Puedes usar la infraestructura de registro integrada del SDK de Apache Beam para registrar información al ejecutar tu flujo de procesamiento. Puedes usar la Google Cloud consola para monitorizar la información de registro durante y después de las ejecuciones de tu canalización.
Añadir mensajes de registro a una canalización
Java
El SDK de Apache Beam para Java recomienda registrar los mensajes de los trabajadores mediante la biblioteca Simple Logging Facade for Java (SLF4J) de código abierto. El SDK de Apache Beam para Java implementa la infraestructura de registro necesaria para que tu código Java solo tenga que importar la API SLF4J. A continuación, crea una instancia de Logger para habilitar el registro de mensajes en el código de tu canal.
En el caso del código o las bibliotecas preexistentes, el SDK de Apache Beam para Java configura una infraestructura de registro adicional. Se registran los mensajes de registro generados por las siguientes bibliotecas de registro de Java:
Python
El SDK de Apache Beam para Python proporciona el paquete de biblioteca logging, que permite a los trabajadores de la canalización generar mensajes de registro. Para usar las funciones de la biblioteca, debes importarla:
import logging
Go
El SDK de Apache Beam para Go proporciona el paquete de biblioteca log, que permite a los trabajadores de la canalización generar mensajes de registro. Para usar las funciones de la biblioteca, debes importarla:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Ejemplo de código de mensaje de registro de trabajador
Java
En el siguiente ejemplo se usa SLF4J para el registro de Dataflow. Para obtener más información sobre cómo configurar SLF4J para el registro de Dataflow, consulta el artículo Consejos para Java.
El ejemplo WordCount de Apache Beam se puede modificar para que genere un mensaje de registro cuando se encuentre la palabra "love" en una línea del texto procesado. El código añadido se indica en negrita en el siguiente ejemplo (se incluye el código circundante para proporcionar contexto).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
El ejemplo wordcount.py de Apache Beam se puede modificar para que genere un mensaje de registro cuando se encuentre la palabra "love" en una línea del texto procesado.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
El ejemplo wordcount.go de Apache Beam se puede modificar para que genere un mensaje de registro cuando se encuentre la palabra "love" en una línea del texto procesado.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Si la canalización WordCount modificada se ejecuta de forma local con el DirectRunner predeterminado y la salida se envía a un archivo local (--output=./local-wordcounts), la salida de la consola incluye los mensajes de registro añadidos:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
De forma predeterminada, solo se envían a Cloud Logging las líneas de registro marcadas con INFO o un nivel superior. Para cambiar este comportamiento, consulta Configurar niveles de registro de trabajador de canalización.
Python
Si la canalización WordCount modificada se ejecuta de forma local con el DirectRunner predeterminado y la salida se envía a un archivo local (--output=./local-wordcounts), la salida de la consola incluye los mensajes de registro añadidos:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
De forma predeterminada, solo se envían a Cloud Logging las líneas de registro marcadas con INFO o un nivel superior. Para cambiar este comportamiento, consulta Configurar niveles de registro de trabajador de canalización.
No sobrescribas la configuración de registro con funciones logging.config, ya que esto podría inhabilitar los controladores de registro preconfigurados que
transmiten los registros de la canalización a Dataflow y Cloud Logging.
Go
Si la canalización WordCount modificada se ejecuta de forma local con el DirectRunner predeterminado y la salida se envía a un archivo local (--output=./local-wordcounts), la salida de la consola incluye los mensajes de registro añadidos:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
De forma predeterminada, solo se envían a Cloud Logging las líneas de registro marcadas con INFO o un nivel superior.
Controlar el volumen de los registros
También puedes reducir el volumen de los registros generados cambiando los niveles de registro de la canalización. Si no quieres seguir ingiriendo algunos o todos tus registros de Dataflow, añade una exclusión de Logging para excluir los registros de Dataflow. A continuación, exporta los registros a otro destino, como BigQuery, Cloud Storage o Pub/Sub. Para obtener más información, consulta el artículo sobre cómo controlar la ingestión de registros de Dataflow.
Límite de registro y limitación de frecuencia
Los mensajes de registro de los trabajadores están limitados a 15.000 mensajes cada 30 segundos por trabajador. Si se alcanza este límite, se añade un mensaje de registro de un solo trabajador que indica que se ha limitado el registro:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Almacenamiento y conservación de registros
Los registros operativos se almacenan en el segmento de registros _Default. El nombre del servicio de la API Logging es dataflow.googleapis.com. Para obtener más información sobre los tipos de recursos monitorizados y los servicios de Google Cloud Platform que se usan en Cloud Logging, consulta Recursos y servicios monitorizados.
Para obtener información sobre cuánto tiempo conservan las entradas de registro, consulta la información sobre la conservación en Cuotas y límites: periodos de conservación de registros.
Para obtener información sobre cómo ver los registros operativos, consulta Monitorizar y ver registros de la canalización.
Monitorizar y ver registros de flujos de procesamiento
Cuando ejecutas tu flujo de procesamiento en el servicio Dataflow, puedes usar la interfaz de monitorización de Dataflow para ver los registros emitidos por tu flujo de procesamiento.
Ejemplo de registro de trabajador de Dataflow
La canalización WordCount modificada se puede ejecutar en la nube con las siguientes opciones:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Ver registros
Como el flujo de procesamiento en la nube WordCount usa la ejecución de bloqueo, los mensajes de la consola se generan durante la ejecución del flujo de procesamiento. Una vez que se inicia el trabajo, se muestra en la consola un enlace a la página de la consolaGoogle Cloud , seguido del ID del trabajo de la canalización:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
La URL de la consola lleva a la interfaz de monitorización de Dataflow, que incluye una página de resumen de la tarea enviada. Muestra un gráfico de ejecución dinámica a la izquierda y un resumen de la información a la derecha. Haz clic en keyboard_capslock en el panel inferior para desplegar el panel de registros.
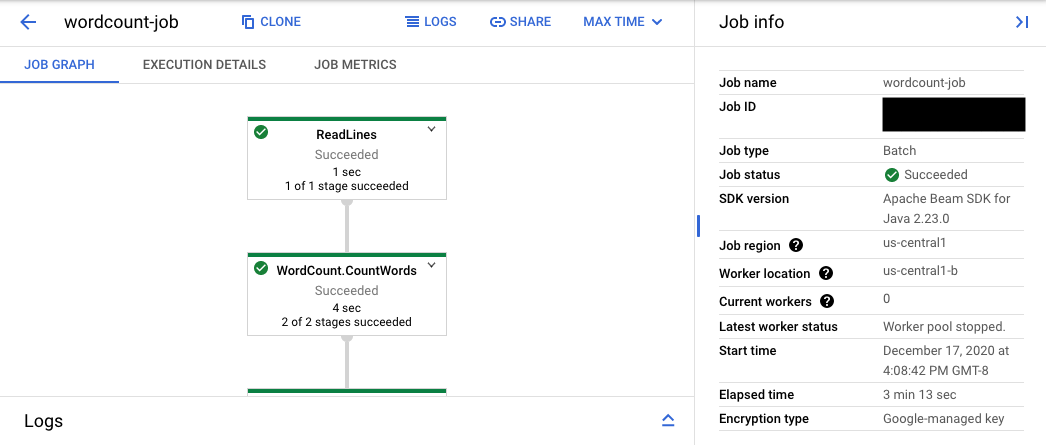
De forma predeterminada, en el panel de registros se muestran los registros de trabajos, que informan del estado del trabajo en su conjunto. Para filtrar los mensajes que aparecen en el panel de registros, haz clic en Informaciónarrow_drop_down y filter_listFiltrar registros.
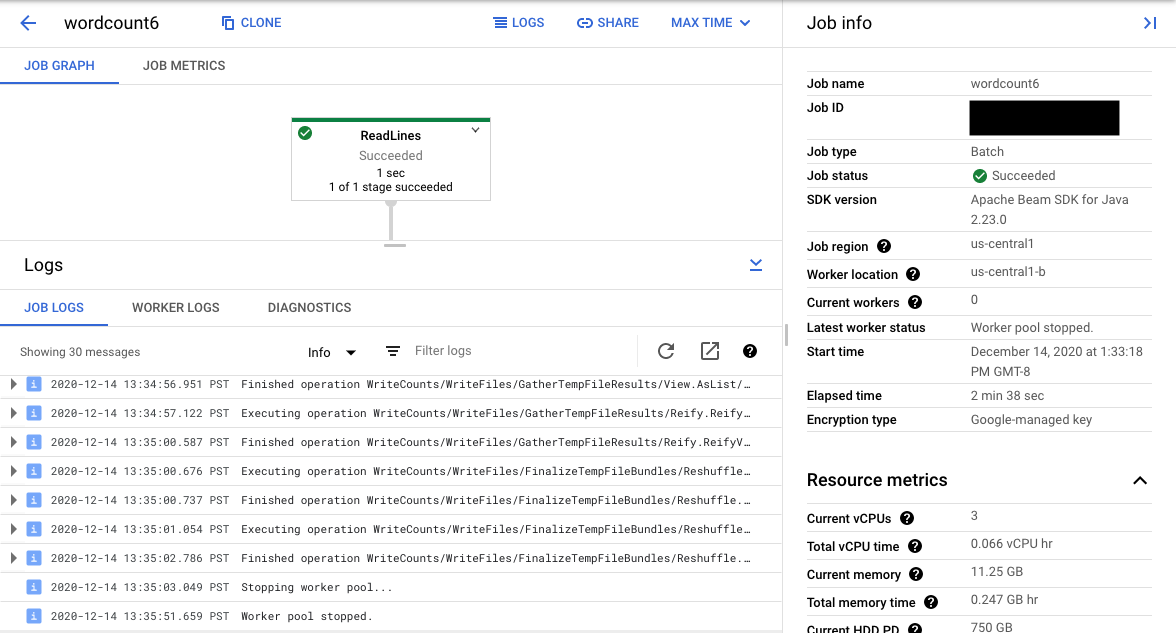
Si seleccionas un paso de la canalización en el gráfico, la vista cambia a Registros de pasos generados por tu código y el código generado que se ejecuta en el paso de la canalización.

Para volver a Registros de trabajos, borra el paso haciendo clic fuera del gráfico o usando el botón Anular selección del paso del panel lateral derecho.
Ve al explorador de registros
Para abrir Explorador de registros y seleccionar diferentes tipos de registros, en el panel de registros, haz clic en Ver en Explorador de registros (el botón de enlace externo).
En el Explorador de registros, para ver el panel con los diferentes tipos de registros, haz clic en el botón Campos de registro.
En la página Explorador de registros, la consulta puede filtrar los registros por paso de trabajo o por tipo de registro. Para quitar filtros, haz clic en el botón Mostrar consulta y edita la consulta.
Para ver todos los registros disponibles de un trabajo, sigue estos pasos:
En el campo Consulta, introduce la siguiente consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Sustituye JOB_ID por el ID de tu trabajo.
Haz clic en Realizar una consulta.
Si usas esta consulta y no ves los registros de tu trabajo, haz clic en Editar hora.
Ajusta las horas de inicio y finalización y, a continuación, haz clic en Aplicar.
Tipos de registros
Explorador de registros también incluye registros de infraestructura de tu canalización. Usa los registros de errores y advertencias para diagnosticar los problemas observados en la canalización. Los errores y las advertencias de los registros de infraestructura que no están relacionados con un problema de la canalización no indican necesariamente que haya un problema.
A continuación, se muestra un resumen de los distintos tipos de registros que se pueden consultar en la página Explorador de registros:
- Los registros job-message contienen mensajes a nivel de trabajo que generan varios componentes de Dataflow. Por ejemplo, la configuración de escalado automático, el momento en que los trabajadores se inician o se cierran, el progreso de los pasos de la tarea y los errores de la tarea. Los errores a nivel de trabajador que se originan en el código de usuario que falla y que están presentes en los registros de trabajador también se propagan a los registros de mensajes de trabajo.
- Los registros de trabajador los generan los trabajadores de Dataflow. Los trabajadores realizan la mayor parte del trabajo de la canalización (por ejemplo, aplican tus
ParDos a los datos). Los registros de trabajadores contienen mensajes registrados por tu código y por Dataflow. - Los registros worker-startup están presentes en la mayoría de los trabajos de Dataflow y pueden registrar mensajes relacionados con el proceso de inicio. El proceso de inicio incluye la descarga de los archivos JAR del trabajo desde Cloud Storage y, a continuación, el inicio de los trabajadores. Si hay algún problema al iniciar los workers, estos registros son un buen punto de partida.
- Los registros de harness contienen mensajes del Runner v2.
- Los registros de shuffler contienen mensajes de los trabajadores que consolidan los resultados de las operaciones de la canalización paralela.
- Los registros system contienen mensajes de los sistemas operativos host de las VMs de trabajo. En algunos casos, pueden registrar fallos de procesos o eventos de falta de memoria (OOM).
- Los registros de docker y kubelet contienen mensajes relacionados con estas tecnologías públicas, que se usan en los trabajadores de Dataflow.
- Los registros de nvidia-mps contienen mensajes sobre las operaciones del servicio multiproceso (MPS) de NVIDIA.
Definir los niveles de registro de los trabajadores de la canalización
Java
El nivel de registro de SLF4J predeterminado que establece el SDK de Apache Beam para Java en los trabajadores es INFO. Se emitirán todos los mensajes de registro de INFO o superior (INFO,
WARN, ERROR). Puedes definir un nivel de registro predeterminado diferente
para admitir niveles de registro de SLF4J inferiores (TRACE o DEBUG) o definir diferentes
niveles de registro para diferentes paquetes de clases en tu código.
Se proporcionan las siguientes opciones de canalización para que puedas definir los niveles de registro de los trabajadores desde la línea de comandos o de forma programática:
--defaultSdkHarnessLogLevel=<level>: usa esta opción para definir todos los registradores en el nivel predeterminado especificado. Por ejemplo, la siguiente opción de línea de comandos anulará el nivel de registroINFOpredeterminado de Dataflow y lo definirá comoDEBUG:
--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: use esta opción para definir el nivel de registro de los paquetes o las clases especificados. Por ejemplo, para anular el nivel de registro predeterminado de la canalización del paqueteorg.apache.beam.runners.dataflowy asignarle el valorTRACE, haz lo siguiente:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Para anular varios valores, proporciona un mapa JSON:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- Las opciones de canalización
defaultSdkHarnessLogLevelysdkHarnessLogLevelOverridesno se admiten en las canalizaciones que usan las versiones 2.50.0 y anteriores del SDK de Apache Beam sin Runner v2. En ese caso, usa las opciones de--defaultWorkerLogLevel=<level>y--workerLogLevelOverrides={"<package or class>":"<level>"}. Para hacer varias sustituciones, proporciona un mapa JSON:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
El siguiente ejemplo define mediante programación las opciones de registro de la canalización con valores predeterminados que se pueden anular desde la línea de comandos:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
El nivel de registro predeterminado que establece el SDK de Apache Beam para Python en los trabajadores es INFO. Se emitirán todos los mensajes de registro de INFO o superior (INFO,
WARNING, ERROR, CRITICAL).
Puedes definir un nivel de registro predeterminado diferente para admitir niveles de registro inferiores (DEBUG)
o definir niveles de registro diferentes para distintos módulos de tu código.
Se ofrecen dos opciones de canalización para que puedas definir los niveles de registro de los trabajadores desde la línea de comandos o de forma programática:
--default_sdk_harness_log_level=<level>: usa esta opción para definir todos los registradores en el nivel predeterminado especificado. Por ejemplo, la siguiente opción de línea de comandos anula el nivel de registroINFOpredeterminado de Dataflow y lo define comoDEBUG:
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: usa esta opción para definir el nivel de registro de los módulos especificados. Por ejemplo, para anular el nivel de registro predeterminado del móduloapache_beam.runners.dataflowy asignarle el valorDEBUG, haz lo siguiente:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Para anular varios valores, proporciona un mapa JSON:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
En el siguiente ejemplo se usa la clase WorkerOptions para definir mediante programación las opciones de registro de la canalización, que se pueden anular desde la línea de comandos:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Haz los cambios siguientes:
PROJECT_NAME: el nombre del proyectoJOB_NAME: nombre del trabajoSTORAGE_BUCKET: el nombre de Cloud StorageDATAFLOW_REGION: la región en la que quieres desplegar la tarea de DataflowLa marca
--regionanula la región predeterminada que se ha definido en el servidor de metadatos, en tu cliente local o en las variables de entorno.
Go
Esta función no está disponible en el SDK de Apache Beam para Go.
Ver el registro de las tareas de BigQuery iniciadas
Cuando usas BigQuery en tu canalización de Dataflow, se inician trabajos de BigQuery para realizar varias acciones en tu nombre. Estas acciones pueden incluir la carga de datos, la exportación de datos y otras tareas similares. Para solucionar problemas y monitorizar, la interfaz de monitorización de Dataflow tiene información adicional sobre estas tareas de BigQuery disponible en el panel Registros.
La información de los trabajos de BigQuery que se muestra en el panel Registros se almacena y se carga desde una tabla del sistema de BigQuery. Se incurre en un coste de facturación cuando se consulta la tabla de BigQuery subyacente.
Ver los detalles del trabajo de BigQuery
Para ver la información de las tareas de BigQuery, su canalización debe usar Apache Beam 2.24.0 o una versión posterior.
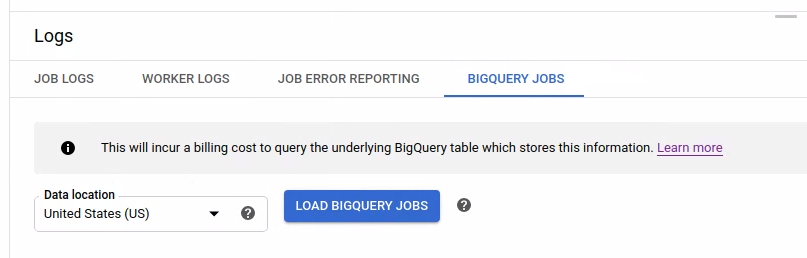
Para ver las tareas de BigQuery, abra la pestaña Tareas de BigQuery y seleccione la ubicación de las tareas de BigQuery. A continuación, haz clic en Cargar tareas de BigQuery y confirma el cuadro de diálogo. Una vez que se haya completado la consulta, se mostrará la lista de tareas.
Se proporciona información básica sobre cada trabajo, como el ID, el tipo, la duración y otros detalles.
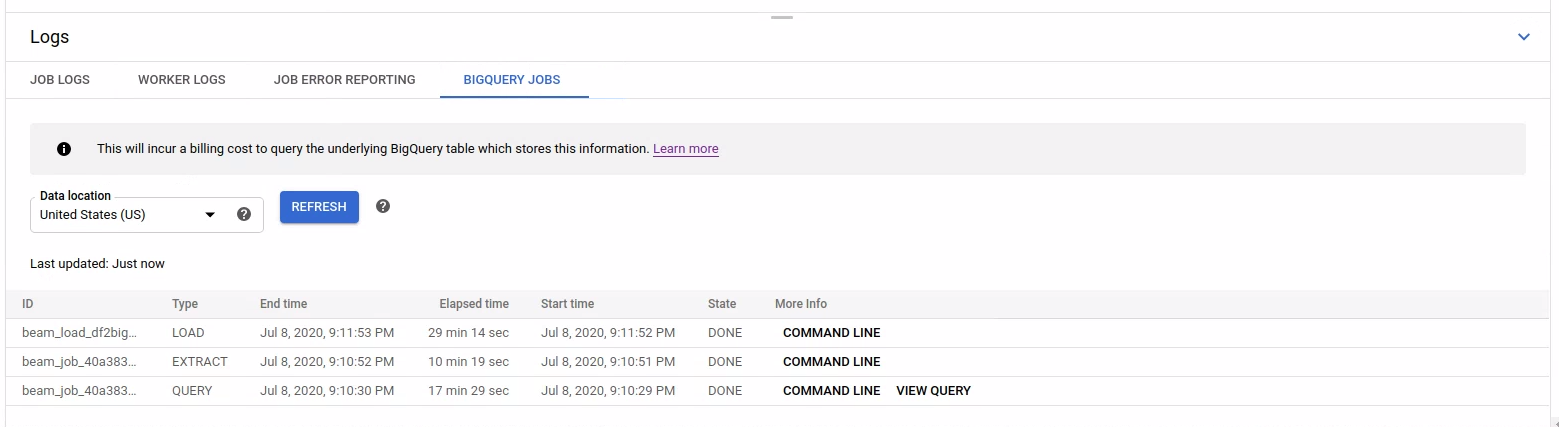
Para obtener información más detallada sobre un trabajo específico, haz clic en Línea de comandos en la columna Más información.
En la ventana modal de la línea de comandos, copia el comando bq jobs describe y ejecútalo de forma local o en Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
El comando bq jobs describe genera JobStatistics, que proporciona más detalles útiles para diagnosticar una tarea de BigQuery lenta o bloqueada.
También puedes usar BigQueryIO con una consulta SQL para enviar una tarea de consulta. Para ver la consulta SQL que usa el trabajo, haz clic en Ver consulta en la columna Más información.
Ver diagnósticos
La pestaña Diagnóstico del panel Registros recoge y muestra determinadas entradas de registro producidas en sus pipelines. Estas entradas incluyen mensajes que indican un problema probable con la canalización y mensajes de error con rastreos de la pila. Las entradas de registro recogidas se desduplican y se combinan en grupos de errores.
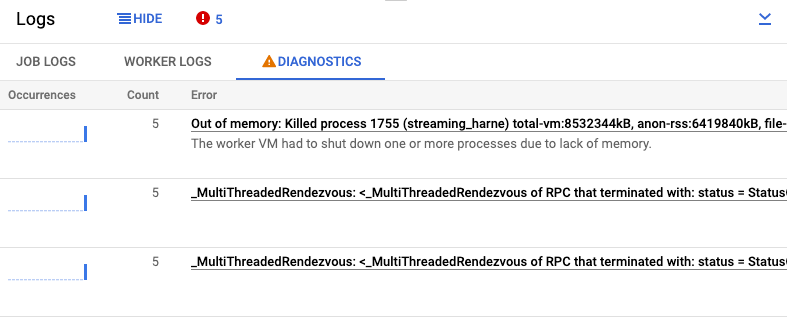
El informe de errores incluye la siguiente información:
- Una lista de errores con mensajes de error
- El número de veces que se ha producido cada error
- Un histograma que indica cuándo se ha producido cada error
- La hora en la que se produjo el error más recientemente
- La hora en la que se produjo el error por primera vez
- El estado del error
Para ver el informe de errores de un error concreto, haga clic en la descripción de la columna Errores. Se muestra la página Informes de errores. Si se trata de un error de servicio, se mostrará un enlace a la guía de solución de problemas.
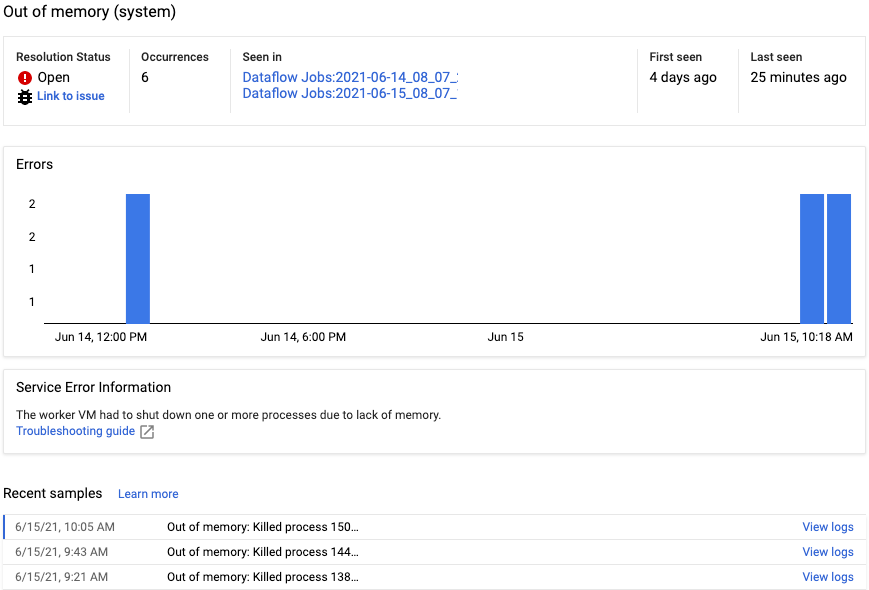
Para obtener más información sobre la página, consulta Ver y filtrar errores.
Silenciar un error
Para silenciar un mensaje de error, sigue estos pasos:
- Abra la pestaña Diagnóstico.
- Haz clic en el error que quieras silenciar.
- Abre el menú de estado de la resolución. Los estados tienen las siguientes etiquetas: Abierto, Confirmado, Resuelto o Silenciado.
- Selecciona Silenciados.