本頁面說明如何在 Dataflow 中,針對自動調度資源的批次管道啟用彈性資源排程 (FlexRS)。
FlexRS 會透過搭配使用進階排程技術、Dataflow Shuffle 服務,以及先占虛擬機器 (VM) 執行個體與一般 VM,來減少批次處理費用。如果 Compute Engine 在系統事件期間停止先占 VM 執行個體,Dataflow 會透過平行執行先占 VM 與一般 VM 來改善使用者體驗。當 Compute Engine 先占您的先占 VM 時,FlexRS 可協助確保管道繼續進行,並確保未遺失先前的工作。
搭配 FlexRS 的工作會使用服務型 Dataflow Shuffle 進行彙整和分組。因此,FlexRS 工作不會使用 Persistent Disk 資源儲存暫時的計算結果。使用 Dataflow Shuffle 可讓 FlexRS 將工作站 VM 的先占處理得更好,因為 Dataflow 服務不需要將資料重新分配至剩下的工作站。每個 Dataflow 工作站仍需要小量 25 GB 的 Persistent Disk 磁碟區,藉以儲存機器映像檔和暫存記錄。
支援與限制
- 支援批次管道。
- 需要 Java 適用的 Apache Beam SDK 2.12.0 以上版本、Python 適用的 Apache Beam SDK 2.12.0 以上版本,或 Go 適用的 Apache Beam SDK。
- 使用 Dataflow Shuffle。 啟用 FlexRS 會自動啟用 Dataflow Shuffle。
- 不支援 GPU。
- 不支援 Compute Engine 預留資源。
- FlexRS 工作會出現排程延遲,因此,FlexRS 最為適合用於沒有時間要求的工作負載,例如能夠於特定時間範圍內完成的每日或每週工作。
延遲排程
提交 FlexRS 工作時,Dataflow 服務會將工作放入佇列,並在工作建立後六小時內提交來執行。Dataflow 會根據可用容量和其他因子,在特定時間範圍內尋找此工作開始的最佳時機。
提交 FlexRS 工作時,Dataflow 服務會執行下列步驟:
- 工作提交後立即傳回工作 ID。
- 執行初步驗證作業。
利用初步驗證結果決定下一步驟。
- 若結果為成功,工作會排入佇列,並等待延遲啟動。
- 若出現其他結果,則工作會失敗,Dataflow 服務會回報錯誤。
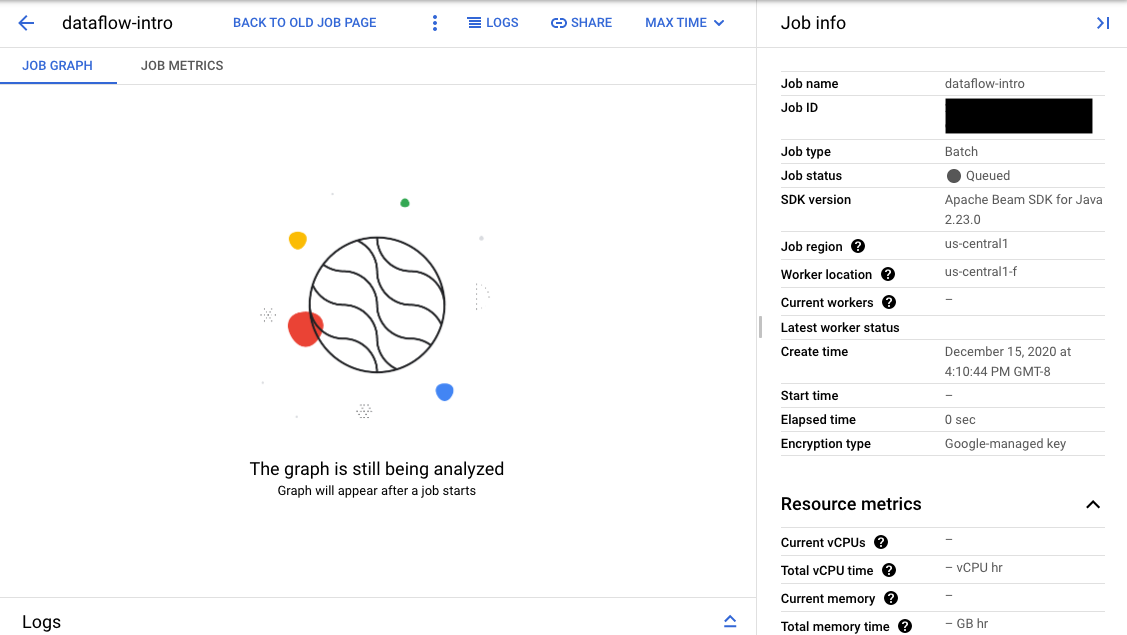
如果驗證成功,在 Dataflow 監控介面中,您的工作會顯示 ID 和狀態
Queued。如果驗證失敗,工作會顯示 Failed 狀態。
初步驗證
FlexRS 工作不會在提交後立即啟動。在初步驗證期間,Dataflow 服務會驗證執行參數和 Google Cloud Platform 環境設定,例如 IAM 角色和網路設定。 Dataflow 會在工作提交時盡可能完成驗證,並回報潛在錯誤。您不需為此初步驗證流程支付費用。
初步驗證步驟不會執行使用者程式碼。您必須透過 Apache Beam Direct Runner 或者非 FlexRS 的工作,驗證您的程式碼,檢查是否有問題。若 Google Cloud 環境在工作建立和工作延遲排程之間出現變動,則工作可能會通過初步驗證階段,但啟動時仍會失敗。
啟用 FlexRS
只要建立 FlexRS 工作就會佔據並行工作配額,即便工作狀態為「Queued」(已排入佇列) 也是如此。初步驗證程序不會驗證或保留任何其他配額。因此,啟用 FlexRS 前,請確認您擁有足夠的 Google Cloud 專案資源配額可啟動工作。這包括先占 CPU、一般 CPU 和 IP 位址的配額,除非您關閉公開 IP 參數。
若您的配額不足,FlexRS 工作部署時,您帳戶的資源可能會不夠。根據預設,Dataflow 會為工作站集區內 90% 的工作站選取先占 VM。規劃 CPU 配額時,請確認您擁有足夠的先占 VM 配額。請務必明確請求先占 VM 配額;否則,您的資源不足,也就無法準時執行 FlexRS 工作。
定價
FlexRS 工作會依據下列資源計費:
- 一般和先占 CPU
- 記憶體資源
- Dataflow Shuffle 資源
- 每個工作站 25 GB 的 Persistent Disk 資源
雖然 Dataflow 同時使用先占和一般工作站來執行 FlexRS 工作,但與一般 Dataflow 定價相比,無論工作站類型為何,都適用相同的折扣費率。Dataflow Shuffle 和 Persistent Disk 資源則沒有折扣。
詳情請參閱 Dataflow 定價詳細資料頁面。
管道選項
Java
如要啟用 FlexRS 工作,請使用下列管道選項:
--flexRSGoal=COST_OPTIMIZED,其中最佳成本目標代表 Dataflow 服務會選擇任何可用的折扣資源。--flexRSGoal=SPEED_OPTIMIZED,並盡可能縮短執行時間。 如果未指定,欄位--flexRSGoal會預設為SPEED_OPTIMIZED,這與省略此旗標相同。
FlexRS 工作會影響下列執行參數:
numWorkers僅會設定工作站的最初數量。不過,您可根據成本控制需求設定maxNumWorkers。- 您無法對 FlexRS 工作使用
autoscalingAlgorithm選項。 - 您無法針對 FlexRS 工作指定
zone標記。對於所有 FlexRS 工作,Dataflow 服務選取的區域就是您在region參數內指定的地區。 - 您必須選取「Dataflow location」(資料流位置) 做為
region。 - 您無法將 M2、M3 或 H3 機器系列用於
workerMachineType。
下列範例說明如何將參數新增至您的一般管道參數,以便使用 FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
若您省略 region、maxNumWorkers 和 workerMachineType,Dataflow 服務會決定預設值。
Python
如要啟用 FlexRS 工作,請使用下列管道選項:
--flexrs_goal=COST_OPTIMIZED,其中最佳成本目標代表 Dataflow 服務會選擇任何可用的折扣資源。--flexrs_goal=SPEED_OPTIMIZED,並盡可能縮短執行時間。 如果未指定,欄位--flexrs_goal會預設為SPEED_OPTIMIZED,這與省略此旗標相同。
FlexRS 工作會影響下列執行參數:
num_workers僅會設定工作站的最初數量。不過,您可根據成本控制需求設定max_num_workers。- 您無法對 FlexRS 工作使用
autoscalingAlgorithm選項。 - 您無法針對 FlexRS 工作指定
zone標記。對於所有 FlexRS 工作,Dataflow 服務選取的區域就是您在region參數內指定的地區。 - 您必須選取「Dataflow location」(資料流位置) 做為
region。 - 您無法將 M2、M3 或 H3 機器系列用於
machine_type。
下列範例說明如何將參數新增至您的一般管道參數,以便使用 FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
若您省略 region、max_num_workers 和 machine_type,Dataflow 服務會決定預設值。
Go
如要啟用 FlexRS 工作,請使用下列管道選項:
--flexrs_goal=COST_OPTIMIZED,其中最佳成本目標代表 Dataflow 服務會選擇任何可用的折扣資源。--flexrs_goal=SPEED_OPTIMIZED,並盡可能縮短執行時間。 如果未指定,欄位--flexrs_goal會預設為SPEED_OPTIMIZED,這與省略此旗標相同。
FlexRS 工作會影響下列執行參數:
num_workers僅會設定工作站的最初數量。不過,您可根據成本控制需求設定max_num_workers。- 您無法對 FlexRS 工作使用
autoscalingAlgorithm選項。 - 您無法針對 FlexRS 工作指定
zone標記。對於所有 FlexRS 工作,Dataflow 服務選取的區域就是您在region參數內指定的地區。 - 您必須選取「Dataflow location」(資料流位置) 做為
region。 - 您無法將 M2、M3 或 H3 機器系列用於
worker_machine_type。
下列範例說明如何將參數新增至您的一般管道參數,以便使用 FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
若您省略 region、max_num_workers 和 machine_type,Dataflow 服務會決定預設值。
Dataflow 範本
部分 Dataflow 範本不支援 FlexRS 管道選項。或者,使用下列管道選項。
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
監控 FlexRS 工作
您可在 Google Cloud 控制台上的兩個位置監控 FlexRS 工作的狀態:
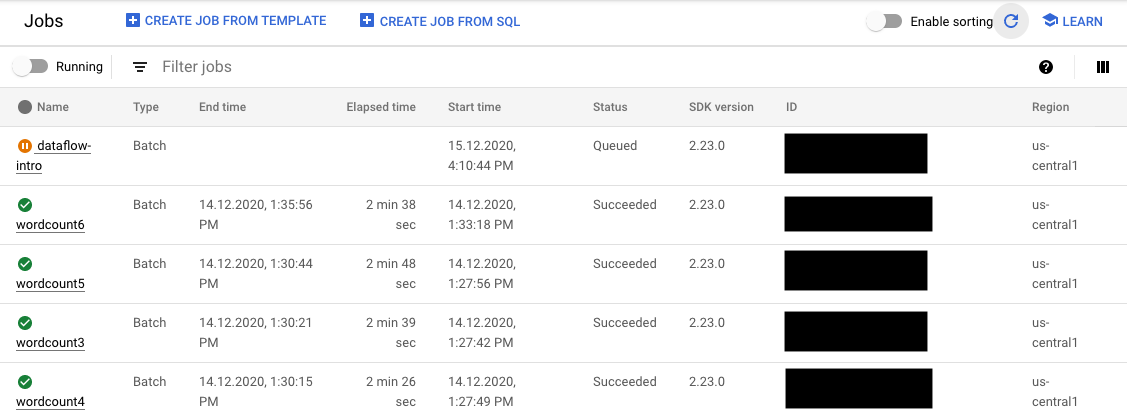
在「Jobs」(工作) 頁面上,尚未開始的工作狀態會顯示為「Queued」(已排入佇列)。
在「Monitoring interface」(監控介面) 頁面上,在佇列中等待的工作會在「Job graph」(工作圖表) 分頁中顯示「圖表隨即會在工作開始後顯示」訊息。