Cette page explique comment activer FlexRS (planification flexible des ressources) pour les pipelines de traitement par lot avec autoscaling dans Dataflow.
La fonctionnalité FlexRS réduit le coût du traitement par lot en s'appuyant sur des techniques de planification avancées, le service Dataflow Shuffle, et une combinaison d'instances de VM préemptives et de VM standards. Grâce à cette exécution combinée de VM préemptives et de VM standards en parallèle, Dataflow améliore l'expérience utilisateur si Compute Engine arrête des instances de VM préemptives lors d'un événement système. FlexRS contribue à garantir que le pipeline continue de progresser et que vous ne perdez pas le travail déjà réalisé lorsque Compute Engine préempte vos VM préemptives.
Les jobs gérés avec FlexRS utilisent la fonctionnalité Dataflow Shuffle basée sur les services pour les jointures et le regroupement. Par conséquent, les jobs FlexRS n'utilisent pas de ressources Persistent Disk pour stocker les résultats de calculs temporaires. L'utilisation de Dataflow Shuffle permet à FlexRS de mieux gérer la préemption d'une VM de nœud de calcul, car le service Dataflow n'a pas à redistribuer les données aux autres nœuds de calcul. Chaque nœud de calcul Dataflow a toujours besoin d'un petit volume de disque persistant de 25 Go pour stocker l'image de la machine et les journaux temporaires.
Compatibilité et limites
- Compatible avec les pipelines de traitement par lot.
- Nécessite le SDK Apache Beam pour Java en version 2.12.0 ou supérieure, le SDK Apache Beam pour Python en version 2.12.0 ou supérieure, ou le SDK Apache Beam pour Go.
- Utilise Dataflow Shuffle. L'activation de FlexRS active Dataflow Shuffle de manière automatique.
- Non compatible avec les GPU.
- Les réservations Compute Engine ne sont pas acceptées.
- Les tâches FlexRS présentent un délai de planification. Par conséquent, FlexRS convient mieux aux charges de travail dont la ponctualité ou l'urgence ne sont pas critiques, par exemple les tâches quotidiennes ou hebdomadaires pouvant être exécutées dans une certaine fenêtre temporelle.
Planification retardée
Lorsque vous envoyez un job FlexRS, le service Dataflow le met en file d'attente et l'envoie pour exécution dans les six heures suivant la création du job. Dataflow sélectionne le moment optimal pour démarrer la tâche dans cette fenêtre de temps, suivant la capacité disponible et d'autres facteurs.
Lorsque vous envoyez une tâche FlexRS, le service Dataflow exécute les étapes suivantes :
- Il renvoie un identifiant de job immédiatement après l'envoi du job.
- Il effectue une validation préliminaire.
Il utilise le résultat de cette validation préliminaire pour déterminer l'étape suivante.
- En cas de succès, il met la tâche en file d'attente, où elle attend son lancement différé.
- Dans tous les autres cas, la tâche échoue et le service Dataflow signale les erreurs.
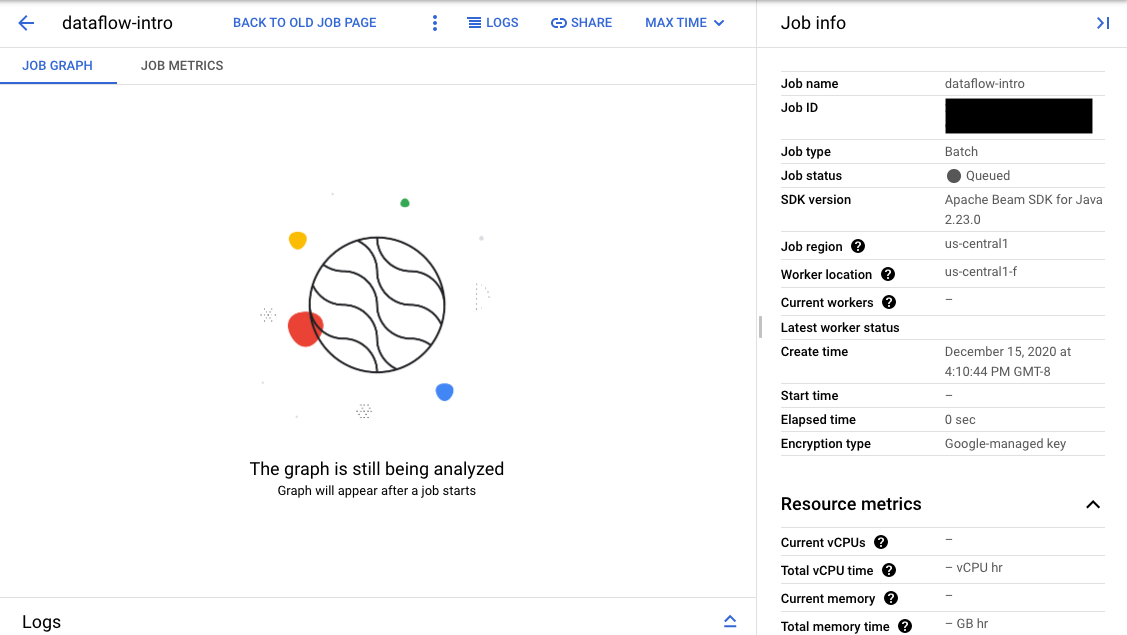
Si la validation réussit, dans l'interface de surveillance de Dataflow, votre job affiche un ID et l'état Queued. Si la validation échoue, votre job affiche l'état Failed.
Validation préliminaire
Les tâches FlexRS ne sont pas lancées immédiatement après leur envoi. Au cours de la validation préliminaire, le service Dataflow vérifie les paramètres d'exécution et les paramètres d'environnementGoogle Cloud , tels que les rôles IAM et les configurations réseau. Dataflow valide la tâche autant que possible au moment de l'envoi et signale les erreurs potentielles. Vous n'êtes pas facturé pour ce processus de validation préliminaire.
L'étape de validation préliminaire n'exécute pas le code de l'utilisateur. Pour y identifier d'éventuels problèmes, vous devez vérifier votre code à l'aide de l'outil Direct Runner d'Apache Beam ou de tâches autres que FlexRS. S'il y a des changements dans l'environnement Google Cloud entre la création de la tâche et son exécution différée, la tâche peut franchir le cap de la validation préliminaire mais échouer quand même à son lancement effectif.
Activer FlexRS
Lorsque vous créez une tâche FlexRS, un quota est défini pour la tâche simultanée, même si celle-ci est encore à l'état Queued (en file d'attente). Le processus de validation préliminaire ne vérifie ni ne réserve aucun autre quota. Par conséquent, avant d'activer FlexRS, vérifiez que vous disposez de quotas de ressources de projet Google Cloud suffisants pour lancer votre job. Cela inclut un quota supplémentaire pour les processeurs préemptifs, les processeurs standards et les adresses IP, à moins que vous ne désactiviez le paramètre d'adresse IP publique.
Si votre quota est insuffisant, il est possible que votre compte ne dispose pas de ressources suffisantes lors du déploiement de votre tâche FlexRS. Par défaut, Dataflow sélectionne des VM préemptives pour 90 % des nœuds de calcul du pool de nœuds de calcul. Lorsque vous planifiez votre quota de processeurs, assurez-vous de disposer d'un quota suffisant de VM préemptives. Vous pouvez explicitement demander un quota de VM préemptives. Dans le cas contraire, votre tâche FlexRS ne disposera pas des ressources nécessaires pour s'exécuter dans le délai imparti.
Tarifs
Les tâches FlexRS font l'objet d'une facturation pour les ressources suivantes :
- Processeurs standards et préemptifs
- Ressources mémoire
- Ressources Dataflow Shuffle
- 25 Go de ressources de disque persistant par nœud de calcul
Bien que Dataflow utilise une combinaison de nœuds de calcul préemptifs et standards pour exécuter une tâche FlexRS, vous êtes facturé à un tarif réduit uniforme comparé aux prix ordinaires de Dataflow, quel que soit le type de nœud de calcul. Les ressources Dataflow Shuffle et de disque persistant ne font pas l'objet d'une remise.
Pour plus d'informations, consultez la section Détails des tarifs de Dataflow.
Options de pipeline
Java
Pour activer une tâche FlexRS, utilisez l'option de pipeline suivante :
--flexRSGoal=COST_OPTIMIZED, où l'objectif de coût optimisé signifie que le service Dataflow choisit toute ressource disponible avec une remise.--flexRSGoal=SPEED_OPTIMIZED, qui optimise le temps d'exécution. Si non spécifié, le champ--flexRSGoalest défini par défaut surSPEED_OPTIMIZED, ce qui revient à omettre cet indicateur.
Les tâches FlexRS affectent les paramètres d'exécution suivants :
numWorkersdéfinit uniquement le nombre initial de nœuds de calcul. Toutefois, vous pouvez choisir de définirmaxNumWorkerspour des raisons de contrôle des coûts.- Vous ne pouvez pas utiliser l'option
autoscalingAlgorithmavec des tâches FlexRS. - Vous ne pouvez pas spécifier l'option
zonepour des tâches FlexRS. Le service Dataflow sélectionne la zone pour toutes les tâches FlexRS de la région que vous avez spécifiée au moyen du paramètreregion. - Vous devez sélectionner un emplacement Dataflow en tant que
region. - Vous ne pouvez pas utiliser les séries de machines M2, M3 ou H3 pour votre
workerMachineType.
L'exemple suivant montre comment ajouter à vos paramètres de pipeline habituels les indicateurs permettant d'utiliser FlexRS :
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Si vous omettez region, maxNumWorkers et workerMachineType, le service Dataflow détermine la valeur par défaut.
Python
Pour activer une tâche FlexRS, utilisez l'option de pipeline suivante :
--flexrs_goal=COST_OPTIMIZED, où l'objectif de coût optimisé signifie que le service Dataflow choisit toute ressource disponible avec une remise.--flexrs_goal=SPEED_OPTIMIZED, qui optimise le temps d'exécution. Si non spécifié, le champ--flexrs_goalest défini par défaut surSPEED_OPTIMIZED, ce qui revient à omettre cet indicateur.
Les tâches FlexRS affectent les paramètres d'exécution suivants :
num_workersdéfinit uniquement le nombre initial de nœuds de calcul. Toutefois, vous pouvez choisir de définirmax_num_workerspour des raisons de contrôle des coûts.- Vous ne pouvez pas utiliser l'option
autoscalingAlgorithmavec des tâches FlexRS. - Vous ne pouvez pas spécifier l'option
zonepour des tâches FlexRS. Le service Dataflow sélectionne la zone pour toutes les tâches FlexRS de la région que vous avez spécifiée au moyen du paramètreregion. - Vous devez sélectionner un emplacement Dataflow en tant que
region. - Vous ne pouvez pas utiliser les séries de machines M2, M3 ou H3 pour votre
machine_type.
L'exemple suivant montre comment ajouter à vos paramètres de pipeline habituels les indicateurs permettant d'utiliser FlexRS :
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Si vous omettez region, max_num_workers et machine_type, le service Dataflow détermine la valeur par défaut.
Go
Pour activer une tâche FlexRS, utilisez l'option de pipeline suivante :
--flexrs_goal=COST_OPTIMIZED, où l'objectif de coût optimisé signifie que le service Dataflow choisit toute ressource disponible avec une remise.--flexrs_goal=SPEED_OPTIMIZED, qui optimise le temps d'exécution. Si non spécifié, le champ--flexrs_goalest défini par défaut surSPEED_OPTIMIZED, ce qui revient à omettre cet indicateur.
Les tâches FlexRS affectent les paramètres d'exécution suivants :
num_workersdéfinit uniquement le nombre initial de nœuds de calcul. Toutefois, vous pouvez choisir de définirmax_num_workerspour des raisons de contrôle des coûts.- Vous ne pouvez pas utiliser l'option
autoscalingAlgorithmavec des tâches FlexRS. - Vous ne pouvez pas spécifier l'option
zonepour des tâches FlexRS. Le service Dataflow sélectionne la zone pour toutes les tâches FlexRS de la région que vous avez spécifiée au moyen du paramètreregion. - Vous devez sélectionner un emplacement Dataflow en tant que
region. - Vous ne pouvez pas utiliser les séries de machines M2, M3 ou H3 pour votre
worker_machine_type.
L'exemple suivant montre comment ajouter à vos paramètres de pipeline habituels les indicateurs permettant d'utiliser FlexRS :
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Si vous omettez region, max_num_workers et machine_type, le service Dataflow détermine la valeur par défaut.
Modèles Dataflow
Certains modèles Dataflow ne sont pas compatibles avec l'option de pipeline FlexRS. Utilisez plutôt l'option de pipeline suivante.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Surveiller les jobs FlexRS
Vous pouvez surveiller l'état de votre tâche FlexRS dans la console Google Cloud à deux endroits :
- Sur la page Tâches, qui affiche l'ensemble des tâches.
- Sur la page Interface de surveillance de la tâche que vous avez envoyée.
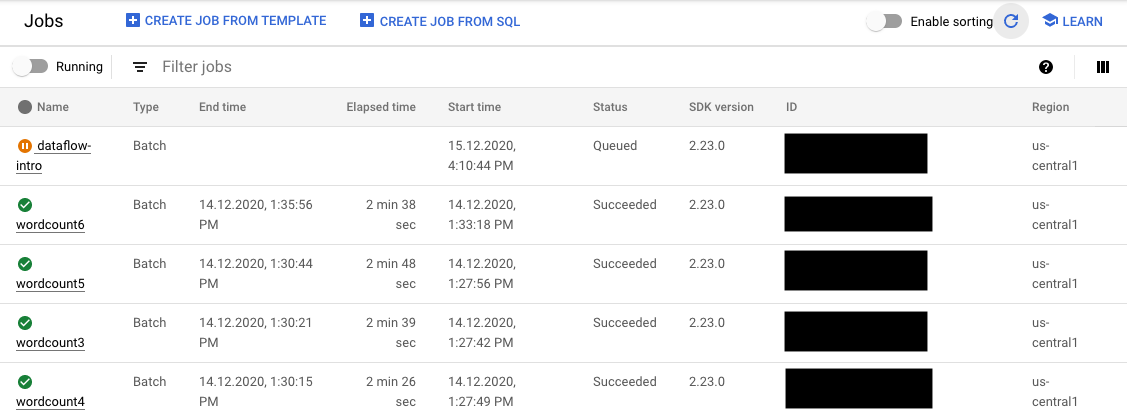
Sur la page des Tâches (Jobs), les tâches qui n'ont pas encore démarré apparaissent avec l'état Queued (en file d'attente).
Sur la page Monitoring interface, les tâches en attente dans la file d'attente affichent le message "Graph display will appear after a job starts" (Le graphique apparaît après le démarrage d'une tâche) dans l'onglet Job graph (Graphique de tâche).