이 페이지에서는 Dataflow의 자동 확장 일괄 파이프라인에서 유연한 리소스 예약(FlexRS)을 사용 설정하는 방법을 설명합니다.
FlexRS는 고급 예약 기술, Dataflow Shuffle 서비스, 선점형 가상 머신(VM) 인스턴스와 일반 VM의 조합을 사용하여 일괄 처리 비용을 줄입니다. Dataflow는 선점형 VM과 일반 VM을 동시에 실행하여 시스템 이벤트 발생 시 Compute Engine이 선점형 VM 인스턴스를 중지하는 경우 사용자 환경을 개선시킵니다. FlexRS를 사용하면 파이프라인이 계속해서 진행되고 Compute Engine에서 선점형 VM을 선점할 때 이전 작업이 손실되지 않습니다.
FlexRS가 적용되는 작업은 조인과 그룹화에 서비스 기반 Dataflow Shuffle을 사용합니다. 그 결과 FlexRS 작업은 임시 계산 결과를 저장하는 데 Persistent Disk 리소스를 사용하지 않습니다. FlexRS는 Dataflow Shuffle을 사용함으로써 작업자 VM의 선점을 더 효과적으로 처리할 수 있습니다. Dataflow 서비스에서 나머지 작업자에 데이터를 재배포할 필요가 없기 때문입니다. 각 Dataflow 작업자에게는 머신 이미지와 임시 로그를 저장하기 위한 용도로 25GB의 작은 Persistent Disk 볼륨이 여전히 필요합니다.
지원 및 제한 사항
- 일괄 파이프라인을 지원합니다.
- Java용 Apache Beam SDK 2.12.0 이상, Python용 Apache Beam SDK 2.12.0 이상 또는 Go용 Apache Beam SDK가 필요합니다.
- Dataflow Shuffle을 사용합니다. FlexRS를 켜면 Dataflow Shuffle이 자동으로 사용 설정됩니다.
- GPU를 지원하지 않습니다.
- Compute Engine 예약을 지원하지 않습니다.
- FlexRS 작업에는 예약 지연이 있습니다. 따라서 FlexRS는 특정 기간 내에 완료할 수 있는 일일 또는 주별 작업과 같은 시간이 중요하지 않은 작업 부하에 가장 적합합니다.
지연된 예약
FlexRS 작업을 제출하면 Dataflow 서비스는 이 작업을 큐에 넣고 작업 생성 기준 6시간 이내에 실행을 위해 제출합니다. Dataflow는 이 기간 내에서 사용 가능한 용량 및 기타 요소를 감안하여 작업을 시작하기에 가장 적합한 시간을 찾습니다
FlexRS 작업을 제출하면 Dataflow 서비스는 다음 단계를 실행합니다.
- 작업 제출 직후 작업 ID를 반환합니다.
- 조기 유효성 검사를 수행합니다.
조기 유효성 검사 결과를 사용하여 다음 단계를 결정합니다.
- 성공인 경우 지연 실행을 대기하도록 작업을 큐에 넣습니다.
- 그 외의 모든 경우 작업은 실패하고 Dataflow 서비스는 오류를 보고합니다.
유효성 검사가 성공하면 Dataflow 모니터링 인터페이스에서 작업에 ID와 Queued 상태가 표시됩니다. 유효성 검사가 실패하면 작업에 Failed 상태가 표시됩니다.
조기 유효성 검사
FlexRS 작업은 제출 시 즉각 실행되지는 않습니다. 조기 유효성 검사 중에 Dataflow 서비스는 실행 파라미터와 IAM 역할 및 네트워크 구성과 같은 Google Cloud Platform 환경 설정을 확인합니다. Dataflow는 작업 제출 시점에 최대한 작업의 유효성을 검사하고 잠재적인 오류를 보고합니다. 이 조기 유효성 검사 프로세스에 대해서는 요금이 청구되지 않습니다.
조기 유효성 검사 단계에서는 사용자 코드가 실행되지 않습니다. Apache Beam Direct Runner 또는 비 FlexRS 작업을 사용하여 문제가 없는지 코드를 확인해야 합니다. 작업 생성과 작업의 지연된 예약 사이에 Google Cloud 환경이 변경된 경우 조기 유효성 검사에서 성공한 작업이라도 실행 시점에 실패할 수 있습니다.
FlexRS 사용 설정
FlexRS 작업을 생성하면 작업이 큐에 저장됨 상태인 경우에도 동시 작업 할당량이 소비됩니다. 조기 유효성 검사 프로세스는 다른 할당량을 확인하거나 예약하지 않습니다. 따라서 FlexRS를 사용 설정하기 전에 작업을 실행하기에 충분한 Google Cloud 프로젝트 리소스 할당량이 있는지 확인해야 합니다. 공개 IP 매개변수를 끄지 않을 경우 선점형 CPU, 일반 CPU, IP 주소에 대한 부가적인 할당량도 여기에 포함됩니다.
충분한 할당량이 없는 경우 FlexRS 작업이 지연될 때 계정의 리소스가 충분하지 않을 수 있습니다. Dataflow는 기본적으로 작업자 풀에서 작업자의 90%에 선점형 VM을 선택합니다. CPU 할당량을 계획할 때는 선점형 VM 할당량이 충분한지 확인하세요. 명시적으로 선점형 VM 할당량을 요청할 수 있으며 그렇지 않을 경우 FlexRS 작업을 적시에 실행하기 위한 리소스가 부족하게 됩니다.
가격 책정
FlexRS 작업 요금은 다음 리소스에 대해 청구됩니다.
- 일반 및 선점형 CPU
- 메모리 리소스
- Dataflow Shuffle 리소스
- 작업자당 25GB의 Persistent Disk 리소스
Dataflow는 선점형 작업자와 일반 작업자를 모두 사용해서 FlexRS 작업을 실행하지만 작업자 유형에 상관없이 일반 Dataflow 가격에 비해 할인된 일정한 요금이 청구됩니다. Dataflow Shuffle 및 Persistent Disk 리소스는 할인되지 않습니다.
자세한 내용은 Dataflow 가격 책정 세부정보 페이지를 참조하세요.
파이프라인 옵션
자바
FlexRS 작업을 사용 설정하려면 다음 파이프라인 옵션을 사용합니다.
--flexRSGoal=COST_OPTIMIZED: 비용 최적화 목표란 Dataflow 서비스가 사용 가능한 할인된 리소스를 선택함을 의미합니다.--flexRSGoal=SPEED_OPTIMIZED: 실행 시간을 단축하도록 최적화합니다. 지정되지 않은 경우--flexRSGoal필드는 기본적으로SPEED_OPTIMIZED로 설정되며, 이 플래그를 생략하는 것과 같습니다.
FlexRS 작업은 다음 실행 매개변수에 영향을 미칩니다.
numWorkers는 초기 작업자 수만 설정합니다. 하지만 비용 관리 목적으로maxNumWorkers를 설정할 수 있습니다.- FlexRS 작업에는
autoscalingAlgorithm옵션을 사용할 수 없습니다. - FlexRS 작업에는
zone플래그를 지정할 수 없습니다. Dataflow 서비스는region매개변수로 지정한 리전의 모든 FlexRS 작업 영역을 선택합니다. - Dataflow 위치를
region으로 선택해야 합니다. workerMachineType에 M2, M3, H3 머신 시리즈를 사용할 수 없습니다.
다음 예시에서는 FlexRS를 사용하기 위해 일반 파이프라인 매개변수에 매개변수를 추가하는 방법을 보여줍니다.
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
region, maxNumWorkers, workerMachineType을 생략할 경우 Dataflow 서비스가 기본값을 결정합니다.
Python
FlexRS 작업을 사용 설정하려면 다음 파이프라인 옵션을 사용합니다.
--flexrs_goal=COST_OPTIMIZED: 비용 최적화 목표란 Dataflow 서비스가 사용 가능한 할인된 리소스를 선택함을 의미합니다.--flexrs_goal=SPEED_OPTIMIZED: 실행 시간을 단축하도록 최적화합니다. 지정되지 않은 경우--flexrs_goal필드는 기본적으로SPEED_OPTIMIZED로 설정되며, 이 플래그를 생략하는 것과 같습니다.
FlexRS 작업은 다음 실행 매개변수에 영향을 미칩니다.
num_workers는 초기 작업자 수만 설정합니다. 하지만 비용 관리 목적으로max_num_workers를 설정할 수 있습니다.- FlexRS 작업에는
autoscalingAlgorithm옵션을 사용할 수 없습니다. - FlexRS 작업에는
zone플래그를 지정할 수 없습니다. Dataflow 서비스는region매개변수로 지정한 리전의 모든 FlexRS 작업 영역을 선택합니다. - Dataflow 위치를
region으로 선택해야 합니다. machine_type에 M2, M3, H3 머신 시리즈를 사용할 수 없습니다.
다음 예시에서는 FlexRS를 사용하기 위해 일반 파이프라인 매개변수에 매개변수를 추가하는 방법을 보여줍니다.
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
region, max_num_workers, machine_type을 생략할 경우 Dataflow 서비스가 기본값을 결정합니다.
Go
FlexRS 작업을 사용 설정하려면 다음 파이프라인 옵션을 사용합니다.
--flexrs_goal=COST_OPTIMIZED: 비용 최적화 목표란 Dataflow 서비스가 사용 가능한 할인된 리소스를 선택함을 의미합니다.--flexrs_goal=SPEED_OPTIMIZED: 실행 시간을 단축하도록 최적화합니다. 지정되지 않은 경우--flexrs_goal필드는 기본적으로SPEED_OPTIMIZED로 설정되며, 이 플래그를 생략하는 것과 같습니다.
FlexRS 작업은 다음 실행 매개변수에 영향을 미칩니다.
num_workers는 초기 작업자 수만 설정합니다. 하지만 비용 관리 목적으로max_num_workers를 설정할 수 있습니다.- FlexRS 작업에는
autoscalingAlgorithm옵션을 사용할 수 없습니다. - FlexRS 작업에는
zone플래그를 지정할 수 없습니다. Dataflow 서비스는region매개변수로 지정한 리전의 모든 FlexRS 작업 영역을 선택합니다. - Dataflow 위치를
region으로 선택해야 합니다. worker_machine_type에 M2, M3, H3 머신 시리즈를 사용할 수 없습니다.
다음 예시에서는 FlexRS를 사용하기 위해 일반 파이프라인 매개변수에 매개변수를 추가하는 방법을 보여줍니다.
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
region, max_num_workers, machine_type을 생략할 경우 Dataflow 서비스가 기본값을 결정합니다.
Dataflow 템플릿
일부 Dataflow 템플릿은 FlexRS 파이프라인 옵션을 지원하지 않습니다. 대안으로 다음 파이프라인 옵션을 사용합니다.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
FlexRS 작업 모니터링
Google Cloud 콘솔의 다음 두 곳에서 FlexRS 작업 상태를 모니터링할 수 있습니다.
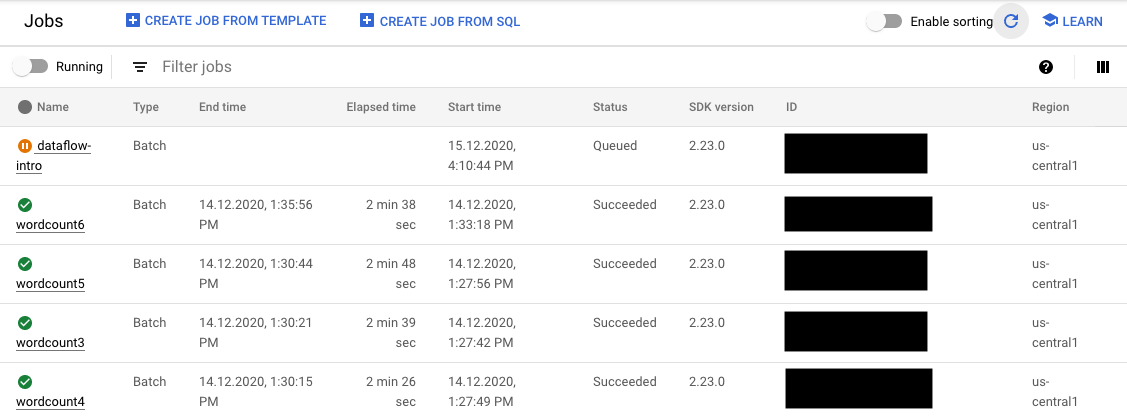
- 모든 작업이 표시되는 작업 페이지
- 제출한 작업의 모니터링 인터페이스 페이지
작업 페이지에서 시작되지 않은 작업의 상태는 큐에 저장됨으로 표시됩니다.
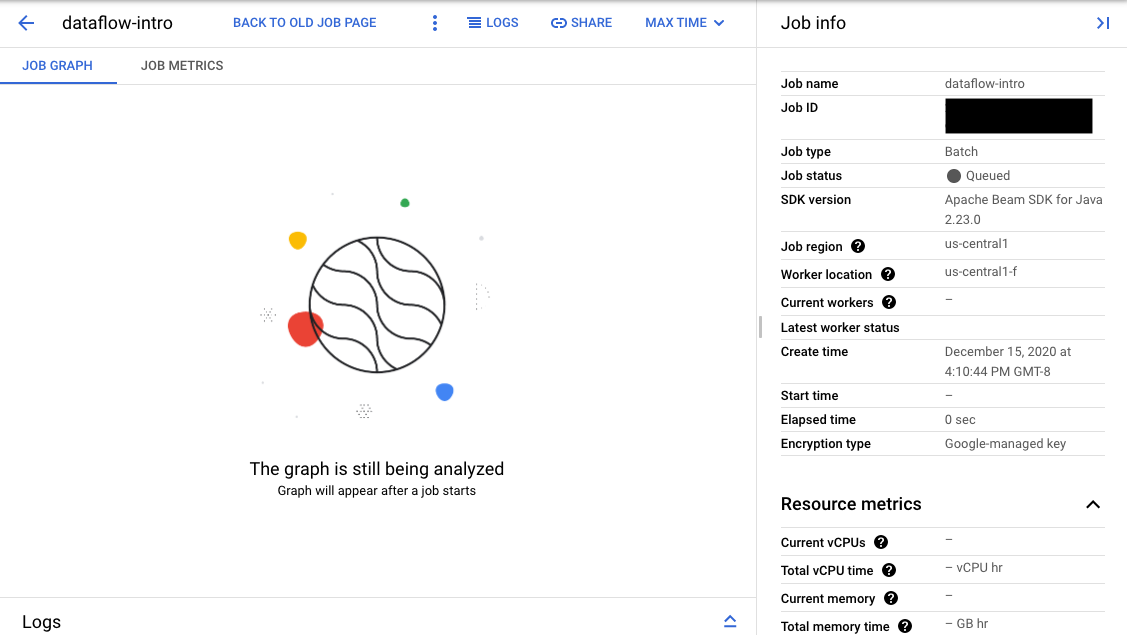
모니터링 인터페이스 페이지에서 큐에서 대기 중인 작업에는 작업 그래프 탭에 '작업 시작 후 그래프가 표시됩니다.'라는 메시지가 표시됩니다.