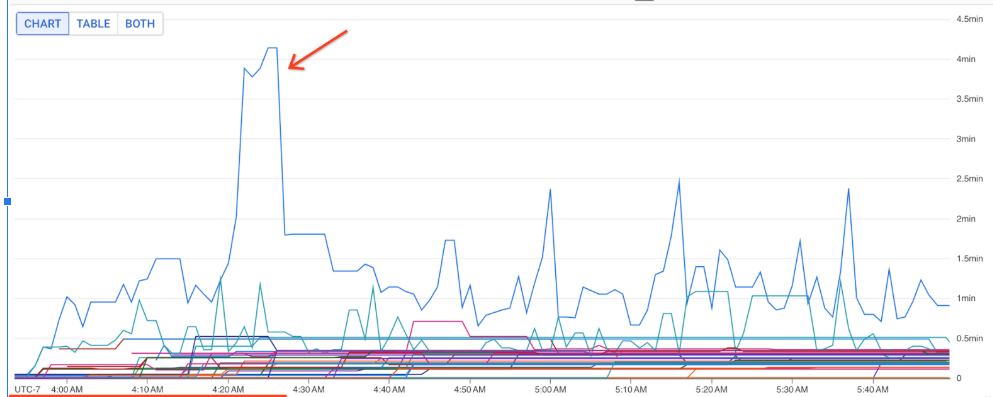
如需查看 DoFn 的名称,请将指针悬停在图表线上。