マネージド I/O を使用すると、Dataflow は Apache Beam パイプラインで使用される特定の I/O コネクタを管理できます。マネージド I/O は、サポートされているソースとシンクを統合するパイプラインの管理を簡素化します。
マネージド I/O は、連携して動作する次の 2 つのコンポーネントで構成されています。
I/O コネクタ(ソースとシンク)を作成するための共通の API を提供する Apache Beam 変換。
これらの I/O コネクタをユーザーに代わって管理する Dataflow サービス。Apache Beam のバージョンとは別にアップグレードする機能も含まれます。
マネージド I/O の利点は次のとおりです。
自動アップグレード。Dataflow は、パイプライン内のマネージド I/O コネクタを自動的にアップグレードします。つまり、コードを変更することなく、これらのコネクタのセキュリティ修正、パフォーマンスの改善、バグの修正をパイプラインで受け取ることができます。詳細については、自動アップグレードをご覧ください。
一貫性のある API。これまで、Apache Beam の I/O コネクタには個別の API があり、各コネクタは異なる方法で構成されていました。マネージド I/O は、Key-Value プロパティを使用する単一構成の API を提供するため、パイプライン コードがよりシンプルで一貫性のあるものになります。詳細については、構成 API をご覧ください。
要件
次の SDK は、マネージド I/O をサポートしています。
- Apache Beam SDK for Java バージョン 2.58.0 以降
- Apache Beam SDK for Python バージョン 2.61.0 以降
バックエンド サービスには Dataflow Runner v2 が必要です。Runner v2 が有効になっていない場合でも、パイプラインは実行されますが、マネージド I/O サービスのメリットは得られません。
自動アップグレード
マネージド I/O コネクタを使用する Dataflow パイプラインでは、信頼できるコネクタの最新バージョンが自動的に使用されます。
ジョブを送信すると、Dataflow はテスト済みで正常に動作する最新バージョンのコネクタを使用します。
ストリーミング ジョブの場合、Dataflow は置換ジョブを起動するたびに更新を確認し、正常であることが確認されている最新バージョンを自動的に使用します。Dataflow は、置換ジョブのコードを変更しない場合でも、このチェックを実行します。
コネクタやパイプラインの Apache Beam バージョンを手動で更新する必要はありません。
次の図は、アップグレード プロセスを示しています。ユーザーが SDK バージョン X を使用して Apache Beam パイプラインを作成します。ユーザーがジョブを送信すると、Dataflow はマネージド I/O のバージョンを確認し、バージョン Y にアップグレードします。
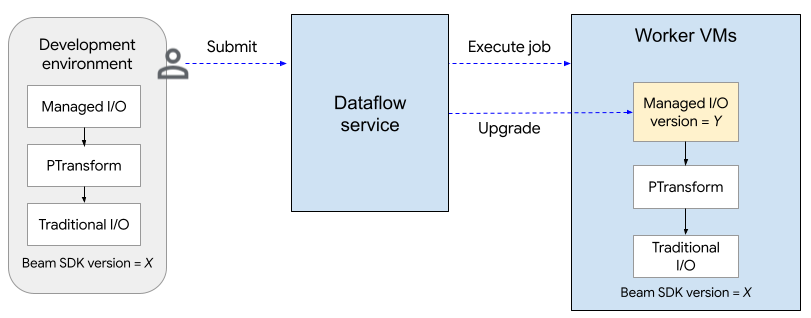
アップグレード プロセスにより、ジョブの起動時間が 2 分ほど長くなります。マネージド I/O オペレーションのステータスを確認するには、文字列「Managed Transform(s)」を含むログエントリを探します。
Configuration API
マネージド I/O は、ソースとシンクを構成するための一貫した API を提供する、すぐに使用可能な Apache Beam 変換です。
Java
マネージド I/O でサポートされているソースまたはシンクを作成するには、Managed クラスを使用します。インスタンス化するソースまたはシンクを指定し、次のように一連の構成パラメータを渡します。
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
構成パラメータを YAML ファイルとして渡すこともできます。完全なコード例については、Apache Iceberg から読み取るをご覧ください。
Python
apache_beam.transforms.managed モジュールをインポートし、managed.Read または managed.Write メソッドを呼び出します。インスタンス化するソースまたはシンクを指定し、次のように一連の構成パラメータを渡します。
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
構成パラメータを YAML ファイルとして渡すこともできます。完全なコード例については、Apache Kafka から読み取るをご覧ください。
ダイナミック デスティネーション
一部のシンクでは、マネージド I/O コネクタは、受信レコードのフィールド値に基づいて宛先を動的に選択できます。
ダイナミック デスティネーションを使用するには、宛先のテンプレート文字列を指定します。テンプレート文字列には、"tables.{field1}" などのフィールド名を中かっこで囲んで含めることができます。実行時に、コネクタは受信レコードごとにフィールドの値を置き換えて、そのレコードの宛先を特定します。
たとえば、データに airport という名前のフィールドがあるとします。宛先を "flights.{airport}" に設定できます。airport=SFO の場合、レコードは flights.SFO に書き込まれます。ネストされたフィールドにはドット表記を使用します。例: {top.middle.nested}。
ダイナミック デスティネーションの使用方法を示すコード例については、ダイナミック デスティネーションで書き込むをご覧ください。
フィルタリング
特定のフィールドを宛先テーブルに書き込む前にフィルタリングが必要になる場合があります。ダイナミック デスティネーションをサポートするシンクでは、この目的で drop、keep、only パラメータを使用できます。これらのパラメータを使用すると、メタデータを宛先に書き込むことなく、入力レコードに宛先メタデータを含めることができます。
シンクごとに設定できるパラメータは 1 つだけです。
| 構成パラメータ | データ型 | 説明 |
|---|---|---|
drop |
文字列のリスト | 宛先に書き込む前に削除するフィールド名のリスト。 |
keep |
文字列のリスト | 宛先に書き込むときに保持するフィールド名のリスト。他のフィールドは削除されます。 |
only |
文字列 | 宛先に書き込むときに最上位レコードとして使用するフィールドの名前(1 つのみ)。他のフィールドはすべて削除されます。このフィールドは行型にする必要があります。 |
サポートされているソースとシンク
マネージド I/O は、次のソースとシンクをサポートしています。