Se você tiver problemas com o pipeline ou o job do Dataflow, esta página listará mensagens de erro que podem ser exibidas e fornecerá sugestões de como corrigir cada erro.
Erros nos tipos de registro dataflow.googleapis.com/worker-startup,
dataflow.googleapis.com/harness-startup e
dataflow.googleapis.com/kubelet indicam problemas de configuração com um job. Elas também podem indicar condições que impedem o funcionamento normal do caminho
de geração de registros.
O pipeline pode lançar exceções durante o processamento de dados. Alguns desses erros são transitórios, por exemplo, quando ocorre uma dificuldade temporária no acesso a um serviço externo. Alguns desses erros são permanentes, como erros causados por dados de entrada corrompidos ou impossíveis de analisar, ou ponteiros nulos durante a computação.
O Dataflow processa elementos em pacotes arbitrários e repete o pacote completo quando um erro é gerado para qualquer elemento nesse pacote. Na execução no modo em lote, os pacotes que incluem um item com falha são repetidos quatro vezes. A falha do pipeline ocorre completamente quando um único pacote falha quatro vezes. Em execuções no modo de streaming, um pacote incluindo um item com falha é repetido indefinidamente, o que pode causar a parada permanente do pipeline.
Exceções no código do usuário, como instâncias DoFn, são
relatadas na
Interface de monitoramento do Dataflow.
Ao executar o pipeline com BlockingDataflowPipelineRunner, você também verá
mensagens de erro impressas no console ou na janela de terminal.
Proteja o código contra erros adicionando gerenciadores de exceção. Por
exemplo, se você quiser descartar elementos que falham em alguma validação de entrada personalizada
feita em um ParDo, use um bloco try/catch dentro do ParDo para lidar com a
exceção e o registro. e solte o elemento. Para cargas de trabalho de produção, implemente um padrão de mensagem não processado. Para acompanhar a contagem de erros, use transformações de agregação.
Arquivos de registros ausentes
Se você não vir registros para seus jobs, remova todos os filtros de exclusão que contenham
resource.type="dataflow_step" de todos os coletores do
Roteador de registros do Cloud Logging.
Acessar o roteador de registros
Para mais detalhes sobre como remover suas exclusões de registros, consulte o guia Como remover exclusões.
Duplicações na saída
Quando você executa um job do Dataflow, a saída contém cópias registros.
Esse problema pode ocorrer quando o job do Dataflow usa o pipeline de modo de streaming pelo menos uma vez. Esse modo garante que os registros sejam processados pelo menos uma vez. No entanto, é possível gerar cópias de registros nesse modo.
Se o fluxo de trabalho não tolerar registros duplicados, use o método o modo de streaming. Esse modo ajuda a garantir que os registros não sejam descartados ou duplicados à medida que os dados se movem pelo pipeline.
Para verificar qual modo de streaming seu job está usando, consulte Veja o modo de streaming de um job.
Para mais informações sobre os modos de streaming, consulte Defina o modo de streaming do pipeline.
Erros do pipeline
As seções a seguir contêm erros de pipeline comuns que você pode encontrar e etapas para resolver ou solucionar os erros.
Algumas APIs do Cloud precisam ser ativadas
Quando você tenta executar um job do Dataflow, ocorre o seguinte erro:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Esse problema ocorre porque algumas APIs necessárias não estão ativadas no projeto.
Para resolver esse problema e executar um job do Dataflow, ative as seguintes APIsGoogle Cloud no seu projeto:
- API Compute Engine (Compute Engine)
- API Cloud Logging
- Cloud Storage
- API Cloud Storage JSON
- API BigQuery
- Pub/Sub
- API Datastore
Para instruções detalhadas, consulte a seção Primeiros passos com a ativação das APIs do Google Cloud .
"@*" e "@N" são especificações de fragmentação reservadas
Quando você tenta executar um job, o seguinte erro aparece nos arquivos de registro e o job falha:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Esse erro ocorrerá se o nome do arquivo do caminho do Cloud Storage para
arquivos temporários (tempLocation ou temp_location) tiver um sinal de arroba (@) seguido
por um número ou um asterisco (*).
Para resolver esse problema, altere o nome do arquivo a fim de que o sinal de arroba seja seguido por um caractere compatível.
Solicitação inválida
Ao executar um job do Dataflow, os registros do Cloud Monitoring exibem uma série de avisos semelhantes aos seguintes:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Os avisos de solicitação inválida ocorrem se as informações de estado do worker estiverem desatualizadas ou fora de sincronia devido a atrasos no processamento. Muitas vezes, seu job do Dataflow será bem-sucedido, apesar dos avisos de solicitações incorretas. Se esse for o caso, ignore-os.
Não é possível ler e gravar em locais diferentes
Ao executar um job do Dataflow, talvez você veja o seguinte erro nos arquivos de registro:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Esse erro ocorre quando a origem e o destino estão em regiões diferentes. Ele
também pode ocorrer quando o local e o destino de preparo estiverem em regiões
diferentes. Por exemplo, se o job lê no Pub/Sub e grava em um
bucket temp do Cloud Storage antes de gravar em uma tabela do BigQuery, o
bucket temp do Cloud Storage e a tabela do BigQuery precisam
estar na mesma região.
Os locais multirregionais são considerados diferentes dos locais regionais, mesmo que a única região esteja no escopo desse local multirregional.
Por exemplo, us (multiple regions in the United States) e us-central1 são
regiões diferentes.
Para resolver esse problema, coloque os locais de destino, origem e preparo na mesma região. Os locais dos buckets do Cloud Storage não podem ser alterados, então talvez seja necessário criar um novo bucket do Cloud Storage na região correta.
Tempo limite de conexão expirado
Ao executar um job do Dataflow, talvez você veja o seguinte erro nos arquivos de registro:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Esse problema ocorre quando os workers do Dataflow não conseguem estabelecer ou manter uma conexão com a origem ou o destino dos dados.
Para resolver o problema, siga estas etapas:
- Verifique se a fonte de dados está em execução.
- Verifique se o destino está em execução.
- Revise os parâmetros de conexão usados na configuração do pipeline do Dataflow.
- Verifique se os problemas de desempenho não estão afetando a origem ou o destino.
- Verifique se as regras de firewall não estão bloqueando a conexão.
Nenhum objeto desse tipo
Ao executar os jobs do Dataflow, você pode ver o seguinte erro nos arquivos de registros:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Esses erros geralmente ocorrem quando alguns dos jobs em execução do Dataflow
usam o mesmo temp_location para organizar arquivos de job temporários criados quando o
pipeline é executado. Quando vários jobs simultâneos compartilham o mesmo temp_location, eles podem usar os dados temporários uns dos outros, e uma disputa pode ocorrer. Para evitar esse problema, é recomendável usar um temp_location exclusivo para cada job.
O Dataflow não consegue determinar o backlog
Ao executar um pipeline de streaming do Pub/Sub, o seguinte aviso é exibido:
Dataflow is unable to determine the backlog for Pub/Sub subscription
Quando um pipeline do Dataflow extrai dados do Pub/Sub, o Dataflow precisa solicitar repetidamente informações do Pub/Sub. Essas informações incluem a quantidade de backlog na assinatura e a idade da mensagem mais antiga não confirmada. Às vezes, o Dataflow não consegue recuperar essas informações do Pub/Sub devido a problemas internos do sistema, o que pode causar um acúmulo temporário de backlog.
Para mais informações, consulte Como fazer streaming com o Cloud Pub/Sub.
DEADLINE_EXCEEDED ou servidor sem resposta
Ao executar os jobs, você pode encontrar exceções de tempo limite de RPC ou um dos seguintes erros:
DEADLINE_EXCEEDED
Ou:
Server Unresponsive
Esses erros geralmente ocorrem por um dos seguintes motivos:
A rede da nuvem privada virtual (VPC) usada no job pode estar sem uma regra de firewall. A regra de firewall precisa permitir todo o tráfego TCP entre as VMs na rede VPC que você especificou nas opções do pipeline. Para mais informações, consulte Regras de firewall para o Dataflow.
Em alguns casos, os workers não conseguem se comunicar entre si. Quando você executa um job do Dataflow que não usa o Dataflow Shuffle ou o Streaming Engine, os workers precisam se comunicar uns com os outros usando as portas TCP
12345e12346na rede VPC. Nesse cenário, o erro inclui o nome do arcabouço do worker e a porta TCP bloqueada. O erro se parece com um dos seguintes exemplos:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Para resolver esse problema, use a flag rules
gcloud compute firewall-rules createpara permitir o tráfego de rede para as portas12345e12346. O exemplo a seguir demonstra o comando da Google Cloud CLI:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Substitua:
FIREWALL_RULE_NAME: o nome da regra de firewallNETWORK: o nome da rede
O job está vinculado à reprodução aleatória.
Para resolver esse problema, faça uma ou mais das mudanças a seguir.
Java
- Se o job não estiver usando o Shuffle baseado em serviço, mude para o uso do
Dataflow Shuffle baseado em serviço definindo
--experiments=shuffle_mode=service. Para detalhes e disponibilidade, leia Dataflow Shuffle. - Adicione mais workers. Defina
--numWorkerscom um valor mais alto ao executar o pipeline. - Aumente o tamanho do disco anexado para os workers. Defina
--diskSizeGbcom um valor mais alto ao executar o pipeline. - Use um disco permanente com SSD. Defina
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"ao executar o pipeline.
Python
- Se o job não estiver usando o Shuffle baseado em serviço, mude para o uso do
Dataflow Shuffle baseado em serviço definindo
--experiments=shuffle_mode=service. Para detalhes e disponibilidade, leia Dataflow Shuffle. - Adicione mais workers. Defina
--num_workerscom um valor mais alto ao executar o pipeline. - Aumente o tamanho do disco anexado para os workers. Defina
--disk_size_gbcom um valor mais alto ao executar o pipeline. - Use um disco permanente com SSD. Defina
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"ao executar o pipeline.
Go
- Se o job não estiver usando o Shuffle baseado em serviço, mude para o uso do
Dataflow Shuffle baseado em serviço definindo
--experiments=shuffle_mode=service. Para detalhes e disponibilidade, leia Dataflow Shuffle. - Adicione mais workers. Defina
--num_workerscom um valor mais alto ao executar o pipeline. - Aumente o tamanho do disco anexado para os workers. Defina
--disk_size_gbcom um valor mais alto ao executar o pipeline. - Use um disco permanente com SSD. Defina
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"ao executar o pipeline.
- Se o job não estiver usando o Shuffle baseado em serviço, mude para o uso do
Dataflow Shuffle baseado em serviço definindo
Erros de codificação, IOExceptions ou comportamento inesperado no código do usuário.
Os SDKs do Apache Beam e os workers do Dataflow dependem de componentes comuns de terceiros. Esses componentes importam mais dependências. Os conflitos de versão podem resultar em um comportamento inesperado no serviço. Além disso, algumas bibliotecas não são compatíveis com versões futuras. Talvez seja necessário fixar nas versões listadas que estão no escopo durante a execução. As dependências do SDK e do worker contêm uma lista com as dependências e as respectivas versões necessárias.
Erro ao executar LookupEffectiveGuestPolicies
Ao executar um job do Dataflow, talvez você veja o seguinte erro nos arquivos de registro:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Esse erro ocorre se o gerenciamento da configuração do SO estiver ativado para todo o projeto.
Para resolver esse problema, desative as políticas do VM Manager que se aplicam a todo o projeto. Se não for possível desativar as políticas do VM Manager em todo o projeto, ignore esse erro e filtre-o das ferramentas de monitoramento de registros.
Um erro fatal foi detectado pelo Java Runtime Environment
O seguinte erro ocorre durante a inicialização do worker:
A fatal error has been detected by the Java Runtime Environment
Esse erro ocorrerá se o pipeline estiver usando a Java Native Interface (JNI) para executar código não Java e esse código ou as vinculações JNI contiverem um erro.
Erro na chave de atributo googclient_deliveryattempt
O job do Dataflow falha com um dos seguintes erros:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
Ou:
Invalid extensions name: googclient_deliveryattempt
Esse erro ocorre quando o job do Dataflow tem as seguintes características:
- O job do Dataflow usa o Streaming Engine.
- O pipeline tem um coletor do Pub/Sub.
- O pipeline usa uma assinatura de pull.
- O pipeline usa uma das APIs de serviço do Pub/Sub para publicar mensagens em vez de usar o coletor integrado de E/S do Pub/Sub.
- O Pub/Sub está usando a biblioteca de cliente em Java ou C#.
- A assinatura do Pub/Sub tem um tópico de mensagens inativas.
Esse erro ocorre porque, quando você usa a biblioteca de cliente do Pub/Sub em Java ou C# e um tópico de mensagens inativas para uma assinatura é ativado, as tentativas de entrega estão no atributo de mensagem googclient_deliveryattempt no lugar do campo delivery_attempt. Para mais informações, consulte Rastrear tentativas de entrega na página "Processar falhas nas mensagens".
Como solução alternativa para esse problema, faça uma ou mais de uma das mudanças a seguir.
- Desative o Streaming Engine.
- Use o conector
PubSubIOdo Apache Beam no lugar da API de serviço do Pub/Sub. - Use um tipo de assinatura do Pub/Sub diferente.
- Remova o tópico de mensagens inativas.
- Não use a biblioteca de cliente em Java ou C# com sua assinatura de pull do Pub/Sub. Para ver outras opções, consulte Exemplos de código da biblioteca de cliente.
- No código do pipeline, quando as chaves de atributos começarem com
goog, apague os atributos das mensagens antes de publicá-las.
Uma tecla de acesso rápido ... foi detectada
O seguinte erro ocorre:
A hot key HOT_KEY_NAME was detected in...
Esses erros ocorrerão se os dados contiverem uma chave quente. Uma chave com uso intenso é uma chave com elementos suficientes para afetar negativamente o desempenho do pipeline. Essas chaves limitam a capacidade do Dataflow de processar elementos em paralelo, o que aumenta o tempo de execução.
Para imprimir a chave legível para os registros quando uma chave quente é detectada no pipeline, use a opção de pipeline de chave quente.
Para resolver esse problema, verifique se seus dados estão distribuídos de maneira uniforme. Se uma chave tiver muitos valores de forma desproporcional, realize uma das ações a seguir:
- Faça o rechaveamento dos dados. Aplique uma
transformação
ParDopara gerar novos pares de chave-valor. - No caso de jobs em Java, use a transformação transformação
Combine.PerKey.withHotKeyFanout. - Para jobs em Python, use a transformação
CombinePerKey.with_hot_key_fanout. - Ative o Dataflow Shuffle.
Para ver as teclas de atalho na interface de monitoramento do Dataflow, consulte Resolver problemas de stragglers em jobs em lote.
Especificação de tabela inválida no Data Catalog
Problema: ao usar o Dataflow SQL para criar jobs do Dataflow SQL, seu job pode falhar com o seguinte erro nos arquivos de registros:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Esse erro ocorrerá se a conta de serviço do Dataflow não tiver acesso à API Data Catalog.
Para resolver esse problema, ative a API Data Catalog no Google Cloud projeto que você está usando para escrever e executar consultas.
Atribua o papel roles/datacatalog.viewer à
conta de serviço do Dataflow..
O gráfico do job é muito grande.
O job pode falhar com o seguinte erro:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Esse erro ocorrerá se o tamanho do gráfico do job exceder 10 MB. Determinadas condições no pipeline podem fazer com que o gráfico do job exceda o limite. As condições mais comuns são as seguintes:
- Uma transformação
Createque inclui uma grande quantidade de dados na memória. - Uma grande instância de
DoFnque é serializada para transmissão a workers remotos. - Uma
DoFncomo uma instância de classe interna anônima que, possivelmente de forma não intencional, extrai uma grande quantidade de dados para serem serializados. - Um gráfico acíclico direcionado (DAG, na sigla em inglês) está sendo usado como parte de um loop programático que enumera uma lista grande.
Para evitar essas condições, reestruture seu pipeline.
Confirmação de chave muito grande
Ao executar um job de streaming, o seguinte erro aparece nos arquivos de registros do worker:
KeyCommitTooLargeException
Esse erro ocorrerá em cenários de streaming se uma quantidade muito grande de dados for agrupada sem usar uma transformação Combine ou se uma grande quantidade de dados for produzida por um único elemento de entrada.
Para reduzir a possibilidade de encontrar esse erro, use as seguintes estratégias:
- Garante que o processamento de um único elemento não possa resultar em saídas ou modificações de estado acima do limite.
- Se vários elementos foram agrupados por uma chave, considere aumentar o espaço para reduzir os elementos agrupados por chave.
- Se os elementos de uma chave forem emitidos em uma frequência alta durante um curto período, isso pode resultar em muitos GB de eventos para essa chave nas janelas. Reescreva o pipeline para detectar chaves como essa e apenas emita uma saída indicando que a chave estava presente com frequência naquela janela.
- Use transformações de espaço sublinear
Combinepara operações comutativas e associadas. Não use um combinador se ele não reduzir o espaço. Por exemplo, usar um combinador para strings que apenas anexa strings é pior do que não usar o combinador.
Rejeitar mensagem maior que 7.168K
Quando você executa um job do Dataflow criado com base em um modelo, ele pode falhar com o seguinte erro:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Esse erro ocorre quando as mensagens gravadas em uma fila de mensagens inativas excedem o limite de tamanho de 7.168K. Como alternativa, ative o Streaming Engine, que tem um limite de tamanho maior. Para ativar o Streaming Engine, use a seguinte opção de pipeline.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large (Entidade de solicitação muito grande)
Ao enviar o job, um dos seguintes erros é exibido no console ou na janela de terminal:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Quando você encontra um erro sobre o payload JSON ao enviar o job, a representação JSON do pipeline excede o tamanho máximo de solicitação de 20 MB.
O tamanho do job está associado especificamente à representação JSON do pipeline. Um pipeline maior significa uma solicitação maior. A limitação do Dataflow restringe as solicitações a 20 MB.
Para estimar o tamanho da solicitação JSON do pipeline, execute-o com a seguinte opção:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
A saída do job como JSON não é compatível com o Go.
Esse comando grava uma representação JSON do job em um arquivo. O tamanho do arquivo serializado é uma boa estimativa do tamanho da solicitação. O tamanho real é um pouco maior devido a algumas informações adicionais incluídas na solicitação.
Certas condições no pipeline podem fazer com que a representação JSON exceda o limite. As condições mais comuns são as seguintes:
- Uma transformação
Createque inclui uma grande quantidade de dados na memória. - Uma grande instância de
DoFnque é serializada para transmissão a workers remotos. - Uma
DoFncomo uma instância de classe interna anônima que, possivelmente de forma não intencional, extrai uma grande quantidade de dados para serem serializados.
Para evitar essas condições, reestruture seu pipeline.
"As opções de pipeline do SDK ou a lista de arquivos de preparo excedem o limite de tamanho.
Ao executar um pipeline, um dos seguintes erros ocorre:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
Ou:
Value for field 'resource.properties.metadata' is too large: maximum size
Esses erros ocorrerão se o pipeline não puder ser iniciado porque os limites de metadados do Compute Engine foram excedidos. Não é possível alterar esses limites. O Dataflow usa os metadados do Compute Engine para as opções de pipeline. Esse limite está documentado nas limitações de metadados personalizados do Compute Engine.
Os cenários a seguir podem fazer com que a representação JSON exceda o limite:
- Há muitos arquivos JAR a serem preparados.
- O campo de solicitação
sdkPipelineOptionsé muito grande.
Para estimar o tamanho da solicitação JSON do pipeline, execute-o com a seguinte opção:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
A saída do job como JSON não é compatível com o Go.
O tamanho do arquivo de saída desse comando precisa ser menor que 256 KB. O tamanho de 512 KB na mensagem de erro refere-se ao tamanho total do arquivo de saída e às opções de metadados personalizados da instância de VM do Compute Engine.
É possível receber uma estimativa aproximada da opção de metadados personalizados da instância de VM a partir da execução de jobs do Dataflow no projeto. Escolha qualquer job do Dataflow em execução. Use uma instância de VM e navegue até a página de detalhes da instância de VM do Compute Engine para verificar a seção de metadados personalizados. O tamanho total dos metadados personalizados e o arquivo devem ser inferiores a 512 KB. Não é possível fazer uma estimativa precisa do job com falha, porque as VMs não são geradas para jobs com falha.
Se sua lista de JARs estiver atingindo o limite de 256 KB, revise-as e reduza os arquivos JAR desnecessários. Se ele ainda for muito grande, tente executar o job do Dataflow usando um JAR uber. Para conferir um exemplo que demonstra como criar e usar o uber JAR, consulte Criar e implantar um Uber JAR.
Se o campo de solicitação sdkPipelineOptions for muito grande, inclua a opção a seguir
ao executar o pipeline. A opção do pipeline é a mesma para Java, Python e Go.
--experiments=no_display_data_on_gce_metadata
Chave aleatória muito grande
O seguinte erro aparece nos arquivos de registros do worker:
Shuffle key too large
Esse erro ocorrerá se a chave serializada emitida para um determinado (Co-) Keras for muito grande após a aplicação do codificador correspondente. O Dataflow tem um limite de chaves de embaralhamento serializadas.
Para resolver esse problema, reduza o tamanho das chaves ou use programadores mais eficientes.
Para mais informações, consulte limites de produção do Dataflow.
O número total de objetos BoundedSource ... é maior que o limite permitido
Um dos seguintes erros pode ocorrer ao executar jobs com Java:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Ou:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Esse erro pode ocorrer durante a leitura de um número muito grande de arquivos via TextIO, AvroIO, BigQueryIO através de EXPORT ou alguma outra origem baseada em arquivo. O limite específico depende dos detalhes da origem, mas está na ordem de dezenas de milhares de arquivos em um pipeline. Por exemplo, a incorporação de esquema em AvroIO.Read permite menos arquivos.
Esse erro também pode ocorrer se você tiver criado uma origem de dados personalizada para o pipeline e o método splitIntoBundles da origem retornar uma lista de objetos BoundedSource que ocupam mais de 20 MB quando serializados.
O limite permitido para o tamanho total dos objetos BoundedSource gerados pela operação splitIntoBundles() da sua origem personalizada é de 20 MB.
Para contornar essa limitação, faça uma das seguintes alterações:
Ative o Runner V2. O Runner v2 converte origens em DoFns divisíveis que não têm esse limite de origem.
Modifique sua subclasse
BoundedSourcepersonalizada para que o tamanho total dos objetosBoundedSourcegerados seja menor que o limite de 20 MB. Por exemplo, a origem pode gerar menos divisões inicialmente e contar com o Reequilíbrio dinâmico de trabalho para dividir ainda mais entradas sob demanda.
NameError
Quando você executa o pipeline usando o serviço Dataflow, o seguinte erro ocorre:
NameError
Esse erro não ocorre quando você executa localmente, como quando usa DirectRunner.
Esse erro ocorrerá se os DoFns estiverem usando valores no namespace global que não estão disponíveis no worker do Dataflow.
Por padrão, importações, funções e variáveis globais definidas na sessão principal não são salvas durante a serialização de um job do Dataflow.
Para resolver esse problema, use um dos métodos a seguir. Se DoFns estiverem definidos no arquivo principal e nas importações e funções de referência no namespace global, defina a opção de pipeline --save_main_session como True. Essa mudança escolhe o estado do namespace global para
e carrega-o no worker do Dataflow.
Se houver objetos no namespace global que não podem ser preservados, ocorrerá um erro de pickling. Se o erro se referir a um módulo que deve estar disponível na distribuição do Python, importe o módulo localmente, onde ele é usado.
Por exemplo, em vez de:
import re … def myfunc(): # use re module
use:
def myfunc(): import re # use re module
Como alternativa, se os DoFns abrangerem vários arquivos,
use uma abordagem diferente para empacotar o fluxo de trabalho e
gerenciar dependências.
O objeto está sujeito à política de retenção do bucket
Quando você tem um job do Dataflow que grava em um bucket do Cloud Storage, ele falha com o seguinte erro:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
O seguinte erropode aparecer:
Unable to rename "gs://BUCKET"
O primeiro erro ocorre quando a retenção de objetos é ativada no Cloud Storage em que o job do Dataflow está gravando. Para mais informações, consulte Ativar e usar configurações de retenção de objetos.
Para resolver esse problema, use um dos métodos a seguir.
Grave em um bucket do Cloud Storage que não tenha uma política de retenção na pasta
temp.Remova a política de armazenamento do bucket em que o job é gravado. Para mais informações, consulte Definir a configuração de retenção de um objeto.
O segundo erro indica que a retenção de objetos está ativada no Cloud Storage ou indica que a conta de serviço do worker do Dataflow não tem permissão para gravar no bucket do Cloud Storage.
Se você vir o segundo erro e a retenção de objetos estiver ativada no bucket do Cloud Storage, tente as soluções alternativas descritas anteriormente. Se a retenção de objetos não estiver ativada no bucket do Cloud Storage, verifique se a conta de serviço do worker do Dataflow tem permissão de gravação no bucket do Cloud Storage. Para mais informações, consulte Acessar buckets do Cloud Storage.
Processamento travado ou operação em andamento
Se o Dataflow passar mais tempo executando um DoFn do que o tempo
especificado em TIME_INTERVAL sem retorno, essa mensagem será exibida.
Java
Uma das duas mensagens de registro a seguir, dependendo da versão:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Esse comportamento tem duas causas possíveis:
- O código
DoFné lento ou está aguardando que alguma operação externa lenta seja concluída. - Ou o código
DoFnpode estar travado, entrou em um impasse ou apresenta uma lentidão anormal para concluir o processamento.
Para determinar qual é o caso, expanda a entrada de registro do Cloud Monitoring para ver um rastreamento de pilha. Procure mensagens que indiquem que o código DoFn está
travado ou encontrando problemas. Se não houver mensagens, o problema pode ser a velocidade de execução do código DoFn. Considere usar o Cloud Profiler ou outra ferramenta para investigar o desempenho do seu código.
Se o canal for criado na VM do Java (usando Java ou Scala), será possível investigar a causa do código travado. Faça um despejo completo de linhas de execução de toda a JVM (não apenas a linha de execução travada) seguindo estas etapas:
- Anote o nome do worker na entrada de registro.
- Na seção Compute Engine do console Google Cloud , encontre a instância do Compute Engine com o nome do worker que você anotou.
- Use o SSH para se conectar à instância com esse nome.
Execute este comando:
curl http://localhost:8081/threadz
Operação em andamento no pacote
Ao executar um pipeline que lê de
JdbcIO,
as leituras particionadas de JdbcIO são lentas, e a seguinte mensagem aparece nos arquivos de registro do worker:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
Para resolver esse problema, faça uma ou mais das seguintes mudanças no pipeline:
Use partições para aumentar o paralelismo do job. Leia com mais partições menores para melhor escalonamento.
Verifique se a coluna de particionamento é uma coluna de índice ou uma coluna de particionamento real na origem. Ative a indexação e o particionamento nessa coluna no banco de dados de origem para ter o melhor desempenho.
Use os parâmetros
lowerBoundeupperBoundpara pular a descoberta dos limites.
Erros de cota do Pub/Sub
Ao executar um pipeline de streaming do Pub/Sub, ocorrem os seguintes erros:
429 (rateLimitExceeded)
Ou:
Request was throttled due to user QPS limit being reached
Esses erros ocorrerão se o projeto não tiver cota de Pub/Sub suficiente.
Para descobrir se o projeto tem cota insuficiente, siga estas etapas para verificar se há erros de cliente:
- Acesse o console doGoogle Cloud .
- No menu à esquerda, selecione APIs e serviços.
- Na caixa de pesquisa, consulte Cloud Pub/Sub.
- Clique na guia Uso.
- Verifique os Códigos de resposta e procure códigos de erro de cliente
(4xx).
A solicitação é proibida pela política da organização
Durante a execução de um pipeline, o seguinte erro ocorre:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Esse erro vai ocorrer se o bucket do Cloud Storage estiver fora do perímetro de serviço.
Para resolver esse problema, crie uma regra de saída que permita o acesso ao bucket fora do perímetro de serviço.
O pacote preparado...está inacessível
Os jobs usados anteriormente podem falhar com o seguinte erro:
Staged package...is inaccessible
Para solucionar esse problema:
- Verifique se o bucket do Cloud Storage usado na preparação não tem configurações de TTL que possam excluir os pacotes preparados.
Verifique se a conta de serviço do worker do projeto do Dataflow tem permissão para acessar o bucket do Cloud Storage usado para o preparo. As falhas na permissão podem ocorrer por qualquer um dos seguintes motivos:
- O bucket do Cloud Storage usado na preparação está presente em um projeto diferente.
- O bucket do Cloud Storage usado na preparação foi migrado do acesso refinado para o acesso uniforme no nível do bucket. Devido à inconsistência entre as políticas do IAM e da ACL, migrar o bucket de preparo para acesso uniforme no nível do bucket não permite ACLs para recursos do Cloud Storage. As ACLs incluem as permissões mantidas pela conta de serviço do worker do projeto do Dataflow sobre o bucket de preparo.
Para mais informações, consulte Como acessar buckets do Cloud Storage em projetos do Google Cloud .
Um item de trabalho falhou 4 vezes
O seguinte erro ocorre quando um job em lote falha:
The job failed because a work item has failed 4 times.
Este erro ocorre se uma única operação em um trabalho em lotes fizer com que o código de trabalho falhe quatro vezes. O Dataflow falha no job, e essa mensagem é exibida.
Em execuções no modo de streaming, um pacote incluindo um item com falha é repetido indefinidamente, o que pode causar a parada permanente do pipeline.
Não é possível configurar esse limite de falhas. Para mais detalhes, consulte como lidar com erros e exceções de pipeline.
Para resolver esse problema, procure nos registros do Cloud Monitoring do job as quatro falhas individuais. Nos registros de trabalho, procure entradas de registro de nível de erro ou de nível fatal que mostram exceções ou erros. A exceção ou o erro deve aparecer pelo menos quatro vezes. Se os registros tiverem apenas erros genéricos de tempo limite relacionados ao acesso a recursos externos, como o MongoDB, verifique se a conta de serviço do worker tem permissão para acessar a sub-rede do recurso.
Tempo limite no arquivo de resultado de enquete
Para informações completas sobre como resolver um erro de "Tempo limite no arquivo de resultado da pesquisa", consulte Resolver problemas de modelos flexíveis.
Falha ao gravar File/Write/WriteImpl/PreFinalize
Ao executar um job, ele falha intermitentemente e ocorre o seguinte erro:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
Esse erro ocorre quando a mesma subpasta é usada como o local de armazenamento temporário para vários jobs executados simultaneamente.
Para resolver esse problema, não use a mesma subpasta do armazenamento temporário local para vários pipelines. Para cada pipeline, forneça uma subpasta exclusiva para usar como o local de armazenamento temporário.
O elemento excede o tamanho máximo da mensagem protobuf
Quando você executa jobs do Dataflow e o pipeline tem elementos grandes, talvez você veja erros semelhantes aos seguintes exemplos:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
Ou:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
Talvez você também veja um aviso semelhante ao exemplo a seguir:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
Esses erros ocorrem quando o pipeline contém elementos grandes.
Para resolver esse problema, se você usa o SDK do Python, faça upgrade para o Apache Beam versão 2.57.0 ou mais recente. As versões 2.57.0 e posteriores do SDK para Python melhoram o processamento de elementos grandes e adicionam registros relevantes.
Se os erros persistirem após o upgrade ou se você não estiver usando o SDK do Python, identifique a etapa do job em que o erro acontece e tente reduzir o tamanho dos elementos nessa etapa.
Quando objetos PCollection no pipeline têm elementos grandes, os requisitos de RAM para o pipeline aumentam.
Elementos grandes também podem causar erros de tempo de execução,
principalmente quando cruzam os limites dessas fases.
Elementos grandes podem ocorrer quando um pipeline materializa acidentalmente um
iterável grande. Por exemplo, um pipeline que transmite a saída de
uma operação GroupByKey em uma operação Reshuffle desnecessária
materializa listas como elementos únicos. Essas listas podem conter
um grande número de valores para cada chave.
Se o erro ocorrer em uma etapa que usa uma entrada secundária, saiba que o uso de entradas secundárias podem introduzir uma barreira de fusão. Verifique se a transformação que produz um elemento grande e a que o consome pertencem ao mesmo estágio.
Ao criar o pipeline, siga estas práticas recomendadas:
- Em
PCollections, use vários elementos pequenos em vez de um único elemento grande. - Armazene blobs grandes em sistemas de armazenamento externos. Use
PCollectionspara transmitir metadados ou usar um codificador personalizado que reduza o tamanho do elemento. - Se você precisar transmitir uma PCollection que possa exceder 2 GB como uma entrada secundária, use visualizações iteráveis, como
AsIterableeAsMultiMap.
O tamanho máximo de um único elemento em um job do Dataflow é limitado a 2 GB. Para mais informações, consulte Cotas e limites.
O Dataflow não consegue processar transformações gerenciadas...
Os pipelines que usam E/S gerenciada podem falhar com esse erro se o Dataflow não conseguir atualizar automaticamente as transformações de E/S para a versão mais recente compatível. O URN e os nomes das etapas fornecidos no erro especificam quais transformações exatas o Dataflow não conseguiu atualizar.
Você pode encontrar mais detalhes sobre esse erro no Explorador de registros em nomes de registros do Dataflow managed-transforms-worker e managed-transforms-worker-startup.
Se a Análise de registros não fornecer informações adequadas para resolver o erro, entre em contato com o Cloud Customer Care.
Arquivar erros do job
As seções a seguir contêm erros comuns que podem ser encontrados ao tentar arquivar um job do Dataflow usando a API.
Nenhum valor é fornecido
Ao tentar arquivar um job do Dataflow usando a API, pode ocorrer o seguinte erro:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Esse erro ocorre por um dos seguintes motivos:
O caminho especificado para o campo
updateMasknão segue o formato correto. Esse problema pode ocorrer devido a erros de digitação.O
JobMetadatanão foi especificado corretamente. No campoJobMetadata, parauserDisplayProperties, use o par de chave-valor"archived":"true".
Para resolver esse erro, verifique se o comando transmitido para a API corresponde ao formato necessário. Para mais detalhes, consulte Arquivar um job.
A API não reconhece o valor
Ao tentar arquivar um job do Dataflow usando a API, pode ocorrer o seguinte erro:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Esse erro ocorre quando o valor fornecido no par de chave-valor de jobs de arquivamento não é compatível. Os valores aceitos para o par de chave-valor de jobs de arquivamento são
"archived":"true" e "archived":"false".
Para resolver esse erro, verifique se o comando transmitido para a API corresponde ao formato necessário. Para mais detalhes, consulte Arquivar um job.
Não é possível atualizar o estado e a máscara
Ao tentar arquivar um job do Dataflow usando a API, pode ocorrer o seguinte erro:
Cannot update both state and mask.
Esse erro ocorre quando você tenta atualizar o estado do job e o status do arquivo na mesma chamada de API. Não é possível fazer atualizações no estado do job e no parâmetro de consulta updateMask na mesma chamada de API.
Para resolver esse erro, atualize o estado do job em uma chamada de API separada. Faça atualizações no estado do job antes de atualizar o status do arquivo do job.
Falha na modificação do fluxo de trabalho
Ao tentar arquivar um job do Dataflow usando a API, pode ocorrer o seguinte erro:
Workflow modification failed.
Esse erro geralmente ocorre quando você tenta arquivar um job que está em execução.
Para resolver esse erro, aguarde a conclusão do job antes de arquivá-lo. Os jobs concluídos têm um dos seguintes estados de job:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Para mais informações, consulte Detectar a conclusão do job do Dataflow.
Erros na imagem do contêiner
As seções a seguir contêm erros comuns que podem ser encontrados ao usar contêineres personalizados e etapas para resolver ou resolver os erros. Os erros geralmente são prefixados com a seguinte mensagem:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Permissão "containeranalysis.occurrences.list" negada
O seguinte erro aparece nos arquivos de registro:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
a API Container Analysis é necessária para a verificação de vulnerabilidades.
Para mais informações, consulte Visão geral da verificação de SO e Como configurar o controle de acesso na documentação do Artifact Analysis.
Erro ao sincronizar o pod ... falha ao usar "StartContainer"
O seguinte erro ocorre durante a inicialização do worker:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Um pod é um grupo colocalizado de contêineres do Docker em execução em um worker do Dataflow. Esse erro ocorre quando um dos contêineres do Docker no pod falha ao iniciar. Se a falha não for recuperável, o worker do Dataflow não será iniciado e os jobs em lote do Dataflow falharão com erros como estes:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Esse erro geralmente ocorre quando um dos contêineres falha constantemente durante a inicialização.
Para entender a causa raiz, procure os registros capturados imediatamente antes da falha. Para analisar os registros, use o Explorador de registros. No Explorador de registros, limite os arquivos de registro às entradas de registro emitidas pelo worker com erros de inicialização do contêiner. Para limitar as entradas de registro, siga estas etapas:
- No Explorador de registros, localize a entrada de registro
Error syncing pod. - Para ver os marcadores associados à entrada de registro, expanda-a.
- Clique no marcador associado ao
resource_namee em Mostrar entradas correspondentes.
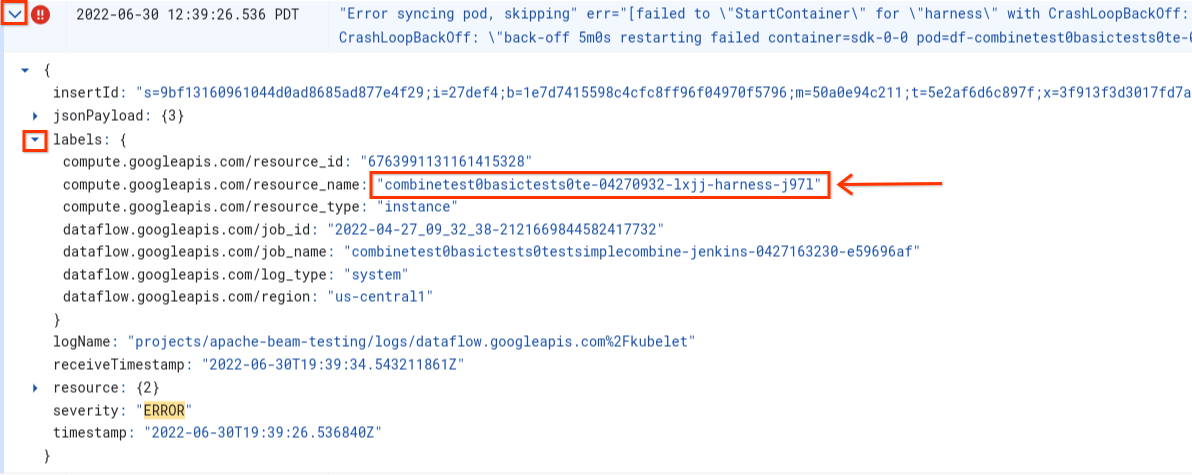
No Explorador de registros, os registros do Dataflow são organizados em vários fluxos. A mensagem Error syncing pod é emitida no registro chamado kubelet. No entanto,
os registros do contêiner com falha podem estar em um fluxo de registros diferente. Cada contêiner tem um nome. Use a tabela a seguir para determinar qual fluxo de registros pode conter registros relevantes para o contêiner com falha.
| Nome do contêiner | Nomes de registro |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 e similares | docker |
| cinto | arcabouço, inicialização do arcabouço |
| python, java-batch, java-streaming | worker-startup, worker |
| artifact | artifact |
Ao consultar o Explorador de registros, verifique se a consulta inclui os nomes de registro relevantes na IU do criador de consultas ou se não há restrições sobre o nome do registro.
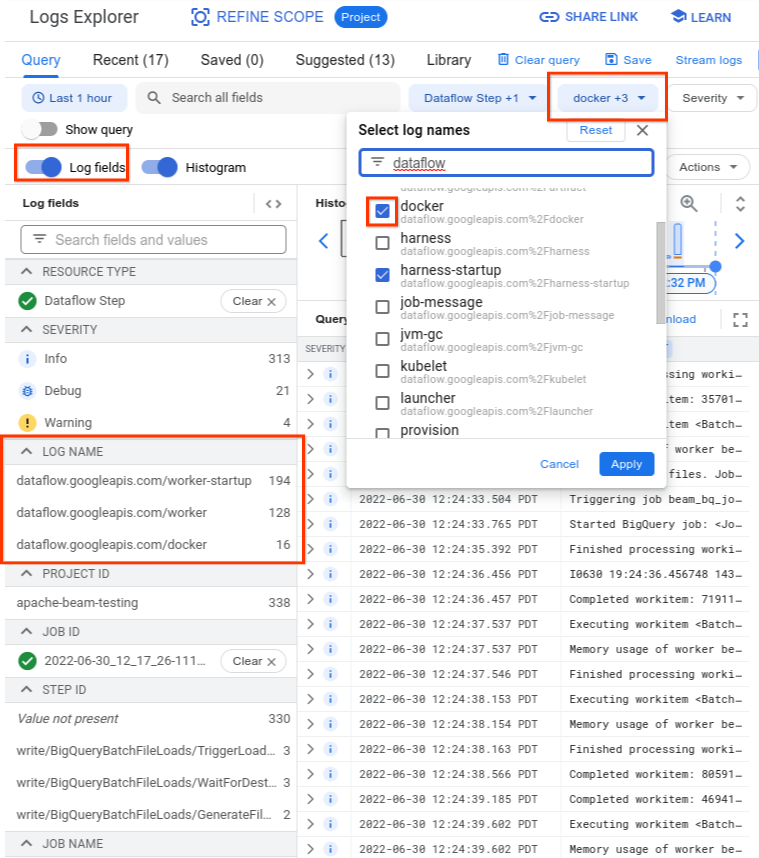
Depois de selecionar os registros relevantes, o resultado da consulta poderá ser semelhante ao seguinte exemplo:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Como os registros que relatam o sintoma da falha do contêiner às vezes são relatados como INFO, inclua registros INFO na sua análise.
As causas típicas de falhas de contêiner incluem:
- O pipeline do Python tem outras dependências instaladas no ambiente de execução,
e a instalação não é concluída. É possível que você veja erros como
pip install failed with error. Esse problema pode ocorrer devido a requisitos conflitantes ou devido a uma configuração de rede restrita que impede que um worker do Dataflow extraia uma dependência externa de um repositório público pela Internet. Um worker falha no meio da execução do pipeline devido a um erro de falta de memória. Você verá um erro como este:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Para depurar um problema de falta de memória, consulte Resolver erros de falta de memória do Dataflow.
O Dataflow não consegue extrair a imagem do contêiner. Para mais informações, consulte Falha na solicitação de envio de imagem com erro.
O contêiner usado não é compatível com a arquitetura de CPU da VM de worker. Nos registros de inicialização do arcabouço, talvez você encontre um erro como este:
exec /opt/apache/beam/boot: exec format error. Para verificar a arquitetura da imagem do contêiner, executedocker image inspect $IMAGE:$TAGe procure a palavra-chaveArchitecture. Se ela mostrarError: No such image: $IMAGE:$TAG, talvez seja necessário primeiro extrair a imagem executandodocker pull $IMAGE:$TAG. Para informações sobre como criar imagens de multiarquitetura, consulte Criar uma imagem de contêiner de várias arquiteturas.
Depois de identificar o erro que causa a falha do contêiner, tente resolvê-lo e reenvie o pipeline.
Falha na solicitação de envio de imagem com erro
Durante a inicialização do worker, um dos seguintes erros aparece nos registros do worker ou do job:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Esses erros ocorrem se um worker não for inicializado porque não consegue extrair uma imagem de contêiner do Docker. Esse problema acontece nos seguintes cenários:
- O URL da imagem do contêiner do SDK personalizado está incorreto
- O worker não tem credenciais ou acesso de rede à imagem remota
Para solucionar esse problema:
- Se você estiver usando uma imagem de contêiner personalizada com o job, verifique se o URL da imagem está correto e tem uma tag ou um resumo válido. Os workers do Dataflow também precisam de acesso à imagem.
- Verifique se as imagens públicas podem ser extraídas localmente executando
docker pull $imagea partir de uma máquina não autenticada.
Para imagens ou workers particulares:
- Em vez de usar o Container Registry para hospedar sua imagem de contêiner, é recomendável usar o Artifact Registry. Em vigor a partir de 15 de maio de 2023, o Container Registry será descontinuado. Se você usa o Container Registry, faça a transição para o Artifact Registry. Se as imagens estiverem em um projeto diferente daquele usado para executar o job do Google Cloud , configure o controle de acesso para a conta de serviço padrão do Google Cloud .
- Se estiver usando uma nuvem privada virtual (VPC) compartilhada, verifique se os workers podem acessar o host do repositório de contêineres personalizado.
- Use
sshpara se conectar a uma VM de worker de jobs e executedocker pull $imagepara confirmar diretamente que ele está configurado corretamente.
Se os workers falharem várias vezes seguidas devido a esse erro e nenhum trabalho for iniciado em um job, ele falhará com um erro como a seguinte mensagem: .
Job appears to be stuck.
Se você remover o acesso à imagem enquanto o job está em execução, seja removendo a imagem em si ou revogando as credenciais da conta de serviço do worker do Dataflow ou o acesso à Internet para acessar imagens, o Dataflow só registrará erros. O Dataflow não falha no job. O Dataflow também evita a falha de pipelines de streaming de longa duração para evitar a perda do estado do pipeline.
Outros possíveis erros podem surgir de problemas de cota do repositório ou interrupções. Se você tiver problemas de extrapolação da cota do Docker Hub para extrair imagens públicas ou interrupções gerais de repositórios de terceiros, considere usar o Artifact Registry como repositório de imagens.
SystemError: desconhecido opcode
O pipeline de contêiner personalizado do Python pode falhar com o seguinte erro imediatamente após o envio do job:
SystemError: unknown opcode
Além disso, o stack trace pode incluir
apache_beam/internal/pickler.py
Para resolver esse problema, verifique se a versão do Python que você está usando localmente corresponde à versão na imagem do contêiner até a versão principal e secundária. A diferença na versão do patch, como 3.6.7 e 3.6.8, não cria problemas de compatibilidade. A diferença na versão secundária, como 3.6.8 em comparação com 3.8.2, pode causar falhas no pipeline.
Erros de upgrade do pipeline de streaming
Para informações sobre como resolver erros ao fazer upgrade de um pipeline de streaming usando recursos como a execução de um job de substituição paralela, consulte Solução de problemas de upgrades de pipeline de streaming.
Atualização do arnés do Runner v2
A seguinte mensagem de informação aparece nos registros de um job do Runner v2
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
Isso significa que a versão do processo de arnes do executor será atualizada automaticamente em algum momento sete dias após a entrega inicial da mensagem, resultando em uma breve pausa no processamento. Se você quiser controlar quando essa pausa ocorre, consulte Atualizar um pipeline atual para iniciar um job de substituição que terá a versão mais recente do conector do runner.
Erros do worker
As seções a seguir contêm erros comuns de worker que você pode encontrar e etapas para resolver ou resolver os erros.
Falha na chamada do arcabouço de trabalho do Java para o DoFn do Python com erro
Se uma chamada do arcabouço de worker do Java para um DoFn do Python falhar, uma mensagem de erro relevante será exibida.
Para investigar o erro, expanda a entrada do registro de erros do Cloud Monitoring e observe a mensagem de erro e o traceback. Ele mostra qual código falhou para que você possa corrigi-lo se necessário. Se você acredita que o erro é um bug no Apache Beam ou no Dataflow, informe-o.
EOFError: dados de marshal muito curtos
O seguinte erro aparece nos registros do worker:
EOFError: marshal data too short
Esse erro às vezes acontece quando os workers do pipeline do Python ficam sem espaço em disco.
Para resolver esse problema, consulte Sem espaço disponível no dispositivo.
Falha ao anexar disco
Quando você tenta iniciar um job do Dataflow que usa VMs C3 com o Persistent Disk, ele falha com um dos seguintes erros ou ambos:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Esses erros ocorrem quando você usa VMs C3 com um tipo de Persistent Disk não compatível. Para mais informações, consulte Tipos de disco compatíveis com C3.
Para usar VMs C3 com seu job do Dataflow, escolha o
tipo de disco do worker pd-ssd. Para mais informações, consulte
Opções no nível do worker.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
Não há espaço livre no dispositivo
Quando um job fica sem espaço em disco, o seguinte erro pode aparecer nos registros do worker:
No space left on device
Esse erro pode ocorrer por um dos seguintes motivos:
- O armazenamento permanente do worker fica sem espaço livre,
o que pode ocorrer por um dos seguintes motivos:
- Um job faz o download de grandes dependências em tempo de execução
- Um job usa contêineres personalizados grandes
- Um job grava muitos dados temporários no disco local
- Ao usar o Dataflow Shuffle, o Dataflow define um tamanho de disco padrão menor. Como resultado, esse erro pode ocorrer com jobs migrando da reprodução aleatória baseada em worker.
- O disco de inicialização do worker é preenchido porque está registrando mais de 50 entradas por segundo.
Para resolver o problema, siga estas etapas:
Para ver os recursos de disco associados a um único worker, procure detalhes de instâncias de VM para VMs de worker associadas ao job. Parte do espaço em disco é consumida pelo sistema operacional, binários, registros e contêineres.
Para aumentar o espaço do disco permanente ou do disco de inicialização, ajuste a opção de pipeline do tamanho do disco.
Use o Cloud Monitoring para rastrear o uso do espaço em disco nas instâncias de VM de worker. Consulte Receber métricas de VMs de workers do agente do Monitoring para instruções sobre como configurar isso.
Procure problemas de espaço em disco de inicialização visualizando a saída da porta serial nas instâncias de VM do worker e procurando mensagens como:
Failed to open system journal: No space left on device
Se você tiver muitas instâncias de VM de worker, poderá criar um script para executar gcloud compute instances get-serial-port-output em todas elas de uma só vez.
Você pode analisar essa saída.
O pipeline Python falha após uma hora de inatividade do worker
Ao usar o SDK do Apache Beam para Python com o Dataflow Runner V2 em máquinas de worker com muitos núcleos de CPU, use o SDK do Apache Beam 2.35.0 ou mais recente. Se o job usar um contêiner personalizado, utilize o SDK do Apache Beam 2.46.0 ou mais recente.
Considere pré-criar o contêiner do Python. Essa etapa pode melhorar os tempos de inicialização da VM e o desempenho do escalonamento automático horizontal. Para testar esse recurso, ative a API Cloud Build no seu projeto e envie seu pipeline com o seguinte parâmetro:
‑‑prebuild_sdk_container_engine=cloud_build.
Para mais informações, consulte Executor do Dataflow V2.
Também é possível usar uma imagem de contêiner personalizada com todas as dependências pré-instaladas.
RESOURCE_POOL_EXHAUSTED
Ao criar um recurso Google Cloud , ocorre o seguinte erro:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
Esse erro ocorre para condições temporárias de falta de um recurso específico em uma zona específica.
Para resolver o problema, aguarde ou crie o mesmo recurso em outra zona.
Como solução alternativa, implemente um loop de novas tentativas para seus jobs. Assim, quando ocorrer um erro de falta de estoque, o job vai tentar novamente de forma automática até que os recursos estejam disponíveis. Para criar um loop de nova tentativa, implemente o seguinte fluxo de trabalho:
- Crie um job do Dataflow e receba o ID dele.
- Pesquise o status do job até que ele seja
RUNNINGouFAILED.- Se o status do job for
RUNNING, saia do loop de novas tentativas. - Se o status do job for
FAILED, use a API Cloud Logging para consultar os registros do job pela stringZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS. Para mais informações, consulte Trabalhar com registros de canal.- Se os registros não contiverem a string, saia do loop de nova tentativa.
- Se os registros contiverem a string, crie um job do Dataflow, receba o ID do job e reinicie o loop de novas tentativas.
- Se o status do job for
Como prática recomendada, distribua seus recursos em várias zonas e regiões para tolerar interrupções.
Instâncias com aceleradores convidados não são compatíveis com a migração em tempo real
Um pipeline do Dataflow falha no envio do job com o seguinte erro:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
Esse erro pode ocorrer quando você solicita um tipo de máquina worker com aceleradores de hardware, mas não configura o Dataflow para usar aceleradores.
Use a opção de serviço do Dataflow --worker_accelerator ou a dica de recurso accelerator para solicitar aceleradores de hardware.
Se você usa modelos Flex, pode usar a opção --additionalExperiments para
fornecer opções do serviço Dataflow. Se feito corretamente, a opção
worker_accelerator pode ser encontrada no painel de informações do job no
consoleGoogle Cloud .
Cota do projeto ... ou políticas de controle de acesso impedindo a operação
O seguinte erro ocorre:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
Esse erro ocorre por um dos seguintes motivos:
- Talvez você tenha excedido uma das cotas do Compute Engine necessárias para a criação do worker do Dataflow.
- Sua organização tem restrições que proíbem algum aspecto do processo de criação da instância de VM, como a conta em uso ou a zona segmentada.
Para resolver o problema, siga estas etapas:
Revise o registro da instância de VM
- Acesse o Visualizador de registros do Cloud.
- Na lista suspensa Recurso auditado, selecione Instância da VM.
- Na lista suspensa Todos os registros, selecione compute.googleapis.com/activity_log.
- Verifique se há entradas no registro relacionadas à falha na criação da instância de VM.
Verificar o uso das cotas do Compute Engine
Para ver o uso de recursos do Compute Engine em comparação com as cotas do Dataflow da zona segmentada, execute o seguinte comando:
gcloud compute regions describe [REGION]Analise os resultados dos seguintes recursos para ver se algum deles excede a cota:
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
Se for necessário, solicite uma alteração de cota.
Conferir as restrições da política da sua organização
- Acesse a página Políticas da organização
- Revise as restrições de qualquer uma que possa limitar a criação de instâncias de VM para a conta que você está usando (por padrão, a conta de serviço do Dataflow) ou na zona em que você.
- Se você tiver uma política que restrinja o uso de endereços IP externos, desative os endereços IP externos para este job. Para mais informações sobre como desativar endereços IP externos, consulte Configurar regras de firewall e acesso à Internet.
O tempo para a atualização do worker expirou
Quando um job do Dataflow falha, ocorre o seguinte erro:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Várias causas podem levar a esse erro, incluindo:
- Sobrecarga do worker
- Como manter o bloqueio global do interpretador
- Configuração de DoFn de longa duração
Sobrecarga de worker
Às vezes, um erro de tempo limite ocorre quando o worker fica sem memória ou espaço de troca. Para resolver esse problema, primeiro execute o job novamente. Se o job ainda falhar e o mesmo erro ocorrer, tente usar um worker com mais memória e espaço em disco. Por exemplo, adicione a seguinte opção de inicialização do pipeline:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
Alterar o tipo de worker pode afetar o custo faturado. Para mais informações, consulte Resolver problemas de falta de memória no Dataflow.
Esse erro também pode ocorrer quando os dados contêm uma tecla de atalho. Nesse cenário, a utilização da CPU é alta em alguns workers durante a maior parte do job. No entanto, o número de workers não atinge o máximo permitido. Para mais informações sobre teclas de atalho e possíveis soluções, consulte Como escrever pipelines do Dataflow com a escalonabilidade em mente.
Para ver outras soluções para esse problema, consulte Uma tecla de atalho ... foi detectada.
Python: Global Interpreter Lock (GIL)
Se o código Python chamar código C/C++ usando o mecanismo de extensão Python, verifique se ele libera o bloqueio global de interpretador (GIL, na sigla em inglês) do Python em partes de código com uso intensivo de computação que não acessam o estado Python. Se a GIL não for lançada por um período prolongado, você poderá receber mensagens de erro como:
Unable to retrieve status info from SDK harness <...> within allowed time e SDK worker appears to be permanently unresponsive. Aborting the SDK.
As bibliotecas que facilitam as interações com extensões, como Cython e PyBind
têm primitivos para controlar o status GIL. Também é possível liberar manualmente a GIL
e reativá-la antes de retornar o controle ao interpretador do Python usando as
macros Py_BEGIN_ALLOW_THREADS e Py_END_ALLOW_THREADS.
Para mais informações, consulte Estado da linha de execução e Bloqueio do interpretador global
na documentação do Python.
É possível recuperar stack traces de uma linha de execução que esteja mantendo a GIL em um worker do Dataflow em execução da seguinte maneira:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
Nos pipelines do Python, na configuração padrão, o Dataflow pressupõe que cada processo do Python executado nos workers usa com eficiência um núcleo de vCPU. Se o código do pipeline ignorar as limitações do GIL, como o uso de bibliotecas implementadas em C++, os elementos de processamento poderão usar recursos de mais de um núcleo de vCPU, fazendo com que os workers não recebam recursos de CPU suficientes. Para contornar esse problema, reduza o número de linhas de execução nos workers.
Configuração de DoFn de longa duração
Se você não estiver usando o Runner v2, uma chamada de longa duração para DoFn.Setup
poderá gerar o seguinte erro:
Timed out waiting for an update from the worker
Em geral, evite operações demoradas dentro de DoFn.Setup.
Erros temporários de publicação no tópico
Quando o job de streaming usa o modo de streaming pelo menos uma vez e publica em um coletor do Pub/Sub, o erro a seguir aparece nos registros do job:
There were transient errors publishing to topic
Se o job for executado corretamente, esse erro é benigno e pode ser ignorado. O Dataflow tenta enviar novamente as mensagens do Pub/Sub automaticamente com um atraso de espera.
Não foi possível buscar dados devido a uma incompatibilidade de token para a chave
O seguinte erro significa que o item de trabalho em processamento foi realocado para outro worker:
Unable to fetch data due to token mismatch for key
Isso geralmente acontece durante o escalonamento automático, mas pode ocorrer a qualquer momento. Qualquer trabalho afetado será repetido. Você pode ignorar esse erro.
Problemas de dependência do Java
Classes e bibliotecas incompatíveis podem causar problemas de dependência do Java. Quando o pipeline tem problemas de dependência Java, pode ocorrer um dos seguintes erros:
NoClassDefFoundError: esse erro ocorre quando uma classe inteira não está disponível durante o tempo de execução. Isso pode ser causado por problemas gerais de configuração ou por incompatibilidades entre a versão do protobuf do Beam e os protos gerados de um cliente (por exemplo, este problema).NoSuchMethodError: esse erro ocorre quando a classe no caminho de classe usa uma versão que não contém o método correto ou quando a assinatura do método mudou.NoSuchFieldError: esse erro ocorre quando a classe no caminho de classe usa uma versão que não tem um campo obrigatório durante o tempo de execução.FATAL ERROR in native method: esse erro ocorre quando uma dependência integrada não pode ser carregada corretamente. Ao usar JAR uber (sombreado), não inclua bibliotecas que usam assinaturas (como Conscrypt) no mesmo JAR.
Se o pipeline contém código e configurações específicos do usuário, o código não pode conter versões mistas de bibliotecas. Se você estiver usando uma biblioteca de gerenciamento de dependências, recomendamos a BOM das bibliotecas doGoogle Cloud .
Se você estiver usando o SDK do Apache Beam, para importar as BOMs das bibliotecas corretas,
use beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Para mais informações, consulte Gerenciar dependências de pipeline no Dataflow.
InaccessibleObjectException no JDK 17 e posterior
Ao executar pipelines com a versão 17 e mais recentes do Java Platform, Standard Edition Development Kit (JDK) e versões mais recentes, o erro a seguir pode aparecer nos arquivos de registros do worker:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Esse problema ocorre porque, a partir da versão 9 do Java, as opções de máquina virtual Java (JVM) de módulo aberto são necessárias para acessar os componentes internos do JDK. No Java 16 e versões mais recentes, as opções de JVM do módulo aberto são sempre necessárias para acessar os componentes internos do JDK.
Para resolver esse problema, ao transmitir módulos para serem abertos pelo
pipeline do Dataflow, use o formato
MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)*
com a opção de pipeline jdkAddOpenModules. Esse formato
permite acesso à biblioteca necessária.
Por exemplo, se o erro for module java.base does not "opens java.lang" to unnamed module @..., inclua a seguinte opção de pipeline ao executá-lo:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
Para mais informações, consulte a
documentação da classe
DataflowPipelineOptions.
Erro ao informar o progresso do workitem
Em pipelines Java, se você não estiver usando o Runner V2, poderá encontrar o seguinte erro:
Error reporting workitem progress update to Dataflow service: ...
Esse erro é causado por uma exceção não processada durante uma atualização do progresso de um item de trabalho, como durante a divisão de uma origem. Na maioria dos casos, se o código do usuário do Apache Beam gerar uma exceção não processada, o item de trabalho vai falhar, causando a falha do pipeline.No entanto, as exceções em Source.split são suprimidas porque essa parte do código está fora de um item de trabalho. Como resultado, apenas um registro de erros é gravado.
Esse erro geralmente é inofensivo se ocorrer apenas de forma intermitente. No entanto, considere processar as exceções de maneira adequada no código Source.split.
Erros do conector do BigQuery
As seções a seguir contêm erros comuns do conector do BigQuery que você pode encontrar e etapas para resolver ou resolver os erros.
quotaExceeded
Quando você usa o conector do BigQuery para gravar no BigQuery usando inserções de streaming, a capacidade de gravação é menor que o esperado, e pode ocorrer o seguinte erro:
quotaExceeded
A capacidade lenta pode ser causada porque o pipeline excede a cota de inserção de streaming do BigQuery disponível. Nesse caso, as mensagens de erro relacionadas à cota do BigQuery aparecem nos registros de worker do Dataflow (procure erros quotaExceeded).
Caso veja erros quotaExceeded, para resolver esse problema:
- Ao usar o SDK do Apache Beam para Java, defina a opção do coletor do BigQuery
ignoreInsertIds(). - Ao usar o SDK do Apache Beam para Python, use a opção
ignore_insert_ids.
Com essas configurações, você se qualifica para um GB/s por segundo de capacidade de processamento de inserção por streaming do BigQuery por projeto. Para mais informações sobre ressalvas relacionadas à eliminação de duplicação automática de mensagens, consulte a documentação do BigQuery. Para aumentar a cota da inserção por streaming do BigQuery para mais de 1 GBps, envie uma solicitação pelo Google Cloud console.
Se você não encontrar erros relacionados à cota nos registros do worker, talvez o problema seja que
os pacotes padrão ou os parâmetros em lote não fornecem paralelismo adequado
para o pipeline escalonar. É possível ajustar várias configurações relacionadas ao conector do BigQuery do Dataflow para alcançar o desempenho esperado ao gravar no BigQuery usando inserções de streaming. Por exemplo, no SDK do Apache Beam para Java, ajuste numStreamingKeys para corresponder ao número máximo de workers e considere aumentar insertBundleParallelism para configurar o conector do BigQuery para gravar no BigQuery usando linhas de execução mais paralelas.
Para ver as configurações disponíveis no SDK do Apache Beam para Java, consulte BigQueryPipelineOptions e consulte as configurações disponíveis no SDK do Apache Beam para Python na transformação do WriteToBigQuery.
rateLimitExceeded
Quando você usa o conector do BigQuery, o seguinte erro ocorre:
rateLimitExceeded
Esse erro ocorrerá se o BigQuery tiver muitas
solicitações de API
enviadas durante um curto período. O BigQuery tem limites de cota de curto prazo.
É possível que o pipeline do Dataflow exceda temporariamente essa cota. Sempre que isso acontece, as
solicitações de API
do seu pipeline do Dataflow para o BigQuery podem falhar, o que
pode resultar em erros rateLimitExceeded nos registros do worker.
O Dataflow repete essas falhas para que seja possível ignorá-los com segurança. Se você acredita que o pipeline foi afetado por erros de rateLimitExceeded, entre em contato com o Cloud Customer Care.
Erros diversos
As seções a seguir contêm diversos erros que você pode encontrar e etapas para resolvê-los.
Não é possível alocar sha384
O job é executado corretamente, mas os registros dele mostram o seguinte erro:
ima: Can not allocate sha384 (reason: -2)
Se o job for executado corretamente, esse erro é benigno e pode ser ignorado. Às vezes, as imagens de base da VM de worker produzem essa mensagem. O Dataflow responde e resolve automaticamente o problema subjacente.
Existe uma solicitação de recurso para alterar o nível dessa mensagem
de WARN para INFO. Para mais informações, consulte Como reduzir o nível de registro de erros de inicialização do sistema do Dataflow para WARN ou INFO.
Erro ao inicializar a sondagem de plug-in dinâmico
O job é executado corretamente, mas os registros dele mostram o seguinte erro:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Se o job for executado corretamente, esse erro é benigno e pode ser ignorado. Esse erro ocorre quando o job do Dataflow tenta criar um diretório sem as permissões de gravação necessárias, e a tarefa falha. Se o job for bem-sucedido, o diretório não foi necessário ou o Dataflow resolveu o problema subjacente.
Existe uma solicitação de recurso para alterar o nível dessa mensagem
de WARN para INFO. Para mais informações, consulte Como reduzir o nível de registro de erros de inicialização do sistema do Dataflow para WARN ou INFO.
Nenhum objeto desse tipo: pipeline.pb
Ao listar jobs usando a opção JOB_VIEW_ALL, ocorre o seguinte erro:
No such object: BUCKET_NAME/PATH/pipeline.pb
Esse erro poderá ocorrer se você excluir o arquivo pipeline.pb dos arquivos de teste
do job.
Como pular a sincronização de pods
O job é executado corretamente, mas os registros do job mostram um dos seguintes erros:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
Ou:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Se o job for executado corretamente, esses erros são benignos e podem ser ignorados.
A mensagem container runtime status check may not have completed yet ocorre quando o kubelet do Kubernetes está pulando a sincronização de pods porque está aguardando a inicialização do ambiente de execução do contêiner. Esse cenário ocorre por vários motivos, como quando o ambiente de execução do contêiner foi iniciado recentemente ou está sendo reiniciado.
Quando a mensagem incluir PLEG is not healthy: pleg has yet to be successful, o kubelet estará esperando que o gerador de eventos de ciclo de vida do pod (PLEG, na sigla em inglês) se torne íntegro antes de sincronizar os pods. A PLEG é responsável por gerar eventos
que são usados pelo kubelet para rastrear o estado dos pods.
Existe uma solicitação de recurso para alterar o nível dessa mensagem
de WARN para INFO. Para mais informações, consulte Como reduzir o nível de registro de erros de inicialização do sistema do Dataflow para WARN ou INFO.
Recomendações
Para ver orientações sobre recomendações geradas pelo Dataflow Insights, consulte Insights.