Halaman ini menjelaskan cara mengaktifkan Flexible Resource Scheduling (FlexRS) untuk pipeline batch yang diskalakan otomatis di Dataflow.
FlexRS mengurangi biaya pemrosesan batch dengan menggunakan teknik penjadwalan lanjutan, layanan Dataflow Shuffle, dan kombinasi instance virtual machine (VM) preemptible dan VM reguler. Dengan menjalankan VM yang dapat di-preempt dan VM reguler secara paralel, Dataflow meningkatkan pengalaman pengguna saat Compute Engine menghentikan instance VM yang dapat di-preempt selama peristiwa sistem. FlexRS membantu memastikan bahwa pipeline terus berjalan dan Anda tidak kehilangan pekerjaan sebelumnya saat Compute Engine mengakhiri VM preemptible Anda.
Tugas dengan FlexRS menggunakan Dataflow Shuffle berbasis layanan untuk menggabungkan dan mengelompokkan. Akibatnya, tugas FlexRS tidak menggunakan resource Persistent Disk untuk menyimpan hasil penghitungan sementara. Dengan menggunakan Dataflow Shuffle, FlexRS dapat menangani penghentian sementara VM pekerja dengan lebih baik, karena layanan Dataflow tidak perlu mendistribusikan ulang data ke pekerja yang tersisa. Setiap pekerja Dataflow masih memerlukan volume Persistent Disk kecil sebesar 25 GB untuk menyimpan image mesin dan log sementara.
Dukungan dan batasan
- Mendukung pipeline batch.
- Memerlukan Apache Beam SDK untuk Java 2.12.0 atau yang lebih baru, Apache Beam SDK untuk Python 2.12.0 atau yang lebih baru, atau Apache Beam SDK untuk Go.
- Menggunakan Dataflow Shuffle. Mengaktifkan FlexRS akan otomatis mengaktifkan Dataflow Shuffle.
- Tidak mendukung GPU.
- Tidak mendukung reservasi Compute Engine.
- Tugas FlexRS mengalami penundaan penjadwalan. Oleh karena itu, FlexRS paling cocok untuk workload yang tidak sensitif terhadap waktu, seperti tugas harian atau mingguan yang dapat diselesaikan dalam jangka waktu tertentu.
Penjadwalan tertunda
Saat Anda mengirimkan tugas FlexRS, layanan Dataflow akan menempatkan tugas ke dalam antrean dan mengirimkannya untuk dieksekusi dalam waktu enam jam setelah pembuatan tugas. Dataflow akan menemukan waktu terbaik untuk memulai tugas dalam jangka waktu tersebut, berdasarkan kapasitas yang tersedia dan faktor lainnya.
Saat Anda mengirimkan tugas FlexRS, layanan Dataflow akan menjalankan langkah-langkah berikut:
- Menampilkan ID tugas segera setelah pengiriman tugas.
- Menjalankan validasi awal
Menggunakan hasil validasi awal untuk menentukan langkah berikutnya.
- Jika berhasil, mengantrekan tugas untuk menunggu peluncuran tertunda.
- Dalam semua kasus lainnya, tugas akan gagal dan layanan Dataflow akan melaporkan error.
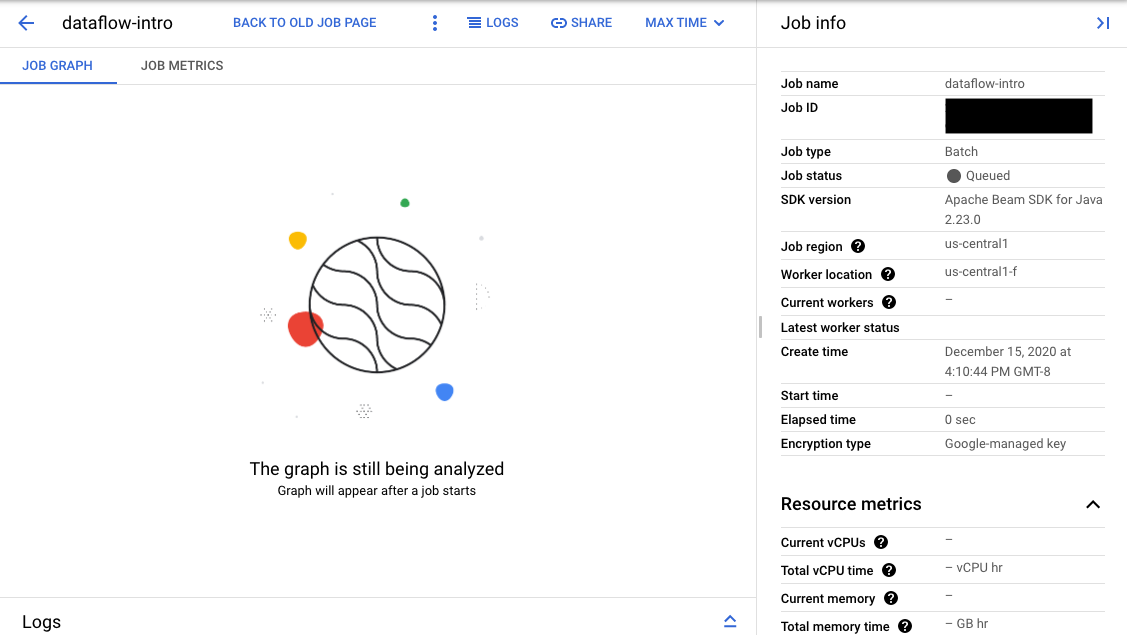
Jika validasi berhasil, di antarmuka pemantauan Dataflow, tugas Anda akan menampilkan ID dan status
Queued. Jika validasi gagal, tugas Anda akan menampilkan status Failed.
Validasi awal
Tugas FlexRS tidak langsung diluncurkan saat pengiriman. Selama validasi awal, layanan Dataflow memverifikasi parameter eksekusi dan setelan lingkunganGoogle Cloud , seperti peran IAM dan konfigurasi jaringan. Dataflow memvalidasi tugas sebanyak mungkin pada waktu pengiriman tugas dan melaporkan potensi error. Anda tidak akan ditagih untuk proses validasi awal ini.
Langkah validasi awal tidak mengeksekusi kode pengguna. Anda harus memverifikasi kode untuk memeriksa masalah menggunakan Direct Runner Apache Beam atau tugas non-FlexRS. Jika ada perubahan lingkungan Google Cloud antara pembuatan tugas dan penjadwalan tugas yang tertunda, tugas mungkin berhasil selama validasi awal, tetapi tetap gagal pada waktu peluncuran.
Mengaktifkan FlexRS
Saat Anda membuat tugas FlexRS, kuota tugas serentak akan diambil, meskipun tugas dalam status Dalam antrean. Proses validasi awal tidak memverifikasi atau mencadangkan kuota lainnya. Oleh karena itu, sebelum mengaktifkan FlexRS, pastikan Anda memiliki Google Cloud kuota resource project yang cukup untuk meluncurkan tugas Anda. Hal ini mencakup kuota tambahan untuk CPU yang dapat di-preempt, CPU reguler, dan alamat IP, kecuali jika Anda menonaktifkan parameter IP Publik.
Jika Anda tidak memiliki cukup kuota, akun Anda mungkin tidak memiliki cukup resource saat tugas FlexRS Anda di-deploy. Dataflow memilih VM preemptible untuk 90% pekerja di kumpulan pekerja secara default. Saat merencanakan kuota CPU, pastikan Anda memiliki kuota VM preemptible yang cukup. Anda dapat secara eksplisit meminta kuota VM yang dapat di-preempt; jika tidak, tugas FlexRS Anda tidak akan memiliki resource untuk dieksekusi tepat waktu.
Harga
Tugas FlexRS ditagih untuk resource berikut:
- CPU reguler dan preemptible
- Sumber daya memori
- Resource Dataflow Shuffle
- Sumber daya Persistent Disk sebesar 25 GB per pekerja
Meskipun Dataflow menggunakan pekerja preemptible dan reguler untuk mengeksekusi tugas FlexRS, Anda akan ditagih dengan tarif diskon yang seragam dibandingkan dengan harga Dataflow reguler, terlepas dari jenis pekerja. Resource Dataflow Shuffle dan Persistent Disk tidak mendapatkan diskon.
Untuk mengetahui informasi selengkapnya, baca halaman detail harga Dataflow.
Opsi pipeline
Java
Untuk mengaktifkan tugas FlexRS, gunakan opsi pipeline berikut:
--flexRSGoal=COST_OPTIMIZED, dengan tujuan yang dioptimalkan untuk biaya berarti layanan Dataflow memilih resource diskon yang tersedia.--flexRSGoal=SPEED_OPTIMIZED, yang mengoptimalkan waktu eksekusi yang lebih rendah. Jika tidak ditentukan, kolom--flexRSGoalakan ditetapkan secara default keSPEED_OPTIMIZED, yang sama dengan tidak menyertakan tanda ini.
Tugas FlexRS memengaruhi parameter eksekusi berikut:
numWorkershanya menetapkan jumlah awal pekerja. Namun, Anda dapat menetapkanmaxNumWorkerskarena alasan pengendalian biaya.- Anda tidak dapat menggunakan opsi
autoscalingAlgorithmdengan tugas FlexRS. - Anda tidak dapat menentukan tanda
zoneuntuk tugas FlexRS. Layanan Dataflow memilih zona untuk semua tugas FlexRS di region yang Anda tentukan dengan parameterregion. - Anda harus memilih
Lokasi Dataflow
sebagai
region. - Anda tidak dapat menggunakan seri mesin M2, M3, atau H3 untuk
workerMachineType.
Contoh berikut menunjukkan cara menambahkan parameter ke parameter pipeline reguler untuk menggunakan FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Jika Anda tidak menyertakan region, maxNumWorkers, dan workerMachineType, layanan Dataflow akan menentukan nilai default.
Python
Untuk mengaktifkan tugas FlexRS, gunakan opsi pipeline berikut:
--flexrs_goal=COST_OPTIMIZED, dengan tujuan yang dioptimalkan untuk biaya berarti layanan Dataflow memilih resource diskon yang tersedia.--flexrs_goal=SPEED_OPTIMIZED, yang mengoptimalkan waktu eksekusi yang lebih rendah. Jika tidak ditentukan, kolom--flexrs_goalakan ditetapkan secara default keSPEED_OPTIMIZED, yang sama dengan tidak menyertakan tanda ini.
Tugas FlexRS memengaruhi parameter eksekusi berikut:
num_workershanya menetapkan jumlah awal pekerja. Namun, Anda dapat menetapkanmax_num_workerskarena alasan pengendalian biaya.- Anda tidak dapat menggunakan opsi
autoscalingAlgorithmdengan tugas FlexRS. - Anda tidak dapat menentukan tanda
zoneuntuk tugas FlexRS. Layanan Dataflow memilih zona untuk semua tugas FlexRS di region yang Anda tentukan dengan parameterregion. - Anda harus memilih
Lokasi Dataflow
sebagai
region. - Anda tidak dapat menggunakan seri mesin M2, M3, atau H3 untuk
machine_type.
Contoh berikut menunjukkan cara menambahkan parameter ke parameter pipeline reguler untuk menggunakan FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Jika Anda tidak menyertakan region, max_num_workers, dan machine_type, layanan Dataflow akan menentukan nilai default.
Go
Untuk mengaktifkan tugas FlexRS, gunakan opsi pipeline berikut:
--flexrs_goal=COST_OPTIMIZED, dengan tujuan yang dioptimalkan untuk biaya berarti layanan Dataflow memilih resource diskon yang tersedia.--flexrs_goal=SPEED_OPTIMIZED, yang mengoptimalkan waktu eksekusi yang lebih rendah. Jika tidak ditentukan, kolom--flexrs_goalakan ditetapkan secara default keSPEED_OPTIMIZED, yang sama dengan tidak menyertakan tanda ini.
Tugas FlexRS memengaruhi parameter eksekusi berikut:
num_workershanya menetapkan jumlah awal pekerja. Namun, Anda dapat menetapkanmax_num_workerskarena alasan pengendalian biaya.- Anda tidak dapat menggunakan opsi
autoscalingAlgorithmdengan tugas FlexRS. - Anda tidak dapat menentukan tanda
zoneuntuk tugas FlexRS. Layanan Dataflow memilih zona untuk semua tugas FlexRS di region yang Anda tentukan dengan parameterregion. - Anda harus memilih
Lokasi Dataflow
sebagai
region. - Anda tidak dapat menggunakan seri mesin M2, M3, atau H3 untuk
worker_machine_type.
Contoh berikut menunjukkan cara menambahkan parameter ke parameter pipeline reguler untuk menggunakan FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Jika Anda tidak menyertakan region, max_num_workers, dan machine_type, layanan Dataflow akan menentukan nilai default.
Template Dataflow
Beberapa template Dataflow tidak mendukung opsi pipeline FlexRS. Sebagai alternatif, gunakan opsi pipeline berikut.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Memantau tugas FlexRS
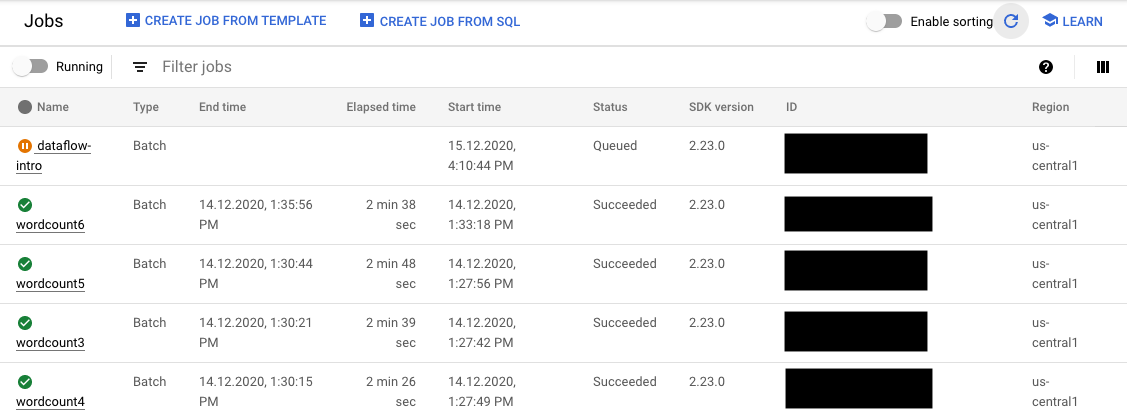
Anda dapat memantau status tugas FlexRS di konsol Google Cloud di dua tempat:
- Halaman Tugas yang menampilkan semua tugas Anda.
- Halaman Antarmuka pemantauan tugas yang Anda kirimkan.
Di halaman Jobs, tugas yang belum dimulai akan menampilkan status Queued.
Di halaman Monitoring interface, tugas yang menunggu dalam antrean menampilkan pesan "Grafik akan muncul setelah tugas dimulai" di tab Job graph.