Vertex AI Pipelines 上での PyTorch ML ワークフローのオーケストレーション
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
前回までの PyTorch on Google Cloud シリーズでは、Vertex AI のトレーニングおよび予測サービスを使って、PyTorch のテキスト分類モデルをトレーニング、チューニング、デプロイしました。この投稿では、Vertex AI Pipelines を使ってパイプラインをサーバーレスでオーケストレーションすることで、PyTorch ベースの ML ワークフローを自動化し、モニタリングする方法を紹介します。さっそく始めましょう。
パイプラインを選ぶ理由
本題に入る前に、まず、なぜ ML ワークフローにパイプラインが必要なのかを理解しましょう。以前に考えた通り、PyTorch ベースのモデルのトレーニングとデプロイには、データの処理、モデルのトレーニング、ハイパーパラメータのチューニング、評価、モデルのアーティファクトのパッケージ化、モデルのデプロイ、再トレーニングのサイクルといった一連のタスクが含まれます。これらのステップにはそれぞれ異なる依存関係があり、ワークフロー全体をモノリスとして扱うと、すぐに扱いづらくなってしまいます。

ML のシステムやプロセスがスケールし始めると、ML のワークフローをチームの他の人と共有して、ワークフローを実行し、コードに貢献することを希望するかもしれません。信頼性と再現性のあるプロセスがなければ、これは難しいことです。パイプラインでは、ML プロセスの各ステップがそれぞれのコンテナで実行されます。これにより、ステップを独立して開発し、各ステップからの入力と出力を再現可能な方法で追跡することができ、テストを効果的にイテレーションできます。これらのタスクを自動化し、複数のサービス間でオーケストレーションすることで、データ サイエンティストやデータ エンジニアなどの異なるチーム間で共有可能な、再現性のある ML ワークフローを実現します。
また、パイプラインは、トレーニングやデプロイのオペレーションを公式化し、モデルの再トレーニング、デプロイ、モニタリングを自動的に行う際に、MLOps の重要な要素となります。たとえば、新しいトレーニング データが利用可能になったときにパイプラインの実行を開始したり、モデルのパフォーマンスが低下し始めたときにモデルを再トレーニングするなど、さまざまなシナリオが考えられます。
Vertex AI Pipelines による PyTorch ベースの ML ワークフローのオーケストレーション
PyTorch ベースの ML ワークフローは、Vertex AI Pipelines でオーケストレートできます。Vertex AI Pipelines は、Vertex AI Platform 上で ML ワークフローの自動化、モニタリング、オーケストレーションを行うための、フルマネージドでサーバーレスな方法です。Vertex AI Pipelines は、以下の理由により、Google Cloud で ML ワークフローをオーケストレート、自動化、共有する最も効果的な方法です。
再現性と共有性のあるワークフロー: Vertex AI のパイプラインは、Python ベースのオープンソース ライブラリである Kubeflow Pipelines (KFP) v2 SDK を使用して定義できます。コンパイルされたパイプラインは、任意の git ツールでバージョン管理し、チーム間で共有できます。これにより、パイプラインを自動化しながら、ML ワークフローの再現性と信頼性を高めることができます。パイプラインは、Tensorflow Extended(TFX)SDK でもオーサリングできます。
ML モデルのオペレーションの効率化: Vertex AI Pipelines は、Vertex ML Metadata サービスを使用してメタデータを自動的に記録し、ML ワークフロー全体のアーティファクト、リネージ、指標、可視化、パイプラインの実行を追跡します。これにより、データ サイエンティストは新しいモデルや新しい機能を試す際に、テストを追跡できます。Vertex ML Metadata にアーティファクトへの参照を格納することで、データセットやモデルなどの ML アーティファクトのリネージを分析し、アーティファクトがどのように作成され、ダウンストリームのタスクで消費されたか、モデルの作成にどのようなパラメータやハイパーパラメータが使用されたかを把握できます。
サーバーレス、スケーラブル、コスト効率に優れている: Vertex AI Pipelines は完全にサーバーレスであるため、ML エンジニアはインフラストラクチャのタスク(プロビジョニング、メンテナンス、クラスタのデプロイなど)ではなく、ML ソリューションに集中できます。パイプラインがアップロードされて送信されると、サービスはパイプラインを実行するために必要なインフラストラクチャのプロビジョニングとスケーリングを行います。これは、パイプラインを実行するために使用されるリソースに対してのみ支払うことを意味します。
他の Google Cloud サービスとのインテグレーション: パイプライン ステップでは、BigQuery や Cloud Storage などのソースからのデータのインポート、Cloud Dataflow や Dataproc を使用したデータセットの変換、Vertex AI によるモデルの学習、パイプラインのアーティファクトの Cloud Storage への保存、モデルの評価指標の取得、Vertex AI エンドポイントへのモデルのデプロイなどを行うことができます。Vertex AI Pipelines の構築済みのパイプライン コンポーネントを使用すると、パイプライン内でこれらのステップを簡単に呼び出すことができます。
注: オープンソースの Kubeflow パイプライン(KFP)を使って、Google Cloud 上で PyTorch ベースの ML ワークフローをオーケストレートできます。KFP は、Docker コンテナをベースにしたポータブルでスケーラブルな ML ワークフローを構築し、デプロイする OSS Kubeflow プロジェクトのコア コンポーネントです。OSS KFP のバックエンドは、Google Kubernetes Engine(GKE)などの Kubernetes クラスタ上で実行されます。OSS KFP にはデータ読み込み、モデル トレーニング、モデル プロファイリングなど、さまざまな ML タスクのための PyTorch KFP コンポーネント SDK があらかじめ組み込まれています。OSS KFP 上で PyTorch ベースの ML ワークフローをオーケストレーションする方法については、こちらのブログ投稿をご覧ください。
この投稿では、KFP SDK v2 を使用して、前回取り上げた PyTorch テキスト分類モデルのトレーニング、チューニングおよびデプロイのワークフローを自動化し、オーケストレートするパイプラインを定義します。 KFP SDK v2 では、コンポーネントとパイプラインのオーサリングが簡素化され、メタデータのロギングとトラッキングがファースト クラスでサポートされているため、パイプラインで生成されたメタデータやアーティファクトの追跡が容易になりました。
Vertex AI Pipelines でパイプラインを定義し、送信するための大まかな流れは次の通りです。
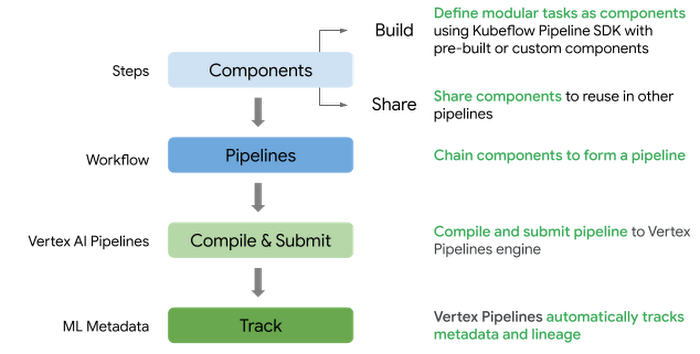
PyTorch モデルのトレーニングとデプロイに関わるパイプライン コンポーネントを定義する
事前に作成された Google Cloud コンポーネントやカスタム コンポーネントを含むワークフローのコンポーネントを合成してパイプラインを定義する
パイプラインをコンパイルして Vertex AI パイプライン サービスに送信し、ワークフローを実行する
パイプラインをモニタリングし、生成された指標やアーティファクトを分析する
この投稿では、これまでの投稿で紹介したトレーニングやサービスコードを基にしています。このブログ投稿の付属コードとノートブックは、GitHub リポジトリでご覧いただけます。
パイプラインのコンセプト
KFP SDK v2 で使われている用語やコンセプトを見てみましょう。KFP SDK に慣れている方は、次のセクション「PyTorch ベースの ML ワークフローのパイプラインの定義」に進んでください。
コンポーネント: コンポーネントとは、ML のワークフローにおいて、モデルの学習などの単一のタスクを実行する自己完結型のコードセットです。コンポーネント インターフェースは、実行コードと環境定義を含む、入力、出力、およびコンポーネントのコードが実行されるコンテナ イメージで構成されます。
パイプライン: パイプラインは、入力と出力を介して連鎖するコンポーネントとして定義されたモジュール式のタスクで構成されます。パイプラインの定義には、パイプラインの実行に必要なパラメータなどの構成が含まれます。パイプラインの各コンポーネントは独立して実行され、データ(入力と出力)はシリアル化された形式でコンポーネント間で受け渡されます。
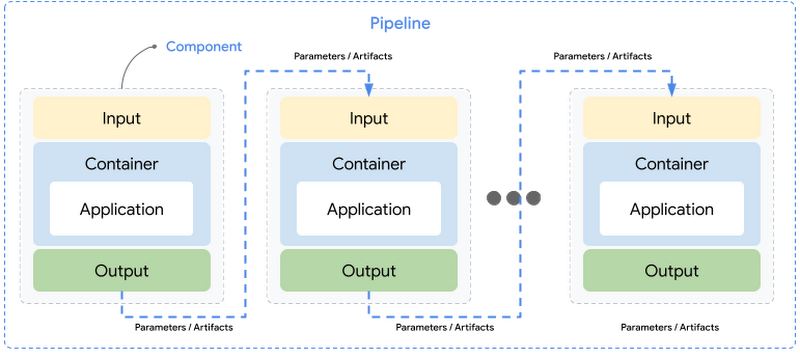
入力と出力: コンポーネントの入力と出力は、データ型でアノテーションされなければならず、それによって入力と出力がパラメータやアーティファクトになります。
パラメータ: パラメータは入力または出力で、str、int、float、bool, dict、list などの単純なデータ型をサポートします。入力パラメータは、コンポーネント間で常に値で渡され、Vertex ML Metadata サービスに格納されます。
アーティファクト: アーティファクトとは、パイプラインの実行によって生成され、入力または出力として渡されるオブジェクトまたはファイルへの参照です。アーティファクトは、ファイルやオブジェクトとして記述されたデータセット、モデル、指標、可視化などのリッチで大きなデータタイプをサポートします。アーティファクトは、名前、URI、および Vertex ML Metadata サービスに自動的に保存されるメタデータによって定義され、アーティファクトの実際のコンテンツは、Cloud Storage のバケット内のパスを参照します。入力アーティファクトは常に参照で渡されます。
KFP SDK v2 のコンセプトについてはこちらをご覧ください。
PyTorch ベースの ML ワークフローのパイプラインの定義
パイプラインのコンセプトが理解できたところで、PyTorch ベースのテキスト分類モデルのパイプラインを構築する方法を見てみましょう。以下のパイプラインの概略図は、入力と出力を含む概要ステップを示しています。
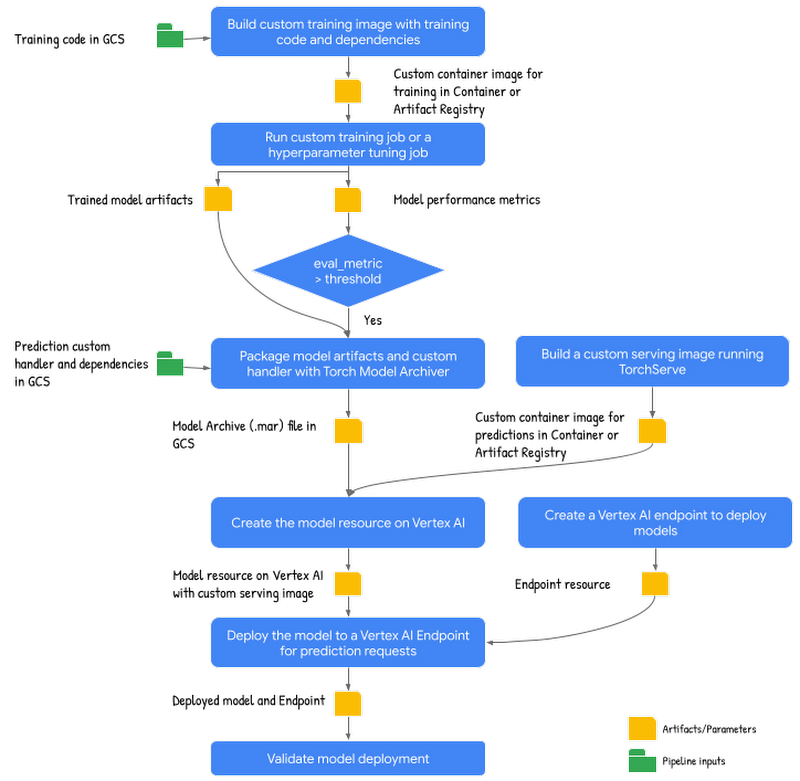
PyTorch のトレーニングとデプロイのパイプラインの概略図
以下は、パイプラインのステップです。
カスタム トレーニング イメージの構築: このステップでは、トレーニング アプリケーションのコードと、依存関係のある Dockerfile を関連付けて、カスタム トレーニング コンテナ イメージを構築します。このステップの出力は、コンテナまたはアーティファクト レジストリの URI です。
カスタム トレーニング ジョブを実行して、モデルのトレーニングと評価を行う: このステップでは、HuggingFace に関する IMDB センチメント分類データセットから、トレーニング データをダウンロードして前処理を行い、前のステップのカスタム トレーニング コンテナ上でモデルのトレーニングと評価を行います。このステップでは、学習したモデルのアーティファクトとモデルの性能評価指標の Cloud Storage のパスを出力します。
モデル アーティファクトのパッケージ化: このステップでは、カスタム予測ハンドラを含め学習済みモデルの成果物をパッケージ化し、モデル アーカイブ(.mar)ファイルを Torch Model Archiver ツールを使用して作成します。このステップの出力は、GCS 上のモデル アーカイブ(.mar)ファイルの位置です。
カスタム サービング イメージの構築: このステップでは、マウントされたモデルの予測リクエストに対応するために、カスタム サービング コンテナを構築し、このコンテナは TorchServe HTTP サーバーを実行します。このステップの出力は、カスタム サービング コンテナに対するコンテナまたはアーティファクト レジストリの URI です。
カスタム サービング コンテナを使ってモデルをアップロード: このステップでは、前のステップで作成したカスタム サービング イメージとモデル アーカイブ ファイル(.mar)を使用して、モデルリソースを作成します。
エンドポイントの作成: このステップでは、予測要求が送信されるサービス URL を提供する Vertex AI エンドポイントを作成します。
モデルをエンドポイントにデプロイし、サービスを提供する: このステップでは、オンライン予測リクエストを処理するために必要なコンピューティング リソース(構成されたマシンスペックに基づく)を作成するエンドポイントにモデルをデプロイします。
デプロイの検証: このステップでは、エンドポイントにテスト要求を送信し、デプロイを検証します。
ここでは、パイプラインについていくつかの注意点があります。
パイプラインは、トレーニング用のコンテナ イメージを構築することから始まります。なぜなら Google が取り組んでいるテキスト分類モデルは、トレーニング コード自体にデータの準備と前処理のステップがあるからです。独自のデータセットを扱う場合、データの準備や前処理のタスクを、モデルのトレーニングとは別のコンポーネントとして含めることができます。
カスタム トレーニングやサービス コンテナの構築は、ML パイプラインの一部として、または既存の CI / CD パイプライン(継続的インテグレーション / 継続的デリバリー)の中で行うことができます。この投稿では、カスタム コンテナの構築を ML パイプラインの一部として選択しました。今後の投稿では、ML パイプラインとモデルの CI / CD について深く掘り下げていきます。
パイプラインとコンポーネント仕様の完全な定義については、添付のノートブックを参照してください。
コンポーネント仕様
このパイプラインの概略図をもとに、次は KFP SDK v2 のコンポーネント仕様を使って、パイプラインのステップを実行するための個々のコンポーネントを定義します。Google Cloud パイプライン コンポーネント SDK のビルド済みコンポーネントと、カスタム コンポーネントを組み合わせて使用します。
ステップの 1 つであるカスタム トレーニング コンテナ イメージの構築について、 コンポーネントの仕様を見てみましょう。ここでは、Python の関数ベースのコンポーネントを定義しています。コンポーネント コードは、スタンドアロンの Python 関数として定義されています。この関数は、トレーニング アプリケーション コードの Cloud Storage パス、プロジェクト名、モデル表示名を入力パラメータとして受け取り、カスタム トレーニング コンテナへの Container Registry (GCR) URI を出力します。この関数は、トレーニング アプリケーション コードと Dockerfile を pull し、Container Registry(またはアーティファクト リポジトリ)に push されるカスタム トレーニング イメージをビルドする Cloud Build ジョブを実行します。前回の投稿では、このステップは docker コマンドを使用してノートブックで実行されましたが、今回はこのステップをコンポーネント内に自己完結させ、パイプラインに含めることでこの作業を自動化します。
コンポーネントの仕様については、いくつか注意すべき点があります。
定義されたスタンドアロン関数を、@kfp.v2.dsl.component デコレーターを使用してパイプライン コンポーネントとして変換する。
KFP は関数の入出力を使ってコンポーネントのインターフェースを定義するため、スタンドアロン関数のすべての引数にデータ型アノテーションを付ける必要がある。
デフォルトでは、定義されたコードを実行するためのベースイメージとして、Python 3.7 が使用される。base_image を指定してデフォルトのイメージを上書きしたり、packages_to_install パラメータを使って追加の python パッケージをインストールしたり、output_component_file を使ってコンパイルされたコンポーネントを YAML ファイルとして書き出したりして、コンポーネントを共有したり再利用したりするための @component デコレーターを構成できます。
上記のスタンドアロン関数の入力と出力は、値を表す単純なデータ型であるパラメータとして定義されています。入力と出力には、コンポーネントの実行中に生成されたファイルやオブジェクトを表すアーティファクトを使用できます。これらの引数は、kfp.dsl.Input または kfp.dsl.Output のアーティファクトとしてアノテーションされます。たとえば、モデル アーカイブ ファイルを作成するコンポーネントの仕様書では、トレーニング ジョブで生成されたモデルのアーティファクトを次の スニペット の中で、Input[Model] という入力として参照しています。
KFP v2 SDK のアーティファクト タイプについてはこちらを、Google Cloud パイプライン コンポーネントのアーティファクト タイプについてはこちらを参照してください。
パイプラインの他のステップのコンポーネント仕様については、付属のノートブックを参照してください。
パイプラインの定義
コンポーネントを定義したら、次はステップ間で入出力パラメータやアーティファクトをどのように受け渡すかを記述したパイプライン定義を構築します。次のコード スニペットでは、コンポーネントを連結して表示しています。
このコードを紐解いて、考えてみましょう。
パイプラインは、@kfp.dsl.pipeline デコレーターでアノテーションされたスタンドアロンの Python 関数として定義され、パイプラインの名前と、パイプラインのアーティファクトが保存されるルートパスを指定します。
パイプラインの定義は、事前に構築されたコンポーネントとカスタム定義されたコンポーネントの両方で構成されている
Google Cloud パイプライン コンポーネント SDK の事前構築されたコンポーネントは、カスタム トレーニング ジョブの投入(custom_job.CustomTrainingJobOp)、モデルのアップロード(ModelUploadOp)、エンドポイントの作成(EndpointCreateOp)、エンドポイントへのモデルのデプロイ(ModelDeployOp)など、Vertex AI サービスを呼び出すステップによって定義されます。
カスタム コンポーネントは、トレーニング用のカスタム コンテナを構築するステップ(build_custom_train_image)、トレーニング ジョブの詳細を取得するステップ(get_training_job_details)、Mar ファイルを作成するステップ(generate_mar_file)とサービングを行うステップ(build_custom_serving_image)、モデルのデプロイタスクを検証するステップ(make_prediction_request)に定義されています。これらの手順については、カスタム コンポーネントの仕様に関するノートブックを参照してください。
コンポーネントの入力は、(引数として渡される)パイプラインの入力から設定することができ、また、このパイプライン内の他のコンポーネントの出力に依存できます。たとえば、ModelUploadOp は、build_custom_serving_image タスクからのカスタム サービング コンテナ イメージの URI と、プロジェクト ID、サービング コンテナのルートやポートなどのパイプラインの入力に依存しています。
kfp.dsl.Condition は、条件が満たされたときにのみ実行されるステップ グループを持つ制御構造。このパイプラインでは、学習したモデルのパフォーマンスが設定したしきい値を超えた場合にのみ、モデルのデプロイのステップが実行されます。そうでない場合は、これらのステップはスキップされます。
パイプラインの各コンポーネントは、独自のコンテナ イメージの中で実行される。パイプライン ステップごとに、CPU、GPU、メモリ制限などのマシンタイプを指定できます。デフォルトでは、各コンポーネントは e2-standard-4 マシンを使用して、Vertex AI CustomJob として実行されます。
デフォルトでは、パイプラインの実行キャッシュ保存は有効。Vertex AI Pipelines サービスは、各パイプライン ステップの実行が Vertex ML Metadata に存在するかどうかを確認します。パイプライン名、ステップの入力、出力、コンポーネントの仕様の組み合わせを使用します。一致する実行がすでに存在する場合、そのステップはスキップされ、それによってコストが削減されます。実行キャッシュ保存は、タスクレベルまたはパイプライン レベルでオフにできます。
パイプラインの構築については、Kubeflow パイプラインの構築セクションを参照し、サンプルやチュートリアルを参考にしてください。
パイプラインのコンパイルと送信
Vertex AI パイプライン サービスで実行するためには、パイプラインをコンパイルする必要があります。パイプラインがコンパイルされると、KFP SDK はコンポーネント間のデータ依存関係を分析し、有向非巡回グラフを作成します。コンパイルされたパイプラインには、パイプラインの実行に必要なすべての情報が JSON 形式で表示されます。
パイプラインは、Vertex AI SDK for Python クライアントを使用して PipelineJob を定義し、必要なパイプラインの入力を渡すことで、Vertex AI Pipelines に送信されます。
パイプラインが送信されると、ログには Google Cloud Console でパイプラインの実行結果を見るためのリンクが表示されるか、Vertex AI のパイプライン ダッシュボードを開いて実行結果にアクセスできます。

パイプライン ダッシュボードにアクセス
以下は、PyTorch テキスト分類モデルのパイプラインのランタイム グラフです。
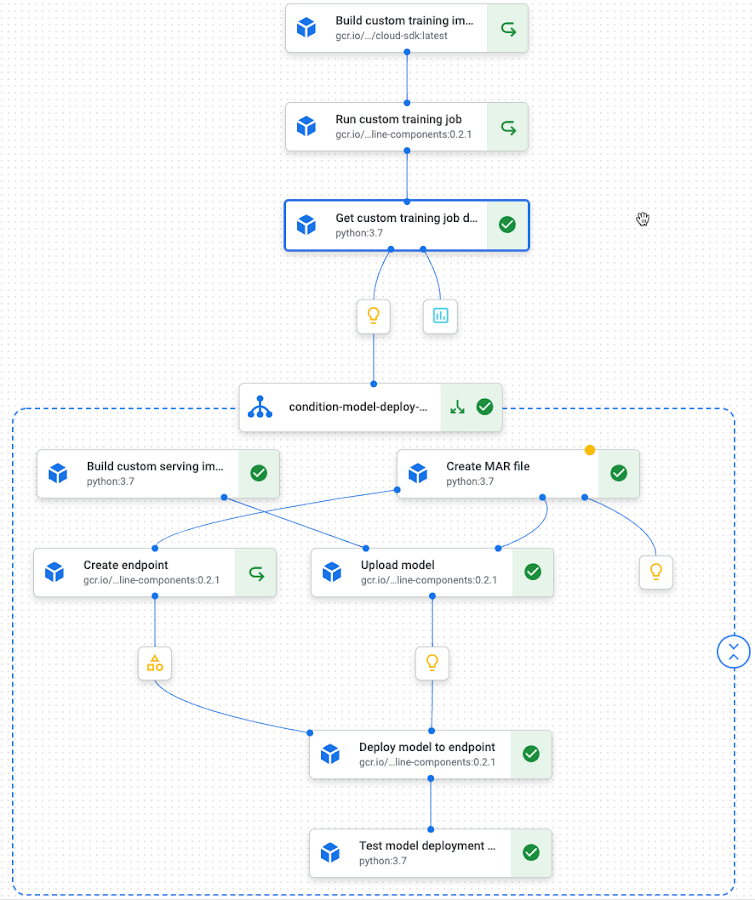
パイプラインのランタイム グラフ
コンパイルされたパイプラインのプロトコル
パイプラインのモニタリング
パイプラインの実行ページには、実行の概要に加えて、ステップの入力やモデル、アーティファクト、指標、可視化などの生成された出力を含む個々のステップの詳細が表示されます。
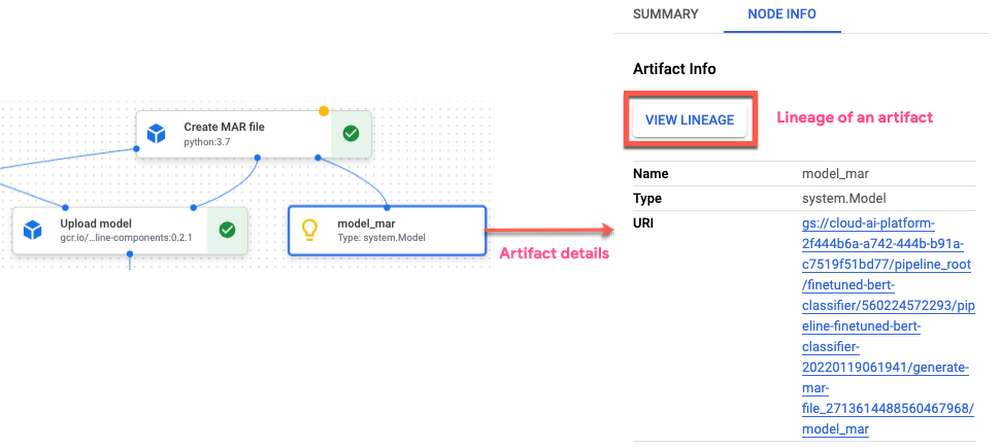
Vertex AI Pipelines では、パイプラインの実行情報を Vertex ML Metadata でメタデータやアーティファクトを含めて自動的に追跡することで、パイプラインの実行間の比較や ML アーティファクトのリネージを可能にしています。

パイプライン リネージ
入力、パラメータ、指標、可視化など、パイプラインの実行結果を Vertex AI パイプラインを用いて比較できます。Vertex AI SDK の aiplatform.get_pipeline_df() メソッドを使って、パイプラインの実行メタデータを Pandas のデータフレームとして取得できます。

Pandas データフレームとしてのパイプライン実行メタデータ
リソースをクリーンアップする
テストが終了したら、Notebooks インスタンスを停止または削除できます。作業内容を保存する場合は、削除の代わりに、インスタンスの停止も選択できます。インスタンスを停止すると、永続ディスク ストレージの料金のみが請求されます。
この投稿で作成したすべての Google Cloud リソースをクリーンアップするには、作成した個々のリソースを削除します。
トレーニング ジョブ
モデル
エンドポイント
Cloud Storage バケット
コンテナ イメージ
パイプラインの実行
Jupyter Notebook のクリーンアップ セクションに沿って、個々のリソースを削除します。
次のステップ
この投稿では、Vertex AI での PyTorch ベースのテキスト分類モデルのトレーニングとデプロイに引き続き、Vertex AI Pipelines と Kubeflow Pipelines v2 SDK を使って PyTorch ベースの ML ワークフローを自動化する方法を紹介します。次のステップとして、このパイプラインの例を Vertex AI で実行することで、独自の PyTorch モデルの 1 つをオーケストレートできます。
参考資料
コードと付随するノートブックを含む GitHub リポジトリ
今後の情報にご注目ください。ご精読ありがとうございました。質問やチャットをご希望の場合は、Twitter または LinkedInで Rajesh までご連絡ください。
Vaibhav Singh、Karl Weinmeister と Jordan Tottenによる執筆の援助および投稿の審査に感謝します。
- Cloud カスタマー エンジニア、機械学習スペシャリスト、Rajesh Thallam




