This page explains how to enable Flexible Resource Scheduling (FlexRS) for autoscaled batch pipelines in Dataflow.
FlexRS reduces batch processing costs by using advanced scheduling techniques, the Dataflow Shuffle service, and a combination of preemptible virtual machine (VM) instances and regular VMs. By running preemptible VMs and regular VMs in parallel, Dataflow improves the user experience when Compute Engine stops preemptible VM instances during a system event. FlexRS helps to ensure that the pipeline continues to make progress and that you don't lose previous work when Compute Engine preempts your preemptible VMs.
Jobs with FlexRS use the service-based Dataflow Shuffle for joining and grouping. As a result, FlexRS jobs don't use Persistent Disk resources for storing temporary calculation results. Using Dataflow Shuffle allows FlexRS to handle the preemption of a worker VM better, because the Dataflow service doesn't have to redistribute data to the remaining workers. Each Dataflow worker still needs a small 25 GB Persistent Disk volume to store the machine image and temporary logs.
Support and limitations
- Supports batch pipelines.
- Requires the Apache Beam SDK for Java 2.12.0 or later, the Apache Beam SDK for Python 2.12.0 or later, or the Apache Beam SDK for Go.
- Uses Dataflow Shuffle. Turning on FlexRS automatically enables Dataflow Shuffle.
- Doesn't support GPUs.
- Doesn't support Compute Engine reservations.
- FlexRS jobs have a scheduling delay. Therefore, FlexRS is most suitable for workloads that are not time-critical, such as daily or weekly jobs that can complete within a certain time window.
Delayed scheduling
When you submit a FlexRS job, the Dataflow service places the job into a queue and submits it for execution within six hours of job creation. Dataflow finds the best time to start the job within that time window, based on the available capacity and other factors.
When you submit a FlexRS job, the Dataflow service executes the following steps:
- Returns a job ID immediately after job submission.
- Performs an early validation run.
Uses the early validation result to determine the next step.
- On success, queues the job to wait for the delay launch.
- In all other cases, the job fails and the Dataflow service reports the errors.
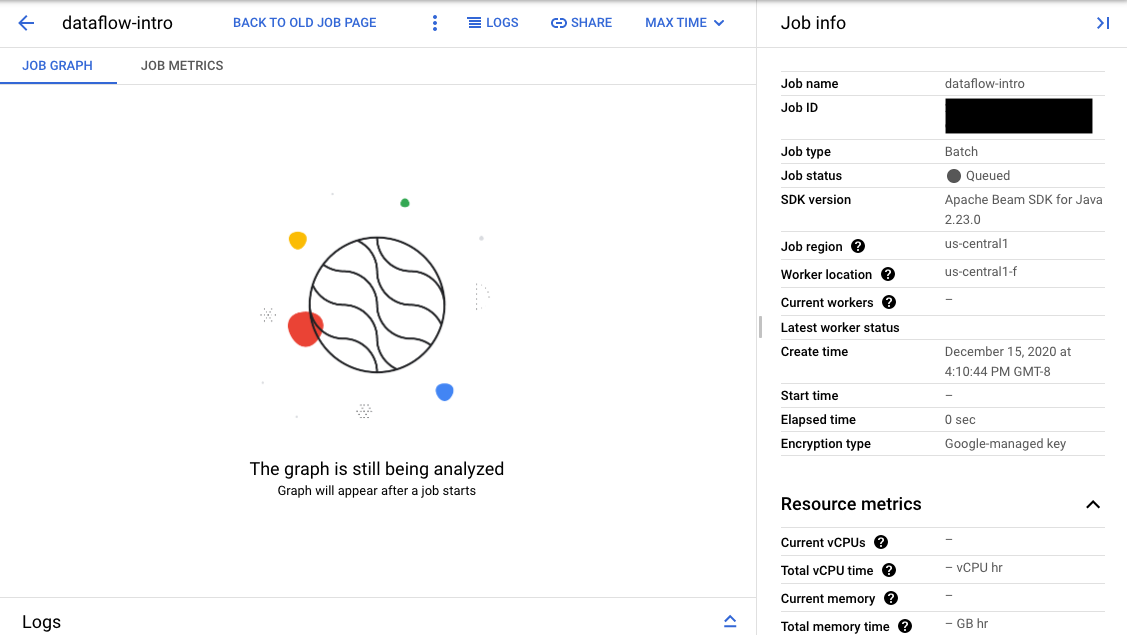
If validation succeeds, in the Dataflow
monitoring interface,
your job displays an ID and the
status
Queued. If validation fails, your job displays the status Failed.
Early validation
FlexRS jobs do not immediately launch upon submission. During early validation, the Dataflow service verifies the execution parameters and Google Cloud Platform environment settings, such as IAM roles and network configurations. Dataflow validates the job as much as possible at job submission time and reports potential errors. You are not billed for this early validation process.
The early validation step does not execute user code. You must verify your code to check for issues using the Apache Beam Direct Runner or non-FlexRS jobs. If there are Google Cloud environment changes between job creation and the job's delayed scheduling, the job might succeed during early validation but still fail at launch time.
Enable FlexRS
When you create a FlexRS job, a concurrent job quota is taken, even when the job is in the Queued status. The early validation process does not verify or reserve any other quotas. Therefore, before you enable FlexRS, verify that you have enough Google Cloud project resource quotas to launch your job. This includes additional quota for preemptible CPUs, regular CPUs, and IP addresses, unless you turn off the Public IP parameter.
If you do not have enough quota, your account might not have enough resources when your FlexRS job deploys. Dataflow selects preemptible VMs for 90% of workers in the worker pool by default. When planning for CPU quota, make sure that you have sufficient preemptible VM quota. You can explicitly request preemptible VM quota; otherwise, your FlexRS job will lack the resources to execute in a timely manner.
Pricing
FlexRS jobs are billed for the following resources:
- Regular and preemptible CPUs
- Memory resources
- Dataflow Shuffle resources
- 25 GB per worker of Persistent Disk resources
While Dataflow uses both preemptible and regular workers to execute your FlexRS job, you are billed a uniform discounted rate compared to regular Dataflow prices regardless of the worker type. Dataflow Shuffle and Persistent Disk resources are not discounted.
For more information, read the Dataflow pricing details page.
Pipeline options
To enable a FlexRS job, use the following pipeline option:
--flexRSGoal=COST_OPTIMIZED, where the cost-optimized goal means that the Dataflow service chooses any available discounted resources.--flexRSGoal=SPEED_OPTIMIZED, where it optimizes for lower execution time. If unspecified, the field--flexRSGoaldefaults toSPEED_OPTIMIZED, which is the same as omitting this flag.
FlexRS jobs affect the following execution parameters:
numWorkersonly sets the initial number of workers. However, you can setmaxNumWorkersfor cost control reasons.- You cannot use the
autoscalingAlgorithmoption with FlexRS jobs. - You cannot specify the
zoneflag for FlexRS jobs. The Dataflow service selects the zone for all FlexRS jobs in the region that you specified with theregionparameter. - You must select a
Dataflow location
as your
region. - You cannot use the M2, M3, or H3 machine series for your
workerMachineType.
The following example shows how to add parameters to your regular pipeline parameters in order to use FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
If you omit region, maxNumWorkers, and workerMachineType, the
Dataflow service determines the default value.
To enable a FlexRS job, use the following pipeline option:
--flexrs_goal=COST_OPTIMIZED, where the cost-optimized goal means that the Dataflow service chooses any available discounted resources.--flexrs_goal=SPEED_OPTIMIZED, where it optimizes for lower execution time. If unspecified, the field--flexrs_goaldefaults toSPEED_OPTIMIZED, which is the same as omitting this flag.
FlexRS jobs affect the following execution parameters:
num_workersonly sets the initial number of workers. However, you can setmax_num_workersfor cost control reasons.- You cannot use the
autoscalingAlgorithmoption with FlexRS jobs. - You cannot specify the
zoneflag for FlexRS jobs. The Dataflow service selects the zone for all FlexRS jobs in the region that you specified with theregionparameter. - You must select a
Dataflow location
as your
region. - You cannot use the M2, M3, or H3 machine series for your
machine_type.
The following example shows how to add parameters to your regular pipeline parameters in order to use FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
If you omit region, max_num_workers, and machine_type, the
Dataflow service determines the default value.
To enable a FlexRS job, use the following pipeline option:
--flexrs_goal=COST_OPTIMIZED, where the cost-optimized goal means that the Dataflow service chooses any available discounted resources.--flexrs_goal=SPEED_OPTIMIZED, where it optimizes for lower execution time. If unspecified, the field--flexrs_goaldefaults toSPEED_OPTIMIZED, which is the same as omitting this flag.
FlexRS jobs affect the following execution parameters:
num_workersonly sets the initial number of workers. However, you can setmax_num_workersfor cost control reasons.- You cannot use the
autoscalingAlgorithmoption with FlexRS jobs. - You cannot specify the
zoneflag for FlexRS jobs. The Dataflow service selects the zone for all FlexRS jobs in the region that you specified with theregionparameter. - You must select a
Dataflow location
as your
region. - You cannot use the M2, M3, or H3 machine series for your
worker_machine_type.
The following example shows how to add parameters to your regular pipeline parameters in order to use FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
If you omit region, max_num_workers, and machine_type, the
Dataflow service determines the default value.
Dataflow templates
Some Dataflow templates don't support the the FlexRS pipeline option. As an alternative, use the following pipeline option.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
Monitor FlexRS jobs
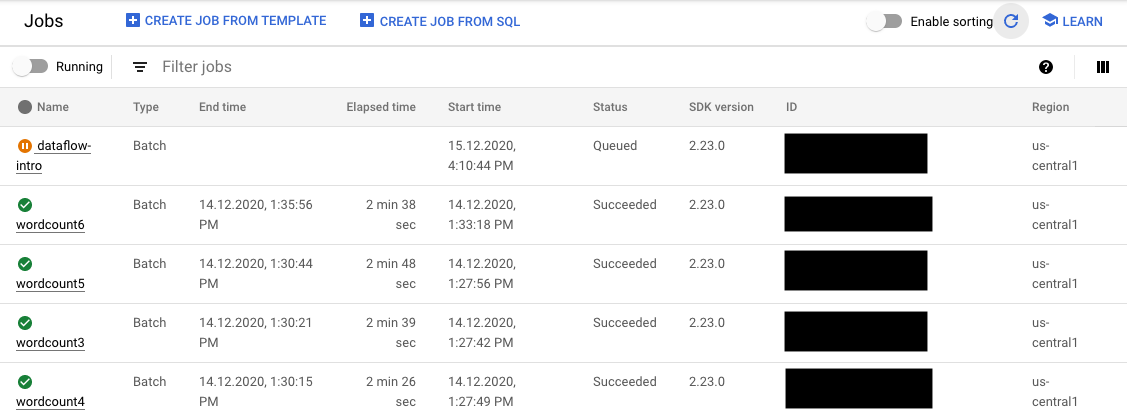
You can monitor the status of your FlexRS job on the Google Cloud console in two places:
- The Jobs page that shows all your jobs.
- The Monitoring interface page of the job you submitted.
On the Jobs page, jobs that have not started show the status Queued.
On the Monitoring interface page, jobs that are waiting in the queue display the message "Graph will appear after a job starts" in the Job graph tab.