Google Cloud 上の PyTorch: Vertex AI に PyTorch モデルをデプロイする方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
この記事は、Vertex AI を使用した Google Cloud 上の PyTorch を紹介するシリーズの一部です。前回の記事では、感情分類タスク用のHugging Face Transformers モデルを、Vertex Training サービスで PyTorch を使用して微調整しました。この投稿では、Vertex Prediction サービスで PyTorch モデルをデプロイし、トレーニングされたモデル アーティファクトから予測を提供する方法を紹介します。
では早速、TorchServe をカスタム コンテナとして使用する PyTorch モデルのデプロイとして、モデル アーティファクトを Vertex Endpoint にデプロイする例を見てみましょう。このブログ投稿の内容に関連するコードは、GitHub リポジトリ と Jupyter Notebook で確認できます。
Vertex Prediction サービスに PyTorch モデルをデプロイする
Vertex Prediction サービスは、Google Cloud のマネージドモデル提供プラットフォームです。マネージド サービスであるこのプラットフォームは、インフラストラクチャのセットアップ、メンテナンス、管理を行います。Vertex Prediction は、CPU による推論と GPU による推論の両方をサポートしており、Compute Engine でさまざまな n1-standard マシンの形状を提供しています。このため、お客様は要件に合わせてスケール ユニットをカスタマイズできます。Vertex Prediction サービスは、次の理由により、モデルをデプロイして予測を提供するのに最も効率的な方法となっています。
シンプル: Vertex Prediction サービスは、予測用の事前構築されたコンテナによりモデルサービスを簡素化します。お客様の側で必要な作業は、モデル アーティファクトの保存場所を指定することだけです。
柔軟: カスタム コンテナを使用する場合、Vertex Prediction は抽象化レベルを下げることで柔軟性を提供します。このため、お客様は ML フレームワーク、モデルサーバー、前処理、後処理を必要に応じて自由に選択できます。
アシスト: モデルのパフォーマンスをトラッキングし、予測を説明または理解するためのツールが組み込まれています。
TorchServe は、本番環境で PyTorch モデルをデプロイするためのおすすめのフレームワークです。TorchServe の CLI により、ローカルに PyTorch モデルをデプロイしやすくなります。また、Vertex Prediction サービスによりスケールアウト可能なコンテナとしてパッケージ化することもできます。Vertex Prediction のカスタム コンテナ機能は、TorchServe モデルサーバーを実行する環境を定義するための柔軟な方法を提供します。
このブログ投稿では、TorchServe モデルサーバーを Vertex Prediction サービスで実行してコンテナをデプロイし、感情分類タスク用に微調整された Hugging Face の Transformer モデルから予測を提供します。その後、Vertex Endpoint にテキストで入力リクエストを送信すると、感情がポジティブかネガティブかを分類できます。

図 1: Vertex Prediction サービスのカスタム コンテナで提供
Vertex Prediction に PyTorch モデルをデプロイする手順は次のとおりです。
トレーニング済みのモデル アーティファクトをダウンロードします。
Torch Model Archiver ツールを使ってアーカイブ ファイルを作成し、デフォルトまたはカスタム ハンドラを含めてトレーニング済みのモデル アーティファクトをパッケージ化します。
Vertex Prediction サービスに適合するカスタム コンテナ(Docker)をビルドし、TorchServe を使ってモデルを提供します。
モデルをカスタム コンテナのイメージとともに Vertex Model のリソースとしてアップロードします。
Vertex Endpoint を作成し、エンドポイントにモデルリソースをデプロイして予測を提供します。
1. トレーニング済みのモデル アーティファクトをダウンロードする
モデル アーティファクトは、予測の提供に必要なトレーニング アプリケーション コードにより作成されます。TorchServe は、モデル アーティファクトが保存されたモデルバイナリ(.bin)形式またはトレースされたモデル(.pth か .pt)形式のどちらかであることを前提としています。以前の投稿では、Vertex Training サービスで Hugging Face Transformer をトレーニングし、.save_model() メソッドを呼び出してモデルをモデルバイナリ(.bin)として保存して、Cloud Storage バケットにモデル アーティファクトを保存しました。
トレーニング ジョブの名前に基づき、Cloud Console または gcloud ai custom-jobs describe コマンドを使用して Vertex Training からモデル アーティファクトの場所を取得してから、Cloud Storage バケットからアーティファクトをダウンロードします。
2. カスタム モデルハンドラを作成して予測リクエストを処理する
TorchServe はベース ハンドラ モジュールを使って、入力を前処理してからモデルに送信する、またはモデル出力を後処理してから予測レスポンスを送信します。TorchServe には、画像分類、オブジェクト検知、セグメンテーション、テキスト分類などの一般的なユースケース向けに、デフォルトのハンドラが用意されています。感情分析タスクでは、カスタム ハンドラを作成します。トレーニング / サービング スキューを避けるために、トレーニング時に使用されたのと同じトークナイザを使用して入力テキストをトークン化する必要があるからです。
このカスタム ハンドラは次のことを行います。
トレーニング中に使用されたのと同じ Hugging Face Transformers Tokenizer クラスを使用して入力テキストを前処理してから、テキストを推論用のモデルに送信する
推論用のモデルを呼び出す
モデルの出力を後処理してからレスポンスを送り返す
3. TorchServe を使ってカスタム コンテナ イメージを作成し、予測を提供する
Vertex Prediction サービスに PyTorch をデプロイする際は、HTTP サーバーを実行するカスタム コンテナ イメージ(この場合 TorchServe など)を使用する必要があります。カスタム コンテナ イメージは、Vertex Prediction サービスに適合するための要件を満たしている必要があります。カスタム コンテナ イメージの要件を満たすベースイメージとして TorchServe を使用した Dockerfile を作成し、次の手順を行います。
カスタム ハンドラがモデル推論リクエストを処理するために必要な依存関係をインストールします。たとえば、ユースケースの Transformers パッケージです。
トレーニング済みのモデル アーティファクトを、コンテナ イメージの /home/model-server/ ディレクトリにコピーします。イメージのビルド時にモデル アーティファクトが使用可能であることを前提としています。ノートブックでは、トレーニング済みのモデル アーティファクトを、ハイパーパラメータ調整を試行した際に保存された Cloud Storage バケットからダウンロードしています。
コンテナ イメージの /home/model-server/ ディレクトリにカスタム ハンドラのスクリプトを追加します。
/home/model-server/config.properties を作成し、ヘルスチェックや予測リスナーポートなどの提供構成を定義します。
Torch Model Archiver ツールを実行して、イメージ /home/model-server/ にコピーされたファイルからモデル アーカイブ ファイルを作成します。モデル アーカイブは /home/model-server/model-store/ に保存され、名前は <model-name>.mar と同じです
Torchserve HTTP サーバーを起動し、構成プロパティを参照するモデルとモデル アーカイブ ファイルの提供を有効化します。
次に、これらのステップにおける TorchServe と Torch Model Archiver ツールの機能について説明します。
Torch Model Archiver
TorchServe には、PyTorch モデルをデプロイ用にパッケージ化するためのモデル アーカイブ ユーティリティが用意されています。生成されたモデルのアーカイブ ファイルは提供時に TorchServe により使用されます。以下は、テキスト分類モデル向けにモデルのアーカイブ ファイルを生成するために Dockerfile に追加する torch-model-archiver コマンドです。
モデルバイナリ(--serialized-file parameter): モデルバイナリはシリアル化された Pytorch モデルで、保存されたモデルバイナリ(.bin)ファイルまたはTorchScript - Torch Just In Time(JIT)コンパイラ を使用して生成するトレースされたモデル(.pth)ファイルのいずれかとなります。この例では、保存されたモデルバイナリを使用します。これは、前回の投稿で事前トレーニング済みの Hugging Face Transformer モデルを微調整して生成したものです。
注: JIT コンパイラのトレースでは、出力にデバイス依存のオペレーションが含まれることがあります。そのため、モデルのデプロイ先と同じ環境でトレースを生成することをおすすめします。
モデルハンドラ(--handler パラメータ): モデルハンドラは、TorchServe のデフォルトのハンドラ、またはモデル入力の前処理もしくはモデル出力の後処理を行えるカスタムの TorchServe 推論ロジックをハンドルする Python ファイルへのパスとなります。カスタム ハンドラについては、この投稿の前のセクションで定義しました。
追加ファイル(--extra-files パラメータ): 追加ファイルにより、モデルハンドラが参照する追加ファイルをパッケージ化できます。例として、コマンドに登場するファイルの一部を以下に示します。
index_to_name.json: 先ほど定義したカスタム ハンドラでは、後処理のステップで予測ターゲットのインデックスを人間が読めるラベルにマッピングするために index_to_name JSON ファイルが使用されます。
config.json: モデルの読み込みに、AutoModelForSequenceClassification.from_pretrained メソッドに必要です
vocab.txt: トークナイザが使用する vocab ファイルです
TorchServe
TorchServe は、PyTorch モデルを HTTP ウェブサーバーが提供する一連の REST API へとラッピングします。torchserve コマンドを CMD またはカスタム コンテナの ENTRYPOINTに追加すると、このサーバーが起動します。この記事では、予測とヘルスチェックの API のみを紹介します。Vertex エンドポイントの PyTorch 用の Explainable AI API は、現在表形式データのみでサポートされています。
TorchServe Config(--ts-config parameter): TorchServe config により、推論アドレスと管理ポートをカスタマイズできます。また、service_envelop フィールドを json に構成して、TorchServe の予想される入力形式を表しています。その他のパラメータの構成については、TorchServe ドキュメントをご覧ください。config.properties ファイルを作成し、TorchServe config として渡します。
● モデルストア(--model-store parameter): ローカルまたはデフォルトのモデルを読み込むことができるモデルストアの場所です
● モデル アーカイブ(--models parameter): [model_name=]model_location 形式を使用して TorchServe が読み込むモデルです。モデルの場所はモデルストアのモデル アーカイブ ファイルです。
4. カスタム コンテナ イメージをビルドおよび push する
● 次のコマンドを実行して、Dockerfile に基づいてコンテナ イメージをビルドし、Container Registry リポジトリと互換性がある名前でタグ付けします。
イメージを Container Registry に push する前に、入力リクエストを docker 内で実行中のローカルの TorchServe デプロイに送信することで、docker イメージをローカルでテストできます。
コンテナ イメージをコンテナとしてローカルで実行するには、次のコマンドを実行します。
コンテナのサーバーにヘルスチェックを送信するには、次のコマンドを実行します。
このリクエストではテスト文を使用します。成功すると、サーバーは次の形式で予測を返します。
- レスポンスの検証後、サーバーはカスタム ハンドラ、モデルのパッケージ、TorchServe config が予想どおりに動作していることを確認します。コンテナを停止すると、TorchServe のローカル サーバーを停止できます。
次に、Container Registry にカスタム コンテナ イメージを push します。これは、その次の手順で Vertex Endpoint にデプロイされます。
注: カスタム コンテナ イメージは、Container Registry リポジトリでなく Artifact Registry リポジトリに push することもできます。
5. 提供コンテナを Vertex Endpoint にデプロイする
ここまでで、モデルをパッケージ化して提供コンテナ イメージをビルドしました。次の手順では、これを Vertex Endpoint にデプロイします。オンライン予測の提供に使用するには、モデルをエンドポイントにデプロイする必要があります。モデルのデプロイでは、少ないレイテンシでオンライン予測を提供できるように、モデルに物理リソースを関連付けます。モデルをアップロードしてエンドポイントにデプロイするには、Vertex SDK for Python を使用します。次の手順は、Vertex Training サービスや、オンプレミスなどの他の場所でトレーニングされたすべてのモデルに適用できます。
モデルをアップロードする
モデル アーティファクトを Vertex AI にアップロードし、デプロイ用にモデルリソースを作成します。この例では、アーティファクトは提供コンテナ イメージの URI です。この手順では、predict および health ルート(必須ルート)とコンテナポートも指定する点に注目してください。
モデルのアップロード後は、Google Cloud Console の Vertex AI セクションの [モデル] ページでモデルを確認できます。
エンドポイントを作成する
サービス エンドポイントを作成してモデルをデプロイします。エンドポイントにより、予測リクエストが送信されるサービス URL が提供されます。モデルを既存のエンドポイントにデプロイする場合は、この手順をスキップできます。
エンドポイントが作成されたら、Google Cloud Console の Vertex AI セクションの [エンドポイント] ページでエンドポイントを確認できます。
モデルをエンドポイントにデプロイする
最後の手順として、モデルをエンドポイントにデプロイします。デプロイ メソッドによりモデルがデプロイされ、マシンタイプ、最小および最大のレプリカ数のスケーリング、トラフィック分割などのパラメータが計算されるエンドポイントを指定するためのインターフェースが提供されます。
モデルをエンドポイントにデプロイした後は、Google Cloud Console の Vertex AI セクションの [エンドポイント] ページで、デプロイされたモデルを管理およびモニタリングできます。
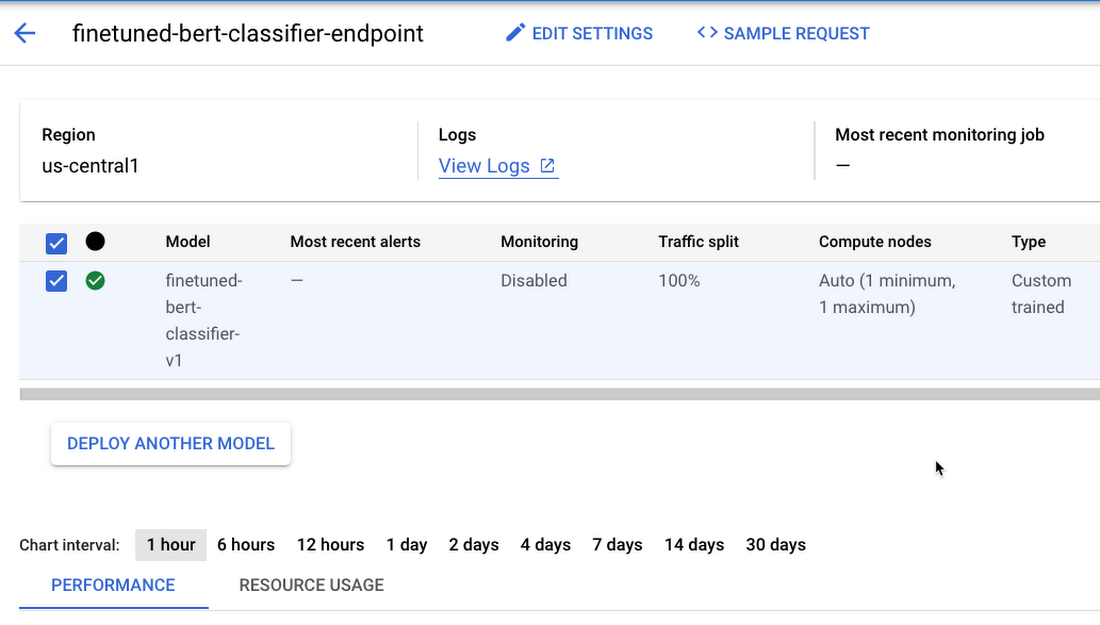
デプロイをテストする
モデルがデプロイされたので、endpoint.predict() メソッドを使って base64 encoded テキストを予測リクエストに送信すると、レスポンスで予測された感情を取得できます。
または、Vertex Endpoint を呼び出し、gcloud beta ai endpoints predict コマンドを使って予測することもできます。コード全体については、Jupyter Notebook をご覧ください。
環境をクリーンアップする
テストが終了したら、Notebooks インスタンスを停止または削除できます。さらなる料金が発生しないようにするには、Notebook インスタンスを削除します。作業内容を保存する場合は、削除の代わりに、インスタンスの停止も選択できます。
この投稿および前回の投稿で作成したすべての Google Cloud リソースをクリーンアップするには、作成したリソースを個別に削除します。
トレーニング ジョブ
モデル
エンドポイント
Cloud Storage バケット
コンテナ イメージ
Jupyter Notebook のクリーンアップ セクションに沿って、個々のリソースを削除します。
次のステップ
Vertex AI の PyTorch ベースのテキスト分類モデルのトレーニングとハイパーパラメータの調整の続きとして、Vertex Prediction サービスでの PyTorch モデルのデプロイを紹介しました。Vertex Prediction サービスで TorchServe モデルサーバーを実行してカスタム コンテナをデプロイし、トレーニング済みのモデル アーティファクトから予測を提供しました。次のステップとして、Vertex AI のこちらの例を学習してみてください。あるいは、自分の PyTorch モデルを 1 つデプロイしてみてもよいでしょう。
参考資料
コードと付随するノートブックを含む GitHub リポジトリ
このシリーズの次の記事では、Vertex Pipelines を使って機械学習のワークフローをオーケストレートし、トレーニング、ハイパーパラメータの調整、PyTorch モデルのデプロイなどの、これまで紹介した個々のステップを続けて行う方法について学習します。これは、Google Cloud Platform 上での機械学習モデルの CI/CD(継続的インテグレーション / 継続的デリバリー)の基盤となります。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、こちらで著者をお探しください。Rajesh [Twitter | LinkedIn] および Vaibhav [LinkedIn]。
記事の作成と推敲に協力してくれた Karl Weinmeister と Jordan Totten に感謝します。
- Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam
- Cloud カスタマー エンジニア、機械学習スペシャリスト Vaibhav Singh


