Vertex Pipelines 一般提供のお知らせ
Google Cloud Japan Team
※この投稿は米国時間 2021 年 11 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、Vertex Pipelines の一般提供を開始しました。
機械学習(ML)ワークフローを拡張する最善の方法の一つとして、ML プロセスを分解して、それぞれ個別のパイプライン ステップを作成し、ワークフローをパイプラインとして実行することが挙げられます。パイプラインは、ML ワークフローの運用化、共有、確実な再現のための優れたツールであるとともに、MLOps の鍵でもあります。パイプラインを使用して、モデルの再トレーニングとデプロイを自動的に行うシステムを構築できます。この記事では、Vertex Pipelines の活用方法をご紹介した後に、活用の足がかりとしてご利用いただけるサンプル パイプラインをご紹介します。
Vertex Pipelines の概要
まず、ML パイプラインの機能について簡単にご説明します。機械学習パイプラインとは、ML ワークフローを一連のステップ(コンポーネントとも呼ばれます)としてカプセル化したものです。パイプラインの各ステップはコンテナに、各ステップの出力は次のステップへの入力になります。しかし、この方法には以下の 2 つの課題があります。
個々のパイプライン ステップをコンテナに変換する方法が必要
パイプラインを大規模実行するために、インフラストラクチャの設定が必要
1 つ目の課題に対処するためには、パイプライン ステップからコンテナへの変換を処理し、パイプライン全体の入出力アーティファクトのフローを管理する優れたオープンソース ライブラリを利用します。これにより、各パイプライン ステップの機能の構築に集中できます。Vertex Pipelines は、Kubeflow パイプライン(KFP)と TensorFlow Extended(TFX)の 2 つの一般的なオープンソース ライブラリをサポートしています。そのため、どちらかのライブラリを使用してパイプラインを定義し、Vertex Pipelines で実行できます。
2 つ目の課題に関しては、Vertex Pipelines は完全にサーバーレスです。KFP パイプラインや TFX パイプラインをアップロードして実行する場合、Vertex AI がプロビジョニングの処理とインフラストラクチャのスケーリングを行い、パイプラインを実行します。パイプラインを実行する間に使用したリソースに対してのみ料金が発生するため、データ サイエンティストは、インフラストラクチャを意識することなく、ML のみに集中できます。
Vertex Pipelines は、Vertex AI および Google Cloud 上の他のツールと統合されています。BigQuery からのデータのインポート、Vertex AI でのモデルのトレーニング、Cloud Storage へのパイプライン アーティファクトの保存、モデル評価指標の取得、Vertex AI エンドポイントへのモデルのデプロイをすべて Vertex Pipelines のステップで行えます。
また、こうした作業をさらに簡単に行えるよう、Vertex Pipelines 向けに、既成のコンポーネント ライブラリを作成しました。この既成のコンポーネントにより、パイプライン ステップで、データセットの作成や AutoML モデルのトレーニングなど、Vertex AI のさまざまな機能を使用するプロセスを簡素化できます。このコンポーネントを使用するには、まず既成のコンポーネント ライブラリをインポートして、ライブラリのコンポーネントをご自身のパイプライン定義内で直接使用します。
たとえば、以下のパイプラインは、BigQuery 内のデータを指す Vertex AI データセットの作成と AutoML モデルのトレーニングを行い、精度が一定のしきい値を超えたトレーニング済みモデルをエンドポイントにデプロイします。
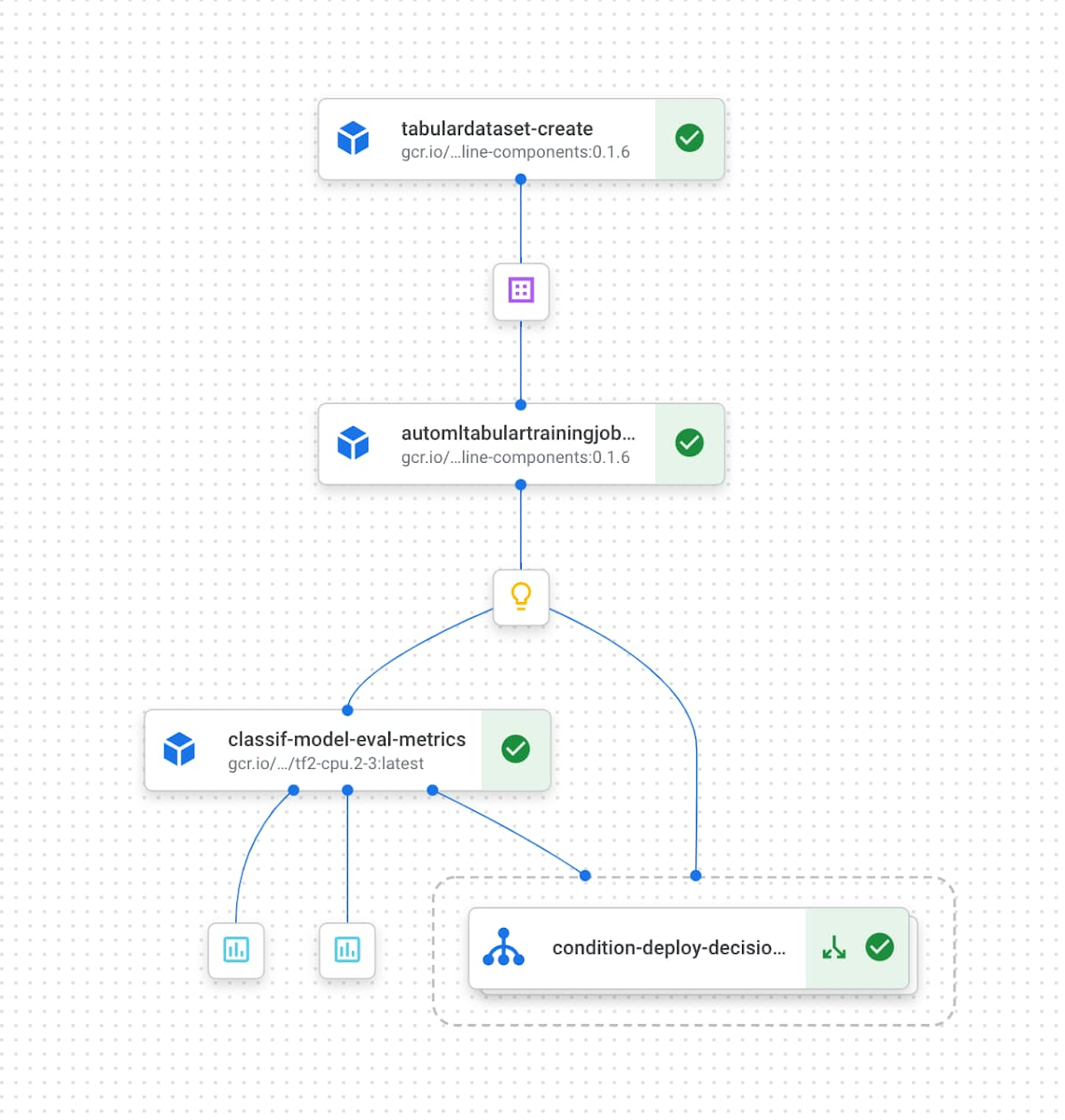
ML メタデータと Vertex Pipelines
出力がパイプライン実行の各ステップで生成されるため、パイプライン実行により作成されるアーティファクトと指標を追跡する仕組みを確保することが大切です。この仕組みは、特にパイプラインの開発と実行に複数のチームメンバーが関わる場合や、さまざまな ML タスク用に複数のパイプラインを管理する場合に有用です。このために、Vertex Pipelines は Vertex ML Metadata と直接統合して、アーティファクト、リネージ、指標を自動的に追跡します。
また、Vertex AI コンソールでは、Vertex AI SDK を使用してパイプライン メタデータを検査できます。このコンソールでメタデータとアーティファクトを確認するには、パイプライン グラフを表示して、[アーティファクトを展開] というスライダーをクリックします。個々のアーティファクトをクリックすると表示される詳細から、アーティファクトごとに保存場所を確認できます。
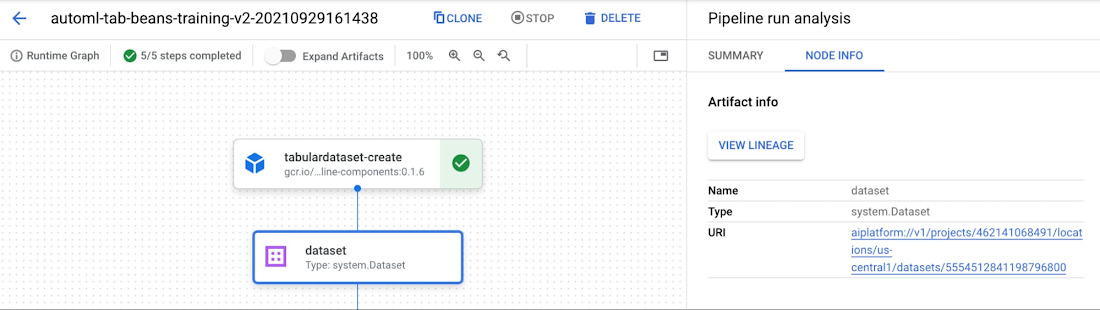
個々のアーティファクトをパイプラインの大きなコンテキストで理解しておくと、出力アーティファクトを確認する際に役立ちます。このために Vertex Pipelines のリネージのトラッキングを活用できます。コンソールでアーティファクトを表示したら、[リネージを表示] ボタンをクリックします。たとえば、以下のエンドポイントには、エンドポイントにデプロイされるモデルと、モデルのトレーニングに使用されるデータセットが表示されています。また、このグラフでは、各アーティファクトを生成したパイプライン ステップも確認できます。

複数の方法でパイプライン メタデータをプログラムで操作できます。Vertex ML Metadata API を使用すると、メタデータ ストア内の任意のアーティファクトや実行をプロパティやリネージでクエリできます。また、Vertex AI SDK の get_pipeline_df メソッドを使用すると、各パイプライン実行の指標を含む Pandas DataFrame を作成できます。さらに、アーティファクト リネージおよびフィルタリング アーティファクトを取得する SDK メソッドを使用すると、パイプラインを追跡するためのカスタム ダッシュボードを作成できます。
サンプル パイプラインの構築
Kubeflow Pipelines SDK で作成したサンプルで、Vertex Pipelines の動作を確認しましょう。このサンプルの完全なパイプライン コードは、こちらの Codelab からご確認いただけます。ここでは、いくつか重要なポイントをご紹介します。このサンプル パイプラインは、Google Cloud の既成のコンポーネント を活用しており、以下の処理を行います。
Vertex AI 内にデータセットを作成
作成したデータセットでカスタムモデルをトレーニング
トレーニング済みモデルでバッチ予測を実行
このパイプラインを構築して実行するには、まず、以下のように Python パッケージをいくつかインポートします。
Vertex AI 上でこのパイプラインを構築して実行するために、以下の 3 つのライブラリを使用します。
Kubeflow Pipelines SDK: コンポーネントの構築と接続によるパイプライン化
Vertex AI SDK: Vertex Pipelines でのパイプライン実行
Google Cloud コンポーネント ライブラリ: 既成のコンポーネントを利用した多様な Google Cloud サービスとのインタラクション
使用する既成のコンポーネントは Google 製であるため、ボイラープレート コードを記述せずにこれらの各タスクを実行できます。または、Google のパイプライン定義内で構成変数をコンポーネントに直接渡すことも可能です。詳細な定義については Codelab でご確認いただけますが、特に重要なものを以下でご紹介します。
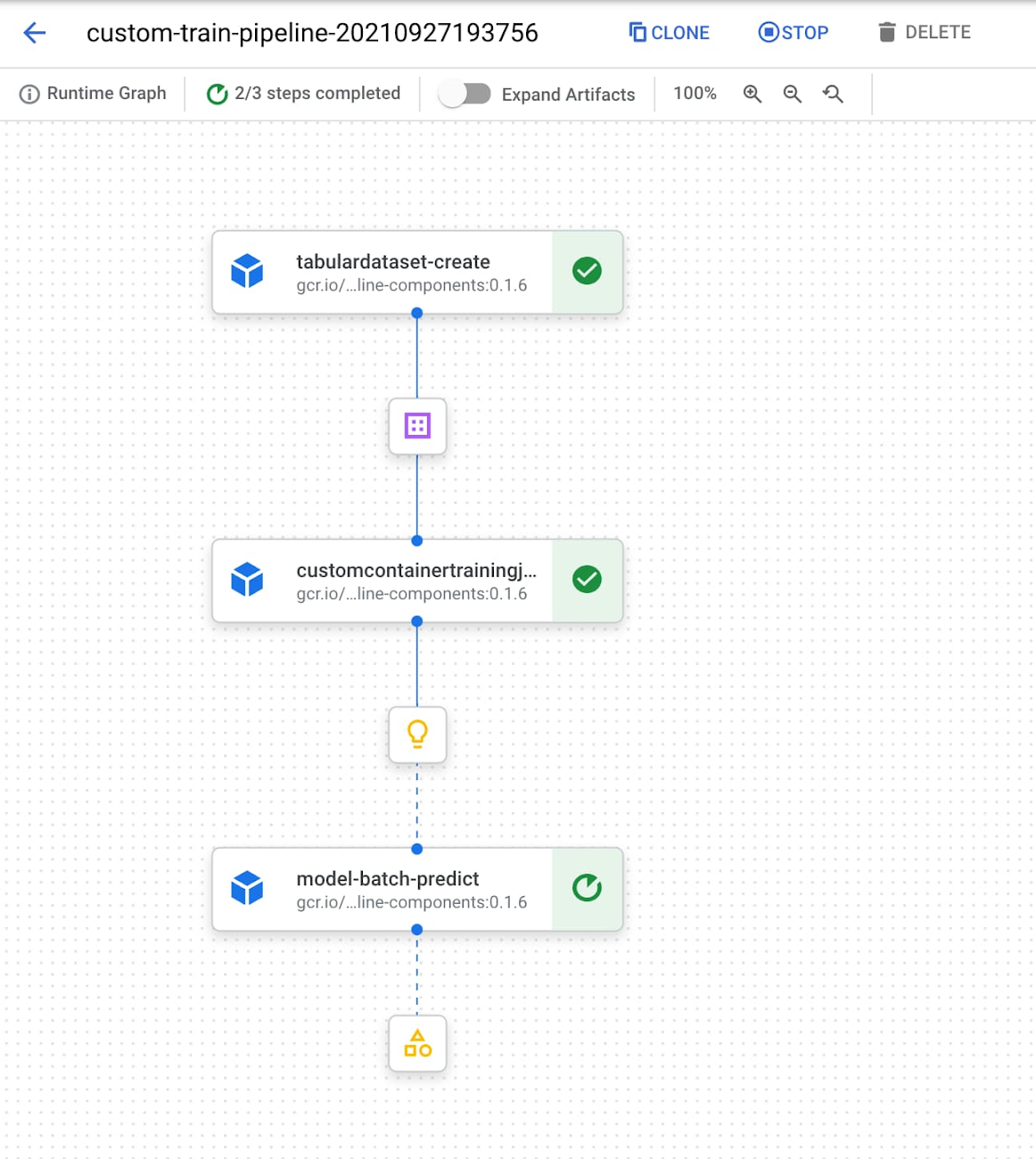
このパイプラインは、最初に TabularDatasetCreateOp コンポーネントを使用して Vertex AI 内にデータセットを作成し、このデータセットの BigQuery ソーステーブルを渡します。作成されたデータセットは、CustomContainerTrainingJobRunOp コンポーネントに渡され、scikit-learn モデル トレーニング ジョブに使用されます。scikit-learn のトレーニング コードをデプロイした Container Registry 内のコンテナを指す構成パラメータがすでに渡されており、このコンポーネントは Vertex AI 内にモデルを出力します。このパイプラインの最後のコンポーネントでは、予測結果を取得したいサンプルの CSV ファイルを提供して、このモデルのバッチ予測ジョブを実行します。
Vertex AI でこのパイプラインをコンパイルして実行すると、以下のように、実行中のパイプラインのグラフをコンソールで確認できます。
Vertex Pipelines を使用して開発を始める
Vertex AI でスケーラブルな ML パイプラインを実行するには、以下のリソースをまずご覧ください。
GitHub で公開中の公式サンプル パイプライン
こちらの Codelabでは、Vertex Pipelines の概要をご覧いただけます。また、こちらの Codelab では、Vertex Pipelines で Vertex ML Metadata を活用する方法を解説しています。
-Staff Developer Relations エンジニア Sara Robinson
-プロダクト マネージャー Karthik Ramachandrank




