Wenn bei Ihrer Dataflow-Pipeline oder Ihrem Dataflow-Job Probleme auftreten, werden auf dieser Seite möglicherweise Fehlermeldungen angezeigt und Vorschläge zur Behebung des jeweiligen Fehlers gegeben.
Fehler in den Logtypen dataflow.googleapis.com/worker-startup, dataflow.googleapis.com/harness-startup und dataflow.googleapis.com/kubelet weisen auf Konfigurationsprobleme mit einem Job hin. Sie können auch auf Bedingungen hindeuten, durch die verhindert wird, dass der normale Logging-Pfad funktioniert.
Die Pipeline kann während der Datenverarbeitung Ausnahmen ausgeben. Einige dieser Fehler sind temporär, beispielsweise wenn vorübergehende Probleme beim Zugriff auf einen externen Dienst auftreten. Einige dieser Fehler sind permanent, z. B. Fehler, die durch beschädigte oder nicht parsingfähige Eingabedaten verursacht werden, oder Nullzeiger während der Berechnung.
Dataflow verarbeitet Elemente in beliebigen Gruppierungen. Sollte für eines der Elemente in der Gruppierung ein Fehler ausgegeben werden, wird die gesamte Gruppierung noch einmal verarbeitet. Im Batchmodus wird die Verarbeitung von Gruppierungen mit einem fehlerhaften Element viermal wiederholt. Wenn eine Gruppierung viermal fehlschlägt, fällt die gesamte Pipeline aus. Im Streamingmodus wird die Verarbeitung einer Gruppierung mit einem fehlerhaften Element unendlich oft wiederholt. Dies kann zur permanenten Blockierung der Pipeline führen.
Ausnahmen im Nutzercode, zum Beispiel in Ihren DoFn-Instanzen, werden in der Monitoring-Oberfläche von Dataflow angezeigt.
Wenn Sie Ihre Pipeline mit BlockingDataflowPipelineRunner ausführen, werden auch Fehlermeldungen in der Konsole oder im Terminalfenster ausgegeben.
Fügen Sie Ihrem Code ggf. einen Ausnahme-Handler hinzu, um Fehler zu vermeiden. Wenn Sie beispielsweise Elemente auslassen möchten, die einige benutzerdefinierte Eingabevalidierungen in einem ParDo fehlschlagen lassen, verwenden Sie einen Try/Catch-Block in Ihrem ParDo für die Ausnahme und das Log und lassen Sie das Element weg. Implementieren Sie für Produktionsarbeitslasten ein unverarbeitetes Nachrichtenmuster. Verwenden Sie Aggregation-Transformationen, um die Fehlerzahl zu verfolgen.
Fehlende Logdateien
Wenn Sie keine Logs für Ihre Jobs sehen, entfernen Sie alle Ausschlussfilter, die resource.type="dataflow_step" enthalten, aus allen Ihren Cloud Logging-Log Router-Senken.
Weitere Informationen zum Entfernen von Logausschlüssen finden Sie im Leitfaden Ausschlüsse entfernen.
Duplikate in der Ausgabe
Wenn Sie einen Dataflow-Job ausführen, enthält die Ausgabe doppelte Datensätze.
Dieses Problem kann auftreten, wenn Ihr Dataflow-Job den Pipeline-Streamingmodus "Mindestens einmal" verwendet. Dieser Modus sorgt dafür, dass Datensätze mindestens einmal verarbeitet werden. In diesem Modus sind jedoch doppelte Einträge möglich.
Wenn Ihr Workflow keine doppelten Datensätze tolerieren kann, verwenden Sie den „Genau einmal“-Streamingmodus. In diesem Modus wird sichergestellt, dass Datensätze nicht gelöscht oder dupliziert werden, wenn die Daten durch die Pipeline geleitet werden.
Informationen zum Prüfen, welchen Streamingmodus Ihr Job verwendet, finden Sie unter Streamingmodus eines Jobs ansehen.
Weitere Informationen zu Streamingmodi finden Sie unter Pipeline-Streamingmodus festlegen.
Pipelinefehler
Die folgenden Abschnitte enthalten gängige Pipelinefehler und Schritte zum Beheben der Fehler.
Einige Cloud APIs müssen aktiviert werden
Wenn Sie versuchen, einen Dataflow-Job auszuführen, tritt der folgende Fehler auf:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Dieses Problem tritt auf, weil einige erforderliche APIs in Ihrem Projekt nicht aktiviert sind.
Um dieses Problem zu beheben und einen Dataflow-Job auszuführen, aktivieren Sie die folgendenGoogle Cloud APIs in Ihrem Projekt:
- Compute Engine API (Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
Eine ausführliche Anleitung finden Sie im Abschnitt „Erste Schritte“ zum Aktivieren von Google Cloud APIs.
"@*" und "@N" sind reservierte Fragmentierungsspezifikationen.
Wenn Sie versuchen, einen Job auszuführen, wird der folgende Fehler in den Logdateien angezeigt und der Job schlägt fehl:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Dieser Fehler tritt auf, wenn der Dateiname Ihres Cloud Storage-Pfads für temporäre Dateien (tempLocation oder temp_location) ein Vorzeichen (@) gefolgt von einer Zahl oder einem Sternchen (*) enthält.
Um dieses Problem zu beheben, ändern Sie den Dateinamen so, dass dem At-Zeichen ein unterstütztes Zeichen folgt.
Fehlerhafte Anfrage
Wenn Sie einen Dataflow-Job ausführen, wird in Cloud Monitoring-Logs eine Reihe von Warnungen angezeigt, die etwa so aussehen:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Warnungen zu ungültigen Anfragen treten auf, wenn die Informationen zum Worker-Status aufgrund von Verarbeitungsverzögerungen veraltet oder nicht synchron sind. Oft wird der Dataflow-Job trotz der Warnungen für fehlerhafte Anfragen erfolgreich ausgeführt. Ignorieren Sie in diesem Fall einfach die Warnungen.
Sie können nicht an verschiedenen Orten lesen und schreiben.
Wenn Sie einen Dataflow-Job ausführen, wird möglicherweise der folgende Fehler in den Logdateien angezeigt:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Dieser Fehler tritt auf, wenn sich die Quelle und das Ziel in verschiedenen Regionen befinden. Sie kann auch auftreten, wenn sich der Staging-Speicherort und das Ziel in verschiedenen Regionen befinden. Beispiel: Wenn der Job aus Pub/Sub liest und dann in einen Cloud Storage temp-Bucket schreibt, bevor er in eine BigQuery-Tabelle schreibt, müssen sich sowohl der Cloud Storage-temp-Bucket als auch die BigQuery-Tabelle in derselben Region befinden.
Standorte mit mehreren Regionen werden als andere Standorte betrachtet, auch wenn die einzelne Region in den Bereich des Standorts mit mehreren Regionen fällt.
Beispielsweise sind us (multiple regions in the United States) und us-central1 unterschiedliche Regionen.
Um dieses Problem zu beheben, müssen sich Ihre Ziel-, Quell- und Staging-Standorte in derselben Region befinden. Standorte von Cloud Storage-Buckets können nicht geändert werden. Daher müssen Sie möglicherweise einen neuen Cloud Storage-Bucket in der richtigen Region erstellen.
Zeitüberschreitung der Verbindung
Wenn Sie einen Dataflow-Job ausführen, wird möglicherweise der folgende Fehler in den Logdateien angezeigt:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Dieses Problem tritt auf, wenn die Dataflow-Worker keine Verbindung zur Datenquelle oder zum Ziel herstellen oder aufrechterhalten können.
Führen Sie die folgenden Schritte aus, um das Problem zu beheben:
- Prüfen Sie, ob die Datenquelle ausgeführt wird.
- Prüfen Sie, ob das Ziel ausgeführt wird.
- Prüfen Sie die Verbindungsparameter, die in der Dataflow-Pipelinekonfiguration verwendet werden.
- Prüfen Sie, ob Leistungsprobleme die Quelle oder das Ziel beeinträchtigen.
- Achten Sie darauf, dass die Verbindung nicht durch Firewallregeln blockiert wird.
Kein solches Objekt
Wenn Sie Ihre Dataflow-Jobs ausführen, wird möglicherweise der folgende Fehler in den Logdateien angezeigt:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Diese Fehler treten normalerweise auf, wenn einige Ihrer laufenden Dataflow-Jobs denselben temp_location zum Staging temporärer Jobdateien verwenden, die bei der Ausführung der Pipeline erstellt werden. Wenn mehrere gleichzeitige Jobs denselben temp_location verwenden, kann unter den Jobs ein Konflikt bezüglich der temporären Daten dieser Jobs entstehen und eine Race-Bedingung auftreten. Zur Vermeidung dieses Problems sollten Sie für jeden Job eine eindeutige temp_location verwenden.
Dataflow kann den Rückstand nicht ermitteln
Beim Ausführen einer Streamingpipeline in Pub/Sub tritt die folgende Warnung auf:
Dataflow is unable to determine the backlog for Pub/Sub subscription
Wenn eine Dataflow-Pipeline Daten aus Pub/Sub abruft, muss Dataflow wiederholt Informationen aus Pub/Sub anfordern. Diese Informationen umfassen den Umfang des Rückstands des Abos und das Alter der ältesten nicht bestätigten Nachricht. Gelegentlich kann Dataflow diese Informationen aufgrund interner Systemprobleme nicht aus Pub/Sub abrufen, was zu einer vorübergehenden Anhäufung von Backlog führen kann.
Weitere Informationen finden Sie unter Streaming mit Cloud Pub/Sub.
DEADLINE_EXCEEDED oder Server reagiert nicht
Beim Ausführen von Jobs können RPC-Zeitüberschreitungsausnahmen oder einer der folgenden Fehler auftreten:
DEADLINE_EXCEEDED
oder:
Server Unresponsive
Diese Fehler treten in der Regel aus einem der folgenden Gründe auf:
Im VPC-Netzwerk (Virtual Private Cloud), das für den Job genutzt wird, fehlt möglicherweise eine Firewallregel. Die Firewallregel muss den gesamten TCP-Traffic zwischen VMs in dem VPC-Netzwerk ermöglichen, das Sie in den Pipelineoptionen angegeben haben. Weitere Informationen finden Sie unter Firewallregeln für Dataflow.
In einigen Fällen können die Worker nicht miteinander kommunizieren. Wenn Sie einen Dataflow-Job ausführen, der weder Dataflow Shuffle noch Streaming Engine verwendet, müssen Worker über die TCP-Ports
12345und12346innerhalb des VPC-Netzwerk miteinander kommunizieren. In diesem Szenario enthält der Fehler den Namen des Worker-Harness und den blockierten TCP-Port. Der Fehler sieht in etwa aus wie eines der folgenden Beispiele:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Verwenden Sie zum Beheben dieses Problems das
gcloud compute firewall-rules create-Regeln-Flag, um den Netzwerktraffic an die Ports12345und12346zuzulassen. Im folgenden Beispiel wird der Google Cloud CLI-Befehl veranschaulicht:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Ersetzen Sie Folgendes:
FIREWALL_RULE_NAME: der Name der FirewallregelNETWORK: der Name Ihres Netzwerks
Ihr Job ist an das Zufallsprinzip gebunden.
Nehmen Sie eine oder mehrere der folgenden Änderungen vor, um dieses Problem zu beheben.
Java
- Wenn der Job nicht das dienstbasierte Shuffle verwendet, gehen Sie zur Verwendung des dienstbasierten Dataflow Shuffle über, indem Sie
--experiments=shuffle_mode=servicefestlegen. Weitere Informationen und die Verfügbarkeit finden Sie unter Dataflow Shuffle. - Fügen Sie weitere Worker hinzu. Legen Sie einen höheren Wert für
--numWorkersfest, wenn Sie die Pipeline ausführen. - Erhöhen Sie die Größe des angehängten Laufwerks für Worker. Legen Sie einen höheren Wert für
--diskSizeGbfest, wenn Sie die Pipeline ausführen. - Nutzen Sie einen SSD-gestützten nichtflüchtigen Speicher. Legen Sie
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"fest, wenn Sie die Pipeline ausführen.
Python
- Wenn der Job nicht das dienstbasierte Shuffle verwendet, gehen Sie zur Verwendung des dienstbasierten Dataflow Shuffle über, indem Sie
--experiments=shuffle_mode=servicefestlegen. Weitere Informationen und die Verfügbarkeit finden Sie unter Dataflow Shuffle. - Fügen Sie weitere Worker hinzu. Legen Sie einen höheren Wert für
--num_workersfest, wenn Sie die Pipeline ausführen. - Erhöhen Sie die Größe des angehängten Laufwerks für Worker. Legen Sie einen höheren Wert für
--disk_size_gbfest, wenn Sie die Pipeline ausführen. - Nutzen Sie einen SSD-gestützten nichtflüchtigen Speicher. Legen Sie
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"fest, wenn Sie die Pipeline ausführen.
Go
- Wenn der Job nicht das dienstbasierte Shuffle verwendet, gehen Sie zur Verwendung des dienstbasierten Dataflow Shuffle über, indem Sie
--experiments=shuffle_mode=servicefestlegen. Weitere Informationen und die Verfügbarkeit finden Sie unter Dataflow Shuffle. - Fügen Sie weitere Worker hinzu. Legen Sie einen höheren Wert für
--num_workersfest, wenn Sie die Pipeline ausführen. - Erhöhen Sie die Größe des angehängten Laufwerks für Worker. Legen Sie einen höheren Wert für
--disk_size_gbfest, wenn Sie die Pipeline ausführen. - Nutzen Sie einen SSD-gestützten nichtflüchtigen Speicher. Legen Sie
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"fest, wenn Sie die Pipeline ausführen.
- Wenn der Job nicht das dienstbasierte Shuffle verwendet, gehen Sie zur Verwendung des dienstbasierten Dataflow Shuffle über, indem Sie
Codierungsfehler, IOExceptions oder unerwartetes Verhalten im Nutzercode
Die Apache Beam SDKs und die Dataflow-Worker sind von gängigen Komponenten von Drittanbietern abhängig. Diese importieren zusätzliche Abhängigkeiten. Versionskollisionen können im Dienst zu unerwarteten Verhaltensweisen führen. Außerdem sind einige Bibliotheken nicht zukunftssicher. Möglicherweise müssen Sie die aufgelisteten Versionen verwenden, die bei der Ausführung aktuell sind. Unter SDK- und Worker-Abhängigkeiten finden Sie eine Liste der Abhängigkeiten und ihrer erforderlichen Versionen.
Fehler beim Ausführen von LookupEffectiveGuestPolicies
Wenn Sie einen Dataflow-Job ausführen, wird möglicherweise der folgende Fehler in den Logdateien angezeigt:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Dieser Fehler tritt auf, wenn OS Configuration Management für das gesamte Projekt aktiviert ist.
Deaktivieren Sie zur Behebung dieses Problems VM Manager-Richtlinien, die für das gesamte Projekt gelten. Wenn eine Deaktivierung der VM Manager-Richtlinien für das gesamte Projekt nicht möglich ist, können Sie diesen Fehler ignorieren und ihn aus Log-Monitoring-Tools herausfiltern.
Die Java-Laufzeitumgebung hat einen schwerwiegenden Fehler erkannt
Der folgende Fehler tritt beim Worker-Start auf:
A fatal error has been detected by the Java Runtime Environment
Dieser Fehler tritt auf, wenn die Pipeline Java Native Interface (JNI) verwendet, um Nicht-Java-Code auszuführen, und der Code oder die JNI-Bindungen enthalten einen Fehler.
Fehler bei googclient_deliveryattempt-Attributschlüssel
Ihr Dataflow-Job schlägt mit einem der folgenden Fehler fehl:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
oder:
Invalid extensions name: googclient_deliveryattempt
Dieser Fehler tritt auf, wenn Ihr Dataflow-Job die folgenden Merkmale aufweist:
- Für den Dataflow-Job wird Streaming Engine verwendet.
- Die Pipeline hat eine Pub/Sub-Senke.
- Die Pipeline verwendet ein Pull-Abo.
- Die Pipeline verwendet eine der Pub/Sub-Dienst-APIs, um Nachrichten zu veröffentlichen, anstatt die integrierte Pub/Sub-E/A-Senke zu verwenden.
- Pub/Sub verwendet die Java- oder C#-Clientbibliothek.
- Das Pub/Sub-Abo hat ein Thema für unzustellbare Nachrichten.
Dieser Fehler tritt auf, weil bei der Verwendung der Pub/Sub Java- oder C#-Clientbibliothek und der Aktivierung eines Themas für unzustellbare Nachrichten für ein Abo die Zustellversuche im Nachrichtenattribut googclient_deliveryattempt statt im Feld delivery_attempt stehen. Weitere Informationen finden Sie auf der Seite „Umgang mit Nachrichtenfehlern“ im Abschnitt Zustellversuche nachverfolgen.
Nehmen Sie eine oder mehrere der folgenden Änderungen vor, um dieses Problem zu umgehen.
- Streaming Engine deaktivieren
- Verwenden Sie den integrierten Apache Beam-Connector
PubSubIOanstelle der Pub/Sub-Dienst-API. - Verwenden Sie einen anderen Typ von Pub/Sub-Abo.
- Thema für unzustellbare Nachrichten entfernen
- Verwenden Sie die Java- oder C#-Clientbibliothek nicht mit Ihrem Pub/Sub-Pull-Abo. Weitere Optionen finden Sie unter Codebeispiele für Clientbibliotheken.
- Wenn Attributschlüssel in Ihrem Pipelinecode mit
googbeginnen, löschen Sie die Nachrichtenattribute, bevor Sie die Nachrichten veröffentlichen.
Ein "heißer" Schlüssel ... wurde erkannt
Folgender Fehler tritt auf:
A hot key HOT_KEY_NAME was detected in...
Diese Fehler treten auf, wenn die Daten einen "heißen" Schlüssel enthalten. Ein „heißer” Schlüssel ist ein Schlüssel mit so vielen Elementen, dass es sich negativ auf die Pipeline-Leistung auswirkt. Diese Schlüssel begrenzen die Möglichkeit von Dataflow, Elemente parallel zu verarbeiten, was die Ausführungszeit erhöht.
Mit der Option "Hot Key"-Pipeline können Sie den für Menschen lesbaren Schlüssel in den Logs ausgeben lassen, wenn ein "heißer" Schlüssel in der Pipeline erkannt wird.
Prüfen Sie zur Behebung dieses Problems, ob Ihre Daten gleichmäßig verteilt sind. Wenn ein Schlüssel unverhältnismäßig viele Werte enthält, sollten Sie die folgenden Vorgehensweisen berücksichtigen:
- Daten nochmal zur Verfügung stellen. Wenden Sie eine
ParDo-Transformation an, um neue Schlüsselwertpaare auszugeben. - Verwenden Sie für Java-Jobs die Transformation
Combine.PerKey.withHotKeyFanout. - Verwenden Sie für Python-Jobs die Transformation
CombinePerKey.with_hot_key_fanout. - Dataflow Shuffle aktivieren
Informationen zum Aufrufen von Hotkeys auf der Dataflow-Monitoring-Oberfläche finden Sie unter Fehlerbehebung bei Nachzüglern in Batchjobs.
Ungültige Tabellenspezifikation in Data Catalog
Wenn Sie Dataflow SQL zum Erstellen von Dataflow SQL-Jobs verwenden, schlägt der Job möglicherweise mit dem folgenden Fehler in den Logdateien fehl:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Dieser Fehler tritt auf, wenn das Dataflow-Dienstkonto keinen Zugriff auf die Data Catalog API hat.
Zur Behebung dieses Problems aktivieren Sie die Data Catalog API im Projekt Google Cloud, das Sie zum Schreiben und Ausführen von Abfragen verwenden.
Weisen Sie dem Dataflow-Dienstkonto die Rolle roles/datacatalog.viewer zu.
Die Jobgrafik ist zu groß.
Der Job kann mit dem folgenden Fehler fehlschlagen:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Dieser Fehler tritt auf, wenn die Grafikgröße Ihres Jobs 10 MB überschreitet. Bestimmte Bedingungen in der Pipeline können dazu führen, dass die Jobgrafik das Limit überschreitet. Zu den häufigsten Bedingungen zählen:
- Eine
Create-Transformation, die eine große Menge an im Speicher befindlichen Daten enthält - Eine große
DoFn-Instanz, die für die Übertragung an Remote-Worker serialisiert ist - Ein
DoFnals anonyme innere Klasseninstanz, die (möglicherweise unbeabsichtigt) große Datenmengen zur Serialisierung abruft - Ein gerichteter azyklischer Graph (DAG) wird als Teil einer programmatischen Schleife verwendet, die eine große Liste auflistet.
Damit diese Bedingungen vermieden werden, sollten Sie Ihre Pipeline neu strukturieren.
Schlüssel-Commit zu groß
Beim Ausführen eines Streamingjobs wird der folgende Fehler in den Worker-Logdateien angezeigt:
KeyCommitTooLargeException
Dieser Fehler tritt in Streamingszenarien auf, wenn eine sehr große Datenmenge ohne Combine-Transformation gruppiert wird oder wenn eine große Datenmenge aus einem einzelnen Eingabeelement erzeugt wird.
Verwenden Sie die folgenden Strategien, um die Wahrscheinlichkeit eines Auftretens dieses Fehlers zu reduzieren:
- Achten Sie darauf, dass die Verarbeitung eines einzelnen Elements nicht zu Ausgaben oder Zustandsänderungen führen kann, die den Grenzwert überschreiten.
- Wenn mehrere Elemente durch einen Schlüssel gruppiert wurden, können Sie den Schlüsselbereich erhöhen, um die pro Schlüssel gruppierten Elemente zu reduzieren.
- Wenn Elemente für einen Schlüssel innerhalb kurzer Zeit mit hoher Frequenz ausgegeben werden, können für diesen Schlüssel möglicherweise mehrere GB an Ereignissen verursacht werden. Schreiben Sie die Pipeline um, um Schlüssel wie diesen zu erkennen und nur eine Ausgabe auszugeben, die angibt, dass der Schlüssel in diesem Fenster häufig vorhanden war.
- Verwenden Sie sublineare Speicherplatz-
Combine-Transformationen für komplexe und verknüpfte Vorgänge. Verwenden Sie keinen Combiner, wenn der Speicherplatz nicht reduziert wird. So ist z. B. Combiner für Strings, der nur Strings aneinanderhängt, schlechter, als wenn Sie keinen Combiner verwenden.
Nachricht über 7.168 KB wird abgelehnt
Wenn Sie einen Dataflow-Job ausführen, der aus einer Vorlage erstellt wurde, schlägt der Job möglicherweise mit dem folgenden Fehler fehl:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Dieser Fehler tritt auf, wenn Nachrichten, die in eine Warteschlange für unzustellbare Nachrichten geschrieben wurden, die Größenbeschränkung von 7.168 KB überschreiten. Aktivieren Sie als Behelfslösung Streaming Engine, das ein höheres Größenlimit bietet. Um Streaming Engine zu aktivieren, verwenden Sie die folgende Pipelineoption.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large (Anfrageentität zu groß)
Wenn Sie Ihren Job senden, wird einer der folgenden Fehler in der Konsole oder im Terminalfenster angezeigt:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Wenn beim Einreichen eines Jobs ein Fehler bezüglich der JSON-Nutzlast auftritt, überschreitet die JSON-Darstellung der Pipeline die maximale Anfragegröße von 20 MB.
Die Größe Ihres Jobs ist mit der JSON-Darstellung der Pipeline verbunden. Eine größere Pipeline führt zu einer größeren Anfrage. Dataflow hat eine Begrenzung von 20 MB für Anfragen.
Führen Sie die Pipeline zum Schätzen der Größe der JSON-Anfrage mit der folgenden Option aus:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Die Ausgabe von Jobs als JSON wird in Go nicht unterstützt.
Mit diesem Befehl wird eine JSON-Darstellung des Jobs in eine Datei geschrieben. Die Größe der serialisierten Datei kann gut anhand der Größe der Anfrage geschätzt werden. Aufgrund von zusätzlichen Informationen in der Anfrage ist die tatsächliche Datei geringfügig größer.
Bestimmte Bedingungen in der Pipeline können bewirken, dass die JSON-Darstellung die Grenze überschreitet. Zu den häufigsten Bedingungen zählen:
- Eine
Create-Transformation, die eine große Menge an im Speicher befindlichen Daten enthält - Eine große
DoFn-Instanz, die für die Übertragung an Remote-Worker serialisiert ist - Ein
DoFnals anonyme innere Klasseninstanz, die (möglicherweise unbeabsichtigt) große Datenmengen zur Serialisierung abruft
Damit diese Bedingungen vermieden werden, sollten Sie Ihre Pipeline neu strukturieren.
SDK-Pipelineoptionen oder Staging-Dateiliste überschreiten die Größenbeschränkung.
Beim Ausführen einer Pipeline tritt einer der folgenden Fehler auf:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
oder:
Value for field 'resource.properties.metadata' is too large: maximum size
Diese Fehler treten auf, wenn die Pipeline nicht gestartet werden konnte, weil die Metadatenbeschränkungen von Compute Engine überschritten wurden. Diese Limits können nicht geändert werden. Dataflow verwendet Compute Engine-Metadaten für Pipelineoptionen. Das Limit ist in den Beschränkungen für benutzerdefinierte Metadaten in Compute Engine dokumentiert.
In den folgenden Szenarien kann die JSON-Darstellung das Limit überschreiten:
- Es gibt zu viele JAR-Dateien für das Staging.
- Das Anfragefeld
sdkPipelineOptionsist zu groß.
Führen Sie die Pipeline zum Schätzen der Größe der JSON-Anfrage mit der folgenden Option aus:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Die Ausgabe von Jobs als JSON wird in Go nicht unterstützt.
Die Größe der Ausgabedatei aus diesem Befehl muss kleiner als 256 KB sein. Die 512 KB in der Fehlermeldung beziehen sich auf die Gesamtgröße der Ausgabedatei und der benutzerdefinierten Metadatenoptionen für die Compute Engine-VM-Instanz.
Eine grobe Schätzung der benutzerdefinierten Metadatenoption für VM-Instanzen erhalten Sie, wenn Sie Dataflow-Jobs im Projekt ausführen. Wählen Sie einen beliebigen Dataflow-Job aus, der gerade ausgeführt wird. Wählen Sie eine VM-Instanz aus und rufen Sie dann die Detailseite der Compute Engine VM-Instanz auf, um den Abschnitt mit den benutzerdefinierten Metadaten zu prüfen. Die Gesamtlänge der benutzerdefinierten Metadaten und der Datei sollte weniger als 512 KB betragen. Eine genaue Schätzung für den fehlgeschlagenen Job ist nicht möglich, da die VMs nicht für fehlgeschlagene Jobs hochgefahren werden.
Wenn Ihre JAR-Liste die Grenze von 256 KB erreicht, prüfen Sie sie und reduzieren Sie alle nicht erforderlichen JAR-Dateien. Wenn sie danach immer noch zu groß ist, führen Sie den Dataflow-Job mit einer Uber-JAR-Datei aus. Ein Beispiel zum Erstellen und Verwenden von Uber-JAR-Dateien finden Sie unter Uber-JAR-Datei erstellen und bereitstellen.
Wenn das Anfragefeld sdkPipelineOptions zu groß ist, fügen Sie beim Ausführen der Pipeline die folgende Option ein. Die Pipelineoption ist für Java, Python und Go identisch.
--experiments=no_display_data_on_gce_metadata
Shuffle-Schlüssel ist zu groß
Der folgende Fehler wird in den Worker-Logdateien angezeigt:
Shuffle key too large
Dieser Fehler tritt auf, wenn der an einen bestimmten (Co-)GroupByKey ausgegebene serielle Schlüssel zu groß ist, nachdem der entsprechende Coder angewendet wurde. Dataflow hat ein Limit für serialisierte Shuffle-Schlüssel.
Zur Behebung dieses Problems reduzieren Sie die Größe der Schlüssel oder verwenden Sie platzsparendere Coder.
Weitere Informationen finden Sie unter Produktionslimits für Dataflow.
Gesamtzahl der BoundedSource-Objekte ist größer als die zulässige Grenze
Einer der folgenden Fehler kann auftreten, wenn Sie Jobs mit Java ausführen:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
oder:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Dieser Fehler kann auftreten, wenn Sie Daten aus einer sehr großen Anzahl von Dateien über TextIO, AvroIO, BigQueryIO über EXPORT oder eine andere dateibasierte Quelle auslesen. Das jeweilige Limit hängt von den Details der Quelle ab, liegt allerdings bei einer Größenordnung von Zehntausenden Dateien in einer Pipeline. Durch das Einbetten von Schemas in AvroIO.Read sind beispielsweise weniger Dateien möglich.
Dieser Fehler kann auch auftreten, wenn Sie eine benutzerdefinierte Datenquelle für Ihre Pipeline erstellt haben und die Methode splitIntoBundles Ihrer Quelle eine Liste von Objekten des Typs BoundedSource geliefert hat, die in serialisierter Form mehr als 20 MB beansprucht.
Das zulässige Limit für die Gesamtgröße der BoundedSource-Objekte, die vom splitIntoBundles()-Vorgang Ihrer benutzerdefinierten Quelle erzeugt wurden, ist 20 MB.
Um diese Einschränkung zu umgehen, haben Sie folgende Möglichkeiten:
Aktivieren Sie Runner V2. In Runner v2 werden Quellen in aufteilbare DoFn-Funktionen konvertiert, die dieses Limit für die Aufteilung von Quellen nicht haben.
Ändern Sie Ihre benutzerdefinierte abgeleitete
BoundedSource-Klasse so, dass die Gesamtgröße der generiertenBoundedSource-Objekte unter dem Limit von 20 MB liegt. Ihre Quelle könnte beispielsweise anfänglich weniger Aufteilungen erzeugen und auf den dynamischen Work-Ausgleich zurückgreifen, um weitere Eingaben nach Bedarf aufzuteilen.
NameError
Wenn Sie Ihre Pipeline mit dem Dataflow-Dienst ausführen, tritt der folgende Fehler auf:
NameError
Dieser Fehler tritt nicht auf, wenn der Befehl lokal ausgeführt wird, beispielsweise bei Verwendung von DirectRunner.
Dieser Fehler tritt auf, wenn Ihre DoFns Werte im globalen Namespace verwenden, die im Dataflow-Worker nicht verfügbar sind.
Standardmäßig werden globale Importe, Funktionen und Variablen, die in der Hauptsitzung definiert werden, während der Serialisierung eines Dataflow-Jobs nicht gespeichert.
Verwenden Sie eine der folgenden Methoden, um dieses Problem zu beheben. Wenn die DoFns in der Hauptdatei definiert sind und auf Importe und Funktionen im globalen Namespace verweisen, setzen Sie die Pipelineoption --save_main_session auf True. Mit dieser Änderung wird der Status des globalen Namespace mit der Pickle-Methode serialisiert und in den Dataflow-Worker geladen.
Wenn Objekte in Ihrem globalen Namespace vorhanden sind, für den die Pickle-Methode nicht verwendet werden kann, tritt ein Pickling-Fehler auf. Wenn sich der Fehler auf ein Modul bezieht, das in der Python-Verteilung verfügbar sein sollte, importieren Sie das Modul lokal, wo es verwendet wird.
Anstelle von:
import re … def myfunc(): # use re module
verwenden Sie zum Beispiel:
def myfunc(): import re # use re module
Wenn Ihre DoFn-Instanzen auf mehrere Dateien verteilt sind, gehen Sie bei der Paketerstellung für Ihren Workflow und bei der Verwaltung von Abhängigkeiten anders vor.
Das Objekt unterliegt der Aufbewahrungsrichtlinie des Buckets.
Wenn Sie einen Dataflow-Job haben, der in einen Cloud Storage-Bucket schreibt, schlägt der Job mit dem folgenden Fehler fehl:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
Möglicherweise wird auch der folgende Fehler angezeigt:
Unable to rename "gs://BUCKET"
Der erste Fehler tritt auf, wenn die Objektaufbewahrung für den Cloud Storage-Bucket aktiviert ist, in den der Dataflow-Job schreibt. Weitere Informationen finden Sie unter Konfigurationen für die Objektaufbewahrung aktivieren und verwenden.
Verwenden Sie eine der folgenden Behelfslösungen, um dieses Problem zu beheben.
Schreiben Sie in einen Cloud Storage-Bucket, der keine Aufbewahrungsrichtlinie für den
temp-Ordner hat.Entfernen Sie die Aufbewahrungsrichtlinie für den Bucket, in den der Job schreibt. Weitere Informationen finden Sie unter Aufbewahrungskonfiguration für ein Objekt festlegen.
Der zweite Fehler kann darauf hinweisen, dass die Objektaufbewahrung für den Cloud Storage-Bucket aktiviert ist, oder dass das Dataflow-Worker-Dienstkonto keine Berechtigung zum Schreiben in den Cloud Storage-Bucket hat.
Wenn Sie den zweiten Fehler sehen und die Objektaufbewahrung für den Cloud Storage-Bucket aktiviert ist, versuchen Sie es mit den oben beschriebenen Problemumgehungen. Wenn die Objektaufbewahrung für den Cloud Storage-Bucket nicht aktiviert ist, prüfen Sie, ob das Dataflow-Worker-Dienstkonto Schreibberechtigungen für den Cloud Storage-Bucket hat. Weitere Informationen finden Sie unter Auf Cloud Storage-Buckets zugreifen.
Verarbeitung hängt oder Vorgang wird weiter ausgeführt
Wenn Dataflow mehr Zeit für die Ausführung einer DoFn benötigt als in TIME_INTERVAL angegeben, ohne ein Ergebnis zu liefern, wird die folgende Meldung angezeigt.
Java
Je nach Version eine der beiden folgenden Logmeldungen:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Dieses Verhalten hat zwei mögliche Ursachen:
- Ihr
DoFn-Code ist langsam oder wartet auf den Abschluss eines langsamen externen Vorgangs. - Ihr
DoFn-Code ist möglicherweise hängen geblieben, blockiert oder ungewöhnlich lange mit der Verarbeitung beschäftigt.
Erweitern Sie den Logeintrag Cloud Monitoring, um festzustellen, in welchem Fall dies der Fall ist, um einen Stacktrace anzuzeigen. Suchen Sie nach Nachrichten, die darauf hinweisen, dass der DoFn-Code nicht funktioniert oder anderweitige Probleme damit aufgetreten sind. Wenn keine Nachrichten vorhanden sind, liegt das Problem möglicherweise an der Ausführungsgeschwindigkeit des DoFn-Codes. Sie können die Leistung des Codes mit Cloud Profiler oder einem anderen Tool untersuchen.
Wenn Ihre Pipeline auf der Java-VM erstellt wurde (entweder mit Java oder Scala), können Sie die Ursache Ihres hängen gebliebenen Codes untersuchen. Führen Sie dazu folgende Schritte aus, um einen vollständigen Thread-Dump der gesamten JVM (nicht nur des hängen gebliebenen Threads) zu erstellen:
- Notieren Sie sich den Worker-Namen aus dem Logeintrag.
- Suchen Sie im Compute Engine-Bereich der Google Cloud -Konsole nach der Compute Engine-Instanz mit dem notierten Worker-Namen.
- Stellen Sie eine SSH-Verbindung zu der Instanz mit diesem Namen her.
Führen Sie dazu diesen Befehl aus:
curl http://localhost:8081/threadz
Vorgang im Bundle läuft
Wenn Sie eine Pipeline ausführen, die Daten aus JdbcIO liest, sind die partitionierten Lesevorgänge aus JdbcIO langsam und die folgende Meldung wird in den Worker-Logdateien angezeigt:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
Nehmen Sie eine oder mehrere der folgenden Änderungen an Ihrer Pipeline vor, um dieses Problem zu beheben:
Verwenden Sie Partitionen, um die Parallelität des Jobs zu erhöhen. Lesen Sie mit mehr und kleineren Partitionen, um die Skalierung zu verbessern.
Prüfen Sie, ob die Partitionierungsspalte eine Indexspalte oder eine echte Partitionierungsspalte in der Quelle ist. Aktivieren Sie die Indexierung und Partitionierung für diese Spalte in der Quelldatenbank, um die beste Leistung zu erzielen.
Mit den Parametern
lowerBoundundupperBoundkönnen Sie das Suchen nach den Grenzen überspringen.
Fehler bei Pub/Sub-Kontingent
Beim Ausführen einer Streamingpipeline in Pub/Sub treten die folgenden Fehler auf:
429 (rateLimitExceeded)
oder:
Request was throttled due to user QPS limit being reached
Diese Fehler treten auf, wenn Ihr Projekt ein unzureichendes Pub/Sub-Kontingent hat.
So finden Sie heraus, ob Ihr Projekt über ein unzureichendes Kontingent verfügt: Gehen Sie folgendermaßen vor, um nach Client-Fehlern zu suchen:
- Rufen Sie die Google Cloud Console auf.
- Wählen Sie im Dreistrich-Menü auf der linken Seite APIs & Dienste aus.
- Suchen Sie im Suchfeld nach Cloud Pub/Sub.
- Klicken Sie auf den Tab Nutzung.
- Prüfen Sie die Antwortcodes und suchen Sie nach Clientfehlercodes vom Typ
(4xx).
Die Anfrage ist gemäß der Richtlinie der Organisation untersagt
Beim Ausführen einer Pipeline tritt der folgende Fehler auf:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Dieser Fehler tritt auf, wenn sich der Cloud Storage-Bucket außerhalb des Dienstperimeters befindet.
Um dieses Problem zu beheben, erstellen Sie eine Regel für ausgehenden Traffic, die den Zugriff auf den Bucket außerhalb des Dienstperimeters zulässt.
Bereitstellung des bereitgestellten Pakets ist nicht möglich
Jobs, die früher erfolgreich waren, können mit dem folgenden Fehler fehlschlagen:
Staged package...is inaccessible
So beheben Sie das Problem:
- Achten Sie darauf, dass der für das Staging verwendete Cloud Storage-Bucket keine TTL-Einstellungen enthält, die zum Löschen bereitgestellter Pakete führen.
Prüfen Sie, ob das Worker-Dienstkonto Ihres Dataflow-Projekts berechtigt ist, auf den für das Staging verwendeten Cloud Storage-Bucket zuzugreifen. Lücken in der Berechtigung können durch einen der folgenden Gründe bedingt sein:
- Der für das Staging verwendete Cloud Storage-Bucket ist in einem anderen Projekt vorhanden.
- Der für das Staging verwendete Cloud-Storage-Bucket wurde von detallierten Zugriffsberechtigungen zu einem einheitlichen Zugriff auf Bucket-Ebene migriert. Aufgrund der Inkonsistenzen zwischen IAM- und ACL-Richtlinien werden bei der Migration des Staging-Buckets auf einheitlichen Bucket-Level-Zugriff ACLs für Cloud-Storage-Ressourcen deaktiviert. ACLs umfassen die Berechtigungen des Worker-Dienstkontos Ihres Dataflow-Projekts für den Staging-Bucket.
Weitere Informationen finden Sie unter Auf Cloud Storage-Buckets in Google Cloud -Projekten zugreifen.
Eine Arbeitsaufgabe ist viermal fehlgeschlagen
Der folgende Fehler tritt auf, wenn ein Batchjob fehlschlägt:
The job failed because a work item has failed 4 times.
Dieser Fehler tritt auf, wenn ein einzelner Vorgang in einem Batchjob dazu führt, dass der Worker-Code viermal fehlschlägt. In Dataflow schlägt der Job fehl und diese Meldung wird angezeigt.
Im Streamingmodus wird die Verarbeitung einer Gruppierung mit einem fehlerhaften Element unendlich oft wiederholt. Dies kann zur permanenten Blockierung der Pipeline führen.
Sie können diesen Fehlerschwellenwert nicht konfigurieren. Weitere Informationen finden Sie unter Pipelinefehler- und Ausnahmebehandlung.
Suchen Sie in den Cloud Monitoring-Logs des Jobs nach den vier einzelnen Fehlern, um dieses Problem zu beheben. Suchen Sie in den Worker-Logs, in denen Ausnahmen oder Fehler aufgeführt sind, nach Logeinträgen der Stufe Fehler oder Schwerwiegend. Die Ausnahme oder der Fehler sollte mindestens viermal angezeigt werden. Wenn die Logs nur allgemeine Zeitüberschreitungsfehler im Zusammenhang mit dem Zugriff auf externe Ressourcen wie MongoDB enthalten, prüfen Sie, ob das Worker-Dienstkonto die Berechtigung hat, auf das Subnetzwerk der Ressource zuzugreifen.
Zeitüberschreitung in der Abfrageergebnisdatei
Ausführliche Informationen zur Fehlerbehebung bei einem Fehler vom Typ „Zeitüberschreitung beim Abrufen der Ergebnisdatei“ finden Sie unter Fehlerbehebung bei Flex-Vorlagen.
File/Write/WriteImpl/PreFinalize fehlgeschlagen
Wenn ein Job ausgeführt wird, schlägt der Job zeitweise fehl und der folgende Fehler tritt auf:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
Dieser Fehler tritt auf, wenn derselbe Unterordner als temporärer Speicherort für mehrere Jobs verwendet wird, die gleichzeitig ausgeführt werden.
Verwenden Sie zur Behebung dieses Problems nicht denselben Unterordner als temporären Speicherort für mehrere Pipelines. Geben Sie für jede Pipeline einen eindeutigen Unterordner an, der als temporärer Speicherort verwendet werden soll.
Element überschreitet die maximale protobuf-Nachrichtengröße
Wenn Sie Dataflow-Jobs ausführen und Ihre Pipeline große Elemente enthält, werden möglicherweise Fehler wie die folgenden Beispiele angezeigt:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
oder:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
Möglicherweise wird auch eine Warnung ähnlich der folgenden angezeigt:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
Diese Fehler treten auf, wenn Ihre Pipeline große Elemente enthält.
Wenn Sie das Python SDK verwenden, führen Sie ein Upgrade auf Apache Beam Version 2.57.0 oder höher durch, um dieses Problem zu beheben. Die Python SDK-Versionen 2.57.0 und höher verbessern die Verarbeitung großer Elemente und fügen relevantes Logging hinzu.
Wenn die Fehler nach dem Upgrade bestehen bleiben oder Sie das Python SDK nicht verwenden, identifizieren Sie den Schritt im Job, in dem der Fehler auftritt, und versuchen Sie, die Größe der Elemente in diesem Schritt zu reduzieren.
Wenn PCollection-Objekte in Ihrer Pipeline große Elemente enthalten, steigen die RAM-Anforderungen für die Pipeline.
Große Elemente können auch Laufzeitfehler verursachen, insbesondere wenn sie die Grenzen zusammengeführter Phasen überschreiten.
Große Elemente können auftreten, wenn eine Pipeline versehentlich eine große Iteration materialisiert. Beispielsweise werden für eine Pipeline, die die Ausgabe eines GroupByKey-Vorgangs an einen unnötigen Reshuffle-Vorgang übergibt, Listen als einzelne Elemente erstellt. Diese Listen enthalten möglicherweise eine große Anzahl von Werten für jeden Schlüssel.
Wenn der Fehler in einem Schritt auftritt, in dem eine Nebeneingabe verwendet wird, beachten Sie, dass die Verwendung von Nebeneingaben zu einer Fusionsbarriere führen kann. Prüfen Sie, ob die Transformation, die ein großes Element erzeugt, und die Transformation, die es verbraucht, zur selben Phase gehört.
Beachten Sie beim Erstellen Ihrer Pipeline die folgenden Best Practices:
- Verwenden Sie in
PCollectionsmehrere kleine Elemente anstelle eines einzelnen großen Elements. - Speichern Sie große Blobs in externen Speichersystemen. Entweder
PCollectionsverwenden, um ihre Metadaten zu übergeben, oder einen benutzerdefinierten Coder verwenden, mit dem die Größe des Elements reduziert wird. - Wenn Sie als Nebeneingabe eine PCollection übergeben müssen, die 2 GB überschreiten kann, verwenden Sie iterierbare Ansichten wie
AsIterableundAsMultiMap.
Die maximale Größe für ein einzelnes Element in einem Dataflow-Job ist auf 2 GB begrenzt. Weitere Informationen finden Sie unter Kontingente und Limits.
Dataflow kann verwaltete Transformation(en) nicht verarbeiten…
Pipelines, die Managed I/O verwenden, schlagen möglicherweise mit diesem Fehler fehl, wenn Dataflow die I/O-Transformationen nicht automatisch auf die neueste unterstützte Version aktualisieren kann. Die URN und die Schrittnamen im Fehler sollten angeben, welche Transformationen in Dataflow nicht aktualisiert werden konnten.
Möglicherweise finden Sie weitere Details zu diesem Fehler im Log-Explorer unter den Dataflow-Log-Namen managed-transforms-worker und managed-transforms-worker-startup.
Wenn der Log-Explorer nicht genügend Informationen zur Fehlerbehebung liefert, wenden Sie sich an Cloud Customer Care.
Fehler beim Archivieren von Jobs
Die folgenden Abschnitte enthalten häufige Fehler, die auftreten können, wenn Sie versuchen, einen Dataflow-Job mit der API zu archivieren.
Kein Wert angegeben
Wenn Sie versuchen, einen Dataflow-Job mit der API zu archivieren, tritt möglicherweise der folgende Fehler auf:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Dieser Fehler tritt aus einem der folgenden Gründe auf:
Der für das Feld
updateMaskangegebene Pfad ist nicht richtig formatiert. Dieses Problem kann durch Tippfehler verursacht werden.Der
JobMetadata-Parameter wurde nicht korrekt angegeben. Verwenden Sie im FeldJobMetadatafüruserDisplayPropertiesdas Schlüssel/Wert-Paar"archived":"true".
Prüfen Sie, ob der Befehl, den Sie an die API übergeben, dem erforderlichen Format entspricht, um diesen Fehler zu beheben. Weitere Informationen finden Sie unter Job archivieren.
Die API erkennt den Wert nicht
Wenn Sie versuchen, einen Dataflow-Job mit der API zu archivieren, tritt möglicherweise der folgende Fehler auf:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Dieser Fehler tritt auf, wenn der im Schlüssel-Wert-Paar für Archivierungsjobs angegebene Wert kein unterstützter Wert ist. Die unterstützten Werte für das Schlüssel/Wert-Paar für Archivierungsjobs sind "archived":"true" und "archived":"false".
Prüfen Sie, ob der Befehl, den Sie an die API übergeben, dem erforderlichen Format entspricht, um diesen Fehler zu beheben. Weitere Informationen finden Sie unter Job archivieren.
Status und Maske können nicht gleichzeitig aktualisiert werden
Wenn Sie versuchen, einen Dataflow-Job mit der API zu archivieren, tritt möglicherweise der folgende Fehler auf:
Cannot update both state and mask.
Dieser Fehler tritt auf, wenn Sie versuchen, sowohl den Jobstatus als auch den Archivstatus im selben API-Aufruf zu aktualisieren. Sie können nicht sowohl den Jobstatus als auch den Abfrageparameter updateMask im selben API-Aufruf aktualisieren.
Aktualisieren Sie den Jobstatus in einem separaten API-Aufruf, um diesen Fehler zu beheben. Aktualisieren Sie den Jobstatus, bevor Sie den Archivierungsstatus des Jobs aktualisieren.
Workflow konnte nicht geändert werden
Wenn Sie versuchen, einen Dataflow-Job mit der API zu archivieren, tritt möglicherweise der folgende Fehler auf:
Workflow modification failed.
Dieser Fehler tritt normalerweise auf, wenn Sie versuchen, einen laufenden Job zu archivieren.
Warten Sie, bis der Job abgeschlossen ist, bevor Sie ihn archivieren, um diesen Fehler zu beheben. Abgeschlossene Jobs haben einen der folgenden Jobstatus:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Weitere Informationen finden Sie unter Abschluss des Dataflow-Jobs.
Container-Image-Fehler
Die folgenden Abschnitte enthalten gängige Fehler, die bei der Verwendung von benutzerdefinierten Containern auftreten können, sowie Schritte zum Beheben der Fehler. Den Fehlern wird in der Regel die folgende Meldung vorangestellt:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Berechtigung "containeranalysis.occurrences.list" verweigert
Der folgende Fehler wird in Ihren Protokolldateien angezeigt:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
Die Container Analysis API ist für das Scannen auf Sicherheitslücken erforderlich.
Weitere Informationen finden Sie in der Dokumentation zur Artefaktanalyse unter Übersicht zum Betriebssystem-Scanning und Zugriffssteuerung konfigurieren.
Fehler beim Synchronisieren des Pods ... „StartContainer“ konnte nicht ausgeführt werden
Der folgende Fehler tritt beim Worker-Start auf:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Ein Pod ist eine gemeinsame Gruppe von Docker-Containern, die auf einem Dataflow-Worker ausgeführt werden. Dieser Fehler tritt auf, wenn einer der Docker-Container im Pod nicht gestartet werden kann. Wenn eine Wiederherstellung nicht möglich ist, kann der Dataflow-Worker nicht gestartet werden. Dies führt dazu, dass Dataflow-Batchjobs mit Fehlern wie diesen fehlschlagen:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Dieser Fehler tritt normalerweise auf, wenn einer der Container beim Start kontinuierlich abstürzt.
Um die Ursache zu ermitteln, suchen Sie nach den Logs, die unmittelbar vor dem Fehler erfasst wurden. Analysieren Sie die Logs mit dem Log-Explorer. Beschränken Sie im Log-Explorer die Logdateien auf Logeinträge, die vom Worker mit Container-Startfehlern ausgegeben werden. Führen Sie die folgenden Schritte aus, um die Logeinträge einzuschränken:
- Suchen Sie im Log-Explorer nach dem Logeintrag
Error syncing pod. - Erweitern Sie den Logeintrag, um die mit dem Logeintrag verknüpften Labels anzusehen.
- Klicken Sie auf das mit
resource_nameverknüpfte Label und dann auf Übereinstimmende Einträge aufrufen.
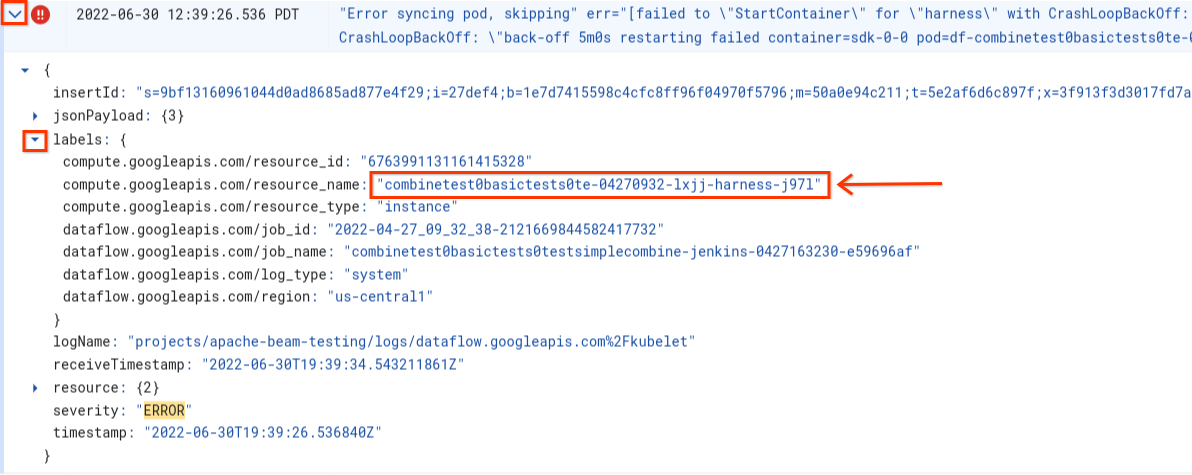
Im Log-Explorer sind die Dataflow-Logs in mehreren Log-Streams organisiert. Die Nachricht Error syncing pod wird im Log namens kubelet ausgegeben. Allerdings können sich die Logs des fehlerhaften Containers in einem anderen Log-Stream befinden. Jeder Container hat einen Namen. Anhand der folgenden Tabelle können Sie feststellen, welcher Log-Stream für den fehlerhaften Container relevante Logs enthalten kann.
| Containername | Lognamen |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 usw. | docker |
| harness | harness, harness-startup |
| python, java-batch, java-streaming | worker-startup, worker |
| artifact | artifact |
Wenn Sie den Log-Explorer abfragen, muss die Abfrage entweder die relevanten Lognamen in der Query Builder-Oberfläche enthalten oder keine Einschränkungen für den Lognamen enthalten.
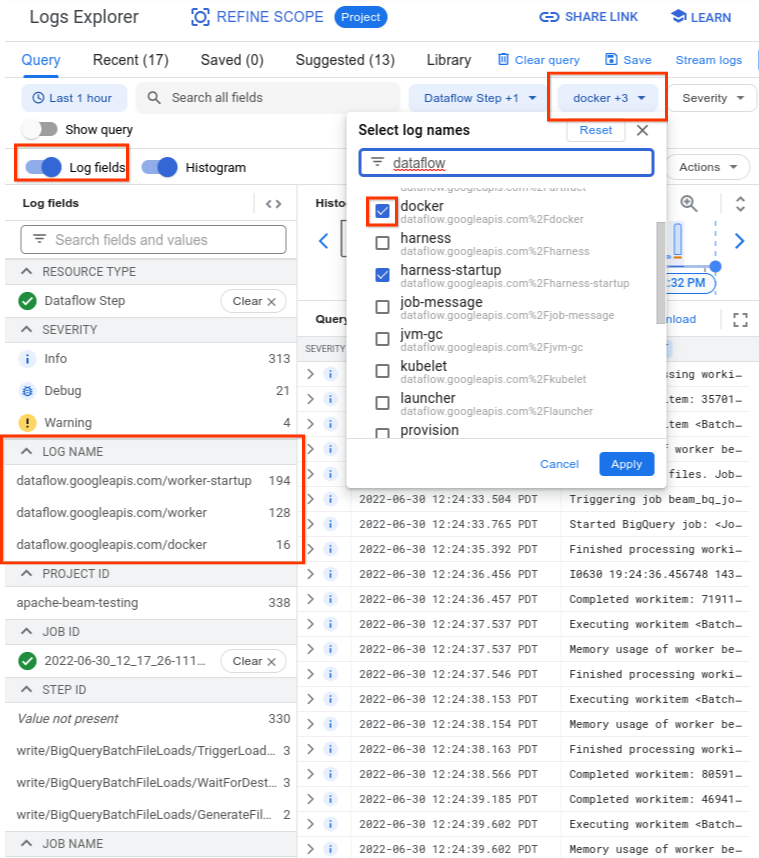
Nachdem Sie die relevanten Logs ausgewählt haben, sieht das Abfrageergebnis möglicherweise so aus:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Da die Logs, die das Symptom des Containerfehlers erfassen, manchmal als INFO erfasst werden, sollten Sie INFO-Logs in Ihre Analyse aufnehmen.
Typische Ursachen für Containerfehler sind:
- Ihre Python-Pipeline hat zusätzliche Abhängigkeiten, die zur Laufzeit installiert werden, und die Installation schlägt fehl. Möglicherweise werden Fehler wie
pip install failed with errorangezeigt. Dieses Problem kann aufgrund von in Konflikt stehenden Anforderungen oder einer eingeschränkten Netzwerkkonfiguration auftreten, die verhindert, dass ein Dataflow-Worker eine externe Abhängigkeit aus einem öffentlichen Repository über das Internet abruft. Ein Worker schlägt in der Mitte der Pipeline fehl, da ein Fehler aufgrund fehlenden Speichers erfolgt. Möglicherweise wird ein Fehler wie der folgende angezeigt:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Informationen zum Debugging bei Speicherproblemen finden Sie unter Fehlerbehebung bei Dataflow-Fehlern aufgrund von fehlerhaftem Arbeitsspeicher.
Dataflow kann das Container-Image nicht abrufen. Weitere Informationen finden Sie unter Image-Pull-Anfrage ist mit einem Fehler fehlgeschlagen.
Der verwendete Container ist nicht mit der CPU-Architektur der Worker-VM kompatibel. In den Protokollen zum Starten des Harness wird möglicherweise ein Fehler wie der folgende angezeigt:
exec /opt/apache/beam/boot: exec format error. Führen Siedocker image inspect $IMAGE:$TAGaus und suchen Sie nach dem SchlüsselwortArchitecture, um die Architektur des Containerbilds zu prüfen. WennError: No such image: $IMAGE:$TAGangezeigt wird, müssen Sie das Image möglicherweise zuerst mit dem Befehldocker pull $IMAGE:$TAGabrufen. Informationen zum Erstellen von Images mit mehreren Architekturen finden Sie unter Container-Image mit mehreren Architekturen erstellen.
Nachdem Sie den Fehler festgestellt haben, der zum Fehlschlagen des Containers geführt hat, versuchen Sie, den Fehler zu beheben, und senden Sie die Pipeline noch einmal.
Image-Pull-Anfrage ist mit einem Fehler fehlgeschlagen
Beim Worker-Start wird einer der folgenden Fehler in den Worker- oder Job-Logs angezeigt:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Diese Fehler treten auf, wenn ein Worker nicht gestartet werden kann, da er kein Docker-Container-Image abrufen kann. Dieses Problem tritt in den folgenden Szenarien auf:
- Die URL des benutzerdefinierten SDK-Container-Images ist falsch
- Der Worker hat keine Anmeldedaten oder keinen Netzwerkzugriff auf das Remote-Image
So beheben Sie das Problem:
- Wenn Sie ein benutzerdefiniertes Container-Image für Ihren Job verwenden, prüfen Sie, ob die Image-URL korrekt ist und ein gültiges Tag oder einen Digest enthält. Die Dataflow-Worker benötigen ebenfalls Zugriff auf das Image.
- Prüfen Sie, ob öffentliche Images lokal abgerufen werden können. Führen Sie dazu
docker pull $imageauf einem nicht authentifizierten Computer aus.
Für private Images oder private Worker:
- Wir empfehlen, das Container-Image statt mit Container Registry mit Artifact Registry zu hosten. Container Registry wurde zum 15. Mai 2023 verworfen. Falls Sie noch Container Registry verwenden, sollten Sie zu Artifact Registry wechseln. Wenn sich Ihre Bilder in einem anderen Projekt als dem befinden, mit dem Ihr Google Cloud -Job ausgeführt wird, konfigurieren Sie die Zugriffssteuerung für das Standarddienstkonto Google Cloud .
- Sorgen Sie bei Verwendung einer freigegebenen Virtual Private Cloud (VPC) dafür, dass die Worker auf den benutzerdefinierten Container-Repository-Host zugreifen können.
- Stellen Sie mit
ssheine Verbindung zu einer ausgeführten Job-Worker-VM her und führen Siedocker pull $imageaus, um zu prüfen, ob der Worker richtig konfiguriert ist.
Wenn Worker aufgrund eines Fehlers mehrmals hintereinander fehlschlagen und für einen Job keine Arbeit gestartet wurde, kann der Job mit einem Fehler ähnlich diesem fehlschlagen:
Job appears to be stuck.
Wenn Sie den Zugriff auf das Image entfernen, während der Job ausgeführt wird, entweder durch Entfernen des Images selbst oder durch Widerrufen der Anmeldedaten des Dataflow-Worker-Dienstkontos oder des Internetzugriffs auf Images, protokolliert Dataflow nur Fehler. Dataflow lässt den Job nicht fehlschlagen. Dataflow vermeidet außerdem lang andauernde Streaming-Pipelines, um einen Verlust des Pipelinestatus zu vermeiden.
Weitere mögliche Fehler können durch Kontingentprobleme oder Ausfälle des Repositorys verursacht werden. Wenn Probleme beim Überschreiten des Docker Hub-Kontingents zum Abrufen öffentlicher Images oder allgemeine Drittanbieter-Repository-Ausfälle auftreten, sollten Sie eventuell Artifact Registry als Image-Repository verwenden.
SystemError: unbekannter Opcode
Ihre benutzerdefinierte Python-Containerpipeline kann unmittelbar nach dem Senden des Jobs mit dem folgenden Fehler fehlschlagen:
SystemError: unknown opcode
Darüber hinaus kann der Stacktrace Folgendes enthalten:
apache_beam/internal/pickler.py
Achten Sie zur Behebung dieses Problems darauf, dass die verwendete Python-Version lokal mit der Version im Container-Image bis zur Haupt- und Nebenversion übereinstimmt. Ein Unterschied in der Patchversion, z. B. 3.6.7 im Vergleich zu 3.6.8, verursacht keine Kompatibilitätsprobleme. Der Unterschied in der Nebenversion, z. B. 3.6.8 im Vergleich zu 3.8.2, kann zu Pipelinefehlern führen.
Fehler bei der Aktualisierung von Streamingpipelines
Informationen zum Beheben von Fehlern beim Aktualisieren einer Streamingpipeline mit Funktionen wie dem Ausführen eines parallelen Ersetzungsjobs finden Sie unter Fehlerbehebung bei der Aktualisierung von Streamingpipelines.
Update des Runner v2-Harness
Die folgende Informationsmeldung wird in den Joblogs eines Runner v2-Jobs angezeigt:
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
Das bedeutet, dass die Version des Runner-Harness-Prozesses irgendwann 7 Tage nach der ersten Zustellung der Nachricht automatisch aktualisiert wird, was zu einer kurzen Verarbeitungspause führt. Wenn Sie steuern möchten, wann diese Pause eintritt, lesen Sie den Abschnitt Vorhandene Pipeline aktualisieren, um einen Ersatzjob zu starten, der die aktuelle Version des Runner-Harness enthält.
Worker-Fehler
Die folgenden Abschnitte enthalten häufig auftretende Worker-Fehler und Schritte zum Beheben der Fehler.
Der Aufruf vom Java-Worker-Harness an Python DoFn schlägt mit Fehler fehl
Wenn ein Aufruf vom Java-Worker-Harness an eine Python-DoFn fehlschlägt, wird eine entsprechende Fehlermeldung angezeigt.
Erweitern Sie den Cloud Monitoring-Fehlerlogeintrag und sehen Sie sich die Fehlermeldung und das Traceback an, um den Fehler zu untersuchen. Dort erfahren Sie, welcher Code fehlgeschlagen ist, sodass Sie ihn gegebenenfalls korrigieren können. Wenn Sie einen Programmfehler in Apache Beam oder Dataflow vermuten, melden Sie diesen Programmfehler.
EOFError: Marshal-Daten zu kurz
Der folgende Fehler wird in den Worker-Logs angezeigt:
EOFError: marshal data too short
Dieser Fehler tritt manchmal auf, wenn nicht genügend Speicherplatz auf den Python-Pipeline-Workern vorhanden ist.
Informationen zum Beheben dieses Problems finden Sie unter Kein Speicherplatz mehr auf dem Gerät.
Laufwerk konnte nicht angehängt werden
Wenn Sie versuchen, einen Dataflow-Job zu starten, der C3-VMs mit Persistent Disk verwendet, schlägt der Job mit einem oder beiden der folgenden Fehler fehl:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Diese Fehler treten auf, wenn Sie C3-VMs mit einem nicht unterstützten Persistent Disk-Typ verwenden. Weitere Informationen finden Sie unter Unterstützte Laufwerkstypen für C3.
Wenn Sie C3-VMs mit Ihrem Dataflow-Job verwenden möchten, wählen Sie den Worker-Festplattentyp pd-ssd aus. Weitere Informationen finden Sie unter Optionen auf Worker-Ebene.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
Kein Speicherplatz mehr auf dem Gerät
Wenn ein Job nicht mehr über genügend Speicherplatz verfügt, wird möglicherweise der folgende Fehler in den Worker-Logs angezeigt:
No space left on device
Dieser Fehler kann aus einem der folgenden Gründe auftreten:
- Der nichtflüchtige Speicher des Workers hat keinen freien Speicherplatz. Dafür kann es einen der folgenden Gründe geben:
- Ein Job lädt große Abhängigkeiten zur Laufzeit herunter
- Ein Job verwendet große benutzerdefinierte Container
- Ein Job schreibt viele temporäre Daten auf ein lokales Laufwerk.
- Wenn Sie Dataflow Shuffle verwenden, legt Dataflow eine niedrigere Standardlaufwerkgröße fest. Deshalb kann dieser Fehler bei Jobs auftreten, die von einem Worker-basierten Shuffle verschoben werden.
- Das Worker-Bootlaufwerk ist voll, da es mehr als 50 Einträge pro Sekunde loggt.
Führen Sie die folgenden Schritte aus, um das Problem zu beheben:
Wenn Sie Laufwerkressourcen aufrufen möchten, die einem einzelnen Worker zugeordnet sind, suchen Sie nach VM-Instanzdetails für Worker-VMs, die mit Ihrem Job verknüpft sind. Ein Teil des Speicherplatzes wird vom Betriebssystem, von Binärdateien, Logs und Containern belegt.
Wenn Sie den Speicherplatz für nichtflüchtige Speicher oder das Bootlaufwerk erhöhen möchten, passen Sie die Pipelineoption für die Laufwerkgröße an.
Verfolgen Sie mit Cloud Monitoring die Speicherplatznutzung auf den Worker-VM-Instanzen. Eine Anleitung zum Einrichten finden Sie unter Worker-VM-Messwerte vom Monitoring-Agent empfangen.
Suchen Sie nach Problemen mit dem Speicherplatz des Startlaufwerks. Rufen Sie dazu die Ausgabe des seriellen Ports auf den Worker-VM-Instanzen auf und suchen Sie nach Nachrichten wie:
Failed to open system journal: No space left on device
Wenn Sie viele Worker-VM-Instanzen haben, können Sie ein Script erstellen, um gcloud compute instances get-serial-port-output auf allen Instanzen gleichzeitig auszuführen.
Sie können sich stattdessen diese Ausgabe ansehen.
Python-Pipeline schlägt nach einer Stunde Inaktivität des Workers fehl
Wenn Sie das Apache Beam SDK für Python mit Dataflow Runner V2 auf Worker-Maschinen mit vielen CPU-Kernen verwenden, sollten Sie Apache Beam SDK 2.35.0 oder höher verwenden. Wenn Ihr Job einen benutzerdefinierten Container verwendet, müssen Sie das Apache Beam SDK in der Version 2.46.0 oder höher verwenden.
Erstellen Sie Ihren Python-Container vorab. Mit diesem Schritt können Sie die VM-Startzeiten und die horizontale Autoscaling-Leistung verbessern. Aktivieren Sie zum Nutzen dieses Features die Cloud Build API in Ihrem Projekt und reichen Sie die Pipeline mit dem folgenden Parameter ein:
‑‑prebuild_sdk_container_engine=cloud_build.
Weitere Informationen finden Sie unter Dataflow Runner V2.
Alternativ können Sie ein benutzerdefiniertes Container-Image verwenden, bei dem alle Abhängigkeiten vorinstalliert sind.
RESOURCE_POOL_EXHAUSTED
Wenn Sie eine Google Cloud -Ressource erstellen, tritt der folgende Fehler auf:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
Dieser Fehler tritt bei vorübergehenden Bedingungen für Zeitüberschreitungen für eine bestimmte Ressource in einer bestimmten Zone auf.
Um das Problem zu beheben, können Sie entweder warten oder dieselbe Ressource in einer anderen Zone erstellen.
Als Workaround können Sie eine Wiederholungsschleife für Ihre Jobs implementieren, sodass der Job bei einem Fehler aufgrund von Ressourcenmangel automatisch wiederholt wird, bis Ressourcen verfügbar sind. So erstellen Sie eine Wiederholungsschleife:
- Erstellen Sie einen Dataflow-Job und rufen Sie die Job-ID ab.
- Fragen Sie den Jobstatus ab, bis er
RUNNINGoderFAILEDist.- Wenn der Jobstatus
RUNNINGist, beenden Sie die Wiederholungsschleife. - Wenn der Jobstatus
FAILEDist, verwenden Sie die Cloud Logging API, um die Joblogs nach dem StringZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILSzu durchsuchen. Weitere Informationen finden Sie unter Mit Pipelinelogs arbeiten.- Wenn die Logs den String nicht enthalten, beenden Sie die Wiederholungsschleife.
- Wenn die Logs den String enthalten, erstellen Sie einen Dataflow-Job, rufen Sie die Job-ID ab und starten Sie die Wiederholungsschleife neu.
- Wenn der Jobstatus
Als Best Practice empfehlen wir, dass Sie Ihre Ressourcen auf mehrere Zonen und Regionen verteilen, um Ausfälle abzufangen.
Instanzen mit Gastbeschleunigern unterstützen keine Live-Migration
Eine Dataflow-Pipeline schlägt beim Senden des Jobs mit dem folgenden Fehler fehl:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
Dieser Fehler kann auftreten, wenn Sie einen Worker-Maschinentyp mit Hardwarebeschleunigern angefordert haben, Dataflow aber nicht für die Verwendung von Beschleunigern konfiguriert haben.
Verwenden Sie die --worker_accelerator Dataflow-Dienstoption oder den accelerator-Ressourcenhinweis, um Hardwarebeschleuniger anzufordern.
Wenn Sie flexible Vorlagen verwenden, können Sie mit der Option --additionalExperiments Dataflow-Dienstoptionen angeben. Wenn alles richtig gemacht wurde, ist die Option worker_accelerator im Job-Infofeld des Jobs in derGoogle Cloud -Konsole verfügbar.
Projektkontingent … oder Zugriffssteuerungsrichtlinien, die den Vorgang verhindern
Folgender Fehler tritt auf:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
Dieser Fehler tritt aus einem der folgenden Gründe auf:
- Sie haben eines der Compute Engine-Kontingente überschritten, auf das sich die Dataflow-Worker-Erstellung stützt.
- Ihre Organisation verfügt über Einschränkungen, die einen bestimmten Aspekt der VM-Instanzerstellung verbieten, z. B. das verwendete Konto oder die ausgewählte Zone.
Führen Sie die folgenden Schritte aus, um das Problem zu beheben:
Prüfen Sie das VM-Instanzlog
- Rufen Sie Cloud Logging Viewer auf.
- Wählen Sie in der Drop-down-Liste Geprüfte Ressource die Option VM-Instanz aus.
- Wählen Sie in der Drop-down-Liste Alle Logs die Option compute.googleapis.com/activity_log aus.
- Prüfen Sie das Log nach Einträgen im Zusammenhang mit dem Fehler bei der VM-Instanzerstellung.
Verwendung von Compute Engine-Kontingenten prüfen
Führen Sie den folgenden Befehl aus, um die Compute Engine-Ressourcennutzung im Vergleich zu Dataflow-Kontingenten für die ausgewählte Zone anzeigen zu lassen:
gcloud compute regions describe [REGION]Prüfen Sie die Ergebnisse für die folgenden Ressourcen, um festzustellen, ob sie das Kontingent überschreiten:
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
Einschränkungen der Organisationsrichtlinien prüfen
- Zur Seite „Organisationsrichtlinien“
- Prüfen Sie die Einschränkungen auf alle, die das Erstellen von VM-Instanzen entweder für das von Ihnen verwendete Konto (standardmäßig das Dataflow-Dienstkonto) oder für die ausgewählte Zone einschränken könnten.
- Wenn Sie eine Richtlinie haben, die die Verwendung externer IP-Adressen einschränkt, deaktivieren Sie externe IP-Adressen für diesen Job. Weitere Informationen zum Deaktivieren externer IP-Adressen finden Sie unter Internetzugriff und Firewallregeln konfigurieren.
Zeitüberschreitung beim Warten auf eine Aktualisierung durch den Worker
Wenn ein Dataflow-Job fehlschlägt, tritt der folgende Fehler auf:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Dieser Fehler kann verschiedene Ursachen haben, darunter:
Worker-Überlastung
Manchmal tritt ein Zeitüberschreitungsfehler auf, wenn dem Worker nicht mehr genügend Arbeitsspeicher oder der Auslagerungsspeicher zur Verfügung steht. Um dieses Problem zu beheben, führen Sie als Erstes den Job noch einmal aus. Wenn der Job weiterhin fehlschlägt und der gleiche Fehler auftritt, verwenden Sie einen Worker mit mehr Arbeitsspeicher und Speicherplatz. Fügen Sie beispielsweise die folgende Pipeline-Startoption hinzu:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
Eine Änderung des Worker-Typs kann sich auf die in Rechnung gestellten Kosten auswirken. Weitere Informationen finden Sie unter Fehlerbehebung bei Dataflow-Fehlern aufgrund von fehlerhaftem Arbeitsspeicher.
Dieser Fehler kann auch auftreten, wenn Ihre Daten einen heißen Schlüssel enthalten. In diesem Szenario ist die CPU-Auslastung bei einigen Workern während der meisten Dauer des Jobs hoch. Die Anzahl der Worker erreicht jedoch nicht das zulässige Maximum. Weitere Informationen zu "heißen" Schlüsseln und möglichen Lösungen finden Sie unter Dataflow-Pipelines unter Berücksichtigung der Skalierbarkeit schreiben.
Weitere Lösungen für dieses Problem finden Sie unter "Heißer" Schlüssel ... erkannt.
Python: Global Interpreter Lock (GIL)
Wenn Ihr Python-Code mithilfe des Python-Erweiterungsmechanismus C/C++-Code aufruft, prüfen Sie, ob der Erweiterungscode das Python Global Interpreter Lock (GIL) in rechenintensiven Codeteilen freigibt, die nicht auf den Python-Status zugreifen. Wenn der GIL über einen längeren Zeitraum nicht freigegeben wird, werden möglicherweise Fehlermeldungen wie Unable to retrieve status info from SDK harness <...> within allowed time und SDK worker appears to be permanently unresponsive. Aborting the SDK angezeigt.
Die Bibliotheken, die Interaktionen mit Erweiterungen wie Cython und PyBind erleichtern, haben Primitive, um den GIL-Status zu steuern. Sie können das GIL auch manuell freigeben und neu übernehmen, bevor Sie die Kontrolle an den Python-Interpreter zurückgeben, indem Sie die Makros Py_BEGIN_ALLOW_THREADS und Py_END_ALLOW_THREADS verwenden.
Weitere Informationen finden Sie in der Python-Dokumentation unter Thread-Status und Global Interpreter Lock.
So können Sie möglicherweise Stacktraces eines Threads abrufen, der den GIL auf einem laufenden Dataflow-Worker enthält:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
In Python-Pipelines geht Dataflow in der Standardkonfiguration davon aus, dass jeder auf den Workern ausgeführte Python-Prozess genau einen vCPU-Kern effizient verwendet. Wenn der Pipelinecode die Einschränkungen des GIL umgeht, z. B. mithilfe von Bibliotheken, die in C++ implementiert sind, können Verarbeitungselemente Ressourcen von mehr als einem vCPU-Kern verwenden und die Worker erhalten möglicherweise nicht genügend CPU-Ressourcen. Zur Umgehung dieses Problems reduzieren Sie die Anzahl der Threads auf den Workern.
Einrichtung von DoFn mit langer Ausführungszeit
Wenn Sie Runner v2 nicht verwenden, kann ein lang andauernder Aufruf von DoFn.Setup zu folgendem Fehler führen:
Timed out waiting for an update from the worker
Vermeiden Sie generell zeitaufwendige Vorgänge in DoFn.Setup.
Vorübergehende Fehler bei der Veröffentlichung zum Thema
Wenn Ihr Streamingjob den „Mindestens einmal“-Streamingmodus verwendet und in eine Pub/Sub-Senke veröffentlicht wird, wird der folgende Fehler in den Joblogs angezeigt:
There were transient errors publishing to topic
Wenn der Job ordnungsgemäß ausgeführt wird, ist dieser Fehler harmlos und kann ignoriert werden. Dataflow versucht automatisch, die Pub/Sub-Nachrichten mit einer Backoff-Verzögerung noch einmal zu senden.
Daten können aufgrund eines Token-Konflikts für den Schlüssel nicht abgerufen werden
Der folgende Fehler bedeutet, dass das zu verarbeitende Arbeitselement einem anderen Worker zugewiesen wurde:
Unable to fetch data due to token mismatch for key
Das passiert am häufigsten bei der automatischen Skalierung, kann aber jederzeit auftreten. Alle betroffenen Aufgaben werden wiederholt. Sie können diesen Fehler ignorieren.
Probleme mit Java-Abhängigkeiten
Inkompatible Klassen und Bibliotheken können Probleme mit Java-Abhängigkeiten verursachen. Wenn Ihre Pipeline Probleme mit der Java-Abhängigkeit hat, kann einer der folgenden Fehler auftreten:
NoClassDefFoundError: Dieser Fehler tritt auf, wenn eine gesamte Klasse zur Laufzeit nicht verfügbar ist. Die Ursache können entweder allgemeine Konfigurationsprobleme oder Inkompatibilitäten zwischen der Protobuf-Version von Beam und den generierten Protos eines Clients sein (z. B. dieses Problem).NoSuchMethodError: Dieser Fehler tritt auf, wenn die Klasse im Klassenpfad eine Version verwendet, die nicht die erforderliche Methode enthält, oder wenn sich die Methodensignatur geändert hat.NoSuchFieldError: Dieser Fehler tritt auf, wenn für die Klasse im Klassenpfad eine Version verwendet wird, der ein zur Laufzeit erforderliches Feld fehlt.FATAL ERROR in native method: Dieser Fehler tritt auf, wenn eine integrierte Abhängigkeit nicht richtig geladen werden kann. Wenn Sie Uber-JAR-Dateien (Shading) verwenden, nehmen Sie keine Bibliotheken auf, die Signaturen (z. B. Conscrypt) in derselben JAR-Datei verwenden.
Wenn Ihre Pipeline nutzerspezifischen Code und Einstellungen enthält, darf der Code keine gemischten Bibliotheksversionen enthalten. Wenn Sie eine Abhängigkeitsmanagement-Bibliothek verwenden, empfehlen wir die Verwendung der Google Cloud Libraries BOM.
Wenn Sie das Apache Beam SDK nutzen, verwenden Sie beam-sdks-java-io-google-cloud-platform-bom, um die richtige Libraries-BOM zu importieren:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Weitere Informationen finden Sie unter Pipelineabhängigkeiten in Dataflow verwalten.
InaccessibleObjectException in JDK 17 und höher
Wenn Sie Pipelines mit dem Java Platform Standard Edition Development Kit (JDK) in Version 17 und höher ausführen, wird möglicherweise der folgende Fehler in den Worker-Logdateien angezeigt:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Dieses Problem tritt auf, weil ab Java Version 9 Open Module Java Virtual Machine-Optionen (JVM) erforderlich sind, um auf JDK-Internals zuzugreifen. In Java 16 und höheren Versionen sind für den Zugriff auf JDK-Internals immer Open Module JVM-Optionen erforderlich.
Um dieses Problem zu beheben, verwenden Sie beim Übergeben von Modulen an Ihre Dataflow-Pipeline zum Öffnen das Format MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* mit der Pipelineoption jdkAddOpenModules. Dieses Format ermöglicht den Zugriff auf die erforderliche Bibliothek.
Wenn der Fehler beispielsweise module java.base does not "opens java.lang" to unnamed module @... ist, fügen Sie die folgende Pipelineoption hinzu, wenn Sie die Pipeline ausführen:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
Weitere Informationen finden Sie in der Dokumentation zur Klasse DataflowPipelineOptions.
Fehlerberichte zum Fortschritt von Arbeitsvorgängen
Wenn Sie Runner V2 nicht verwenden, wird für Java-Pipelines möglicherweise der folgende Fehler angezeigt:
Error reporting workitem progress update to Dataflow service: ...
Dieser Fehler wird durch eine unbehandelte Ausnahme während einer Aktualisierung des Fortschritts einer Arbeitsaufgabe verursacht, z. B. beim Aufteilen einer Quelle. Wenn im Apache Beam-Nutzercode eine unbehandelte Ausnahme ausgelöst wird, schlägt das Arbeitselement fehl, was dazu führt, dass die Pipeline fehlschlägt.Ausnahmen in Source.split werden jedoch unterdrückt, da dieser Teil des Codes außerhalb eines Arbeitselements liegt. Daher wird nur ein Fehlerlog aufgezeichnet.
Dieser Fehler ist in der Regel harmlos, wenn er nur gelegentlich auftritt. Es empfiehlt sich jedoch, Ausnahmen im Source.split-Code ordnungsgemäß zu behandeln.
BigQuery-Connector-Fehler
Die folgenden Abschnitte enthalten gängige BigQuery-Connector-Fehler und Schritte zum Beheben der Fehler.
quotaExceeded
Wenn Sie den BigQuery-Connector für das Schreiben in BigQuery mithilfe von Streaming-Insert-Anweisungen verwenden, ist der Schreibdurchsatz geringer als erwartet und der folgende Fehler kann auftreten:
quotaExceeded
Ein langsamer Durchsatz kann darauf zurückzuführen sein, dass Ihre Pipeline das verfügbare Kontingent für Streaming-Insert-Anweisungen in BigQuery überschreitet. In diesem Fall werden kontingentbezogene Fehlermeldungen von BigQuery in den Dataflow-Worker-Logs angezeigt (suchen Sie nach quotaExceeded-Fehlern).
Wenn Fehler vom Typ quotaExceeded angezeigt werden, beheben Sie dieses Problem:
- Legen Sie bei Verwendung des Apache Beam SDK für Java die BigQuery-Senkenoption
ignoreInsertIds()fest. - Verwenden Sie bei Verwendung des Apache Beam SDK für Python die Option
ignore_insert_ids.
Mit diesen Einstellungen haben Sie einen Durchsatz von Streaming-Insert-Anweisungen in BigQuery von 1 GB/s pro Projekt. Weitere Informationen zu Vorbehalten im Zusammenhang mit der automatischen Deduplizierung von Nachrichten finden Sie in der BigQuery-Dokumentation. Senden Sie eine Anfrage über die Google Cloud Console, um das BigQuery-Kontingent für Streaming-Insert-Anweisungen auf über 1 GBit/s zu erhöhen.
Wenn in Worker-Logs keine kontingentbezogenen Fehler angezeigt werden, besteht das Problem möglicherweise darin, dass Parameter für die Standardbündelung oder das Batching keine ausreichende Parallelität für die Skalierung Ihrer Pipeline bieten. Sie können mehrere Dataflow-BigQuery-Connector-bezogene Konfigurationen anpassen, um die erwartete Leistung zu erzielen, wenn Sie mithilfe von Streaming-Insert-Anweisungen in BigQuery schreiben. Passen Sie beispielsweise für Apache Beam SDK für Java numStreamingKeys an die maximale Anzahl von Workern an und erhöhen Sie insertBundleParallelism, um den BigQuery-Connector so zu konfigurieren, dass er mit mehr parallelen Threads in BigQuery schreibt.
Informationen zu Konfigurationen, die im Apache Beam SDK für Java verfügbar sind, finden Sie unter BigQueryPipelineOptions. Informationen zu Konfigurationen, die im Apache Beam SDK für Python verfügbar sind, finden Sie unter WriteToBigQuery-Transformation.
rateLimitExceeded
Bei Verwendung des BigQuery-Connectors tritt der folgende Fehler auf:
rateLimitExceeded
Dieser Fehler tritt auf, wenn BigQuery zu viele API-Anfragen innerhalb kurzer Zeit sendet. Für BigQuery gelten kurzfristige Kontingentlimits.
Es ist möglich, dass Ihre Dataflow-Pipeline ein solches Kontingent vorübergehend überschreitet. In einem solchen Fall können API-Anfragen von Ihrer Dataflow-Pipeline an BigQuery fehlschlagen, was zu rateLimitExceeded-Fehlern in den Worker-Logs führen kann.
Dataflow wiederholt solche Fehler, sodass Sie diese Fehler ignorieren können. Wenn Sie der Meinung sind, dass Ihre Pipeline von rateLimitExceeded-Fehlern betroffen ist, wenden Sie sich an den Cloud Customer Care.
Sonstige Fehler
Die folgenden Abschnitte enthalten verschiedene Fehler, die möglicherweise auftreten, und Schritte zur Lösung oder zur Suche nach Lösungen.
sha384 kann nicht zugewiesen werden
Der Job wird korrekt ausgeführt, aber in den Joblogs wird der folgende Fehler angezeigt:
ima: Can not allocate sha384 (reason: -2)
Wenn der Job ordnungsgemäß ausgeführt wird, ist dieser Fehler harmlos und kann ignoriert werden. Diese Meldung wird manchmal von den Basis-Images der Worker-VM ausgegeben. Dataflow reagiert automatisch auf das zugrunde liegende Problem und behebt es.
Es ist eine Funktionsanfrage vorhanden, um die Ebene dieser Nachricht von WARN in INFO zu ändern. Weitere Informationen finden Sie unter Logebene für Fehler beim Dataflow-System auf WARN oder INFO senken.
Fehler beim Initialisieren des dynamischen Plug-in-Probers
Der Job wird korrekt ausgeführt, aber in den Joblogs wird der folgende Fehler angezeigt:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Wenn der Job ordnungsgemäß ausgeführt wird, ist dieser Fehler harmlos und kann ignoriert werden. Dieser Fehler tritt auf, wenn der Dataflow-Job versucht, ein Verzeichnis ohne die erforderlichen Schreibberechtigungen zu erstellen, und die Aufgabe fehlschlägt. Wenn Ihr Job erfolgreich ist, war das Verzeichnis entweder nicht erforderlich oder Dataflow hat das zugrunde liegende Problem behoben.
Es ist eine Funktionsanfrage vorhanden, um die Ebene dieser Nachricht von WARN in INFO zu ändern. Weitere Informationen finden Sie unter Logebene für Fehler beim Dataflow-System auf WARN oder INFO senken.
Kein solches Objekt: pipeline.pb
Beim Auflisten von Jobs mit der Option JOB_VIEW_ALL tritt der folgende Fehler auf:
No such object: BUCKET_NAME/PATH/pipeline.pb
Dieser Fehler kann auftreten, wenn Sie die Datei pipeline.pb aus den Staging-Dateien für den Job löschen.
Pod-Synchronisierung überspringen
Der Job wird korrekt ausgeführt, aber in den Joblogs wird einer der folgenden Fehler angezeigt:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
oder:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Wenn der Job ordnungsgemäß ausgeführt wird, sind diese Fehler harmlos und können ignoriert werden.
Die Meldung container runtime status check may not have completed yet wird angezeigt, wenn das Kubernetes-Kubelet die Synchronisierung von Pods überspringt, weil es auf die Initialisierung der Containerlaufzeit wartet. Dieses Szenario kann aus verschiedenen Gründen auftreten, z. B. wenn die Container-Laufzeitumgebung vor Kurzem gestartet wurde oder neu gestartet wird.
Wenn die Meldung PLEG is not healthy: pleg has yet to be successful enthält, wartet das Kubelet darauf, dass der Pod-Lebenszyklus-Ereignisgenerator (PLEG) fehlerfrei ist, bevor es Pods synchronisiert. Der PLEG ist für das Generieren von Ereignissen verantwortlich, die vom Kubelet verwendet werden, um den Status von Pods zu verfolgen.
Es ist eine Funktionsanfrage vorhanden, um die Ebene dieser Nachricht von WARN in INFO zu ändern. Weitere Informationen finden Sie unter Logebene für Fehler beim Dataflow-System auf WARN oder INFO senken.
Empfehlungen
Eine Anleitung zu von Dataflow Insights generierten Empfehlungen finden Sie unter Insights.