La E/S administrada permite que Dataflow administre conectores de E/S específicos que se usan en las canalizaciones de Apache Beam. La E/S administrada simplifica la administración de las canalizaciones que se integran con las fuentes y los receptores admitidos.
La E/S administrada consta de dos componentes que funcionan en conjunto:
Es una transformación de Apache Beam que proporciona una API común para crear conectores de E/S (fuentes y receptores).
Un servicio de Dataflow que administra estos conectores de E/S en tu nombre, incluida la capacidad de actualizarlos de forma independiente de la versión de Apache Beam
Entre las ventajas de las E/S administradas, se incluyen las siguientes:
Actualizaciones automáticas Dataflow actualiza automáticamente los conectores de E/S administrados en tu canalización. Esto significa que tu canalización recibe correcciones de seguridad, mejoras de rendimiento y correcciones de errores para estos conectores, sin necesidad de realizar cambios en el código. Para obtener más información, consulta Actualizaciones automáticas.
API coherente: Tradicionalmente, los conectores de E/S en Apache Beam tienen APIs distintas, y cada conector se configura de una manera diferente. La E/S administrada proporciona una sola API de configuración que usa propiedades de clave-valor, lo que genera un código de canalización más simple y coherente. Para obtener más información, consulta la API de Configuration.
Requisitos
Los siguientes SDKs admiten E/S administrada:
- SDK de Apache Beam para Java, versión 2.58.0 o posterior
- SDK de Apache Beam para Python, versión 2.61.0 o posterior
El servicio de backend requiere Dataflow Runner v2. Si Runner v2 no está habilitado, tu canalización se seguirá ejecutando, pero no obtendrá los beneficios del servicio de E/S administrado.
Actualizaciones automáticas
Las canalizaciones de Dataflow con conectores de E/S administrados usan automáticamente la versión confiable más reciente del conector, de la siguiente manera:
Cuando envías un trabajo, Dataflow usa la versión más reciente del conector que se probó y funciona bien.
En el caso de los trabajos de transmisión, Dataflow busca actualizaciones cada vez que inicias un trabajo de reemplazo y usa automáticamente la versión más reciente que se sabe que funciona bien. Dataflow realiza esta verificación incluso si no cambias ningún código en el trabajo de reemplazo.
No tienes que preocuparte por actualizar manualmente el conector ni la versión de Apache Beam de tu canalización.
En el siguiente diagrama, se muestra el proceso de actualización. El usuario crea una canalización de Apache Beam con la versión X del SDK. Cuando el usuario envía el trabajo, Dataflow verifica la versión de la E/S administrada y la actualiza a la versión Y.
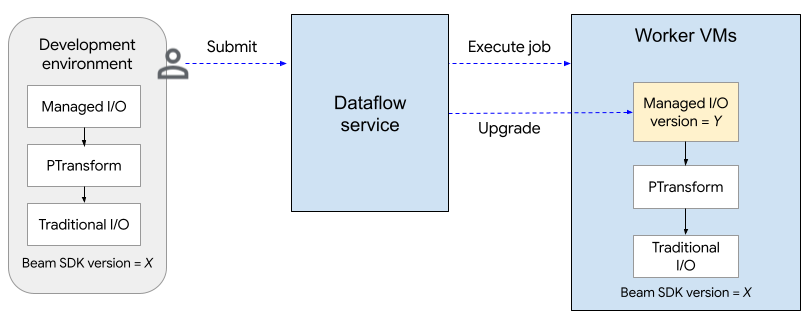
El proceso de actualización agrega unos dos minutos al tiempo de inicio de un trabajo. Para verificar el estado de las operaciones de E/S administradas, busca entradas de registro que incluyan la cadena "Managed Transform(s)".
API de configuración
La E/S administrada es una transformación de Apache Beam lista para usar que proporciona una API coherente para configurar fuentes y receptores.
Java
Para crear cualquier fuente o receptor compatible con E/S administradas, usa la clase Managed. Especifica qué fuente o receptor crear como instancia y pasa un conjunto de parámetros de configuración, de manera similar a lo siguiente:
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
También puedes pasar parámetros de configuración como un archivo YAML. Para obtener un ejemplo de código completo, consulta Lectura desde Apache Iceberg.
Python
Importa el módulo apache_beam.transforms.managed y llama al método managed.Read o managed.Write. Especifica qué fuente o receptor crear como instancia y pasa un conjunto de parámetros de configuración, de manera similar a lo siguiente:
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
También puedes pasar parámetros de configuración como un archivo YAML. Para ver un ejemplo de código completo, consulta Lee desde Apache Kafka.
Destinos dinámicos
En algunos receptores, el conector de E/S administrado puede seleccionar de forma dinámica un destino según los valores de los campos en los registros entrantes.
Para usar destinos dinámicos, proporciona una cadena de plantilla para el destino. La cadena de plantilla puede incluir nombres de campos entre corchetes, como "tables.{field1}". En el tiempo de ejecución, el conector sustituye el valor del campo para cada registro entrante y, así, determina el destino de ese registro.
Por ejemplo, supongamos que tus datos tienen un campo llamado airport. Podrías establecer el destino en "flights.{airport}". Si airport=SFO, el registro se escribe en flights.SFO. Para los campos anidados, usa la notación de puntos. Por ejemplo: {top.middle.nested}.
Para ver un código de ejemplo que muestra cómo usar destinos dinámicos, consulta Escribe con destinos dinámicos.
Filtros
Es posible que desees filtrar ciertos campos antes de que se escriban en la tabla de destino. En el caso de los receptores que admiten destinos dinámicos, puedes usar los parámetros drop, keep o only para este propósito. Estos parámetros te permiten incluir metadatos de destino en los registros de entrada sin escribir los metadatos en el destino.
Puedes establecer, como máximo, uno de estos parámetros para un receptor determinado.
| Parámetro de configuración | Tipo de datos | Descripción |
|---|---|---|
drop |
lista de cadenas | Es una lista de nombres de campos que se quitarán antes de escribir en el destino. |
keep |
lista de cadenas | Es una lista de nombres de campos que se conservarán cuando se escriba en el destino. Se descartan otros campos. |
only |
string | Nombre de exactamente un campo para usar como registro de nivel superior cuando se escribe en el destino. Se descartan todos los demás campos. Este campo debe ser de tipo fila. |
Fuentes y receptores compatibles
La E/S administrada admite las siguientes fuentes y receptores.
Para obtener más información, consulta Conectores de E/S administrados en la documentación de Apache Beam.