制限なし PCollection、または制限なしコレクションにより、ストリーミング パイプラインにおけるデータが表現されます。制限なしコレクションには、Pub/Sub など、継続的に更新されるデータソースのデータが含まれます。
鍵のみを使用して、制限なしコレクション内の要素をグループ化することはできません。データソースには常に新しい要素が追加されるため、ストリーミング データのキーは無限に多くなる可能性があります。ウィンドウ、ウォーターマーク、トリガーを使用して制限なしコレクションの要素を集約できます。
ウィンドウの概念は、バッチ パイプライン内のデータを表す制限付き PCollection にも適用されます。バッチ パイプラインでのウィンドウ処理について詳しくは、Apache Beam のドキュメントの Windowing with bounded PCollections をご覧ください。
Dataflow パイプラインに制限付きデータソース(つまり、継続的に更新されるデータを含まないソース)があり、パイプラインが --streaming フラグを使用してストリーミング モードに切り替えられている場合、制限付きソースがすべて消費された時点でパイプラインの動作が停止します。
ストリーミング モードを使用する
ストリーミング モードでパイプラインを実行するには、パイプラインの実行時にコマンドラインで --streaming フラグを設定します。また、パイプラインを作成する際に、プログラムによってストリーミング モードを設定することもできます。
バッチソースは、ストリーミング モードではサポートされません。
より大きなワーカープールでパイプラインを更新すると、ストリーミング ジョブが想定どおりにアップスケールされないことがあります。ストリーミング エンジンを使用しないストリーミング ジョブでは、元のジョブの開始時に割り当てられたワーカーと Persistent Disk リソースの数を超えてスケーリングすることはできません。Dataflow ジョブを更新するときに、新しいジョブの指定でワーカー数を増やす場合は、元のジョブに指定したワーカーの最大数と等しいワーカー数だけを指定できます。
次のフラグを使用して、ワーカーの最大数を指定します。
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
ウィンドウとウィンドウ処理関数
ウィンドウ関数は、制限なしコレクションを論理的な要素、つまりウィンドウに分割します。ウィンドウ関数は、個々の要素のタイムスタンプで制限なしコレクションをグループ化します。各ウィンドウには一定数の要素が入ります。
Apache Beam SDK で次のウィンドウを設定します。
- タンブリング ウィンドウ(Apache Beam では固定ウィンドウ)
- ホッピング ウィンドウ(Apache Beam ではスライディング ウィンドウ)
- セッション ウィンドウ
タンブリング ウィンドウ
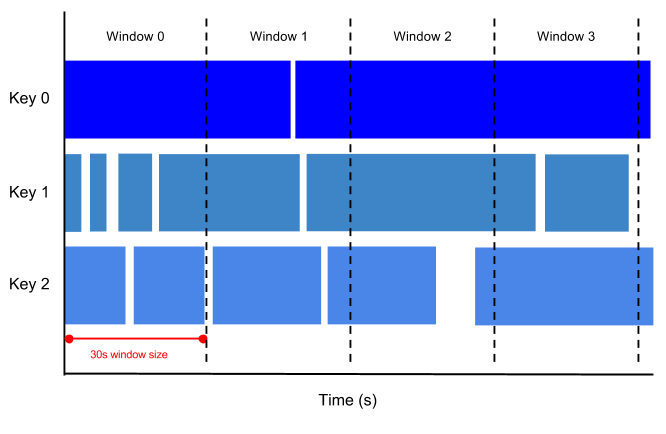
タンブリング ウィンドウとは、データ ストリームを重なりなく分ける一定の時間間隔を表します。
たとえば、30 秒のタンブリング ウィンドウに設定すると、タイムスタンプ値が [0:00:00-0:00:30] の要素が最初のウィンドウに表示されます。2 番目のウィンドウには、[0:00:30-0:01:00] のタイムスタンプ値を持つ要素が表示されます。
次の図は、30 秒のタンブリング ウィンドウに分割された要素を表しています。
ホッピング ウィンドウ
ホッピング ウィンドウとは、データ ストリーム内の一定の時間間隔を表します。タンブリング ウィンドウは重なりませんが、ホッピング ウィンドウは重なることがあります。
たとえば、ホッピング ウィンドウが 30 秒ごとに開始し、1 分間のデータを持つ場合があります。ホッピング ウィンドウの開始間隔はピリオドといいます。この例では、1 分間のウィンドウと 30 秒のピリオドが設定されています。
次の図は、30 秒のピリオドを持つ 1 分間のホッピング ウィンドウに分割された要素を表しています。
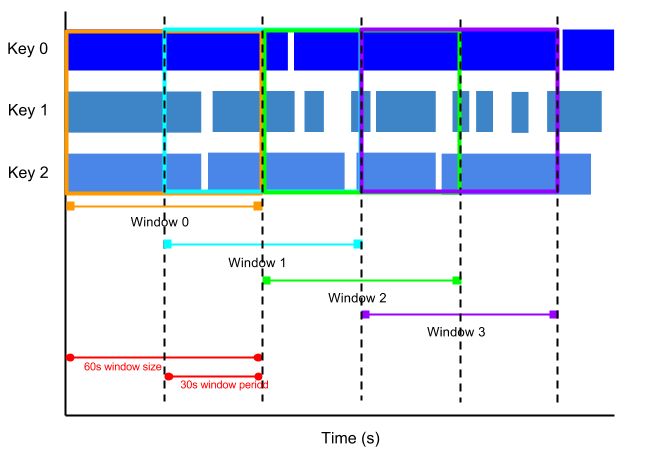
平均データを取得するには、ホッピング ウィンドウを使用します。30 秒の期間と 1 分のホッピング ウィンドウを使用して、30 秒ごとに平均 1 分間の実行を計算できます。
セッション ウィンドウ
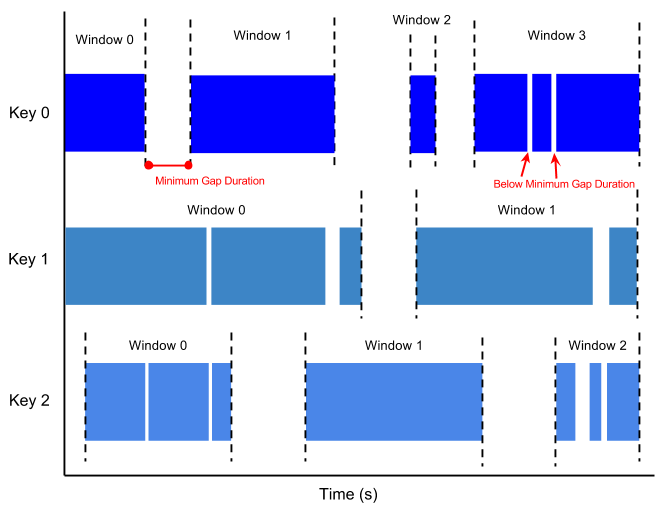
セッション ウィンドウには、別の要素とのギャップ期間に存在する複数の要素が含まれます。ギャップ期間とは、データ ストリームの新しいデータの間隔を表します。ギャップ期間の後にデータを取得すると、そのデータには新しいウィンドウが割り当てられます。
たとえば、セッション ウィンドウでは、ユーザーのマウスの操作を表すデータ ストリームを分割できます。このデータ ストリームでは、長時間アイドル状態が続き、クリックが多い期間が点在します。セッション ウィンドウには、クリックで生成されたデータを含めることができます。
セッション ウィンドウは、各データキーに異なるウィンドウを割り当てます。タンブル ウィンドウとホッピング ウィンドウには、データキーに関係なく、指定された期間内のすべての要素が含まれます。
次の図は、セッション ウィンドウに分割された要素を表しています。
ウォーターマーク
ウォーターマークとは、Dataflow でウィンドウのすべてのデータが必要になるしきい値を表します。ウォーターマークがウィンドウの終わりを超えて進み、ウィンドウ内にタイムスタンプ付きの新しいデータが到着した場合、そのデータは遅延データとみなされます。詳細については、Apache Beam ドキュメントのウォーターマークと遅延データをご覧ください。
Dataflow では、次の理由からウォーターマークを追跡します。
- データを時間順や予測可能な間隔で受信できるとは限りません。
- データイベントは、生成時と同じ順序でパイプラインに提供されるとは限りません。
データソースによってウォーターマークが決まります。Apache Beam SDK では遅延データを許可できます。
トリガー
トリガーは、データが到着したときに集計結果をいつ出力するかを決定します。デフォルトでは、ウォーターマークがウィンドウ末尾を過ぎると結果が出力されます。
Apache Beam SDK を使用すると、ストリーミング パイプラインの各コレクションのトリガーを作成または変更できます。
Apache Beam SDK では、次の条件を組み合わせて動作するトリガーを設定できます。
- 各データ要素のタイムスタンプで表されるイベントの時刻。
- パイプラインの任意のステージでデータ要素が処理される時間。
- コレクション内のデータ要素の数。