Best practices for optimizing your cloud costs
Justin Lerma
Professional Services, Technical Account Manager
Pathik Sharma
Cloud FinOps Lead, delta, Google Cloud Consulting
One of the greatest benefits of running in the cloud is being able to scale up and down to meet demand and reduce operational expenditures. And that’s especially true when you’re experiencing unexpected changes in customer demand.
Here at Google Cloud, we have an entire team of Solutions Architects dedicated to helping customers manage their cloud operating expenses. Over the years working with our largest customers, we’ve identified some common things people tend to miss when looking for ways to optimize costs, and compiled them here for you. We think that following these best practices will help you rightsize your cloud costs to the needs of your business, so you can get through these challenging, unpredictable times.

1. Get to know billing and cost management tools
Due to the on-demand, variable nature of cloud, costs have a way of creeping up on you if you're not monitoring them closely. Once you understand your costs, you can start to put controls in place and optimize your spending. To help with this, Google Cloud provides a robust set of no-cost billing and cost management tools that can give you the visibility and insights you need to keep up with your cloud deployment.
At a high level, learn to look for things like “which projects cost the most, and why?" To start, organize and structure your costs in relation to your business needs. Then, drill down into the services using Billing reports to get an at-a-glance view of your costs. You should also learn how to attribute costs back to departments or teams using labels and build your own custom dashboards for more granular cost views. You can also use quotas, budgets, and alerts to closely monitor your current cost trends and forecast them over time, to reduce the risk of overspending.
If you aren't familiar with our billing and cost management tools, we are offering free training for a limited time to help you learn the fundamentals of understanding and optimizing your Google Cloud costs. For a comprehensive step by step guide, see our Guide to Cloud Billing and watch our Beyond Your Bill video series. Be sure to also check out these hands-on training courses: Understanding your Google Cloud Costs and Optimizing your GCP Costs.
2. Only pay for the compute you need
Now that you have better visibility in your cloud spend, it’s time to set your sights on your most expensive project(s) to identify compute resources that aren’t providing enough business value.
Identify idle VMs (and disks): The easiest way to reduce your Google Cloud Platform (GCP) bill is to get rid of resources that are no longer being used. Think about those proof-of-concept projects that have since been deprioritized, or zombie instances that nobody bothered to delete. Google Cloud offers several Recommenders that can help you optimize these resources, including an idle VM recommender that identifies inactive virtual machines (VMs) and persistent disks based on usage metrics.
Always tread carefully when deleting a VM, though. Before deleting a resource, ask yourself, “what potential impact will deleting this resource have and how can I recreate it, if necessary?” Deleting instances gets rid of the underlying disk(s) and all of its data. One best practice is to take a snapshot of the instance before deleting it. Alternatively, you can choose to simply stop the VM, which terminates the instance, but keeps resources like disks or IP addresses until you detach or delete them.
For more info, read the recommender documentation. And stay tuned as we add more usage-based recommenders to the portfolio.
Schedule VMs to auto start and stop: The benefit of a platform like Compute Engine is that you only pay for the compute resources that you use. Production systems tend to run 24/7; however, VMs in development, test or personal environments tend to only be used during business hours, and turning them off can save you a lot of money! For example, a VM that runs for 10 hours per day, Monday through Friday costs 75% less to run per month compared to leaving it running.
To get started, here’s a serverless solution that we developed to help you automate and manage automated VM shutdown at scale.
Rightsize VMs: On Google Cloud, you can already realize significant savings by creating custom machine type with the right amount of CPU and RAM to meet your needs. But workload requirements can change over time. Instances that were once optimized may now be servicing fewer users and traffic. To help, our rightsizing recommendations can show you how to effectively downsize your machine type based on changes in vCPU and RAM usage. These rightsizing recommendations for your instance’s machine type (or managed instance group) are generated using system metrics gathered by Cloud Monitoring over the previous eight days.
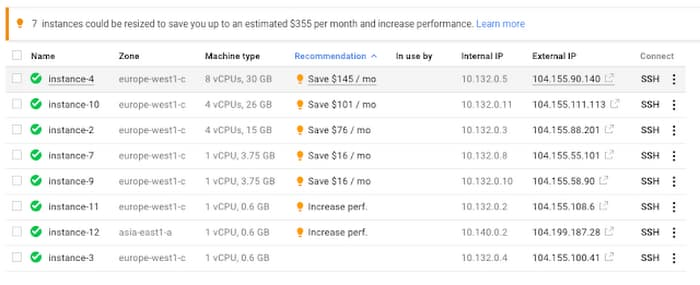
For organizations that use infrastructure as code to manage their environments, check out this guide, which will show you how to deploy VM rightsizing recommendations at scale.
Leverage preemptible VMs: Preemptible VMs are highly affordable compute instances that live up to 24 hours and that are up to 80% cheaper than regular instances. Preemptible VMs are a great fit for fault tolerant workloads such as big data, genomics, media transcoding, financial modelling and simulation. You can also use a mix of regular and preemptible instances to finish compute-intensive workloads faster and cost-effectively, by setting up a specialized managed instance group.
But why limit preemptible VMs to a Compute Engine environment? Did you know GPUs, GKE clusters and secondary instances in Dataproc can also use preemptible VMs? And now, you can also reduce your Cloud Dataflow streaming (and batch) analytics costs by using Flexible Resource Scheduling to supplement regular instances with preemptible VMs.
3. Optimize Cloud Storage costs and performance
When you run in your own data center, storage tends to get lost in your overall infrastructure costs, making it harder to do proper cost management. But in the cloud, where storage is billed as a separate line item, paying attention to storage utilization and configuration can result in substantial cost savings.
And storage needs, like compute, are always changing. It’s possible that the storage class you picked when you first set up your environment may no longer be appropriate for a given workload. Also, Cloud Storage has come a long way—it offers a lot of new features that weren't there just a year ago.
If you’re looking to save on storage, here are some good places to look.
Storage classes: Cloud Storage offers a variety of storage classes—standard, nearline, coldline and archival, all with varying costs and their own best-fit use cases. If you only use the standard class, it might be time to take a look at your workloads and reevaluate how frequently your data is being accessed. In our experience, many companies use standard class storage for archival purposes, and could reduce their spend by taking advantage of nearline or coldline class storage. And in some cases, if you are holding onto objects for cold-storage use cases like legal discovery, the new archival class storage might offer even more savings.
Lifecycle policies: Not only can you save money by using different storage classes, but you can make it happen automatically with object lifecycle management. By configuring a lifecycle policy, you can programmatically set an object to adjust its storage class based on a set of conditions—or even delete it entirely if it's no longer needed. For example, imagine you and your team analyze data within the first month it’s created; beyond that, you only need it for regulatory purposes. In that case, simply set a policy that adjusts your storage to coldline or archive after your object reaches 31 days.
Deduplication: Another common source of waste in storage environments is duplicate data. Of course, there are times when it’s necessary. For instance, you may want to duplicate a dataset across multiple geographic regions so that local teams can access it quickly. However, in our experience working with customers, a lot of duplicate data is the result of lax version control, and the resulting duplicates can be cumbersome and expensive to manage.
Luckily, there are lots of ways to prevent duplicate data, as well as tools to prevent data from being deleted in error. Here are a few things to consider:
If you’re trying to maintain resiliency with a single source of truth, it may make more sense to use a multi-region bucket rather than creating multiple copies in various buckets. With this feature, you will have geo redundancy enabled for objects stored. This will ensure your data is replicated asynchronously across two or more locations. This protects against regional failures in the event of a natural disaster.
A lot of duplicate data comes from not properly using the Cloud Storage object versioning feature. Object versioning prevents data from being overwritten or accidentally deleted, but the duplicates it creates can really add up. Do you really need five copies of your data? One might be enough as long as it's protected. Worried you won’t be able to roll back? You can set up object versioning policies to ensure you have an appropriate number of copies. Still worried about losing something accidentally? Consider using the bucket lock feature, which helps ensure that items aren’t deleted before a specific date or time. This is really useful for demonstrating compliance with several important regulations. In short, if you use object versioning, there are several features you can use to keep your data safe without wasting space unnecessarily.
4. Tune your data warehouse
Organizations of all sizes look to BigQuery for a modern approach to data analytics. However, some configurations are more expensive than others. Let's do a quick check of your BigQuery environment and set up some guardrails to help you keep costs down.
Enforce controls: The last thing you need is a long query to run forever and rack up costs. To limit query costs, use the maximum bytes billed setting. Going above the limit will cause the query to fail, but you also won’t get charged for it, as shown below.
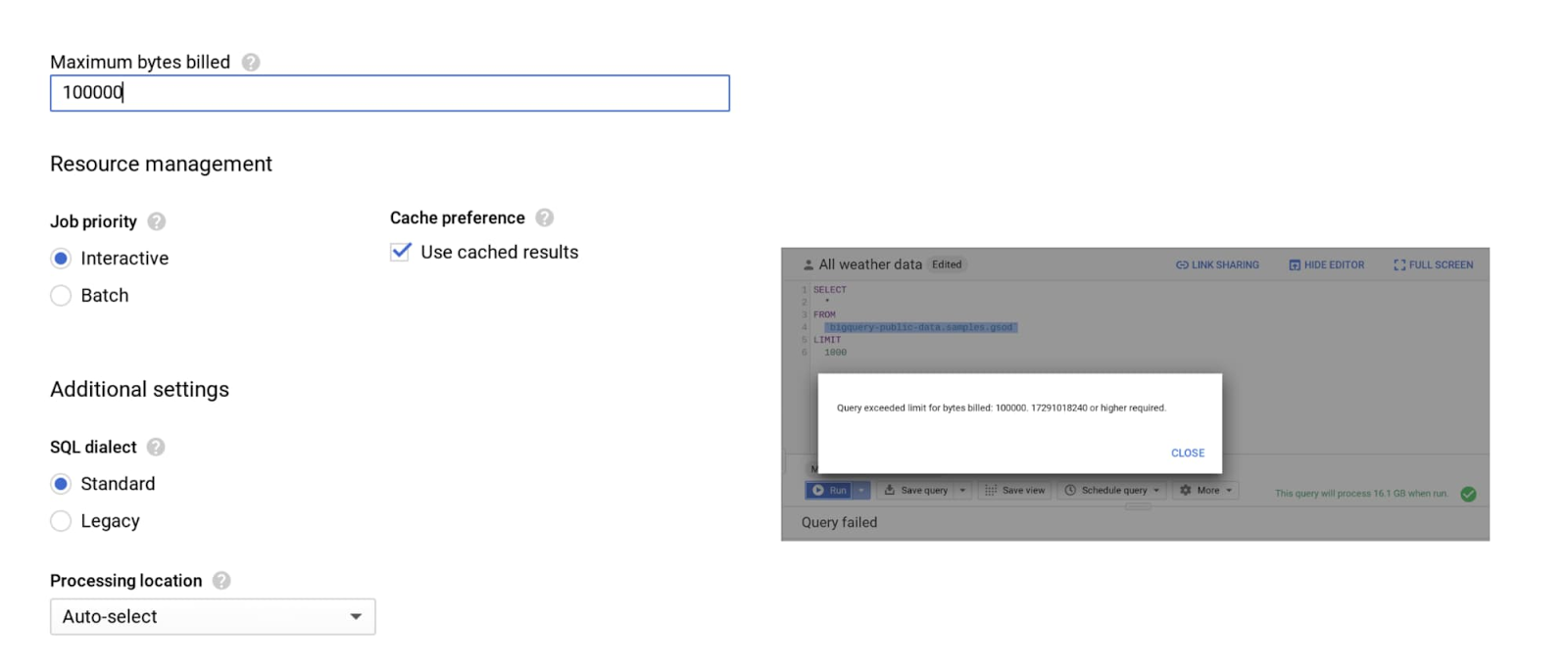
Along with enabling cost control on a query level, you can apply similar logic to users and projects as well.
Use partitioning and clustering: Partitioning and clustering your tables, whenever possible, can help greatly reduce the cost of processing queries, as well as improve performance. Today, you can partition a table based on ingestion time, date, timestamp or integer range column. To make sure your queries and jobs are taking advantage of partitioned tables, we also recommend you enable the Require partition filter, which forces users to include the partition column in the WHERE clause.
Another benefit of partitioning is that BigQuery automatically drops the price of data stored by 50% for each partition or table that hasn’t been edited in 90 days, by moving it into long-term storage. It is more cost-effective and convenient to keep your data in BigQuery rather than going through hassles of migrating it to lower tiered storage. There is no degradation of performance, durability, availability or any other functionality when a table or partition is moved to long-term storage.
Check for streaming inserts: You can load data into BigQuery in two ways: as a batch load job, or with real-time streaming, using streaming inserts. When optimizing your BigQuery costs, the first thing to do is check your bill and see if you are being charged for streaming inserts. And if you are, ask yourself, “Do I need data to be immediately available (seconds instead of hours) in BigQuery?” and “Am I using this data for any real-time use case once the data is available in BigQuery?” If the answer to either of these questions is no, then we recommend you to switch to batch loading data, which is free.
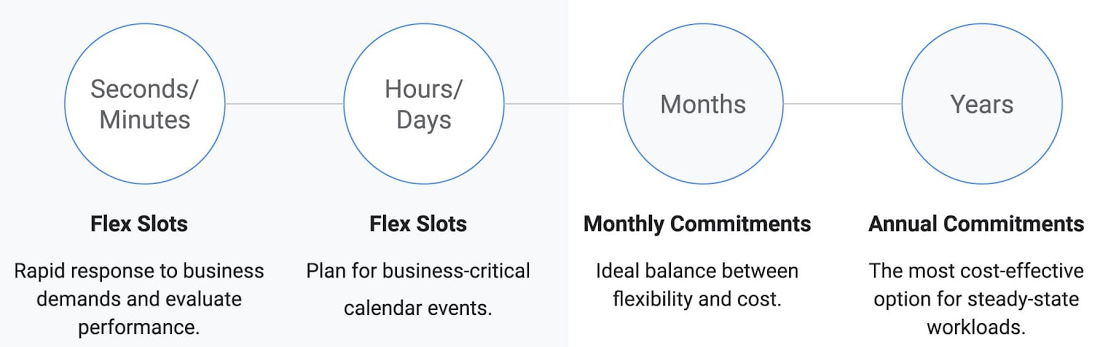
Use Flex Slots: By default, BigQuery charges you variable on-demand pricing based on bytes processed by your queries. If you are a high-volume customer with stable workloads, you may find it more cost effective to switch from on-demand to flat rate pricing, which gives you an ability to process unlimited bytes for a fixed predictable cost.
Given rapidly changing business requirements, we recently introduced Flex Slots, a new way to purchase BigQuery slots for duration as short as 60 seconds, on top of monthly and annual flat-rate commitments. With this combination of on-demand and flat-rate pricing, you can respond quickly and cost-effectively to changing demand for analytics.
5. Filter that network packet
Logging and monitoring are the cornerstones of network and security operations. But with environments that span clouds and on-premises environments, getting clear and comprehensive visibility into your network usage can be as hard as identifying how much electricity your microwave used last month. In fact, Google Cloud comes with several tools that can give you visibility into your network traffic (and therefore costs). There are also some quick and dirty configuration changes you can make to bring your network costs down, fast. Let’s take a look.
Identify your “top talkers”: Ever wonder which services are taking up your bandwidth? Cloud Platform SKUs is a quick way to identify how much you are spending on a given Google Cloud service. It’s also important to know your network layout and how traffic flows between your applications and users. Network Topology, a module of Network Intelligence Center, provides you comprehensive visibility into your global GCP deployment and its interaction with the public internet, including an organization-wide view of the topology, and associated network performance metrics. This allows you to identify inefficient deployments and take necessary actions to optimize your regional and intercontinental network egress cost. Checkout this brief video for an overview of Network Intelligence Center and Network Topology.
Network Service Tiers: Google Cloud lets you choose between two network service tiers: premium and standard. For excellent performance around the globe, you can choose premium tier, which continues to be our tier of choice. Standard tier offers a lower performance, but may be a suitable alternative for some cost-sensitive workloads.
Cloud Logging: You may not know it, but you do have control over network traffic visibility by filtering out logs that you no longer need. Check out some common examples of logs that you can safely exclude.The same applies to Data Access audit logs, which can be quite large and incur additional costs. For example you probably don’t need to log them for development projects. For VPC Flow Logs and Cloud Load Balancing, you can also enable sampling, which can dramatically reduce the volume of log traffic being written into the database. You can set this from 1.0 (100% log entries are kept) to 0.0 (0%, no logs are kept). For troubleshooting or custom use cases, you can always choose to collect telemetry for a particular VPC network or subnet or drill down further to monitor a specific VM Instance or virtual interface.
Want more?
Whether you’re an early-stage startup or a large enterprise with a global footprint, everyone wants to be smart with their money right now. Following the tips in this blog post will get you on your way. For more on optimizing your Google Cloud costs, check out our Cost Management video playlist, as well as deeper dives into other Cloud Storage, BigQuery, Networking, Compute Engine, and Cloud Logging and Monitoring cost optimization strategies. You can also reach out to talk to a cost optimization specialist; we’re here to help.



