Questa pagina spiega come attivare la pianificazione flessibile delle risorse (FlexRS) per le pipeline batch con scalabilità automatica in Dataflow.
FlexRS riduce i costi di elaborazione batch utilizzando tecniche di pianificazione avanzate, il servizio Dataflow Shuffle e una combinazione di istanze di macchine virtuali prerilasciabili e VM normali. Eseguendo VM prerilasciabili e VM normali in parallelo, Dataflow migliora l'esperienza utente quando Compute Engine arresta le istanze VM prerilasciabile durante un evento di sistema. FlexRS contribuisce a garantire che la pipeline continui a fare progressi e che non perdi il lavoro precedente quando Compute Engine prerilascia le tue VM prerilasciabili.
I job con FlexRS utilizzano Dataflow Shuffle basato su servizi per l'unione e il raggruppamento. Di conseguenza, i job FlexRS non utilizzano risorse Persistent Disk per archiviare i risultati temporanei dei calcoli. L'utilizzo di Dataflow Shuffle consente a FlexRS di gestire meglio il prerilascio di una VM worker, perché il servizio Dataflow non deve ridistribuire i dati ai worker rimanenti. Ogni worker Dataflow ha comunque bisogno di un piccolo volume Persistent Disk da 25 GB per archiviare l'immagine macchina e i log temporanei.
Supporto e limitazioni
- Supporta le pipeline batch.
- Richiede l'SDK Apache Beam per Java 2.12.0 o versioni successive, l'SDK Apache Beam per Python 2.12.0 o versioni successive oppure l'SDK Apache Beam per Go.
- Utilizza Dataflow Shuffle. L'attivazione di FlexRS abilita automaticamente Dataflow Shuffle.
- Non supporta le GPU.
- Non supporta le prenotazioni di Compute Engine.
- I job FlexRS hanno un ritardo di pianificazione. Pertanto, FlexRS è più adatto ai carichi di lavoro non urgenti, come i job giornalieri o settimanali che possono essere completati entro un determinato intervallo di tempo.
Pianificazione posticipata
Quando invii un job FlexRS, il servizio Dataflow lo inserisce in una coda e lo invia per l'esecuzione entro sei ore dalla creazione del job. Dataflow trova il momento migliore per avviare il job all'interno di questa finestra temporale, in base alla capacità disponibile e ad altri fattori.
Quando invii un job FlexRS, il servizio Dataflow esegue i seguenti passaggi:
- Restituisce un ID job immediatamente dopo l'invio del job.
- Esegue un'esecuzione di convalida anticipata.
Utilizza il risultato della convalida anticipata per determinare il passaggio successivo.
- In caso di esito positivo, il job viene messo in coda in attesa dell'avvio ritardato.
- In tutti gli altri casi, il job non riesce e il servizio Dataflow segnala gli errori.
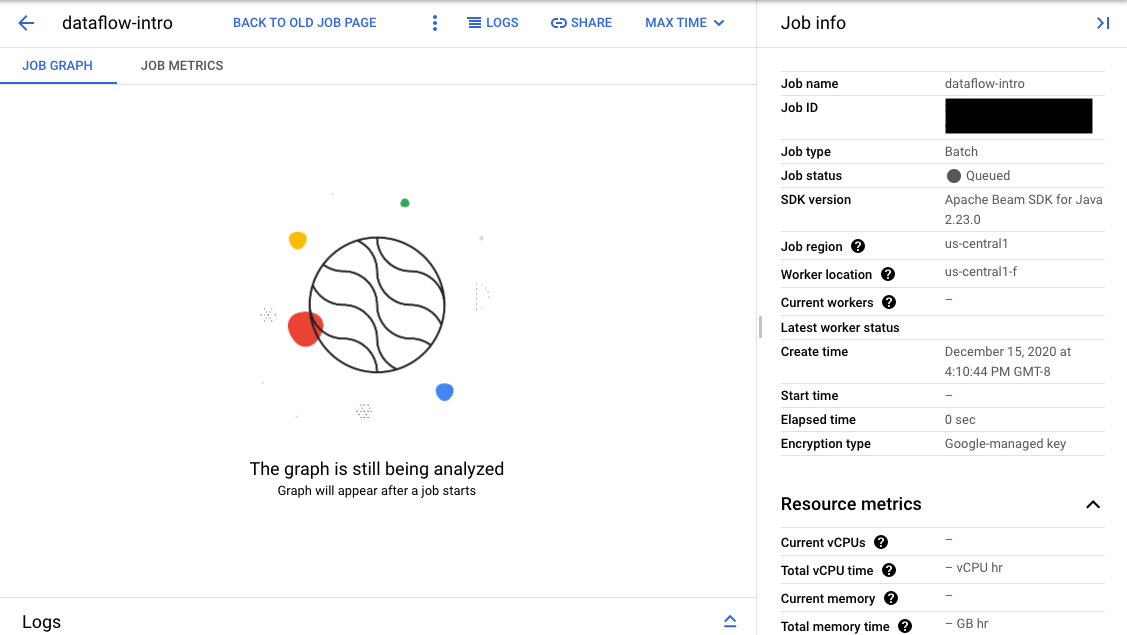
Se la convalida ha esito positivo, nell'interfaccia di monitoraggio di Dataflow, il job mostra un ID e lo stato
Queued. Se la convalida non va a buon fine, il job mostra lo stato Failed.
Convalida anticipata
I job FlexRS non vengono avviati immediatamente dopo l'invio. Durante la convalida iniziale, il servizio Dataflow verifica i parametri di esecuzione e le impostazioni dell'ambiente Google Cloud Platform, ad esempio ruoli IAM e configurazioni di rete. Dataflow convalida il job il più possibile al momento dell'invio del job e segnala i potenziali errori. Non ti viene addebitato alcun costo per questa procedura di convalida anticipata.
Il passaggio di convalida iniziale non esegue il codice utente. Devi verificare il codice per controllare la presenza di problemi utilizzando Direct Runner di Apache Beam o job non FlexRS. Se si verificano modifiche all'ambiente Google Cloud tra la creazione del job e la pianificazione posticipata del job, il job potrebbe essere eseguito correttamente durante la convalida iniziale, ma non al momento dell'avvio.
Abilita FlexRS
Quando crei un job FlexRS, viene utilizzata una quota di job simultanei, anche quando il job è nello stato In coda. La procedura di convalida anticipata non verifica né riserva altre quote. Pertanto, prima di attivare FlexRS, verifica di disporre di quote di risorse di progetto sufficienti per avviare il job. Google Cloud Ciò include una quota aggiuntiva per CPU preemptive, CPU regolari e indirizzi IP, a meno che tu non disattivi il parametro IP pubblico.
Se la quota non è sufficiente, il tuo account potrebbe non disporre di risorse sufficienti quando viene eseguito il deployment del job FlexRS. Per impostazione predefinita, Dataflow seleziona le VM prerilasciabili per il 90% dei worker nel pool di worker. Quando pianifichi la quota di CPU, assicurati di disporre di una quota di VM prerilasciabili sufficiente. Puoi richiedere esplicitamente VM prerilasciabile preemptible; in caso contrario, il tuo job FlexRS non avrà le risorse per essere eseguito in modo tempestivo.
Prezzi
I job FlexRS vengono fatturati per le seguenti risorse:
- CPU regolari e preemptible
- Risorse di memoria
- Risorse Dataflow Shuffle
- 25 GB per worker di risorse Persistent Disk
Quando Dataflow utilizza worker prerilasciabili e normali per eseguire il job FlexRS, ti viene addebitata una tariffa uniforme scontata rispetto ai normali prezzi di Dataflow, a prescindere dal tipo di worker. Le risorse Dataflow Shuffle e Persistent Disk non sono scontate.
Per ulteriori informazioni, consulta la pagina Dettagli dei prezzi di Dataflow.
Opzioni pipeline
Java
Per abilitare un job FlexRS, utilizza la seguente opzione della pipeline:
--flexRSGoal=COST_OPTIMIZED, dove l'obiettivo ottimizzato per i costi indica che il servizio Dataflow sceglie le risorse scontate disponibili.--flexRSGoal=SPEED_OPTIMIZED, dove viene ottimizzato per un tempo di esecuzione inferiore. Se non specificato, il campo--flexRSGoalviene impostato suSPEED_OPTIMIZEDper impostazione predefinita, il che equivale a omettere questo flag.
I job FlexRS influiscono sui seguenti parametri di esecuzione:
numWorkersimposta solo il numero iniziale di worker. Tuttavia, puoi impostaremaxNumWorkersper motivi di controllo dei costi.- Non puoi utilizzare l'opzione
autoscalingAlgorithmcon i job FlexRS. - Non puoi specificare il flag
zoneper i job FlexRS. Il servizio Dataflow seleziona la zona per tutti i job FlexRS nella regione specificata con il parametroregion. - Devi selezionare una
posizione del dataflow
come
region. - Non puoi utilizzare le serie di macchine M2, M3 o H3 per
workerMachineType.
Il seguente esempio mostra come aggiungere parametri ai parametri della pipeline standard per utilizzare FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Se ometti region, maxNumWorkers e workerMachineType, il servizio Dataflow determina il valore predefinito.
Python
Per abilitare un job FlexRS, utilizza la seguente opzione della pipeline:
--flexrs_goal=COST_OPTIMIZED, dove l'obiettivo ottimizzato per i costi indica che il servizio Dataflow sceglie le risorse scontate disponibili.--flexrs_goal=SPEED_OPTIMIZED, dove viene ottimizzato per un tempo di esecuzione inferiore. Se non specificato, il campo--flexrs_goalviene impostato suSPEED_OPTIMIZEDper impostazione predefinita, il che equivale a omettere questo flag.
I job FlexRS influiscono sui seguenti parametri di esecuzione:
num_workersimposta solo il numero iniziale di worker. Tuttavia, puoi impostaremax_num_workersper motivi di controllo dei costi.- Non puoi utilizzare l'opzione
autoscalingAlgorithmcon i job FlexRS. - Non puoi specificare il flag
zoneper i job FlexRS. Il servizio Dataflow seleziona la zona per tutti i job FlexRS nella regione specificata con il parametroregion. - Devi selezionare una
posizione del dataflow
come
region. - Non puoi utilizzare le serie di macchine M2, M3 o H3 per
machine_type.
Il seguente esempio mostra come aggiungere parametri ai parametri della pipeline standard per utilizzare FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se ometti region, max_num_workers e machine_type, il servizio Dataflow determina il valore predefinito.
Vai
Per abilitare un job FlexRS, utilizza la seguente opzione della pipeline:
--flexrs_goal=COST_OPTIMIZED, dove l'obiettivo ottimizzato per i costi indica che il servizio Dataflow sceglie le risorse scontate disponibili.--flexrs_goal=SPEED_OPTIMIZED, dove viene ottimizzato per un tempo di esecuzione inferiore. Se non specificato, il campo--flexrs_goalviene impostato suSPEED_OPTIMIZEDper impostazione predefinita, il che equivale a omettere questo flag.
I job FlexRS influiscono sui seguenti parametri di esecuzione:
num_workersimposta solo il numero iniziale di worker. Tuttavia, puoi impostaremax_num_workersper motivi di controllo dei costi.- Non puoi utilizzare l'opzione
autoscalingAlgorithmcon i job FlexRS. - Non puoi specificare il flag
zoneper i job FlexRS. Il servizio Dataflow seleziona la zona per tutti i job FlexRS nella regione specificata con il parametroregion. - Devi selezionare una
posizione del dataflow
come
region. - Non puoi utilizzare le serie di macchine M2, M3 o H3 per
worker_machine_type.
Il seguente esempio mostra come aggiungere parametri ai parametri della pipeline standard per utilizzare FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Se ometti region, max_num_workers e machine_type, il servizio Dataflow determina il valore predefinito.
Modelli Dataflow
Alcuni modelli Dataflow non supportano l'opzione della pipeline FlexRS. In alternativa, utilizza la seguente opzione della pipeline.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Monitora i job FlexRS
Puoi monitorare lo stato del job FlexRS nella console Google Cloud in due posizioni:
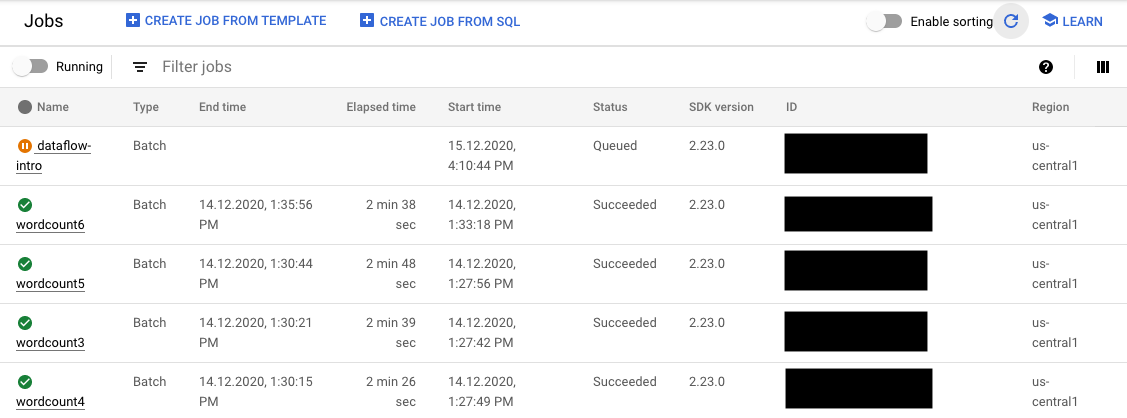
- La pagina Job che mostra tutti i tuoi job.
- La pagina Interfaccia di monitoraggio del job che hai inviato.
Nella pagina Job, i job non avviati mostrano lo stato In coda.
Nella pagina Interfaccia di monitoraggio, i job in attesa nella coda mostrano il messaggio "Il grafico verrà visualizzato dopo l'avvio di un job" nella scheda Grafico del job.