Unbegrenzte PCollections oder unbegrenzte Sammlungen stellen Daten in Streaming-Pipelines dar. Eine unbegrenzte Sammlung enthält Daten aus einer kontinuierlich aktualisierten Datenquelle wie z. B. Pub/Sub.
Sie können einen Schlüssel nicht zum Gruppieren von Elementen in einer unbegrenzten Sammlung verwenden. Es kann unendlich viele Elemente für einen bestimmten Schlüssel in Streaming-Daten geben, da die Datenquelle ständig neue Elemente hinzufügt. Mit Fenstern, Wasserzeichen und Triggern können Sie Elemente in unbegrenzten Sammlungen zusammenfassen.
Das Fensterkonzept gilt auch für begrenzte PCollections, die Daten in Batch-Pipelines darstellen. Informationen zum Windowing in Batch-Pipelines finden Sie in der Apache Beam-Dokumentation zum Windowing mit begrenzten PCollections.
Wenn eine Dataflow-Pipeline eine begrenzte Datenquelle hat, d. h. eine Quelle, die keine kontinuierlich aktualisierten Daten enthält, und die Pipeline mit dem Flag --streaming in den Streaming-Modus wechselt, wenn die begrenzte Quelle vollständig genutzt wird, beendet die Pipeline die Ausführung.
Streamingmodus verwenden
Setzen Sie das Flag --streaming in der Befehlszeile, wenn Sie eine Pipeline ausführen, um die Pipeline im Streamingmodus auszuführen. Außerdem lässt sich der Streamingmodus beim Erstellen der Pipeline programmatisch festlegen.
Batchquellen werden nicht im Streamingmodus unterstützt.
Wenn Sie die Pipeline mit einem größeren Worker-Pool aktualisieren, wird der Streamingjob möglicherweise nicht wie erwartet hochskaliert. Bei Streaming-Jobs, die nicht Streaming Engine verwenden, können Sie keine Skalierung über die ursprüngliche Anzahl von Workern und Ressourcen an nichtflüchtigem Speicher hinaus vornehmen, die zu Beginn Ihres ursprünglichen Jobs zugewiesen wurden. Wenn Sie einen Dataflow-Job aktualisieren und eine größere Anzahl von Workern im neuen Job angeben, können Sie nur so viele Worker angeben, wie Sie für die maximale Anzahl von Workern für Ihren ursprünglichen Job festgelegt haben.
Geben Sie die maximale Anzahl der Worker mit den folgenden Flags an:
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
Fenster und Fensterfunktionen
Fensterfunktionen teilen unbegrenzte Sammlungen in logische Komponenten oder Fenster. Fensterfunktionen gruppieren unbegrenzte Sammlungen nach den Zeitstempeln der einzelnen Elemente. Jedes Fenster enthält eine endliche Anzahl von Elementen.
Mit dem Apache Beam SDK legen Sie die folgenden Fenster fest:
- Rollierende Fenster (werden in Apache Beam als feste Fenster bezeichnet)
- Springende Fenster (werden in Apache Beam gleitende Fenster genannt)
- Sitzungsfenster
Rollierende Fenster
Ein rollierendes Fenster stellt ein konsistentes, disjunktes Zeitintervall im Datenstrom dar.
Wenn Sie beispielsweise ein 30 Sekunden langes rollierendes Fenster festlegen, befinden sich die Elemente mit Zeitstempelwerten [0:00:00-0:00:30] im ersten Fenster. Elemente mit Zeitstempelwerten [0:00:30-0:01:00] befinden sich im zweiten Fenster.
Die folgende Abbildung zeigt, wie Elemente in rollierende 30-Sekunden-Fenster unterteilt werden.
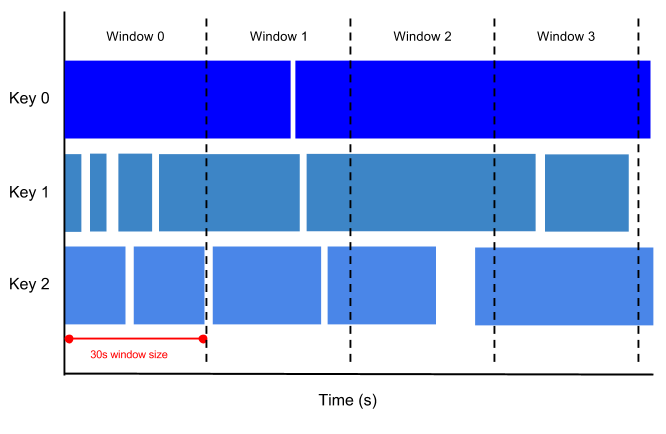
Springende Fenster
Ein springendes Fenster stellt ein konsistentes Zeitintervall im Datenstrom dar. Springende Fenster können sich überschneiden, während rollierende Fenster disjunkt sind.
Beispielsweise kann ein springendes Fenster alle 30 Sekunden beginnen und eine Minute Daten erfassen. Die Frequenz, mit der springende Fenster beginnen, wird Periode genannt. Dieses Beispiel hat ein einminütiges Fenster und einen dreißigsekündigen Zeitraum.
Die folgende Abbildung zeigt, wie Elemente in springende einminütige Fenster mit einem Zeitraum von 30 Sekunden unterteilt werden.
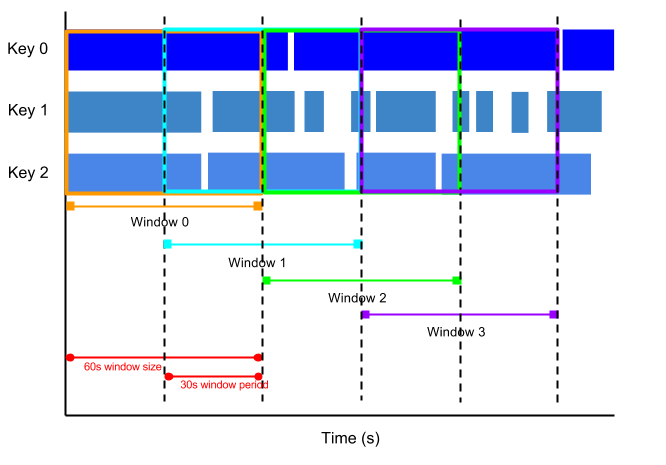
Um laufende Durchschnittswerte von Daten zu erhalten, verwenden Sie springende Fenster. Sie können springende einminütige Fenster mit 30-Sekunden-Perioden verwenden, um alle 30 Sekunden einen laufenden Durchschnitt von einer Minute zu berechnen.
Sitzungsfenster
Ein Sitzungsfenster enthält Elemente mit einer Abstandszeit eines anderen Elements. Die Abstandszeit ist ein Intervall zwischen neuen Daten in einem Datenstrom. Wenn Daten nach der Abstandszeit ankommen, werden die Daten einem neuen Fenster zugewiesen.
Sitzungsfenster können beispielsweise einen Datenstrom teilen, der die Nutzermausaktivität darstellt. Dieser Datenstream kann längere Inaktivitätszeiten mit vielen Klicks haben. Ein Sitzungsfenster kann die von den Klicks generierten Daten enthalten.
Beim Sitzungs-Windowing werden jedem Datenschlüssel verschiedene Fenster zugewiesen. Rollierende und springende Fenster enthalten alle Elemente im angegebenen Zeitintervall, unabhängig von den Datenschlüsseln.
Die folgende Abbildung zeigt, wie Elemente in Sitzungsfenster unterteilt werden.
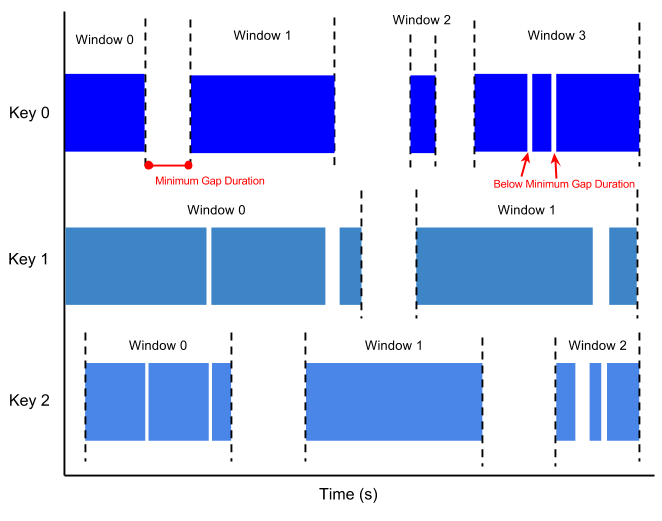
Wasserzeichen
Ein Wasserzeichen ist ein Grenzwert, der angibt, wann Dataflow erwartet, dass alle Daten in einem Fenster angekommen sind. Wenn das Wasserzeichen das Ende des Fensters überschritten hat und neue Daten mit einem Zeitstempel innerhalb des Fensters eintreffen, werden die Daten als verspätete Daten betrachtet. Weitere Informationen finden Sie in der Apache Beam-Dokumentation unter Wasserzeichen und verspätete Daten.
Dataflow verfolgt Wasserzeichen aus folgenden Gründen:
- Es kann nicht garantiert werden, dass Daten in zeitlicher Reihenfolge oder in vorhersehbaren Intervallen eingehen.
- Es kann nicht garantiert werden, dass Datenereignisse in Pipelines in derselben Reihenfolge angezeigt werden, in der sie generiert wurden.
Die Datenquelle bestimmt das Wasserzeichen. Mit dem Apache Beam SDK können Sie verspätete Daten zulassen.
Trigger
Trigger bestimmen, wann aggregierte Ergebnisse nach dem Eintreffen von Daten ausgegeben werden. Standardmäßig werden Ergebnisse ausgegeben, wenn das Wasserzeichen das Ende des Fensters übergibt.
Sie können das Apache Beam SDK verwenden, um Trigger für jede Sammlung in einer Streaming-Pipeline zu erstellen oder zu ändern.
Das Apache Beam SDK kann Trigger setzen, die mit einer beliebigen Kombination der folgenden Bedingungen arbeiten:
- Ereigniszeit, wie durch den Zeitstempel für jedes Datenelement angegeben.
- Die Verarbeitungszeit, in der das Datenelement in einer bestimmten Phase der Pipeline verarbeitet wird.
- Die Anzahl der Datenelemente in einer Sammlung.