Dataflow 모니터링 인터페이스는 각 작업을 작업 그래프와 같은 그래픽으로 표시합니다. 작업 그래프에서는 작업 요약, 작업 로그, 파이프라인의 각 단계에 대한 정보도 제공합니다.
작업에 대한 작업 그래프를 보려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Dataflow > 작업 페이지로 이동합니다.
작업을 선택합니다.
작업 그래프 탭을 클릭합니다.
기본적으로 작업 그래프 페이지에는 그래프 뷰가 표시됩니다. 작업 그래프를 표로 보려면 작업 단계 뷰에서 테이블 뷰를 선택합니다. 테이블 뷰에는 동일한 정보가 다른 형식으로 포함됩니다. 테이블 뷰는 다음과 같은 시나리오에 유용합니다.
- 작업에 단계가 많아 작업 그래프를 탐색하기 어려운 경우
- 특정 속성으로 작업 단계를 정렬하고 싶은 경우. 예를 들어 테이블을 실제 경과 시간으로 정렬하여 느린 단계를 식별할 수 있습니다.
그래프 뷰
작업 그래프는 파이프라인의 각 변환을 상자로 나타냅니다. 다음 이미지는 변환 3개(Read PubSub Events, 5m Window, Write File(s))가 있는 작업 그래프를 보여줍니다.

각 상자에는 다음 정보가 포함됩니다.
상태: 다음 중 하나입니다.
- 실행 중: 단계가 실행 중입니다.
- 대기 중: FlexRS 작업 단계가 대기 중입니다.
- 성공: 단계가 성공적으로 완료되었습니다.
- 중지됨: 작업이 중단되어 단계가 중지되었습니다.
- 알 수 없음: 상태를 보고하지 못했습니다.
- 실패: 단계를 완료하지 못했습니다.
이 단계를 실행하는 작업 단계 수
단계가 복합 변환을 나타내는 경우 단계를 확장하여 하위 변환을 볼 수 있습니다. 단계를 펼치려면 노드 펼치기 화살표를 클릭합니다.
변환 이름
Dataflow에는 모니터링 작업 그래프에 표시되는 변환 이름을 가져오는 몇 가지 방법이 있습니다. 템플릿 이름은 Dataflow 모니터링 인터페이스, 로그 파일, 디버깅 도구를 포함하여 공개적으로 표시 가능한 장소에 사용됩니다. 사용자 이름 또는 조직 이름과 같은 개인 식별 정보를 포함하는 이름을 변환하지 마세요.
자바
- 사용자가 변환을 적용할 때 Dataflow는 할당 받은 이름을 사용할 수 있습니다.
apply메서드에 제공하는 첫 번째 인수가 변환 이름이 됩니다. - Dataflow는 클래스 이름(커스텀 변환을 구축한 경우) 또는
DoFn함수 객체 이름(ParDo와 같은 코어 변환을 사용하는 경우)에서 변환 이름을 유추할 수 있습니다.
Python
- 사용자가 변환을 적용할 때 Dataflow는 할당 받은 이름을 사용할 수 있습니다. 변환의
label인수를 지정하여 변환 이름을 설정할 수 있습니다. - Dataflow는 클래스 이름(커스텀 변환을 구축한 경우) 또는
DoFn함수 객체 이름(ParDo와 같은 코어 변환을 사용하는 경우)에서 변환 이름을 유추할 수 있습니다.
Go
- 사용자가 변환을 적용할 때 Dataflow는 할당 받은 이름을 사용할 수 있습니다.
Scope를 지정하여 변환 이름을 설정하세요. DoFn구조를 사용하는 경우 구조체 이름에서, 또는 함수 이름DoFn을 사용하는 경우 함수 이름으로부터 Dataflow가 변환 이름을 유추할 수 있습니다.
단계 정보 보기
작업 그래프에서 단계를 클릭하면 단계 정보 패널에 단계에 대한 세부정보가 표시됩니다. 자세한 내용은 작업 단계 정보를 참고하세요.
병목 현상
Dataflow가 병목 현상을 감지하면 작업 그래프에 영향을 받는 단계에 경고 기호가 표시됩니다. 병목 현상의 원인을 확인하려면 단계를 클릭하여 단계 정보 패널을 엽니다. 자세한 내용은 병목 현상 문제 해결을 참고하세요.

작업 그래프 예시
이 섹션에서는 파이프라인 코드의 예와 해당 작업 그래프를 보여줍니다.
기본 작업 그래프
파이프라인 코드:자바// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
작업 그래프:
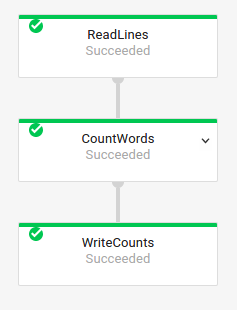
|
복합 변환이 포함된 작업 그래프
복합 변환은 중첩된 하위 변환 여러 개가 포함되어 있는 변환입니다. 작업 그래프에서 복합 변환을 확장할 수 있습니다. 변환을 확장하고 하위 변환을 보려면 화살표를 클릭합니다.
파이프라인 코드:
자바// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
작업 그래프:
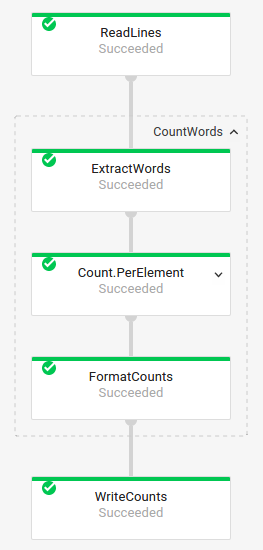
|
파이프라인 코드에서 다음 코드를 사용하여 복합 변환을 호출할 수 있습니다.
result = transform.apply(input);
이런 방식으로 호출된 복합 변환은 예상되는 중첩을 생략하므로 Dataflow 모니터링 인터페이스에서 확장된 상태로 나타날 수 있습니다. 파이프라인 실행 시 안정적인 고유 이름에 대한 경고 또는 오류가 발생할 수도 있습니다.
이러한 문제를 방지하려면 권장 형식을 사용하여 변환을 호출해야 합니다.
result = input.apply(transform);