Les PCollections illimitées, ou collections illimitées, représentent des données dans des pipelines de traitement par flux. Une collection illimitée contient des données issues d'une source de données actualisée en continu, telle que Pub/Sub.
Vous ne pouvez pas utiliser qu'une clé pour regrouper des éléments dans une collection illimitée. Il peut y avoir une infinité d'éléments pour une clé donnée dans les flux de données, car la source de données ajoute constamment de nouveaux éléments. Vous pouvez exploiter des fenêtres, des filigranes et des déclencheurs pour regrouper des éléments dans des collections illimitées.
Le concept de fenêtres s'applique également aux PCollections limitées qui représentent des données dans des pipelines de traitement par lot. Pour en savoir plus sur le fenêtrage dans les pipelines par lot, consultez la documentation Apache Beam pour le fenêtrage avec des PCollections limitées.
Si un pipeline Dataflow possède une source de données limitée, c'est-à-dire une source qui ne contient pas de données continuellement mises à jour, et que le pipeline passe en mode de traitement par flux à l'aide de l'option --streaming, il s'arrête lorsque la source limitée est entièrement consommée.
Utiliser le mode de traitement par flux
Pour exécuter un pipeline en mode de traitement par flux, définissez l'indicateur --streaming dans la ligne de commande lorsque vous exécutez votre pipeline. Vous avez également la possibilité de définir le mode de traitement par flux de façon automatisée lorsque vous construisez votre pipeline.
Les sources de traitement par lots ne sont pas compatibles avec le mode de traitement par flux.
Lorsque vous mettez à jour votre pipeline avec un pool de nœuds de calcul plus important, votre job de traitement par flux risque de ne pas s'adapter comme prévu. Pour les jobs de traitement par flux qui n'utilisent pas Streaming Engine, le nombre de nœuds de calcul et de ressources de disques persistants ne peut pas dépasser la quantité allouée au début de la tâche d'origine. Lorsque vous mettez à jour une tâche Dataflow et augmentez le nombre de nœuds de calcul de la nouvelle tâche, vous ne pouvez spécifier qu'un nombre de nœuds de calcul égal au nombre maximal de nœuds de calcul que vous avez spécifié pour votre tâche d'origine.
Spécifiez le nombre maximal de nœuds de calcul à l'aide des options suivantes :
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
Fonctions des fenêtres et du fenêtrage
Les fonctions de fenêtrage permettent de diviser les collections illimitées en composants logiques ou fenêtres. Elles regroupent les collections illimitées selon l'horodatage des éléments individuels. Chaque fenêtre contient un nombre fixe d'éléments.
Vous définissez les fenêtres suivantes avec le SDK Apache Beam :
- Fenêtres bascules (appelées fenêtres fixes dans Apache Beam)
- Fenêtres récurrentes (appelées fenêtres glissantes dans Apache Beam)
- Fenêtres de session
Tumbling windows
Une fenêtre bascule représente un intervalle de temps cohérent et disjoint dans le flux de données.
Par exemple, si vous définissez une fenêtre bascule de 30 secondes, les éléments avec des valeurs d'horodatage [0:00:00-0:00:30) sont dans la première fenêtre. Les éléments associés à des valeurs d'horodatage [0:00:30-0:01:00) se trouvent dans la deuxième fenêtre.
L'image suivante illustre la division des éléments dans des fenêtres bascules de 30 secondes.

Hopping windows
Une fenêtre récurrente représente un intervalle de temps cohérent dans le flux de données. Les fenêtres récurrentes peuvent se chevaucher, tandis que les fenêtres bascules sont disjointes.
Par exemple, une fenêtre récurrente peut démarrer toutes les trente secondes et capturer une minute de données. La fréquence à laquelle les fenêtres récurrentes démarrent s'appelle la période. Cet exemple présente une fenêtre d'une minute avec une période de 30 secondes.
L'image suivante montre comment les éléments sont divisés en fenêtres récurrentes d'une minute avec une période de 30 secondes.
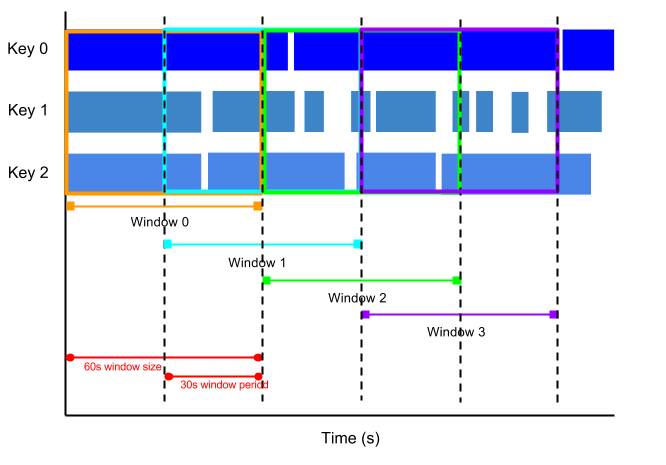
Pour utiliser des moyennes de données, utilisez des fenêtres récurrentes. Vous pouvez utiliser des fenêtres récurrentes d'une minute avec une période de trente secondes pour calculer une moyenne mobile d'une minute toutes les trente secondes.
Session windows (Fenêtres de session)
Une fenêtre de session contient des éléments dans une durée d'intervalle d'un autre élément. La durée d'intervalle correspond à un intervalle entre les nouvelles données d'un flux de données. Si les données arrivent après la durée d'intervalle, elles sont attribuées à une nouvelle fenêtre.
Par exemple, les fenêtres de session peuvent diviser un flux de données représentant l'activité de la souris de l'utilisateur. Ce flux de données peut comporter de longues périodes d'inactivité entrecoupées de nombreux clics. Une fenêtre de session peut contenir les données générées par les clics.
Le fenêtrage de session attribue des fenêtres différentes à chaque clé de données. Les fenêtres bascules et récurrentes contiennent tous les éléments dans l'intervalle spécifié, quelles que soient les clés de données.
L'image suivante montre comment les éléments sont divisés en fenêtres de session.

Filigranes
Un filigrane est un seuil qui indique à quel moment Dataflow attend l'arrivée de toutes les données d'une fenêtre. Si le filigrane a dépassé la fin de la fenêtre et que de nouvelles données arrivent avec un horodatage compris dans la fenêtre, les données sont considérées comme étant en retard. Pour en savoir plus, consultez la section Filigranes et données en retard dans la documentation Apache Beam.
Dataflow suit les filigranes pour les raisons suivantes :
- Il n'est pas certain que les données arrivent dans l'ordre chronologique ou à des intervalles prévisibles.
- Il n'est pas certain que les événements de données apparaissent dans les pipelines dans le même ordre que celui où ils ont été générés.
La source de données détermine le filigrane. Vous pouvez autoriser les données en retard avec le SDK Apache Beam.
Déclencheurs
Les déclencheurs déterminent à quel moment émettre les résultats agrégés à l'arrivée des données. Par défaut, les résultats sont émis lorsque le filigrane dépasse la fin de la fenêtre.
Vous pouvez utiliser le SDK Apache Beam pour créer ou modifier des déclencheurs pour chaque collection dans un pipeline de traitement par flux.
Le SDK Apache Beam peut définir des déclencheurs qui fonctionnent sur n'importe quelle combinaison des conditions suivantes :
- Heure de l'événement, comme indiqué par l'horodatage de chaque élément de données.
- Heure de traitement, soit l'heure à laquelle l'élément de données est traité à une étape donnée du pipeline.
- Nombre d'éléments de données dans une collection.