Après avoir créé et appliqué votre modèle Dataflow, exécutez le modèle à l'aide de la console Google Cloud , de l'API REST ou de Google Cloud CLI. Vous pouvez déployer les jobs du modèle Dataflow à partir de nombreux environnements, y compris l'environnement App Engine standard, les fonctions Cloud Run et d'autres environnements restreints.
Utiliser la console Google Cloud
Vous pouvez utiliser la console Google Cloud pour exécuter des modèles Dataflow personnalisés et fournis par Google.
Modèles fournis par Google
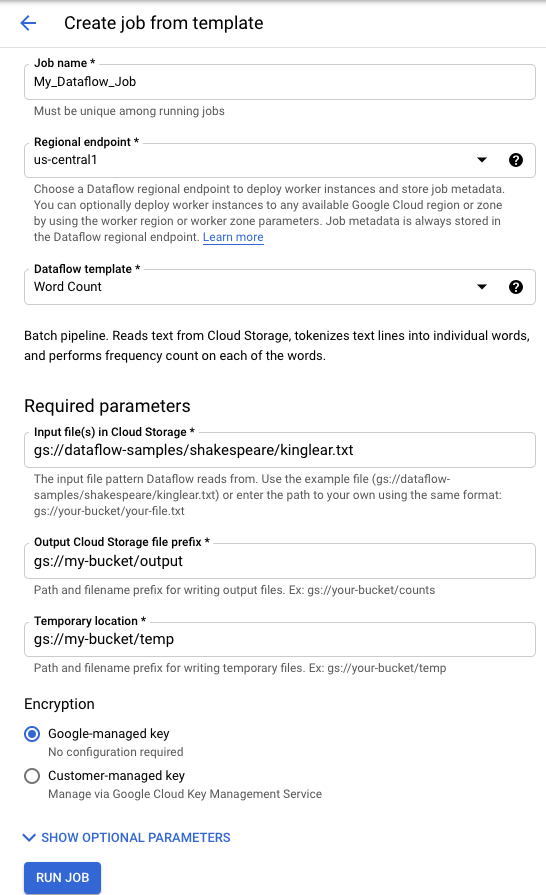
Pour exécuter un modèle fourni par Google, procédez comme suit :
- Accédez à la page Dataflow dans la console Google Cloud . Accéder à la page Dataflow
- Cliquez sur add_boxCreate job from template (Créer une tâche à partir d'un modèle).
- Sélectionnez le modèle fourni par Google que vous souhaitez exécuter dans le menu déroulant Dataflow template (Modèle Dataflow).
- Saisissez un nom de tâche dans le champ Job Name (Nom de la tâche).
- Saisissez vos valeurs de paramètres dans les champs fournis. La section Additional Parameters (Paramètres supplémentaires) peut être ignorée lorsque vous utilisez un modèle fourni par Google.
- Cliquez sur Exécuter le job.

Modèles personnalisés
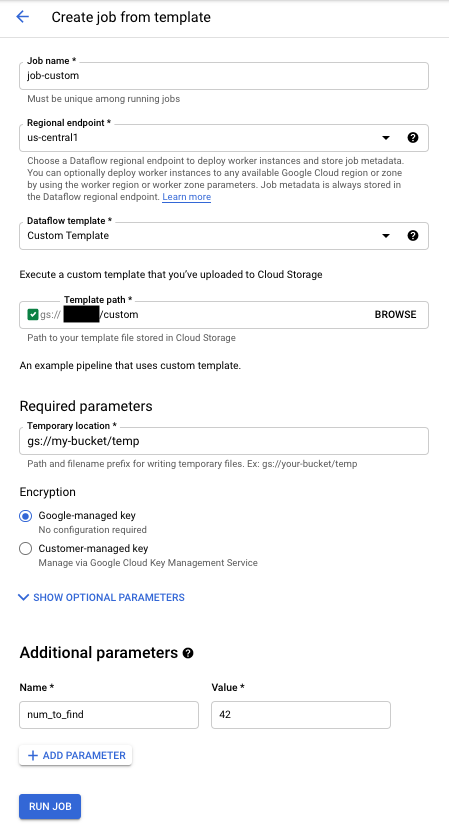
Pour exécuter un modèle personnalisé, procédez comme suit :
- Accédez à la page Dataflow dans la console Google Cloud . Accéder à la page Dataflow
- Cliquez sur CREATE JOB FROM TEMPLATE (Créer une tâche à partir d'un modèle).
- Sélectionnez Custom Template (Modèle personnalisé) dans le menu déroulant Dataflow template (Modèle Dataflow).
- Saisissez un nom de tâche dans le champ Job Name (Nom de la tâche).
- Saisissez le chemin d'accès Cloud Storage vers votre fichier de modèle dans le champ "Template GCS Path" (Chemin d'accès GCS du modèle).
- Si votre modèle a besoin d'autres paramètres, cliquez sur addAdd parameter (Ajouter un paramètre) dans la section Additional Parameters (Paramètres supplémentaires). Saisissez le nom (Name) et la valeur (Value) du paramètre. Répétez cette opération pour chaque paramètre requis.
- Cliquez sur Exécuter le job.
Utiliser l'API REST
Pour exécuter un modèle avec une requête API REST, envoyez une requête HTTP POST avec votre ID de projet. Cette requête nécessite une autorisation.
Consultez la documentation de référence de l'API REST concernant la requête projects.locations.templates.launch pour en savoir plus sur les paramètres disponibles.
Créer un job par lot à partir d'un modèle personnalisé
Cet exemple de requête projects.locations.templates.launch crée une tâche par lot à partir d'un modèle qui lit un fichier texte et génère un fichier texte de sortie. Si la requête aboutit, le corps de la réponse contient une instance de LaunchTemplateResponse.
Modifiez les valeurs suivantes :
- Remplacez
YOUR_PROJECT_IDpar l'ID du projet. - Remplacez
LOCATIONpar la région Dataflow de votre choix. - Remplacez
JOB_NAMEpar le nom de tâche de votre choix. - Remplacez
YOUR_BUCKET_NAMEpar le nom de votre bucket Cloud Storage. - Définissez
gcsPathsur l'emplacement Cloud Storage du fichier de modèle. - Définissez
parameterssur votre liste de paires clé/valeur. - Définissez
tempLocationsur un emplacement pour lequel vous disposez d'une autorisation en écriture. Cette valeur est nécessaire pour exécuter les modèles fournis par Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=gs://YOUR_BUCKET_NAME/templates/TemplateName
{
"jobName": "JOB_NAME",
"parameters": {
"inputFile" : "gs://YOUR_BUCKET_NAME/input/my_input.txt",
"output": "gs://YOUR_BUCKET_NAME/output/my_output"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Créer un job par flux à partir d'un modèle personnalisé
Cet exemple de requête projects.locations.templates.launch crée un job de traitement en flux continu à partir d'un modèle classique qui lit un abonnement Pub/Sub et écrit dans une table BigQuery. Si vous souhaitez lancer un modèle Flex, utilisez plutôt projects.locations.flexTemplates.launch. Le modèle d'exemple est un modèle fourni par Google. Vous pouvez modifier le chemin d'accès du modèle pour qu'il pointe vers un modèle personnalisé. La même logique s'applique pour lancer des modèles fournis par Google et des modèles personnalisés. Dans cet exemple, la table BigQuery doit déjà exister avec le schéma approprié. Si la requête aboutit, le corps de la réponse contient une instance de LaunchTemplateResponse.
Modifiez les valeurs suivantes :
- Remplacez
YOUR_PROJECT_IDpar l'ID du projet. - Remplacez
LOCATIONpar la région Dataflow de votre choix. - Remplacez
JOB_NAMEpar le nom de tâche de votre choix. - Remplacez
YOUR_BUCKET_NAMEpar le nom de votre bucket Cloud Storage. - Remplacez
GCS_PATHpar l'emplacement Cloud Storage du fichier de modèle. L'emplacement doit commencer par gs:// - Définissez
parameterssur votre liste de paires clé/valeur. Les paramètres répertoriés sont spécifiques à cet exemple de modèle. Si vous utilisez un modèle personnalisé, modifiez les paramètres selon vos besoins. Si vous utilisez le modèle d'exemple, remplacez les variables suivantes.- Remplacez
YOUR_SUBSCRIPTION_NAMEpar le nom de votre abonnement Pub/Sub. - Remplacez
YOUR_DATASETpar le nom de votre ensemble de données BigQuery etYOUR_TABLE_NAMEpar le nom de votre table BigQuery.
- Remplacez
- Définissez
tempLocationsur un emplacement pour lequel vous disposez d'une autorisation en écriture. Cette valeur est nécessaire pour exécuter les modèles fournis par Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH
{
"jobName": "JOB_NAME",
"parameters": {
"inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_SUBSCRIPTION_NAME",
"outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Mettre à jour un job par flux à partir d'un modèle personnalisé
Cet exemple de requête projects.locations.templates.launch montre comment mettre à jour une tâche par flux à partir d'un modèle. Si vous souhaitez mettre à jour un modèle Flex, utilisez plutôt projects.locations.flexTemplates.launch.
- Exécutez Exemple 2 : Création d'une tâche par flux à partir d'un modèle personnalisé pour démarrer une tâche par flux à partir d'un modèle.
- Envoyez la requête HTTP POST ci-dessous, avec les valeurs modifiées suivantes :
- Remplacez
YOUR_PROJECT_IDpar l'ID du projet. - Remplacez
LOCATIONpar la région Dataflow du job que vous mettez à jour. - Remplacez
JOB_NAMEpar le nom exact du job que vous souhaitez mettre à jour. - Remplacez
GCS_PATHpar l'emplacement Cloud Storage du fichier de modèle. L'emplacement doit commencer par gs:// - Définissez
parameterssur votre liste de paires clé/valeur. Les paramètres répertoriés sont spécifiques à cet exemple de modèle. Si vous utilisez un modèle personnalisé, modifiez les paramètres selon vos besoins. Si vous utilisez le modèle d'exemple, remplacez les variables suivantes.- Remplacez
YOUR_SUBSCRIPTION_NAMEpar le nom de votre abonnement Pub/Sub. - Remplacez
YOUR_DATASETpar le nom de votre ensemble de données BigQuery etYOUR_TABLE_NAMEpar le nom de votre table BigQuery.
- Remplacez
- Utilisez le paramètre
environmentpour modifier les paramètres de l'environnement, tels que le type de machine. Cet exemple utilise le type de machine n2-highmem-2, qui dispose de plus de mémoire et de processeurs par nœud de calcul que le type de machine par défaut.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH { "jobName": "JOB_NAME", "parameters": { "inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_TOPIC_NAME", "outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME" }, "environment": { "machineType": "n2-highmem-2" }, "update": true } - Remplacez
- Accédez à l'interface de surveillance de Dataflow et vérifiez qu'une nouvelle tâche portant le même nom a été créée. Cette tâche est associée à l'état Updated (Mis à jour).
Utiliser les bibliothèques clientes des API Google
Pensez à utiliser les bibliothèques clientes des API Google pour effectuer facilement des appels aux API REST de Dataflow. Cet exemple de script utilise la bibliothèque cliente des API Google pour Python.
Dans cet exemple, vous devez définir les variables suivantes :
project: définie sur l'ID de votre projet.job: définie sur le nom de tâche unique de votre choix.template: définie sur l'emplacement Cloud Storage du fichier de modèle.parameters: définie sur un dictionnaire contenant les paramètres du modèle.
Pour définir la région, incluez le paramètre location.
Pour en savoir plus sur les options disponibles, reportez-vous à la section traitant de la méthode projects.locations.templates.launch dans la documentation de référence de l'API REST de Dataflow.
Utiliser gcloud CLI
gcloud CLI permet d'exécuter un modèle personnalisé ou fourni par Google à l'aide de la commande gcloud dataflow jobs run. Des exemples d'exécution de modèles fournis par Google sont présentés sur la page de modèles fournis par Google.
Pour les exemples de modèles personnalisés ci-après, définissez les valeurs suivantes :
- Remplacez
JOB_NAMEpar le nom de tâche de votre choix. - Remplacez
YOUR_BUCKET_NAMEpar le nom de votre bucket Cloud Storage. - Définissez
--gcs-locationsur l'emplacement Cloud Storage du fichier de modèle. - Définissez
--parameterssur la liste de paramètres séparés par des virgules à appliquer à la tâche. Les espaces entre virgules et valeurs ne sont pas autorisés. - Pour empêcher les VM d'accepter les clés SSH stockées dans les métadonnées du projet, utilisez l'option
additional-experimentsavec l'option de serviceblock_project_ssh_keys:--additional-experiments=block_project_ssh_keys.
Créer un job par lot à partir d'un modèle personnalisé
Cet exemple crée une tâche par lot à partir d'un modèle qui lit un fichier texte et génère un fichier texte de sortie.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters inputFile=gs://YOUR_BUCKET_NAME/input/my_input.txt,output=gs://YOUR_BUCKET_NAME/output/my_output
La requête renvoie une réponse au format suivant :
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_BATCH
Créer un job par flux à partir d'un modèle personnalisé
Cet exemple crée une tâche par flux à partir d'un modèle qui lit un sujet Pub/Sub et écrit dans une table BigQuery. Cette dernière doit déjà exister avec le schéma approprié.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters topic=projects/project-identifier/topics/resource-name,table=my_project:my_dataset.my_table_name
La requête renvoie une réponse au format suivant :
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_STREAMING
Pour obtenir la liste complète des options disponibles pour la commande gcloud dataflow jobs run, consultez la documentation de référence de gcloud CLI.
Surveillance et dépannage
L'interface de surveillance de Dataflow vous permet de surveiller vos tâches Dataflow. En cas d'échec, des conseils de dépannage, des stratégies de débogage et un catalogue des erreurs courantes sont disponibles dans le guide Résoudre les problèmes liés à votre pipeline.