En esta página, se explica cómo habilitar la programación flexible de recursos (FlexRS) para canalizaciones por lotes con ajuste de escala automático en Dataflow.
FlexRS reduce los costos de procesamiento por lotes mediante el uso de técnicas de programación avanzadas, el servicio Dataflow Shuffle y una combinación de instancias de máquinas virtuales interrumpibles (VMs) y de VMs normales. A través de la ejecución de VMs interrumpibles y VMs normales en paralelo, Dataflow mejora la experiencia del usuario en caso de que Compute Engine detenga las instancias de VMs interrumpibles durante un evento del sistema. FlexRS ayuda a garantizar que la canalización progrese y no pierdas trabajo anterior cuando Compute Engine interrumpe las VM interrumpibles.
Los trabajos con FlexRS usan Dataflow Shuffle basado en servicios para unir y agrupar. Como resultado, los trabajos de FlexRS no usan recursos de Persistent Disk para almacenar resultados temporales de cálculos. Usar Dataflow Shuffle permite que FlexRS controle mejor la interrupción de una VM de trabajador, ya que el servicio de Dataflow no tiene que redistribuir los datos a los trabajadores restantes. Cada trabajador de Dataflow necesita 25 GB de volumen de Persistent Disk para almacenar la imagen de la máquina y los registros temporales.
Asistencia y limitaciones
- Admite canalizaciones por lotes.
- Se requiere el SDK de Apache Beam para Java 2.12.0 o versiones posteriores, el SDK de Apache Beam para Python 2.12.0 o versiones posteriores, o el SDK de Apache Beam para Go.
- Usa Dataflow Shuffle. Activar FlexRS también habilita Dataflow Shuffle de forma automática
- No admite GPU.
- No admite reservas de Compute Engine.
- Los trabajos de FlexRS tienen un retraso de programación. Por lo tanto, FlexRS es más adecuado para cargas de trabajo que no son críticas, como los trabajos diarios o semanales que pueden completarse dentro de un período determinado.
Programación retrasada
Cuando envías un trabajo de FlexRS, el servicio de Dataflow lo ubica en una cola y lo envía para que se ejecute dentro de las seis horas posteriores a su creación. Dataflow busca el mejor momento para iniciar el trabajo dentro de ese período, en función de la capacidad disponible y otros factores.
Cuando envías un trabajo de FlexRS, el servicio de Dataflow realiza los siguientes pasos:
- Muestra un ID de trabajo justo después de que se envió el trabajo.
- Realiza una ejecución de validación temprana.
Usa el resultado de la validación temprana para determinar el siguiente paso:
- En caso de éxito, se pone en cola el trabajo para esperar el lanzamiento retrasado.
- En todos los demás casos, el trabajo falla y el servicio de Dataflow informa los errores.
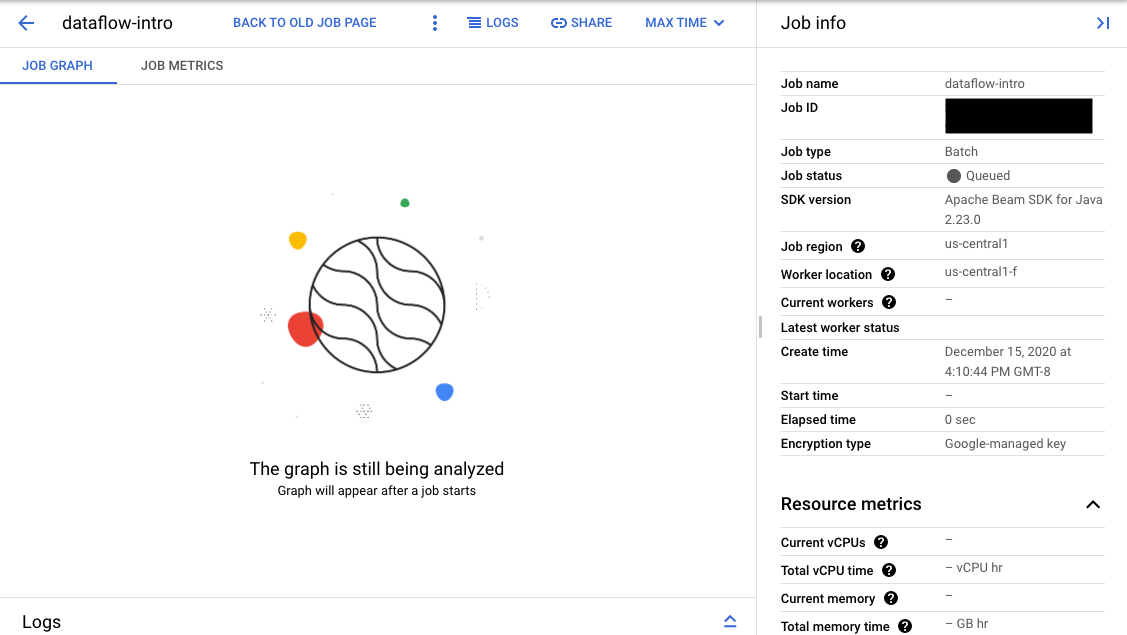
Si la validación se realiza correctamente, en la interfaz de supervisión de Dataflow, tu trabajo muestra un ID y el estado
Queued. Si la validación falla, el trabajo muestra el estado Failed.
Validación temprana
Los trabajos de FlexRS no se inician inmediatamente después del envío. Durante la validación temprana, el servicio de Dataflow verifica los parámetros de ejecución y la configuración del entorno deGoogle Cloud , como las funciones de IAM y las configuraciones de red. Dataflow valida el trabajo tanto como sea posible cuando se lo envía y, luego, informa posibles errores. No se te cobrará por este proceso de validación temprana.
El paso de validación temprana no ejecuta el código de usuario. Debes verificar tu código para comprobar si hay problemas mediante Direct Runner de Apache Beam o trabajos que no son de FlexRS. Si hay Google Cloud cambios en el entorno entre la creación del trabajo y su programación retrasada, es posible que el trabajo pase la validación temprana con éxito, pero que falle en el momento del inicio.
Habilita FlexRS
Cuando creas un trabajo de FlexRS, se toma una cuota de trabajo simultáneo, incluso cuando el trabajo se encuentra en el estado En cola. El proceso de validación temprana no verifica ni reserva ninguna otra cuota. Por lo tanto, antes de habilitar FlexRS, verifica que tengas suficientes Google Cloud cuotas de recursos del proyecto para iniciar tu trabajo. Esto incluye cuota adicional para CPU interrumpibles, CPU normales y direcciones IP, a menos que desactives el parámetro de IP pública.
Si no tienes suficiente cuota, es posible que tu cuenta no tenga recursos suficientes cuando se implemente el trabajo de FlexRS. De forma predeterminada, Dataflow selecciona las VM interrumpibles para el 90% de los trabajadores en el grupo de trabajadores. Cuando planifiques la cuota de CPU, asegúrate de tener suficiente cuota de VM interrumpible. Puedes solicitar explícitamente una cuota de VM interrumpible; de lo contrario, tu trabajo de FlexRS carecerá de los recursos para ejecutarlo de manera oportuna.
Precios
En los trabajos de FlexRS, se cobran los siguientes recursos:
- CPU interrumpibles y normales
- Recursos de memoria
- Recursos de Dataflow Shuffle
- 25 GB de recursos de Persistent Disk por trabajador
Si bien Dataflow usa trabajadores interrumpibles y normales para ejecutar el trabajo de FlexRS, se te cobrará una tarifa uniforme con descuento en comparación con los precios normales de Dataflow, sin importar el tipo de trabajador. No se descuentan los recursos de Dataflow Shuffle ni de Persistent Disk.
Para obtener más información, consulta la página de detalles de los precios de Dataflow.
Opciones de canalización
Java
Para habilitar un trabajo de FlexRS, usa la siguiente opción de canalización:
--flexRSGoal=COST_OPTIMIZED, en el que el objetivo de costo optimizado significa que el servicio de Dataflow elige cualquier recurso con descuento disponible.--flexRSGoal=SPEED_OPTIMIZED, en la que se optimiza para lograr un tiempo de ejecución menor. Si no se especifica, el campo--flexRSGoalse establece de forma predeterminada enSPEED_OPTIMIZED, que es lo mismo que omitir esta marca.
Los trabajos de FlexRS afectan los siguientes parámetros de ejecución:
numWorkerssolo establece la cantidad inicial de trabajadores. Sin embargo, puedes establecermaxNumWorkerspor motivos de control de costos.- No puedes usar la opción
autoscalingAlgorithmcon trabajos de FlexRS. - No puedes especificar la marca
zoneen trabajos de FlexRS. El servicio de Dataflow selecciona la zona de todos los trabajos de FlexRS en la región que especificaste con el parámetroregion. - Debes seleccionar una ubicación de Dataflow como tu
region. - No puedes usar las series de máquinas M2, M3 o H3 para tu
workerMachineType.
En el siguiente ejemplo, se muestra cómo agregar parámetros a tus parámetros de canalización normales a fin de usar FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Si omites region, maxNumWorkers y workerMachineType, el servicio de Dataflow determinará el valor predeterminado.
Python
Para habilitar un trabajo de FlexRS, usa la siguiente opción de canalización:
--flexrs_goal=COST_OPTIMIZED, en el que el objetivo de costo optimizado significa que el servicio de Dataflow elige cualquier recurso con descuento disponible.--flexrs_goal=SPEED_OPTIMIZED, en la que se optimiza para lograr un tiempo de ejecución menor. Si no se especifica, el campo--flexrs_goalse establece de forma predeterminada enSPEED_OPTIMIZED, que es lo mismo que omitir esta marca.
Los trabajos de FlexRS afectan los siguientes parámetros de ejecución:
num_workerssolo establece la cantidad inicial de trabajadores. Sin embargo, puedes establecermax_num_workerspor motivos de control de costos.- No puedes usar la opción
autoscalingAlgorithmcon trabajos de FlexRS. - No puedes especificar la marca
zoneen trabajos de FlexRS. El servicio de Dataflow selecciona la zona de todos los trabajos de FlexRS en la región que especificaste con el parámetroregion. - Debes seleccionar una ubicación de Dataflow como tu
region. - No puedes usar las series de máquinas M2, M3 o H3 para tu
machine_type.
En el siguiente ejemplo, se muestra cómo agregar parámetros a tus parámetros de canalización normales a fin de usar FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Si omites region, max_num_workers y machine_type, el servicio de Dataflow determinará el valor predeterminado.
Go
Para habilitar un trabajo de FlexRS, usa la siguiente opción de canalización:
--flexrs_goal=COST_OPTIMIZED, en el que el objetivo de costo optimizado significa que el servicio de Dataflow elige cualquier recurso con descuento disponible.--flexrs_goal=SPEED_OPTIMIZED, en la que se optimiza para lograr un tiempo de ejecución menor. Si no se especifica, el campo--flexrs_goalse establece de forma predeterminada enSPEED_OPTIMIZED, que es lo mismo que omitir esta marca.
Los trabajos de FlexRS afectan los siguientes parámetros de ejecución:
num_workerssolo establece la cantidad inicial de trabajadores. Sin embargo, puedes establecermax_num_workerspor motivos de control de costos.- No puedes usar la opción
autoscalingAlgorithmcon trabajos de FlexRS. - No puedes especificar la marca
zoneen trabajos de FlexRS. El servicio de Dataflow selecciona la zona de todos los trabajos de FlexRS en la región que especificaste con el parámetroregion. - Debes seleccionar una ubicación de Dataflow como tu
region. - No puedes usar las series de máquinas M2, M3 o H3 para tu
worker_machine_type.
En el siguiente ejemplo, se muestra cómo agregar parámetros a tus parámetros de canalización normales a fin de usar FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Si omites region, max_num_workers y machine_type, el servicio de Dataflow determinará el valor predeterminado.
Plantillas de Dataflow
Algunas plantillas de Dataflow no admiten la opción de canalización de FlexRS. Como alternativa, usa la siguiente opción de canalización.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Supervisa trabajos de FlexRS
Puedes supervisar el estado del trabajo de FlexRS en la consola de Google Cloud en dos lugares:
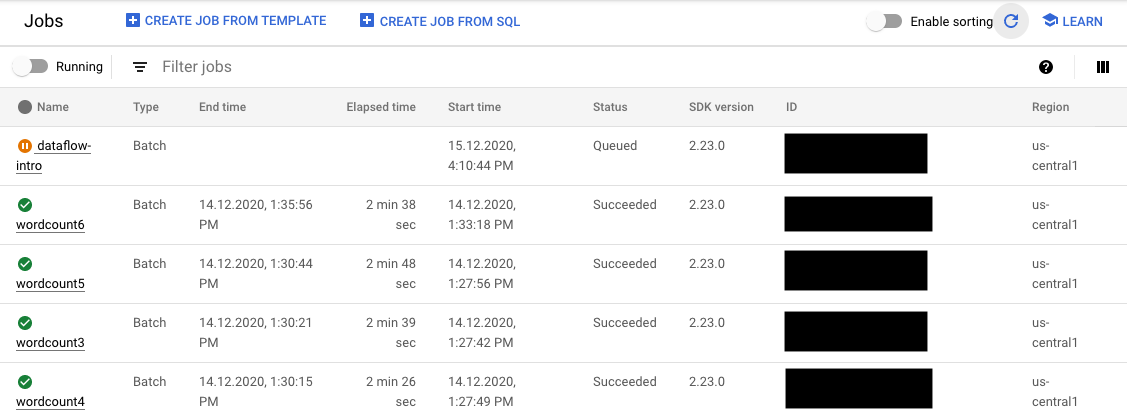
- La página Trabajos, que muestra todos tus trabajos.
- La página de la interfaz de supervisión del trabajo que enviaste.
En la página Trabajos, los trabajos que aún no han comenzado muestran el estado En cola.
En la página Interfaz de supervisión, los trabajos que están en cola muestran el mensaje “El gráfico aparecerá después de que se inicie un trabajo” ("Graph will appear after a job starts") en la pestaña Gráfico del trabajo (Job graph).